
資料分析與資料探勘 - 02基礎操練
阿新 • • 發佈:2020-09-04
### 一 知識體系
在這一章我們將使用基礎的Python庫pandas,numpy,matplotlib來完成一個數據分析的小專案,推薦使用Anaconda環境下的jupter-notebook來進行練習。
### 二 背景介紹 這是一組航空公司使用者的資料,我們希望能夠從這些資料中分析出有價值的資訊,資料如下。
[chapter2-1.zip](https://www.yuque.com/attachments/yuque/0/2020/zip/281865/1598816105888-9cbf30e6-8358-4b29-bfd9-664d61619cc0.zip?_lake_card=%7B%22uid%22%3A%221598816103725-0%22%2C%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2020%2Fzip%2F281865%2F1598816105888-9cbf30e6-8358-4b29-bfd9-664d61619cc0.zip%22%2C%22name%22%3A%22chapter2-1.zip%22%2C%22size%22%3A5059285%2C%22type%22%3A%22application%2Fzip%22%2C%22ext%22%3A%22zip%22%2C%22progress%22%3A%7B%22percent%22%3A99%7D%2C%22status%22%3A%22done%22%2C%22percent%22%3A0%2C%22id%22%3A%2240Rgb%22%2C%22card%22%3A%22file%22%7D)
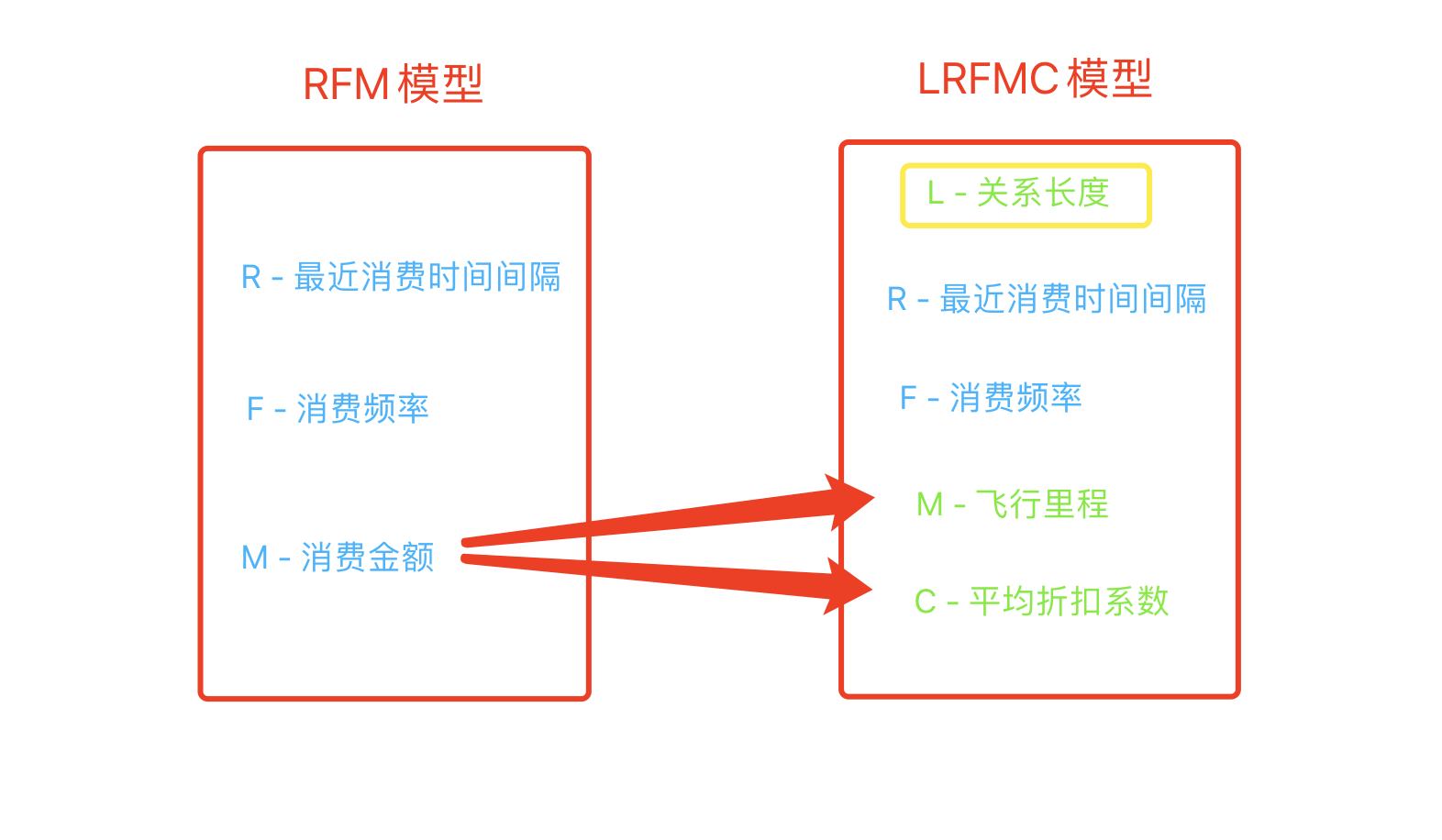
接下來我們要做的就是資料探索了
### 五 探索性分析 我們可以使用以下程式碼很容易找到資料中的缺失值,最大值和最小值 ```python import pandas as pd # 1 定義檔名稱 datafile = 'air_data.csv' # 初始檔案 resultfile = 'explore.csv' # 目標檔案 # 2 讀取檔案資訊 data = pd.read_csv(datafile, encoding='utf-8') # 使用pd.read_csv來讀取csv檔案 # 3 呈現檔案內容 explore = data.describe().T # 獲取描述資訊後在進行據陣轉置 # 4 計算空白數量 explore['null'] = len(data) - explore['count'] # 5 構造問題矩陣 explore = explore[['null', 'max', 'min']] # 通過這個矩陣來初步觀察問題 # 6 修改矩陣名稱 explore.columns = ['空值數量', '最大值', '最小值'] # 7 儲存探索檔案 explore.to_csv(resultfile) ``` ### 六 資料預處理 資料預處理主要採用資料清洗和資料變換的方法,這是構造模型的必要條件,資料清洗的原則必須是根據業務場景而定,根據業務場景,我們制定出如下規則:保留票價非零資料,或平局折扣率不為零且總飛行里程大於零的資料,然後清洗資料,具體程式碼如下 ```python import numpy as np import pandas as pd # 1 