
jinja2快速實現自定義的robotframework的測試報告
阿新 • • 發佈:2020-09-07
#### 一、背景
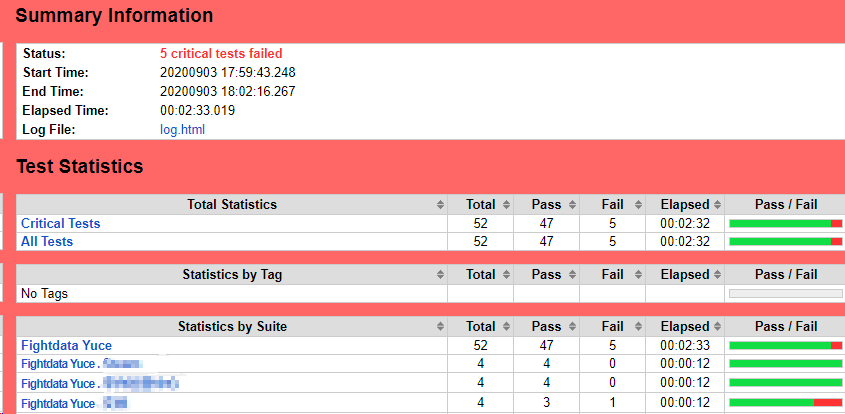
RF的結果報告可以方便我們檢視每一條用例集、用例的執行結果統計,但是有的專案涉及到一些資料的比對,希望能夠直觀到看到資料,原生的測試報告就無法滿足這個需求了。
- 原生的報告
- 專案需求報告格式 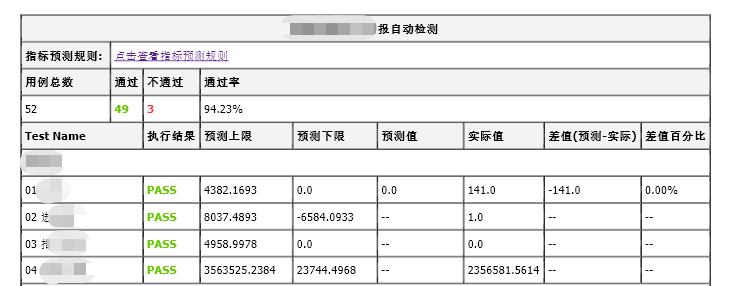
#### 二、解決方案 ##### 2.1 流程圖  - 解析output.xml,將用例的相關資訊和執行結果獲取 - 通過API和資料庫獲取需要展示的資料 - 將上述兩步的資料封裝到一個數據列表中,方便後面進行模板渲染 - 根據需求畫HTML的報告模板 - 對模板進行資料填充渲染,生成報告檔案 - 郵件傳送報告 ##### 2.2 output.xml解析 測試用例相關的資訊和執行結果,我們可以通過解析RF的output.xml檔案來進行獲取 ###### 2.2.1獲取用例執行情況的統計  ``` import xml.dom.minidom import xml.etree.ElementTree # 開啟xml文件 dom = xml.dom.minidom.parse('E:\\robot\\fightdata_yuce\\results\\output.xml') root2 = xml.etree.ElementTree.parse('E:\\robot\\fightdata_yuce\\results\\output.xml') # 得到文件元素物件 root = dom.documentElement total = root.getElementsByTagName('total'); total_len = len(total) # total的stat節點個數 total2 = root2.getiterator("total") total_stat_num = len(total2[total_len-1].getchildren()) statlist = root.getElementsByTagName('stat'); def get_total_statistics(): list = [] for i in range(0,total_stat_num): d = dict() d['fail'] = int(statlist[i].getAttribute("fail"))#失敗用例數 d['pass'] = int(statlist[i].getAttribute("pass"))#成功用例數 d['total'] = d['fail']+d['pass']#用例總數 d['percent'] = ('{:.2%}'.format(d['pass'] / d['total']))#用例百分比 list.append(d) return list ``` ###### 2.2.2 獲取用例資訊 - 用例的組織結構 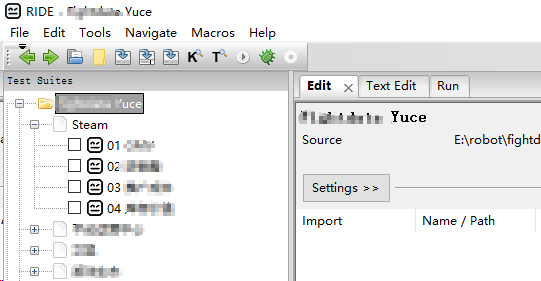 - 獲取用例資訊和執行結果 用例結構是多個suite,每個suite下有4條case  ``` import xml.dom.minidom import xml.etree.ElementTree # 開啟xml文件 dom = xml.dom.minidom.parse('E:\\robot\\xxx\\results\\output.xml') root2 = xml.etree.ElementTree.parse('E:\\robot\\xxx\\results\\output.xml') tree3=root2.getroot() # 獲取suite下的子節點 def getcase(): casedict = {} testlist2 = [] for elem in tree3.iterfind('suite/suite'): a = elem.attrib suitedict = {} testlist2.append(suitedict) #每一個用例集合存入列表 testlist = [] suitename = a['name']#獲取用例結合的名字 for test in elem.iter(tag='test'): b=test.attrib for data in test.iterfind('status'): casename = b['name'] #獲取用例的名字 c=data.attrib status=c['status'] #獲取每條用例的執行結果 casedict['casename'] = casename #用例名字存入字典 casedict['status'] = status #用例執行結果存入字典 testlist.append(casedict) #每一條用例的名字和執行結果作為字典存入列表 casedict = {} suitedict['suitename']=suitename