
資料分析與資料探勘 - 05統計概率
阿新 • • 發佈:2020-09-19
### 一 統計學基礎運算
#### 1 方差的計算
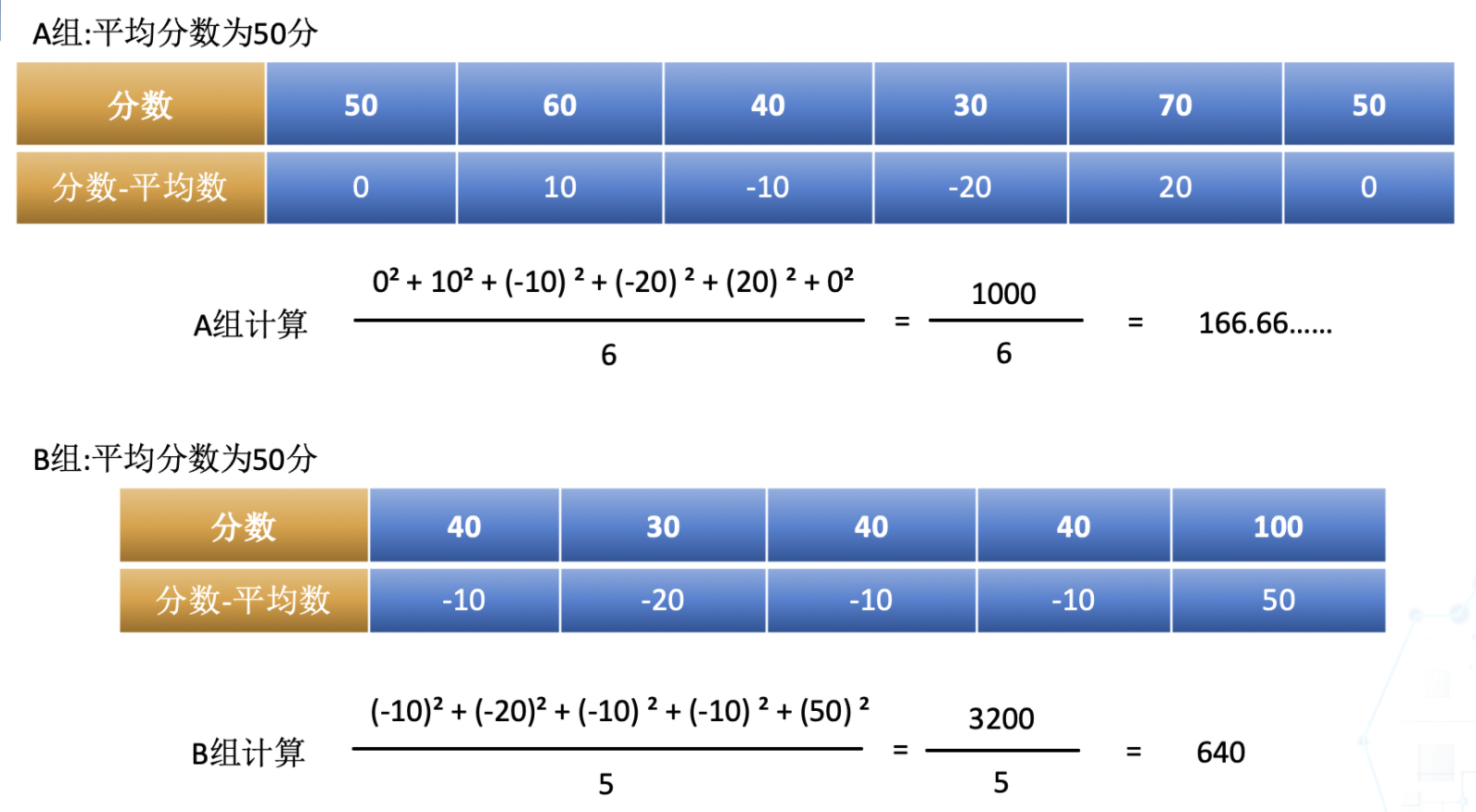
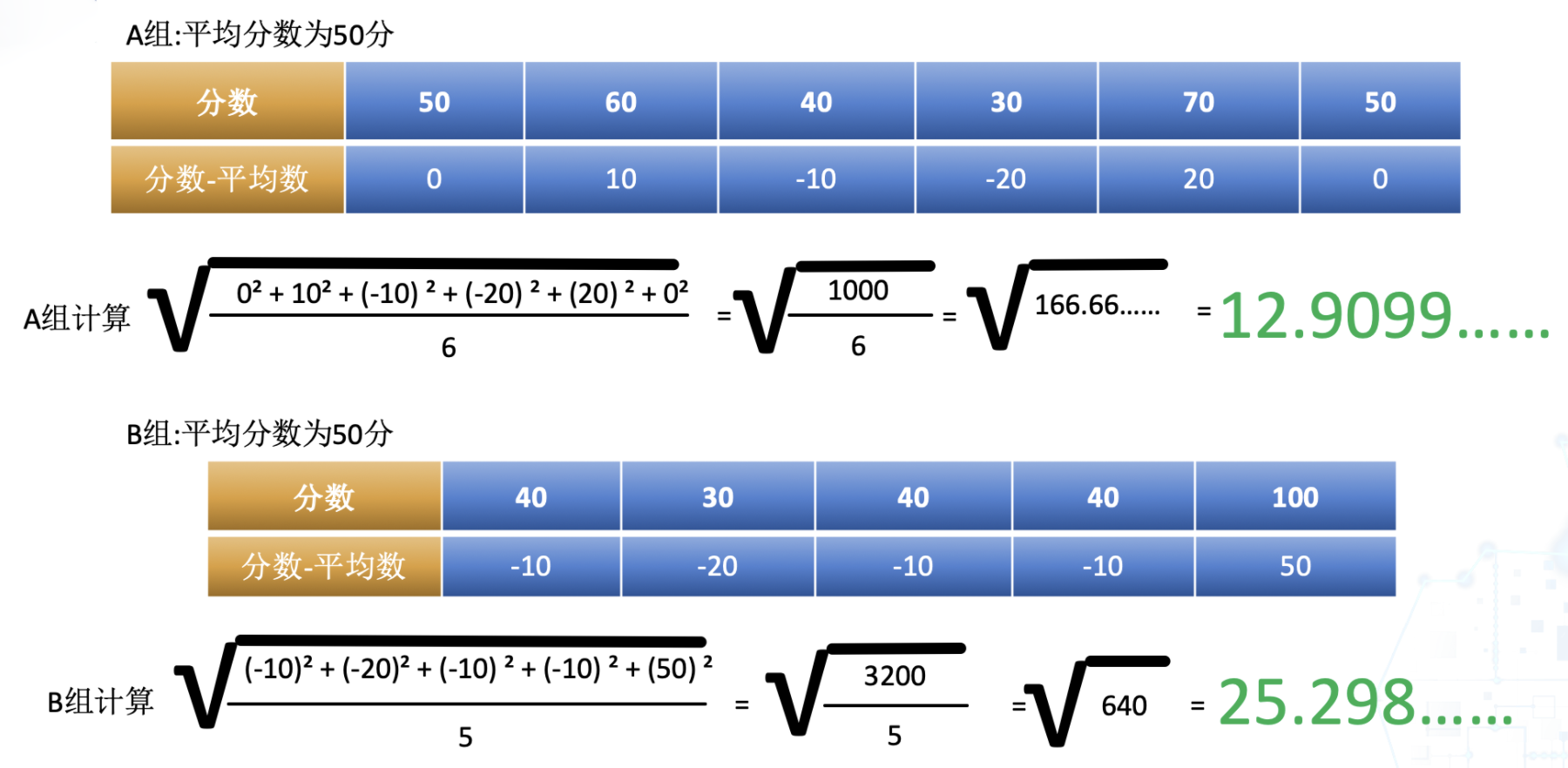
在統計學中為了觀察資料的離散程度,我們需要用到標準差,方差等計算。我們現在擁有以下兩組資料,代表著兩組同學們的成績,現在我們要研究哪一組同學的成績更穩定一些。方差是中學就學過的知識,可能有的同學忘記了 ,一起來回顧下。
**A組 = [50,60,40,30,70,50] B組 = [40,30,40,40,100]**
為了便於理解,我們可以先使用平均數來看,它們的平均數都是50,無法比較出他們的離散程度的差異。針對這樣的情況,我們可以先把分數減去平均分進行平方運算後,再取平均值。