讀取原始資料 datafile = 'air_data.csv' cleanedfile = 'data_cleaned.csv' data = pd.read_csv(datafile) print("原始資料的形狀", data.shape) # 2 刪除缺失資料 airline_notnull = data.loc[data['SUM_YR_1'].notnull() & data['SUM_YR_1'].notnull()] print("刪除缺失資料後的形狀", airline_notnull.shape) """ 3 定製規則:保留票價非零資料,或平局折扣率不為零且總飛行里程大於零的資料,然後清洗資料 """ index1 = airline_notnull['SUM_YR_1'] != 0 # 保留票價非零 index2 = airline_notnull['SUM_YR_2'] != 0 index3 = airline_notnull['SEG_KM_SUM'] >
我們使用kmeans演算法來完成聚類分析,分析過程如下 ```python from sklearn.cluster import KMeans import matplotlib.pyplot as plt airline_scale = np.load('airline_scale.npz')['arr_0'] k = 5 # 把相似的物件分成幾類,k值就設定成幾 # 構建模型 kmeans_model = KMeans(n_clusters = k, random_state=123) # random_state為隨即種子 # 訓練模型 fit_means = kmeans_model.fit(airline_scale) # 獲取聚類中心 kmeans_cc = kmeans_model.cluster_centers_ print(kmeans_cc) # 每一行程式碼五維空間中的一個點 # 獲取樣本類別標籤 kmeans_labels = kmeans_model.labels_ print(kmeans_labels) # 統計不同類別樣本數目 r1 = pd.Series(kmeans_labels).value_counts() # 轉換資料格式 cluster_center = pd.DataFrame(kmeans_model.cluster_centers_, columns=['L','R','F','M','C']) # 順序重置 cluster_center.index = pd.DataFrame(kmeans_model.labels_).drop_duplicates().iloc[:,0] print(cluster_center) # 用聚類演算法,把幾萬個使用者聚成5類 ``` 關於聚類演算法,現在我們可以不必關係他的原理,後續我們會有專門的章節來講解,現在只需要跟著我的程式碼,一步一步瞭解這個過程即可。
### 九資料視覺化 用純資料的方式不利於我們觀察聚類分析的結果,讓我們資料視覺化的方法繪製成圖形來看一下吧。 ```python import matplotlib.pyplot as plt labels = ['L','R','F','M','C'] # 指標 legen = ['customer' + str(i + 1) for i in cluster_center.index] # 名稱 lstype = ['-','--',(0,(3,5,1,5,1,5)),':','-.'] # 樣式 kinds = list(cluster_center.iloc[:,0]) # 分類 kinds # 資料閉合,雷達圖需要資料閉合 cluster_center = pd.concat([cluster_center, cluster_center[['L']]], axis=1) cluster_center centers = np.array(cluster_center.iloc[:, 0:]) centers # 分割圓周的長 n = len(labels) angle = np.linspace(0,2*np.pi, n, endpoint=False) angle = np.concatenate((angle, [angle[0]])) angle # 畫布 fig = plt.figure(figsize=(8,6)) ax = fig.add_subplot(111, polar=True) for i in range(len(kinds)): ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i]) ax.set_thetagrids(angle*180/np.pi, labels) plt.title('customer type') plt.legend(legen) # 新增圖例 plt.show() ``` ### 十 結合業務做分析報告 一個優秀的資料分析師的功底即將呈現的時刻到了,上面我們做的所有的工作就是為了最後這一步,如何結合業務場景分析出使用者價值和後續應對策略已以及營銷方案才是我們做資料分析的重中之重。
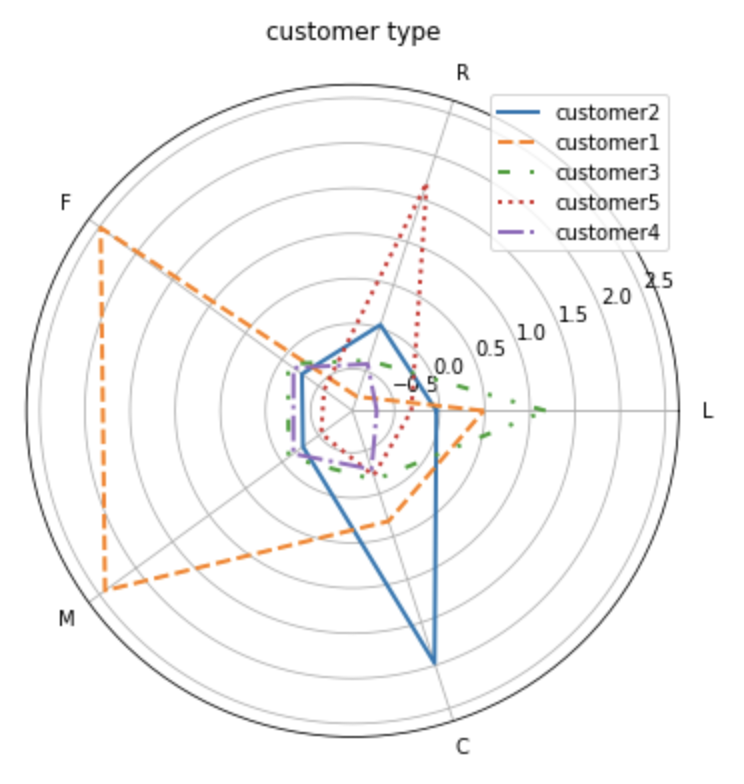
L 關係長度- LOAD_TIME - FFP_DATE
R 最近消費時間間隔- LAST_TO_END
F 消費頻率- FLIGHT_COUNT
M 飛行里程- SEG_KM_SUM
C 平均折扣係數- AVG_DISCOUNT
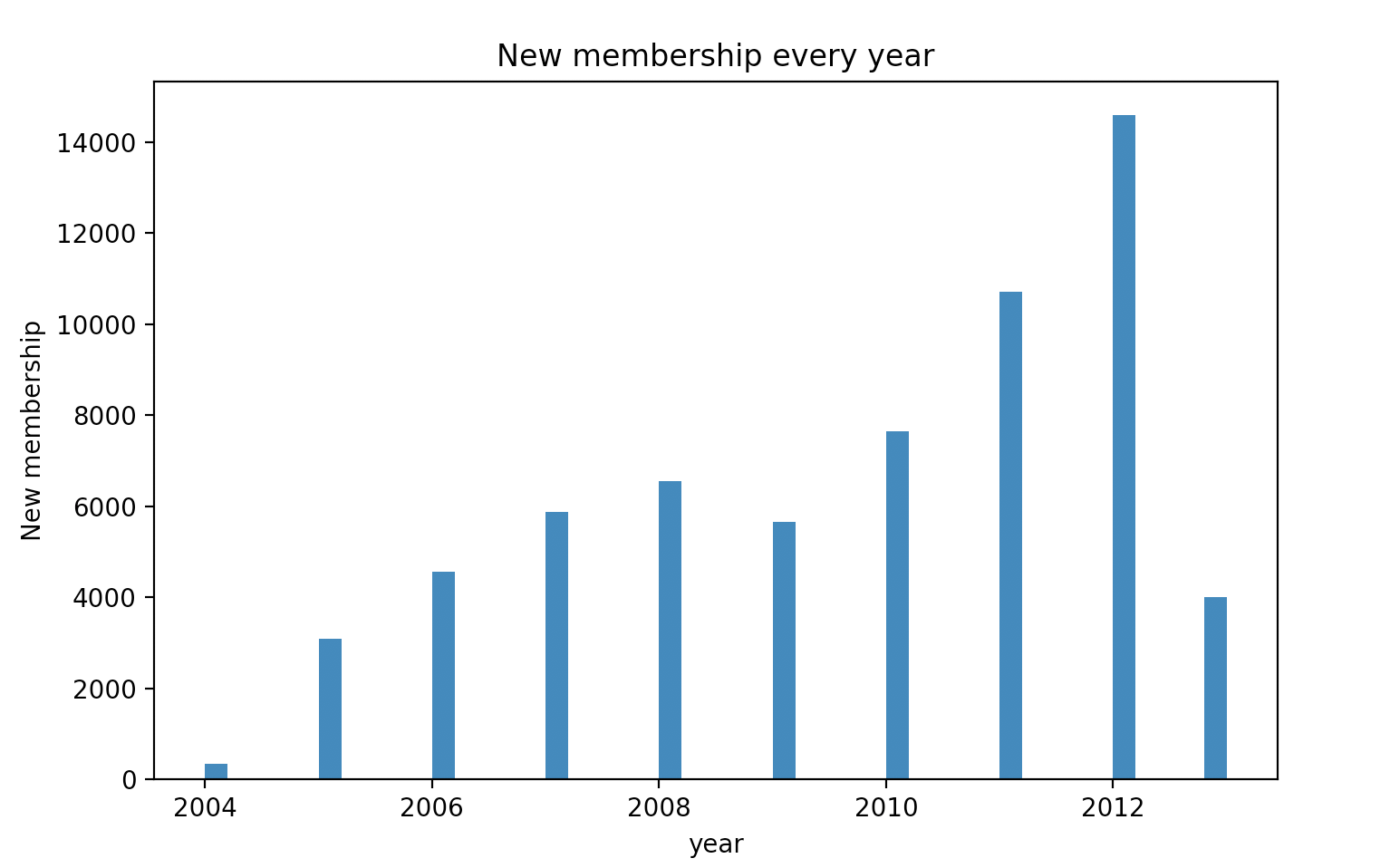
我們把圖形和每一緯度對應的指標都放在這裡,下面就和我一起根據圖形來做分析。根據上面的特徵分析圖示說明每類使用者都有顯著不同的表現特徵,基於這些特徵的描述,我們把這些使用者分為五個等級的客戶類別:重要保持客戶,重要發展客戶,重要挽留客戶,一般客戶,其中每類客戶類別的特徵如下: 1. 重要保持客戶:customer1,這類客戶的平均折扣率(C)較高,說明一般所乘坐航班的艙位等級較高,最近乘坐本航班(R)低,乘坐次數(F)和里程(M)最高,他們是航空公司的高價值使用者,是最為理想的客戶型別,對航空公司貢獻最大,所佔比例卻小,航空公司應該優先將資源投放到他們身上,對他們進行差異化管理和一對一服務,提高這類客戶的忠誠度和滿意度,儘可能延長這類客戶的高消費水平。 2. 重要發展使用者:customer2,這類客戶平均折扣率最高,雖然當前價值不高,卻是航空公司的潛在價值客戶,要努力使這類客戶增加消費,加強客戶滿意度,提高他們轉向競爭對手的轉移成本,是他們逐漸成為公司的忠誠客戶。 3. 重要挽留使用者:customer3,這類客戶入會時間最長,但其他屬性都比較低。航空公司應該根據這些客戶的最近消費時間,消費次數的變化情況,對其採取一定的營銷手段,延長客戶的生命週期。 4. 一般價值使用者:customer4,customer5,這類客戶沒有什麼忠誠度可言,應該是機票打折才會購買的。 ### 十一 補充分析 #### 1 每年新增會員人數 ```python import pandas as pd from datetime import datetime import matplotlib.pyplot as plt data = pd.read_csv('air_data.csv') ffp = data['FFP_DATE'].apply(lambda x: datetime.strptime(x, '%Y/%m/%d')) ffp_year = ffp.map(lambda x: x.year) fig = plt.figure(figsize=(8, 5)) plt.rcParams['font.sans-serif'] = 'SimHei' plt.rcParams['axes.unicode_minus'] = False plt.hist(ffp_year, bins='auto') plt.xlabel('year') plt.ylabel('New membership') plt.title('New membership every year') plt.show() ```
結果如下圖所示:
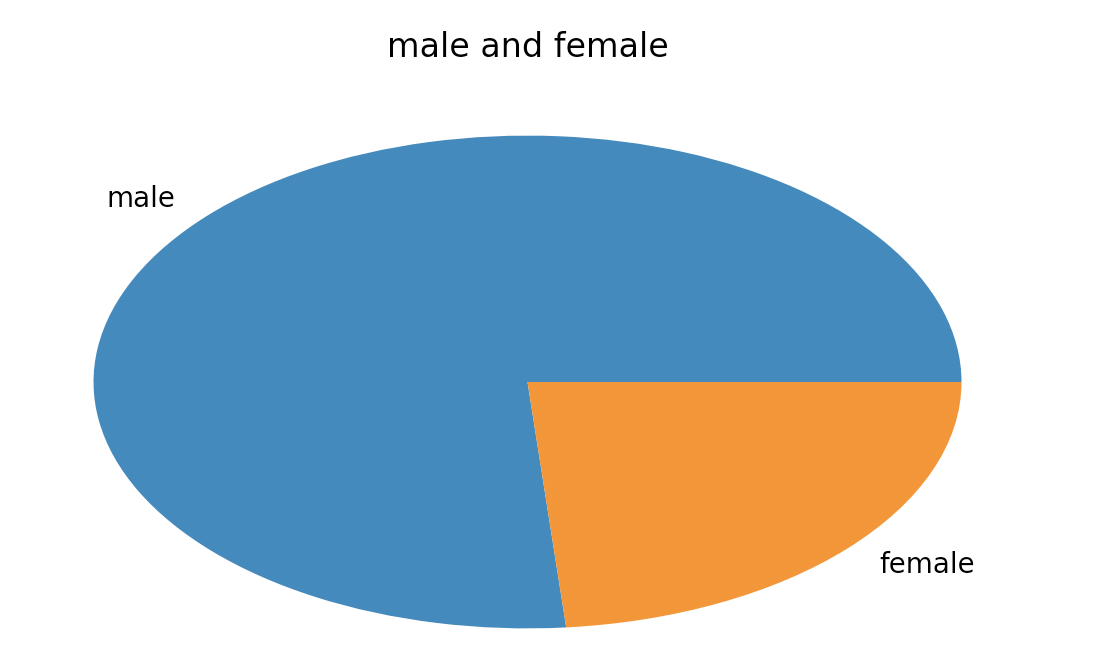
 #### 2 男女比例分析 ```python male = pd.value_counts(data['GENDER'])['男'] female = pd.value_counts(data['GENDER'])['女'] fig = plt.figure(figsize=(7, 4)) plt.pie([male, female], labels=['male', 'female']) plt.title('male and female') plt.show() ```
結果如下圖所示:
以上就是一些最為常用的圖形,當然還有很多的圖形等待著我們後續的學習,每一種資料總有一種圖形適合去表示它,所以資料的視覺化操作在資料分析以及AI領域都有非常重要的作用。相信通過這一章的學習,你一定能夠掌握資料分析的整個流程,並且對資料有一個全新的認
### 二 背景介紹 這是一組航空公司使用者的資料,我們希望能夠從這些資料中分析出有價值的資訊,資料如下。
[chapter2-1.zip](https://www.yuque.com/attachments/yuque/0/2020/zip/281865/1598816105888-9cbf30e6-8358-4b29-bfd9-664d61619cc0.zip?_lake_card=%7B%22uid%22%3A%221598816103725-0%22%2C%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2020%2Fzip%2F281865%2F1598816105888-9cbf30e6-8358-4b29-bfd9-664d61619cc0.zip%22%2C%22name%22%3A%22chapter2-1.zip%22%2C%22size%22%3A5059285%2C%22type%22%3A%22application%2Fzip%22%2C%22ext%22%3A%22zip%22%2C%22progress%22%3A%7B%22percent%22%3A99%7D%2C%22status%22%3A%22done%22%2C%22percent%22%3A0%2C%22id%22%3A%2240Rgb%22%2C%22card%22%3A%22file%22%7D)