2ab這一項可以用排列組合的知識來理解,從(a+b)(a+b)分別選出a和b的可能性,那麼一共有兩種情況:
- 從第一個(a+b)中選出a,從第二個(a+b)選出b - 從第二個(a+b)中選出a,從第一個(a+b)中選出b
所以ab左邊的係數就是2,這個2就是二項式係數,同理:


我們從上邊的兩個例子中可以看到,無論是第一個例子中的從兩個括號中選出一個b,還是後邊的從3個括號中選出一個b(這裡我們把b作為研究物件,其實無論是誰都是一樣的)都是組合的問題,所以結合我們中學學過的知識二項係數可以總結為如下公式:

在統計學中,對於二項分佈來說,二項係數是必不可少的知識,關於二項分佈我們後邊會講到。 #### 2 用Python獲得二項係數 首先需要宣告一個函式,函式接收兩個引數,一個是n,一個是k,返回值為其二項係數的值。 ```python import itertools import numpy as np # 等待排列的陣列 arr = [1, 2, 3, 4, 5] # 排列的實現P print(list(itertools.permutations(arr, 3))) # 組合的實現C print(list(itertools.combinations(arr, 3))) # 獲取二項係數的函式 # 支援兩個引數,第一個是n,第二個是k def get_binomial_coefficient(n, k): return len(list(itertools.combinations(np.arange(n), k))) print(get_binomial_coefficient(3, 1)) ``` 使用二項式係數就可以展開(a+b)^n,所以有二項式定理,如下:
 ### 三 獨立實驗與重複實驗 > 寺廟在中國已經遍佈大江南北了,一天小王和小李二人出遊,爬山後,偶遇一寺廟,寺廟中有一個大師,善占卜。於是二人決定請大師幫忙占卜一次。大師見二人結伴而來,便問二人是占卜獨卦,還是連卦呢?二人不解,何為獨卦,何為連卦?於是大師解答到:獨卦為第一人占卜後,將卦籤放回籤桶中後,再進行第二次占卜。連卦為第一人占卜後,已抽出的卦籤不放回籤桶中,直接進行第二次占卜。 假設籤筒中,只有5根籤,其中2根是上籤,而其他3根是下籤。小王先抽籤,小王抽籤的行為記為S,小李抽籤的行為記為T。在獨卦的占卜規則下,S的結果並不影響T的結果。也就是說不管小王是否抽中上籤,小李抽中上籤的概率都是2/5。而在連卦的占卜規則下,S的結果對T的結果產生影響。因為小王抽完籤之後,並不把籤放回桶中。如果小王抽中上籤,那麼小李抽中上籤的概率就是1/4,如果小王沒有抽中上籤,那麼小李抽中上籤的概率就是2/4。在獨卦的占卜規則下,兩次抽籤行為S與T的。它們的結果互不影響,我們在統計學中稱S與T是獨立試驗。
當S與T相互獨立時,S中發生事件A和T中發生的事件B的概率P可以表示為:
**P(A∩B) = P(A) * P(B)**
顯然,在獨卦的占卜規則下,小王和小李都抽中上籤的概率是4/25。
> 現在有這樣一個場景,擲骰子的遊戲,仍然是小王和小李一起玩,每人拿3顆骰子。遊戲規則是三顆骰子每個擲一次,最後誰的點數大誰贏。這裡不管他們擲骰子多少次,每一次的結果對於其他次的結果都不會產生影響,所以他們都是相互獨立的實驗。 對於這樣反覆的獨立試驗,我們稱其為重複試驗或者叫獨立重複試驗。現在我們把擲3次骰子,每一次擲骰子時,其中2顆骰子都出現1的情況畫圖如下(X代表其他數字):

我們先來看一下第一次擲骰子的情況前兩顆骰子為1,第三顆骰子為其他數字的概率分別為1/6、1/6、5/6,因為每一次的試驗都是相互獨立的,所以發生的概率為1/6×1/6×5/6。三次擲骰子,每一次有兩顆骰子是1的情況的種類為3種,由於3種情況是互斥的(不可能同時發生),所以概率應該為3次的概率相加。也就是:3×(1/6)²×5/6。A事件和B事件相互排斥時,公式可以表示為:
**P(A∪B)=P(A)+P(B)**
根據以上試驗結果,可得重複試驗的概率公式為:

重複試驗對於下一章我們要學習的二項分佈的理解非常有幫助,所以一定要理解。如果不是特別的理解,你可以現在把上邊擲骰子的情況修改成為4顆骰子擲6次,每一次出現兩個1的情況畫圖重新按照咱們上邊的思路梳理一下,相信你就已經能夠掌握了。
練習題:
現在有5道4選1的問題。A同學對這5道題目完全不會,但在亂答的情況下,能夠答對一半以上的概率是多少,用程式碼實現一下。 ```python import itertools import numpy as np """ 題目解析:答對一半以上的情況分別為3題,4題和5題 不用考慮其順序,答對任意題目都可以,所以這是一個組合的問題 """ # 宣告一個函式來求組合問題 def get_binomial_coefficient(n, k): return len(list(itertools.combinations(np.arange(n), k))) # 每題答對的概率 P_true = 1 / 4 # 每題答錯的概率 P_false = 3 / 4 # 求答對0到5題的組合情況 # 答對0題的組合情況 zero = get_binomial_coefficient(5, 0) # 答對1題的組合情況 one = get_binomial_coefficient(5, 1) # 答對2題的組合情況 two = get_binomial_coefficient(5, 2) # 答對3題的組合情況 three = get_binomial_coefficient(5, 3) # 答對4題的組合情況 four = get_binomial_coefficient(5, 4) # 答對5題的組合情況 five = get_binomial_coefficient(5, 5) # # # 答對一半以上的概率(答對3題、4題、5題) last = three * pow(P_true, 3) * pow(P_false, 2) + four * pow(P_true, 4) * pow(P_false, 1) + five * pow(P_true, 5) * pow( P_false, 0) print(last) ``` > 學霸的世界:有一兩個不太確定的,蒙一下吧,考完了很沒信心,感覺考得不怎麼樣,結果是除了蒙的,其他的都對了,數學140分。 > > 學渣的世界:好多不會的,我感覺選這個就應該對,畢竟蒙對的經驗很豐富,感覺考得還可以,結果是會的馬虎做錯了,蒙的就對了一個,數學89分,啪啪打臉。 根據概率結果可知,亂答看似概率還不錯,但實際運算出來後概率低的可憐,所以每次亂答後,實際得分總比想象中的得分低。 ### 四 ∑符號及其意義 在以前,我們表示a1到a5的和會這樣寫:S5 = a1 + a2 + a3 + a4 + a5。同理,如果我們要表示a1到a10的和會這樣寫:S10 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + a9 + a10。如果我們要表示a1到a1000的和我們會這樣寫S1000 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + …… + a1000。但是中間的……總給人一種不好的感覺,就像我們在學習二項定理時的表達方式,總感覺特別的冗長。為了解決這個問題,我們就引入了Σ(讀西格瑪)符號,也可以叫做求和符號。像上邊的表示a1到a1000的和我們可以這樣表達:

Σ(讀西格瑪)符號在數學中非常的常見,在以後的學習中,你也幾乎可以在任意一個演算法模型中見到這個符號,所以它的特點也一定要掌握。
Σ可以使用分配率,我們一起來看一個例子:

下面我們一起來學習一下幾個關於Σ的計算公式,記住它們,以後你的計算將會非常的方便。
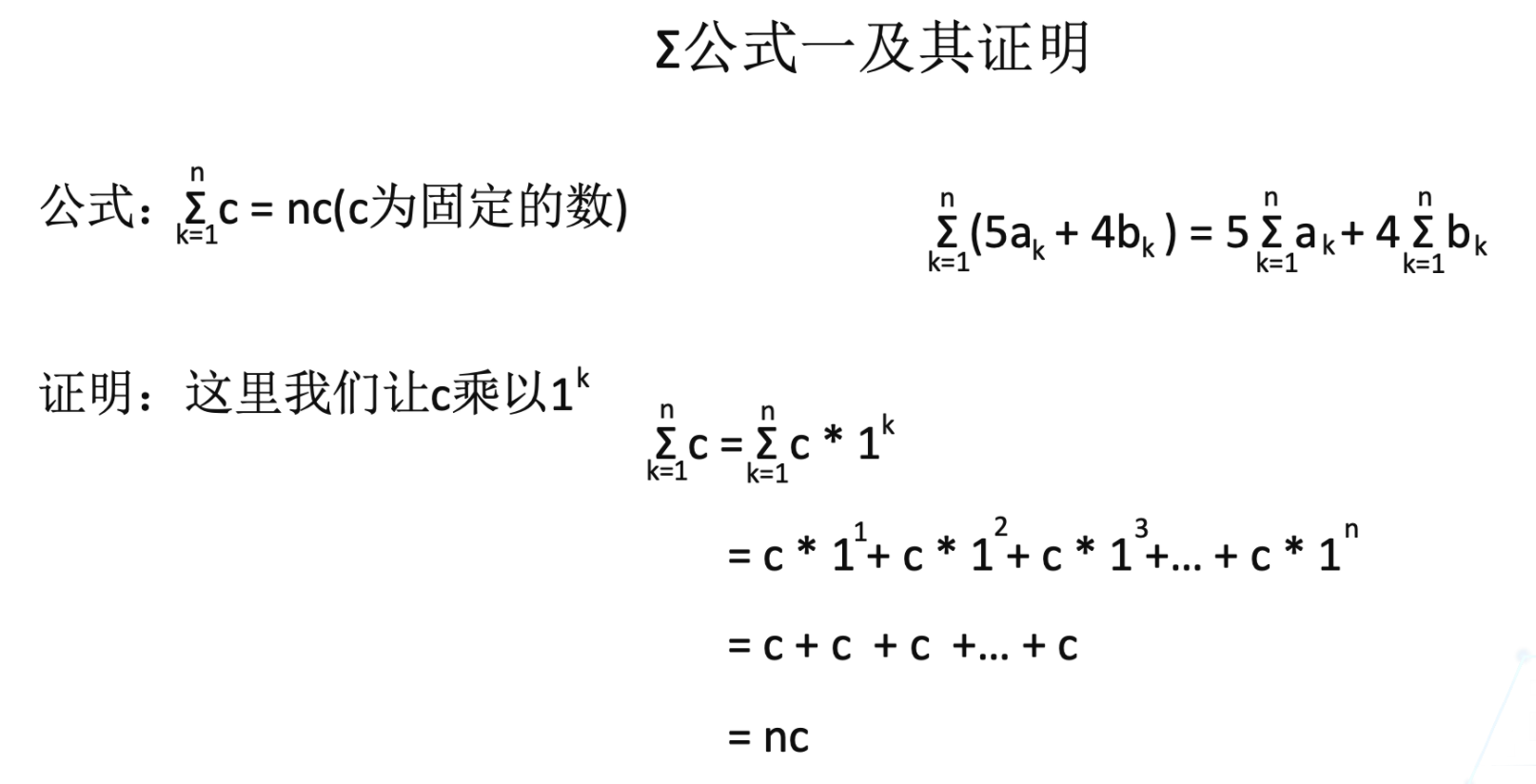
公式一及其證明過程如下:
公式二及其證明過程如下:

Σ的計算公式我們暫時先學習這兩個,其他的公式後邊用到的時候我們再來結合著場景進行學習。 ### 五 隨機變數 終於到了隨機變數,隨機變數後邊就是概率分佈的知識了,隨機變數在人工智慧領域中的應用非常的普遍。首先說一下隨機變數的分類,隨機變數分為離散型隨機變數和連續型隨機變數。離散型隨機變數的基本定義就是在實數範圍內取值並不連續,或者說他的取值不是一個區間,而是一些固定的值。連續型隨機變數則相反,它的取值是一個區間,在實數範圍內是連續的。
還是舉個例子比較形象,請看下面的示例: > 離散型隨機變數:一次擲20個硬幣,k個硬幣正面朝上,k是隨機變數,k的取值只能是自然數0,1,2,…,20,而不能取小數3.5、無理數√20,因而k是離散型隨機變數。 > > 連續型隨機變數:公共汽車每15分鐘一班,某人在站臺等車時間x是個隨機變數,x的取值範圍是[0,15),它是一個區間,從理論上說在這個區間內可取任一實數3.5、√20等,因而稱這隨機變數是連續型隨機變數。 ### 六 伯努利分佈 伯努利分佈也被稱為“零一分佈”或“兩點分佈”。從名字上,我們就能夠看出來,伯努利分佈中事件的發生就兩種情況。伯努利分佈指的是一次隨機試驗,結果只有兩種。生活中這樣的場景很多,拋硬幣是其中一個,我們拋一次硬幣,其結果只有正面或反面。或某一個事件的成功和失敗,病情的康復或未康復等等。
我們用字母x來表示隨機變數的取值,並且它的概率計算公式為:
**P(x=1) = p****,****P(x=0) = 1-p**
當x=1時,它的概率為p,當x-0時,它的概率為1-p,我們就稱隨機變數x服從伯努利分佈。
練習:
甲和乙,兩個人用一個均勻的硬幣來賭博,均勻的意思就是不存在作弊行為,硬幣丟擲正面和反面的概率各佔一半。硬幣丟擲正面時,甲輸給乙一塊錢,丟擲反面時,乙輸給甲一塊錢。我們來用Python實現這一過程和輸贏的總金額呈現的分佈情況。
分析:
我們用數字1來表示拋得的結果為正面,用數字-1來表示拋得的結果為反面。為了呈現出概率分佈的情況,我們需要有足夠多的人來參與這個遊戲,並且讓他們兩兩一組來進行對決。 ```python # 匯入 matplotlib庫,用來畫圖,關於畫圖我們後邊會有專門的章節進行講解 import matplotlib.pyplot as plt # 匯入numpy import numpy as np n_person = 200 n_times = 500 t = np.arange(n_times) # 建立包含1和-1兩種型別元素的隨機陣列來表示輸贏 # *2 -1 是為了隨機出1 和-1,(n_person, n_times)表示生成一個200*500的二維陣列 steps = 2 * np.random.random_integers(0, 1, (n_person, n_times)) - 1 # 計算每一組的輸贏總額 amount = np.cumsum(steps, axis=1) # 計算平方 sd_amount = amount ** 2 # 計算所有參加賭博的組的平均值 average_amount = np.sqrt(sd_amount.mean(axis=0)) print(average_amount) # 畫出資料,用綠色表示,並畫出平方根的曲線,用紅色表示 plt.plot(t, average_amount, 'g.', t, np.sqrt(t), 'r') plt.show() ``` ### 七 二項分佈 離散型隨機變數最常見的分佈就是二項分佈,我們還是以擲骰子為例子來開始這一章節的知識講解。比如我們擁有一個骰子,那麼每擲一次骰子的取值可能性為1、2、3、4、5、6,這些取值每一次的可能性都為六分之一,因為每一次擲骰子的行為都是獨立的,第一次的結果並不影響第二次的任何行為和結果,這也叫概率的獨立性。
總結一下,它一共有兩個特點:
- 每一次事件的概率都大於等於0,如果我們用P來表示概率,用X來表示事件,其數學表示就是P(X)>=0 - 所有事件的概率的總和為1,也就是說骰子一共有6個面,我們每投擲一次骰子,一定會獲得1、2、3、4、5、6數字其中的一個,其數學表示就是∑P(Xi)=1
現在有兩個人A和B在進行某種對決,瓶子裡有兩個紅球,一個白球,從裡面隨機抽取,抽到紅球A獲勝,抽到白球B獲勝,抽完球再放進去。顯然,A獲勝的概率為2/3,在這種情況下,A能贏的次數就是一個隨機變量了,而這個隨機變數是如何分佈的呢?
假設對局3次,A能贏的次數為x,則x的值有可能是0、1、2、3中的一個,關於其分別出現的概率,我們可以用反覆試驗的概率來進行求解(這其實就是3重伯努利試驗)。
概率計算結果如下:

將x的概率分佈整理成表,並替換成二項係數如下圖:
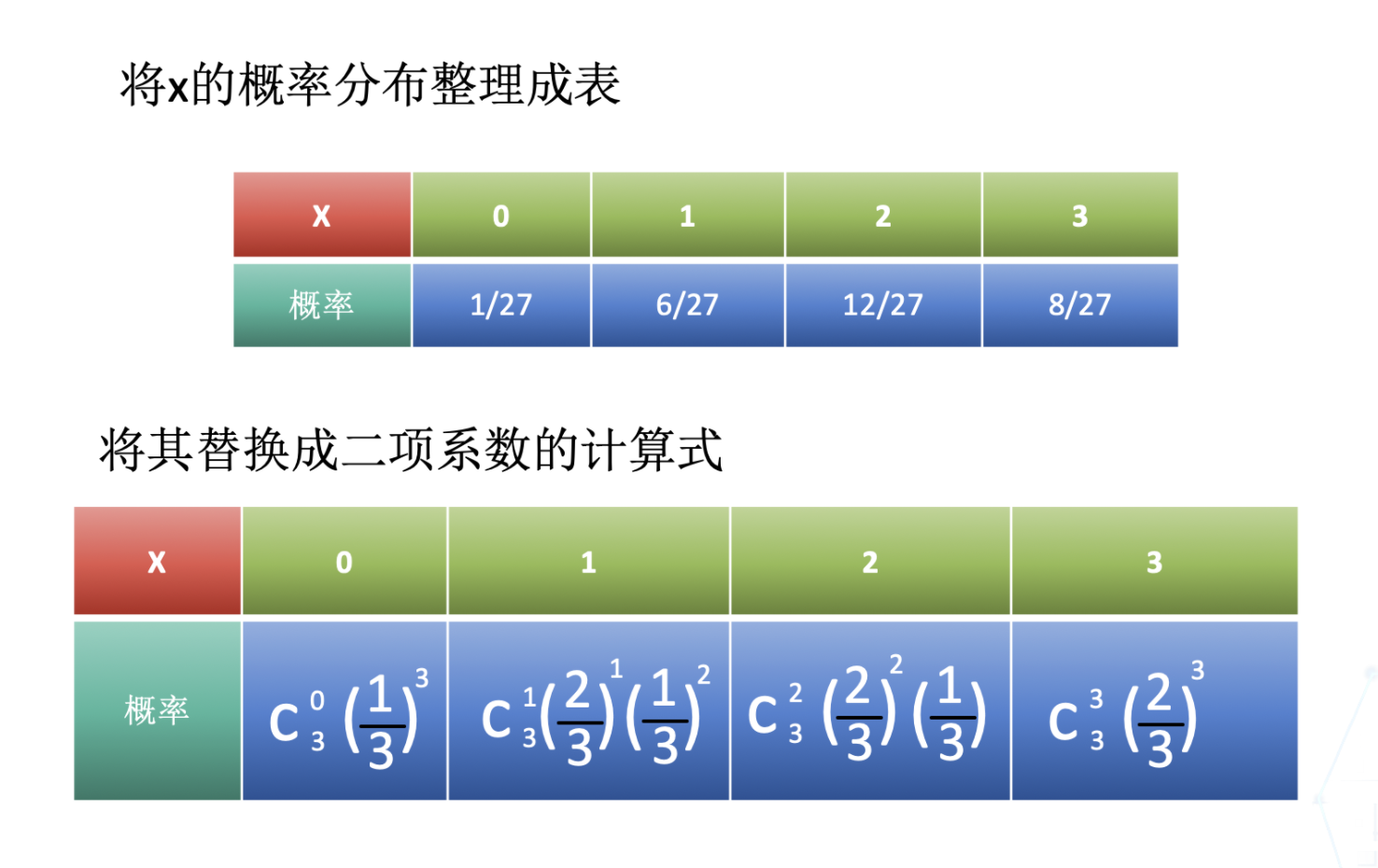
這就是二項分佈的典型例子啦。一般來說,成功概率為p的試驗,獨立重複n次後的成功次數為X的概率分佈,被稱為關於發生概率為p、次數為n的二項分佈。
這中情況下,X=k(k=0、1、2、…、n)的概率為n次重複中有k次成功(一次成功概率為p),整理後的公式如下:
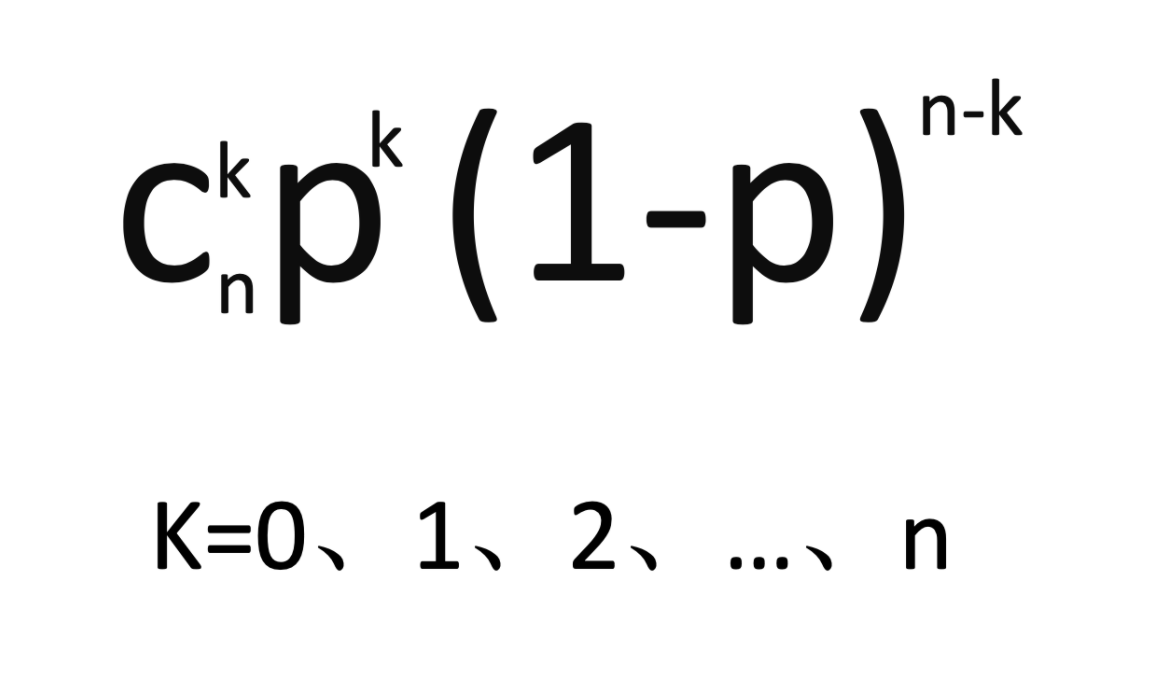
那麼二項分佈又與伯努利分佈是什麼樣的關係呢?看著好像感覺有一些相似的地方,這種結果為成功或失敗,勝或負等,結果是二選一的試驗,被稱為伯努利試驗。在伯努利試驗中,已知其中一個結果發生的概率(多數取成功的概率)時,此伯努利試驗重複n次(也叫n重伯努利試驗)時,其事件發生的次數(成功次數)遵循二項分佈。如果二項分佈中的試驗次數變成了1次,那麼這就叫做伯努利試驗了,其隨機變數是服從二項分佈的。所以伯努利分佈是二項分佈在n=1時的特例,這就是它們的關係了。
最後總結一下二項分佈,如下圖:
 ### 八 條件概率 現在假設我們有兩個事件,事件A和事件B。當事件B發生時,事件A發生的概率,這就是條件概率的理解。條件概率公式是:
**P(A|B) = P(A∩B)÷P(B)**
**
這個公式看似有點抽象,但如果我們把它變形為** P(B) * P(A|B) = P(A∩B),**就很好理解,P(B)表示事件B發生的概率,確定了事件B發生的概率再乘以P(A|B)自然就是事件A和事件B同時發生的概率。P(A|B)就是事件B發生時事件A發生的概率,P(A∩B)指的是事件A和事件B同時發生的概率。 同理,可得: **P(B|A) = P(A∩B)÷P(A)**
**
把兩個公式變形:
**P(A∩B) = P(B) * P(A|B)**
** P(A∩B) = P(A) * P(B|A) **
即可推匯出:
**P(A|B) = P(B|A) * P(A) / P(B)**
**
這就是簡單貝葉斯公式和它的推導過程,貝葉斯定理在人工智慧領域可是非常重要的知識點,未來你會學到很多貝葉斯模型的,比如高斯貝葉斯、多項式貝葉斯、伯努利貝葉斯等等的分類器。
練習: > 現在假設一天之中,我餓了的概率是10%,我餓了並且在吃飯的概率是50%,我吃飯的概率是40% > 問:我吃飯的時候餓了的概率。
把我餓了看作事件A,則P(A) = 10%,把我吃飯的概率看作事件B,則P(B) = 40%,已知P(B|A) = 50%,則P(A|B) = P(B|A) * P(A) / P(B) = 0.5 * 0.1 / 0.4 = 12.5% ### 九 全概率 全概率可是概率論中非常重要的知識點,也關係著後邊我們對貝葉斯定理進行深入的推導。那麼什麼又是全概率呢?
先從一個故事開始講解一下,拿上班的道路選擇舉例說明吧。 > 我每天上班一共有4條路可以選擇,我們現在把這4條路編成號碼,分別是1號路到4號路。我每天會選擇不同的路進行上班,來碰一下自己運氣。現在我每天選擇1號路上班的概率是20%,2號路的概率是30%,3號路的概率是10%,4號路的概率是40%。但是北京的路很糟糕,尤其是上班的高峰期,每一條路都有可能擁堵。現在1號路堵的概率為30%,2號路堵的概率是40%,3號路堵的概率是50%,4號路堵的概率是25%。一旦發生擁堵的情況我一定會遲到,現在來求一下我上班不遲到的概率。 這道題目首先要理解的就是如果我想要上班不遲到,那麼路上就不能遇到擁堵的情況,也就是我們現在要把擁堵的概率,轉換成為不擁堵的概率。那麼對應的把擁堵的概率換算成不擁堵的概率就是1號路不堵的概率為70%,2號路不堵的概率是60%,3號路不堵的概率是50%,4號路堵的不概率是75%。換算完成後,下一步就是計算出我選擇了其中一條路,並且這條路沒有發生擁堵的概率。
首先我選擇1號路的概率是20%,也就是0.2,並且1號路不擁堵的概率為70%,就是0.7,那麼這件事情發生的概率就是0.2*0.7,結果等於0.14。這裡有兩個事件,事件A是我選擇了1號路,事件B是1號路不擁堵,那麼可以用P(AB)來進行概率的表示。也就是P(AB)=0.14,當我選擇了1號路,並且一號路不擁堵的概率是0.14。我選擇2號路的概率是0.3,2號路不擁堵的概率是0.6,這個時候我把事件A當做是2號路不擁堵,事件B當做是我選擇了2號路,那麼就可以寫成P(AB)=0.18。那麼現在我們來看一下我選擇了3號路,並且3號路不堵的概率吧,就是0.1*0.5 = 0.05。同理,我選擇了4號路,並且4號路不堵的概率是0.4*0.75 = 0.3。那麼最終我上班不遲到的概率就是0.14+0.18+0.05+0.3=0.67。
以上就是全概率的計算過程。我們來總結一下全概率公式。這裡我們把上班不遲到的這件事情叫做事件A,它可以表示為P(A)。選擇上班路線的事件叫做事件B,那麼4條路的選擇概率分別可以表示為P(B1)=0.2、P(B2)=0.3、P(B3)=0.1、P(B4)=0.4。那麼分別對應著4條路,並且選擇後它們不堵的概率可以表示為P(A|B1)=0.7、P(A|B2)=0.6、P(A|B3)=0.5、P(A|B4)=0.75。 也就是說,我上班不遲到的全概率的計算方法就是
**P(A)=P(A|B1)P(B1)+P(A|B2)P(B21)+P(A|B3)P(B3)+P(A|B4)P(B4)**
**
以上只有4種情況的發生,那麼針對於n中情況的全概率公式,我們可以這樣寫P(A)=P(A|B1)P(B1) + P(A|B2)P(B2) + ... + P(A|Bn)P(Bn),進一步簡化公式,用求和符號Σ(西格瑪)來進行表示就是: 
以上這就是全概率公式和他的推導過程。 ### 十 貝葉斯定理 上面的章節我們分別學習了簡單貝葉斯公式和全概率公式,現在我們把全概率公式A和B做一個互換,可得:

把現在的P(B)帶入到簡單貝葉斯公式中,並替換P(B),可得:

這個最終的公式就叫做貝葉斯定理,下面我們用一個經典的題目來練習一下。
> 有一種疾病,發病率為千分之一。目前的基因檢測技術,只要發病了就一定能夠檢測到。但如果沒有發病的話,其誤診的概率為百分之五。這裡我們用陽性代表生病了,這是醫院裡的檢測報告的術語。現在一個人的化驗結果呈陽性(結果代表它得病了),求這個人真實患病的概率。
這道題目的解題思路是,首先我們要列出已知條件:
- 第一個已知條件是這種疾病的發病率為千分之一,那麼用可以用P(病)=0.001來表示。 - 第二個已知條件是隻要發病了就一定能夠檢測到,那麼也就是P(陽性|病)=1,也就是生病了那麼其檢測結果就是陽性,因為陽性代表著生病。 - 第三個條件是誤診率為百分之五,也就是P(陽性|健康)=0.05。
梳理清楚了三個條件,那麼問題是其化驗結果呈陽性,其真實的患病概率是多少,其實求的就是P(病|陽性)的值是多少?
1. 根據簡單貝葉斯公式來進行計算一下,也就是P(病|陽性)=P(陽性|病)P(病)/P(陽性)。 1. 進一步的把P(陽性)換算成全概率公式P(陽性)=P(病)P(陽性|病)+P(健康)P(陽性|健康)。 1. 最終得到P(病|陽性)=P(陽性|病)P(病)/(P(病)P(陽性|病)+P(健康)P(陽性|健康))
P(病|陽性) = 1 * 0.001 / (0.001 * 1 + 0.999 * 0.05) = 0.0196 = 1.96%
這一章到這裡就結束了,最後留一個小題目:垃圾郵件篩選
判斷郵件標題中包含"購買商品,不是廣告",這樣一個郵件是垃圾郵件嗎?
> 我們通過分詞技術已經把"購買商品,不是廣告"切分為4個單詞,分別是購買、商品、不是、廣告。 在已知的資料樣本中,共有36封郵件。其中的24封郵件為正常郵件,12封郵件為垃圾郵件。其中正常郵件包含"購買"這個詞的有2封,包含"商品"的郵件有4封,包含"不是"的郵件有4封,包含"廣告"的郵件有5封。 在垃圾郵件中包含"購買"這個詞的有5封,包含"商品"的郵件有3封,包含"不是"的郵件有3封,包含"廣告"的郵件有3封。注:一封郵件標題可以包含一個或多個關鍵詞。
問題:判斷一封新來的郵件,標題是"購買商品,不是廣告",是正常郵件還是垃圾郵件。
思路提示:求的就是P("購買商品,不是廣告")P("正常")的概率大還是P("購買商品,不是廣告")P("垃圾")的概率大,誰的概率大結果就是誰。
**A組 = [50,60,40,30,70,50] B組 = [40,30,40,40,100]**
為了便於理解,我們可以先使用平均數來看,它們的平均數都是50,無法比較出他們的離散程度的差異。針對這樣的情況,我們可以先把分數減去平均分進行平方運算後,再取平均值。