接下來我們要做的就是資料探索了
### 五 探索性分析 我們可以使用以下程式碼很容易找到資料中的缺失值,最大值和最小值 ```python import pandas as pd # 1 定義檔名稱 datafile = 'air_data.csv' # 初始檔案 resultfile = 'explore.csv' # 目標檔案 # 2 讀取檔案資訊 data = pd.read_csv(datafile, encoding='utf-8') # 使用pd.read_csv來讀取csv檔案 # 3 呈現檔案內容 explore = data.describe().T # 獲取描述資訊後在進行據陣轉置 # 4 計算空白數量 explore['null'] = len(data) - explore['count'] # 5 構造問題矩陣 explore = explore[['null', 'max', 'min']] # 通過這個矩陣來初步觀察問題 # 6 修改矩陣名稱 explore.columns = ['空值數量', '最大值', '最小值'] # 7 儲存探索檔案 explore.to_csv(resultfile) ``` ### 六 資料預處理 資料預處理主要採用資料清洗和資料變換的方法,這是構造模型的必要條件,資料清洗的原則必須是根據業務場景而定,根據業務場景,我們制定出如下規則:保留票價非零資料,或平局折扣率不為零且總飛行里程大於零的資料,然後清洗資料,具體程式碼如下 ```python import numpy as np import pandas as pd # 1 讀取原始資料 datafile = 'air_data.csv' cleanedfile = 'data_cleaned.csv' data = pd.read_csv(datafile) print("原始資料的形狀", data.shape) # 2 刪除缺失資料 airline_notnull = data.loc[data['SUM_YR_1'].notnull() & data['SUM_YR_1'].notnull()] print("刪除缺失資料後的形狀", airline_notnull.shape) """ 3 定製規則:保留票價非零資料,或平局折扣率不為零且總飛行里程大於零的資料,然後清洗資料 """ index1 = airline_notnull['SUM_YR_1'] != 0 # 保留票價非零 index2 = airline_notnull['SUM_YR_2'] != 0 index3 = airline_notnull['SEG_KM_SUM'] >
我們使用kmeans演算法來完成聚類分析,分析過程如下 ```python from sklearn.cluster import KMeans import matplotlib.pyplot as plt airline_scale = np.load('airline_scale.npz')['arr_0'] k = 5 # 把相似的物件分成幾類,k值就設定成幾 # 構建模型 kmeans_model = KMeans(n_clusters = k, random_state=123) # random_state為隨即種子 # 訓練模型 fit_means = kmeans_model.fit(airline_scale) # 獲取聚類中心 kmeans_cc = kmeans_model.cluster_centers_ print(kmeans_cc) # 每一行程式碼五維空間中的一個點 # 獲取樣本類別標籤 kmeans_labels = kmeans_model.labels_ print(kmeans_labels) # 統計不同類別樣本數目 r1 = pd.Series(kmeans_labels).value_counts() # 轉換資料格式 cluster_center = pd.DataFrame(kmeans_model.cluster_centers_, columns=['L','R','F','M','C']) # 順序重置 cluster_center.index = pd.DataFrame(kmeans_model.labels_).drop_duplicates().iloc[:,0] print(cluster_center) # 用聚類演算法,把幾萬個使用者聚成5類 ``` 關於聚類演算法,現在我們可以不必關係他的原理,後續我們會有專門的章節來講解,現在只需要跟著我的程式碼,一步一步瞭解這個過程即可。
### 九資料視覺化 用純資料的方式不利於我們觀察聚類分析的結果,讓我們資料視覺化的方法繪製成圖形來看一下吧。 ```python import matplotlib.pyplot as plt labels = ['L','R','F','M','C'] # 指標 legen = ['customer' + str(i + 1) for i in cluster_center.index] # 名稱 lstype = ['-','--',(0,(3,5,1,5,1,5)),':','-.'] # 樣式 kinds = list(cluster_center.iloc[:,0]) # 分類 kinds # 資料閉合,雷達圖需要資料閉合 cluster_center = pd.concat([cluster_center, cluster_center[['L']]], axis=1) cluster_center centers = np.array(cluster_center.iloc[:, 0:]) centers # 分割圓周的長 n = len(labels) angle = np.linspace(0,2*np.pi, n, endpoint=False) angle = np.concatenate((angle, [angle[0]])) angle # 畫布 fig = plt.figure(figsize=(8,6)) ax = fig.add_subplot(111, polar=True) for i in range(len(kinds)): ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i]) ax.set_thetagrids(angle*180/np.pi, labels) plt.title('customer type') plt.legend(legen) # 新增圖例 plt.show() ``` ### 十 結合業務做分析報告 一個優秀的資料分析師的功底即將呈現的時刻到了,上面我們做的所有的工作就是為了最後這一步,如何結合業務場景分析出使用者價值和後續應對策略已以及營銷方案才是我們做資料分析的重中之重。

L 關係長度- LOAD_TIME - FFP_DATE
R 最近消費時間間隔- LAST_TO_END
F 消費頻率- FLIGHT_COUNT