2ab這一項可以用排列組合的知識來理解,從(a+b)(a+b)分別選出a和b的可能性,那麼一共有兩種情況:
- 從第一個(a+b)中選出a,從第二個(a+b)選出b - 從第二個(a+b)中選出a,從第一個(a+b)中選出b
所以ab左邊的係數就是2,這個2就是二項式係數,同理:


我們從上邊的兩個例子中可以看到,無論是第一個例子中的從兩個括號中選出一個b,還是後邊的從3個括號中選出一個b(這裡我們把b作為研究物件,其實無論是誰都是一樣的)都是組合的問題,所以結合我們中學學過的知識二項係數可以總結為如下公式:

在統計學中,對於二項分佈來說,二項係數是必不可少的知識,關於二項分佈我們後邊會講到。 #### 2 用Python獲得二項係數 首先需要宣告一個函式,函式接收兩個引數,一個是n,一個是k,返回值為其二項係數的值。 ```python import itertools import numpy as np # 等待排列的陣列 arr = [1, 2, 3, 4, 5] # 排列的實現P print(list(itertools.permutations(arr, 3))) # 組合的實現C print(list(itertools.combinations(arr, 3))) # 獲取二項係數的函式 # 支援兩個引數,第一個是n,第二個是k def get_binomial_coefficient(n, k): return len(list(itertools.combinations(np.arange(n), k))) print(get_binomial_coefficient(3, 1)) ``` 使用二項式係數就可以展開(a+b)^n,所以有二項式定理,如下:
 ### 三 獨立實驗與重複實驗 > 寺廟在中國已經遍佈大江南北了,一天小王和小李二人出遊,爬山後,偶遇一寺廟,寺廟中有一個大師,善占卜。於是二人決定請大師幫忙占卜一次。大師見二人結伴而來,便問二人是占卜獨卦,還是連卦呢?二人不解,何為獨卦,何為連卦?於是大師解答到:獨卦為第一人占卜後,將卦籤放回籤桶中後,再進行第二次占卜。連卦為第一人占卜後,已抽出的卦籤不放回籤桶中,直接進行第二次占卜。 假設籤筒中,只有5根籤,其中2根是上籤,而其他3根是下籤。小王先抽籤,小王抽籤的行為記為S,小李抽籤的行為記為T。在獨卦的占卜規則下,S的結果並不影響T的結果。也就是說不管小王是否抽中上籤,小李抽中上籤的概率都是2/5。而在連卦的占卜規則下,S的結果對T的結果產生影響。因為小王抽完籤之後,並不把籤放回桶中。如果小王抽中上籤,那麼小李抽中上籤的概率就是1/4,如果小王沒有抽中上籤,那麼小李抽中上籤的概率就是2/4。在獨卦的占卜規則下,兩次抽籤行為S與T的。它們的結果互不影響,我們在統計學中稱S與T是獨立試驗。
當S與T相互獨立時,S中發生事件A和T中發生的事件B的概率P可以表示為:
**P(A∩B) = P(A) * P(B)**
顯然,在獨卦的占卜規則下,小王和小李都抽中上籤的概率是4/25。
> 現在有這樣一個場景,擲骰子的遊戲,仍然是小王和小李一起玩,每人拿3顆骰子。遊戲規則是三顆骰子每個擲一次,最後誰的點數大誰贏。這裡不管他們擲骰子多少次,每一次的結果對於其他次的結果都不會產生影響,所以他們都是相互獨立的實驗。 對於這樣反覆的獨立試驗,我們稱其為重複試驗或者叫獨立重複試驗。現在我們把擲3次骰子,每一次擲骰子時,其中2顆骰子都出現1的情況畫圖如下(X代表其他數字):

我們先來看一下第一次擲骰子的情況前兩顆骰子為1,第三顆骰子為其他數字的概率分別為1/6、1/6、5/6,因為每一次的試驗都是相互獨立的,所以發生的概率為1/6×1/6×5/6。三次擲骰子,每一次有兩顆骰子是1的情況的種類為3種,由於3種情況是互斥的(不可能同時發生),所以概率應該為3次的概率相加。也就是:3×(1/6)²×5/6。A事件和B事件相互排斥時,公式可以表示為:
**P(A∪B)=P(A)+P(B)**
根據以上試驗結果,可得重複試驗的概率公式為:

重複試驗對於下一章我們要學習的二項分佈的理解非常有幫助,所以一定要理解。如果不是特別的理解,你可以現在把上邊擲骰子的情況修改成為4顆骰子擲6次,每一次出現兩個1的情況畫圖重新按照咱們上邊的思路梳理一下,相信你就已經能夠掌握了。
練習題:
現在有5道4選1的問題。A同學對這5道題目完全不會,但在亂答的情況下,能夠答對一半以上的概率是多少,用程式碼實現一下。 ```python import itertools import numpy as np """ 題目解析:答對一半以上的情況分別為3題,4題和5題 不用考慮其順序,答對任意題目都可以,所以這是一個組合的問題 """ # 宣告一個函式來求組合問題 def get_binomial_coefficient(n, k): return len(list(itertools.combinations(np.arange(n), k))) # 每題答對的概率 P_true = 1 / 4 # 每題答錯的概率 P_false = 3 / 4 # 求答對0到5題的組合情況 # 答對0題的組合情況 zero = get_binomial_coefficient(5, 0) # 答對1題的組合情況 one = get_binomial_coefficient(5, 1) # 答對2題的組合情況 two = get_binomial_coefficient(5, 2) # 答對3題的組合情況 three = get_binomial_coefficient(5, 3) # 答對4題的組合情況 four = get_binomial_coefficient(5, 4) # 答對5題的組合情況 five = get_binomial_coefficient(5, 5) # # # 答對一半以上的概率(答對3題、4題、5題) last = three * pow(P_true, 3) * pow(P_false, 2) + four * pow(P_true, 4) * pow(P_false, 1) + five * pow(P_true, 5) * pow( P_false, 0) print(last) ``` > 學霸的世界:有一兩個不太確定的,蒙一下吧,考完了很沒信心,感覺考得不怎麼樣,結果是除了蒙的,其他的都對了,數學140分。 > > 學渣的世界:好多不會的,我感覺選這個就應該對,畢竟蒙對的經驗很豐富,感覺考得還可以,結果是會的馬虎做錯了,蒙的就對了一個,數學89分,啪啪打臉。 根據概率結果可知,亂答看似概率還不錯,但實際運算出來後概率低的可憐,所以每次亂答後,實際得分總比想象中的得分低。 ### 四 ∑符號及其意義 在以前,我們表示a1到a5的和會這樣寫:S5 = a1 + a2 + a3 + a4 + a5。同理,如果我們要表示a1到a10的和會這樣寫:S10 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + a9 + a10。如果我們要表示a1到a1000的和我們會這樣寫S1000 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + …… + a1000。但是中間的……總給人一種不好的感覺,就像我們在學習二項定理時的表達方式,總感覺特別的冗長。為了解決這個問題,我們就引入了Σ(讀西格瑪)符號,也可以叫做求和符號。像上邊的表示a1到a1000的和我們可以這樣表達:

Σ(讀西格瑪)符號在數學中非常的常見,在以後的學習中,你也幾乎可以在任意一個演算法模型中見到這個符號,所以它的特點也一定要掌握。
Σ可以使用分配率,我們一起來看一個例子:

下面我們一起來學習一下幾個關於Σ的計算公式,記住它們,以後你的計算將會非常的方便。
公式一及其證明過程如下:

公式二及其證明過程如下:

Σ的計算公式我們暫時先學習這兩個,其他的公式後邊用到的時候我們再來結合著場景進行學習。 ### 五 隨機變數 終於到了隨機變數,隨機變數後邊就是概率分佈的知識了,隨機變數在人工智慧領域中的應用非常的普遍。首先說一下隨機變數的分類,隨機變數分為離散型隨機變數和連續型隨機變數。離散型隨機變數的基本定義就是在實數範圍內取值並不連續,或者說他的取值不是一個區間,而是一些固定的值。連續型隨機變數則相反,它的取值是一個區間,在實數範圍內是連續的。
還是舉個例子比較形象,請看下面的示例: > 離散型隨機變數:一次擲20個硬幣,k個硬幣正面朝上,k是隨機變數,k的取值只能是自然數0,1,2,…,20,而不能取小數3.5、無理數√20,因而k是離散型隨機變數。 > > 連續型隨機變數:公共汽車每15分鐘一班,某人在站臺等車時間x是個隨機變數,x的取值範圍是[0,15),它是一個區間,從理論上說在這個區間內可取任一實數3.5、√20等,因而稱這隨機變數是連續型隨機變數。 ### 六 伯努利分佈 伯努利分佈也被稱為“零一分佈”或“兩點分佈”。從名字上,我們就能夠看出來,伯努利分佈中事件的發生就兩種情況。伯努利分佈指的是一次隨機試驗,結果只有兩種。生活中這樣的場景很多,拋硬幣是其中一個,我們拋一次硬幣,其結果只有正面或反面。或某一個事件的成功和失敗,病情的康復或未康復等等。
我們用字母x來表示隨機變數的取值,並且它的概率計算公式為:
**P(x=1) = p****,****P(x=0) = 1-p**
當x=1時,它的概率為p,當x-0時,它的概率為1-p,我們就稱隨機變數x服從伯努利分佈。
練習:
甲和乙,兩個人用一個均勻的硬幣來賭博,均勻的意思就是不存在作弊行為,硬幣丟擲正面和反面的概率各佔一半。硬幣丟擲正面時,甲輸給乙一塊錢,丟擲反面時,乙輸給甲一塊錢。我們來用Python實現這一過程和輸贏的總金額呈現的分佈情況。
分析:
我們用數字1來表示拋得的結果為正面,用數字-1來表示拋得的結果為反面。為了呈現出概率分佈的情況,我們需要有足夠多的人來參與這個遊戲,並且讓他們兩兩一組來進行對決。 ```python # 匯入 matplotlib庫,用來畫圖,關於畫圖我們後邊會有專門的章節進行講解 import matplotlib.pyplot as plt # 匯入numpy import numpy as np n_person = 200 n_times = 500 t = np.arange(n_times) # 建立包含1和-1兩種型別元素的隨機陣列來表示輸贏 # *2 -1 是為了隨機出1 和-1,(n_person, n_times)表示生成一個200*500的二維陣列 steps = 2 * np.random.random_integers(0, 1, (n_person, n_times)) - 1 # 計算每一組的輸贏總額 amount = np.cumsum(steps, axis=1) # 計算平方 sd_amount = amount ** 2 # 計算所有參加賭博的組的平均值 average_amount = np.sqrt(sd_amount.mean(axis=0)) print(average_amount) # 畫出資料,用綠色表示,並畫出平方根的曲線,用紅色表示 plt.plot(t, average_amount, 'g.', t, np.sqrt(t), 'r') plt.show() ``` ### 七 二項分佈 離散型隨機變數最常見的分佈就是二項分佈,我們還是以擲骰子為例子來開始這一章節的知識講解。比如我們擁有一個骰子,那麼每擲一次骰子的取值可能性為1、2、3、4、5、6,這些取值每一次的可能性都為六分之一,因為每一次擲骰子的行為都是獨立的,第一次的結果並不影響第二次的任何行為和結果,這也叫概率的獨立性。
總結一下,它一共有兩個特點:
- 每一次事件的概率都大於等於0,如果我們用P來表示概率,用X來表示事件,其數學表示就是P(X)>=0 - 所有事件的概率的總和為1,也就是說骰子一共有6個面,我們每投擲一次骰子,一定會獲得1、2、3、4、5、6數字其中的一個,其數學表示就是∑P(Xi)=1
現在有兩個人A和B在進行某種對決,瓶子裡有兩個紅球,一個白球,從裡面隨機抽取,抽到紅球A獲勝,抽到白球B獲勝,抽完球再放進去。顯然,A獲勝的概率為2/3,在這種情況下,A能贏的次數就是一個隨機變量了,而這個隨機變數是如何分佈的呢?
假設對局3次,A能贏的次數為x,則x的值有可能是0、1、2、3中的一個,關於其分別出現的概率,我們可以用反覆試驗的概率來進行求解(這其實就是3重伯努利試驗)。
概率計算結果如下:

將x的概率分佈整理成表,並替換成二項係數如下圖:

這就是二項分佈的典型例子啦。一般來說,成功概率為p的試驗,獨立重複n次後的成功次數為X的概率分佈,被稱為關於發生概率為p、次數為n的二項分佈。
這中情況下,X=k(k=0、1、2、…、n)的概率為n次重複中有k次成功(一次成功概率為p),整理後的公式如下:
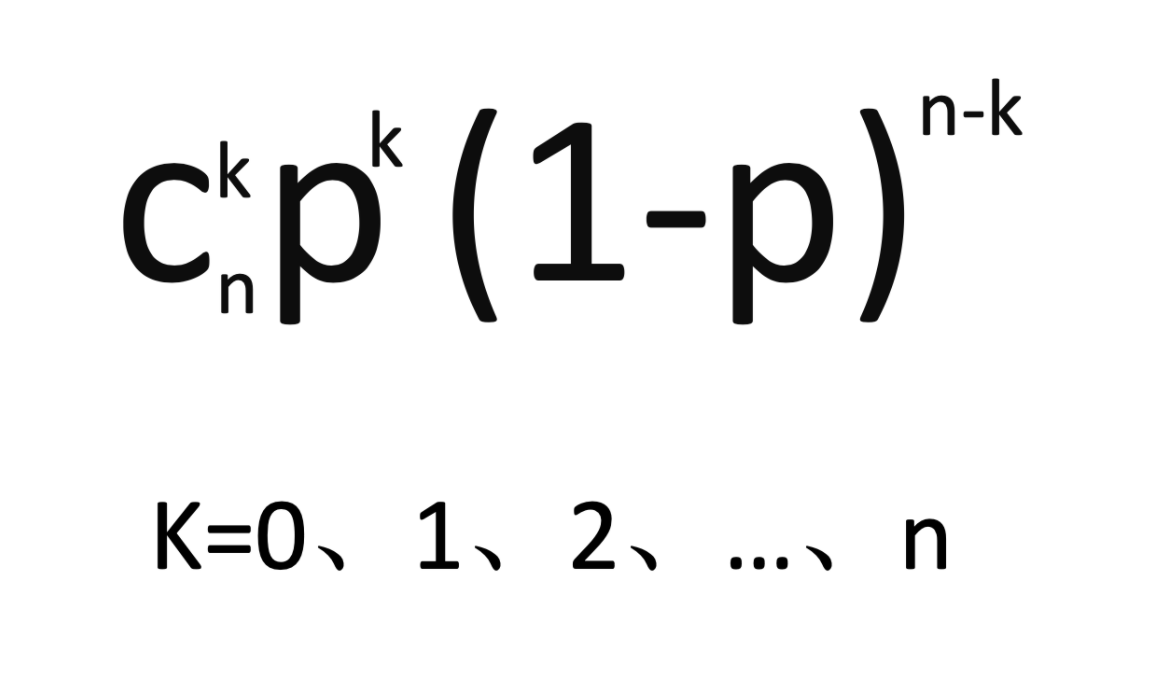
那麼二項分佈又與伯努利分佈是什麼樣的關係呢?看著好像感覺有一些相似的地方,這種結果為成功或失敗,勝或負等,結果是二選一的試驗,被稱為伯努利試驗。在伯努利試驗中,已知其中一個結果發生的概率(多數取成功的概率)時,此伯努利試驗重複n次(也叫n重伯努利試驗)時,其事件發生的次數(成功次數)遵循二項分佈。如果二項分佈中的試驗次數變成了1次,那麼這就叫做伯努利試驗了,其隨機變數是服從二項分佈的。所以伯努利分佈是二項分佈在n=1時的特例,這就是它們的關係了。
最後總結一下二項分佈,如下圖:
 ### 八 條件概率 現在假設我們有兩個事件,事件A和事件B。當事件B發生時,事件A發生的概率,這就是條件概率的理解。條件概率公式是:
**P(A|B) = P(A∩B)÷P(B)**
**
這個公式看似有點抽象,但如果我們把它變形為** P(B) * P(A|B) = P(A∩B),**就很好理解,P(B)表示事件B發生的概率,確定了事件B發生的概率再乘以P(A|B)自然就是事件A和事件B同時發生的概率。P(A|B)就是事件B發生時事件A發生的概率,P(A∩B)指的是事件A和事件B同時發生的概率。 同理,可得: **P(B|A) = P(A∩B)÷P(A)**
**
把兩個公式變形:
**P(A∩B) = P(B) * P(A|B)**
** P(A∩B) = P(A) * P(B|A) **
即可推匯出:
**P(A|B) = P(B|A) * P(A) / P(B)**
**
這就是簡單貝葉斯公式和它的推導過程,貝葉斯定理在人工智慧領域可是非常重要的知識點,未來你會學到很多貝葉斯模型的,比如高斯貝葉斯、多項式貝葉斯、伯努利貝葉斯等等的分類器。
練習: > 現在假設一天之中,我餓了的概率是10%,我餓了並且在吃飯的概率是50%,我吃飯的概率是40% > 問:我吃飯的時候餓了的概率。
把我餓了看作事件A,則P(A) = 10%,把我吃飯的概率看作事件B,則P(B) = 40%,已知P(B|A) = 50%,則P(A|B) = P(B|A) * P(A) / P(B) = 0.5 * 0.1 / 0.4 = 12.5% ### 九 全概率 全概率可是概率論中非常重要的知識點,也關係著後邊我們對貝葉斯定理進行深入的推導。那麼什麼又是全概率呢?
先從一個故事開始講解一下,拿上班的道路選擇舉例說明吧。 > 我每天上班一共有4條路可以選擇,我們現在把這4條路編成號碼,分別是1號路到4號路。我每天會選擇不同的路進行上班,來碰一下自己運氣。現在我每天選擇1號路上班的概率是20%,2號路的概率是30%,3號路的概率是10%,4號路的概率是40%。但是北京的路很糟糕,尤其是上班的高峰期,每一條路都有可能擁堵。現在1號路堵的概率為30%,2號路堵的概率是40%,3號路堵的概率是50%,4號路堵的概率是25%。一旦發生擁堵的情況我一定會遲到,現在來求一下我上班不遲到的概率。 這道題目首先要理解的就是如果我想要上班不遲到,那麼路上就不能遇到擁堵的情況,也就是我們現在要把擁堵的概率,轉換成為不擁堵的概率。那麼對應的把擁堵的概率換算成不擁堵的概率就是1號路不堵的概率為70%,2號路不堵的概率是60%,3號路不堵的概率是50%,4號路堵的不概率是75%。換算完成後,下一步就是計算出我選擇了其中一條路,並且這條路沒有發生擁堵的概率。
首先我選擇1號路的概率是20%,也就是0.2,並且1號路不擁堵的概率為70%,就是0.7,那麼這件事情發生的概率就是0.2*0.7,結果等於0.14。這裡有兩個事件,事件A是我選擇了1號路,事件B是1號路不擁堵,那麼可以用P(AB)來進行概率的表示。也就是P(AB)=0.14,當我選擇了1號路,並且一號路不擁堵的概率是0.14。我選擇2號路的概率是0.3,2號路不擁堵的概率是0.6,這個時候我把事件A當做是2號路不擁堵,事件B當做是我選擇了2號路,那麼就可以寫成P(AB)=0.18。那麼現在我們來看一下我選擇了3號路,並且3號路不堵的概率吧,就是0.1*0.5 = 0.05。同理,我選擇了4號路,並且4號路不堵的概率是0.4*0.75 = 0.3。那麼最終我上班不遲到的概率就是0.14+0.18+0.05+0.3=0.67。
以上就是全概率的計算過程。我們來總結一下全概率公式。這裡我們把上班不遲到的這件事情叫做事件A,它可以表示為P(A)。選擇上班路線的事件叫做事件B,那麼4條路的選擇概率分別可以表示為P(B1)=0.2、P(B2)=0.3、P(B3)=0.1、P(B4)=0.4。那麼分別對應著4條路,並且選擇後它們不堵的概率可以表示為P(A|B1)=0.7、P(A|B2)=0.6、P(A|B3)=0.5、P(A|B4)=0.75。 也就是說,我上班不遲到的全概率的計算方法就是
**P(A)=P(A|B1)P(B1)+P(A|B2)P(B21)+P(A|B3)P(B3)+P(A|B4)P(B4)**
**
以上只有4種情況的發生,那麼針對於n中情況的全概率公式,我們可以這樣寫P(A)=P(A|B1)P(B1) + P(A|B2)P(B2) + ... + P(A|Bn)P(Bn),進一步簡化公式,用求和符號Σ(西格瑪)來進行表示就是: 
以上這就是全概率公式和他的推導過程。 ### 十 貝葉斯定理 上面的章節我們分別學習了簡單貝葉斯公式和全概率公式,現在我們把全概率公式A和B做一個互換,可得:

把現在的P(B)帶入到簡單貝葉斯公式中,並替換P(B),可得:

這個最終的公式就叫做貝葉斯定理,下面我們用一個經典的題目來練習一下。
> 有一種疾病,發病率為千分之一。目前的基因檢測技術,只要發病了就一定能夠檢測到。但如果沒有發病的話,其誤診的概率為百分之五。這裡我們用陽性代表生病了,這是醫院裡的檢測報告的術語。現在一個人的化驗結果呈陽性(結果代表它得病了),求這個人真實患病的概率。
這道題目的解題思路是,首先我們要列出已知條件:
- 第一個已知條件是這種疾病的發病率為千分之一,那麼用可以用P(病)=0.001來表示。 - 第二個已知條件是隻要發病了就一定能夠檢測到,那麼也就是P(陽性|病)=1,也就是生病了那麼其檢測結果就是陽性,因為陽性代表著生病。 - 第三個條件是誤診率為百分之五,也就是P(陽性|健康)=0.05。
梳理清楚了三個條件,那麼問題是其化驗結果呈陽性,其真實的患病概率是多少,其實求的就是P(病|陽性)的值是多少?
1. 根據簡單貝葉斯公式來進行計算一下,也就是P(病|陽性)=P(陽性|病)P(病)/P(陽性)。 1. 進一步的把P(陽性)換算成全概率公式P(陽性)=P(病)P(陽性|病)+P(健康)P(陽性|健康)。 1. 最終得到P(病|陽性)=P(陽性|病)P(病)/(P(病)P(陽性|病)+P(健康)P(陽性|健康))
P(病|陽性) = 1 * 0.001 / (0.001 * 1 + 0.999 * 0.05) = 0.0196 = 1.96%
這一章到這裡就結束了,最後留一個小題目:垃圾郵件篩選
判斷郵件標題中包含"購買商品,不是廣告",這樣一個郵件是垃圾郵件嗎?
> 我們通過分詞技術已經把"購買商品,不是廣告"切分為4個單詞,分別是購買、商品、不是、廣告。 在已知的資料樣本中,共有36封郵件。其中的24封郵件為正常郵件,12封郵件為垃圾郵件。其中正常郵件包含"購買"這個詞的有2封,包含"商品"的郵件有4封,包含"不是"的郵件有4封,包含"廣告"的郵件有5封。 在垃圾郵件中包含"購買"這個詞的有5封,包含"商品"的郵件有3封,包含"不是"的郵件有3封,包含"廣告"的郵件有3封。注:一封郵件標題可以包含一個或多個關鍵詞。
問題:判斷一封新來的郵件,標題是"購買商品,不是廣告",是正常郵件還是垃圾郵件。
思路提示:求的就是P("購買商品,不是廣告")P("正常")的概率大還是P("購買商品,不是廣告")P("垃圾")的概率大,誰的概率大結果就是誰。