M 飛行里程- SEG_KM_SUM
C 平均折扣係數- AVG_DISCOUNT
我們把圖形和每一緯度對應的指標都放在這裡,下面就和我一起根據圖形來做分析。根據上面的特徵分析圖示說明每類使用者都有顯著不同的表現特徵,基於這些特徵的描述,我們把這些使用者分為五個等級的客戶類別:重要保持客戶,重要發展客戶,重要挽留客戶,一般客戶,其中每類客戶類別的特徵如下: 1. 重要保持客戶:customer1,這類客戶的平均折扣率(C)較高,說明一般所乘坐航班的艙位等級較高,最近乘坐本航班(R)低,乘坐次數(F)和里程(M)最高,他們是航空公司的高價值使用者,是最為理想的客戶型別,對航空公司貢獻最大,所佔比例卻小,航空公司應該優先將資源投放到他們身上,對他們進行差異化管理和一對一服務,提高這類客戶的忠誠度和滿意度,儘可能延長這類客戶的高消費水平。 2. 重要發展使用者:customer2,這類客戶平均折扣率最高,雖然當前價值不高,卻是航空公司的潛在價值客戶,要努力使這類客戶增加消費,加強客戶滿意度,提高他們轉向競爭對手的轉移成本,是他們逐漸成為公司的忠誠客戶。 3. 重要挽留使用者:customer3,這類客戶入會時間最長,但其他屬性都比較低。航空公司應該根據這些客戶的最近消費時間,消費次數的變化情況,對其採取一定的營銷手段,延長客戶的生命週期。 4. 一般價值使用者:customer4,customer5,這類客戶沒有什麼忠誠度可言,應該是機票打折才會購買的。 ### 十一 補充分析 #### 1 每年新增會員人數 ```python import pandas as pd from datetime import datetime import matplotlib.pyplot as plt data = pd.read_csv('air_data.csv') ffp = data['FFP_DATE'].apply(lambda x: datetime.strptime(x, '%Y/%m/%d')) ffp_year = ffp.map(lambda x: x.year) fig = plt.figure(figsize=(8, 5)) plt.rcParams['font.sans-serif'] = 'SimHei' plt.rcParams['axes.unicode_minus'] = False plt.hist(ffp_year, bins='auto') plt.xlabel('year') plt.ylabel('New membership') plt.title('New membership every year') plt.show() ```
結果如下圖所示:
 #### 2 男女比例分析 ```python male = pd.value_counts(data['GENDER'])['男'] female = pd.value_counts(data['GENDER'])['女'] fig = plt.figure(figsize=(7, 4)) plt.pie([male, female], labels=['male', 'female']) plt.title('male and female') plt.show() ```
結果如下圖所示:

以上就是一些最為常用的圖形,當然還有很多的圖形等待著我們後續的學習,每一種資料總有一種圖形適合去表示它,所以資料的視覺化操作在資料分析以及AI領域都有非常重要的作用。相信通過這一章的學習,你一定能夠掌握資料分析的整個流程,並且對資料有一個全新的認