suitedict['test']=testlist return testlist2 #最終返回的就是[{'suitename': 'xxx', 'test': [{'casename': '01 xxx', 'status': 'PASS'}, #{'casename': '02 xxx', 'status': 'PASS'} ``` ##### 2.3 資料填充 通過前面獲取的獲取,填充到jinja2的模板中,會生成另外一個有資料的html檔案 ``` from jinja2 import Environment, FileSystemLoader import parsexml def generate_html(data): env = Environment(loader=FileSystemLoader('./')) # 載入模板 template = env.get_template('report.html') # template.stream(body).dump('result.html', 'utf-8') data=parsexml.get_total_statistics()#獲取解析的xml的用例統計資料 data2=parsexml.getcase()#獲取測試用例資訊和執行結果 with open("result.html", 'w',encoding='utf-8') as fout: html_content = template.render(data=data,data2=data2) fout.write(html_content) # 寫入模板 生成html ``` ##### 2.4 jinja2模板介紹 jinja2模板的原理就是,通過先建立一個html的模板檔案,然後將資料渲染到模板檔案,生成一個渲染後的html檔案,該檔案會顯示填充的資料 ```戰娃利潤中心指標自動化測試報告
```
##### 2.5 傳送郵件
將上述渲染生成的有資料的html檔案作為測試報告進行郵件傳送
```
# !/usr/bin/python
# -*- coding: utf-8 -*-
import smtplib, time, os
from email.mime.text import MIMEText
from email.header import Header
import generate
def send_mail_html(file):
sender = '[email protected]' #發件人
mail_to =['[email protected]','[email protected]] #收件人
t = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) #獲取當前時間
subject = '戰娃利潤中心指標自動化測試報告' + t #郵件主題
smtpserver = 'smtp.qiye.aliyun.com' #傳送伺服器地址
username = '[email protected]' #使用者名稱
password = '123456' #密碼
f = open(file, 'rb')
mail_body = f.read()
f.close()
msg = MIMEText(mail_body, _subtype='html', _charset='utf-8')
msg['Subject'] = Header(subject, 'utf-8')
msg['From'] = sender
msg['To'] = ";".join(mail_to)
try:
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(username, password)
smtp.sendmail(sender, mail_to, msg.as_string())
except:
print("郵件傳送失敗!")
else:
print("郵件傳送成功!")
finally:
smtp.quit()
def result():
file = 'result.html' #渲染後的html報告檔案
result = {}
generate.generate_html(result)
send_mail_html(file)
```
郵件展示結果
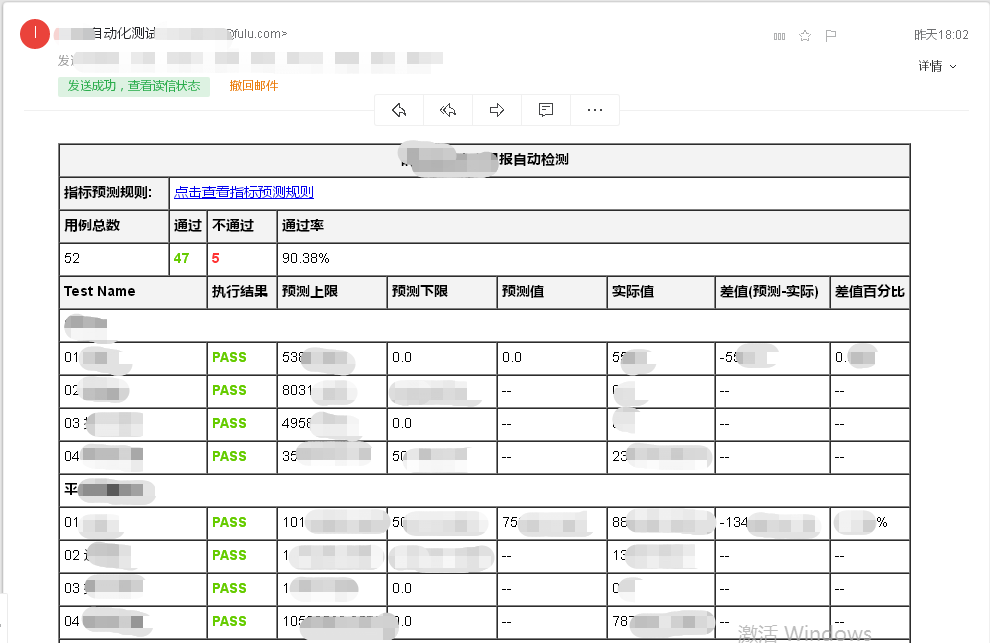
#### 三、回顧整個實現過程
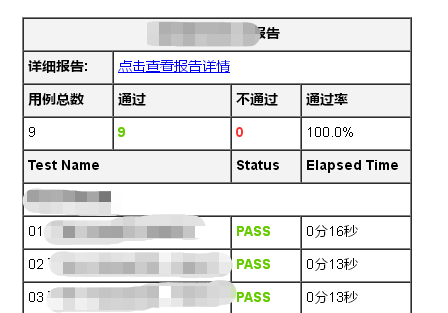
在當初接到該需求的時候,嘗試在網上找相關的實現方案,其中jenkins自帶的RF的外掛可以實現報告的解析和郵件傳送,第一版我們就是採用該報告模板進行推送
第一版報告,參考該博文https://blog.csdn.net/qq_38317509/article/details/81316940
在需要展示每條用例的具體資料資訊的時候,也是嘗試對該模板檔案進行修改取值,並查看了外掛的原始碼實現,發現無法進行這種個性化的資料的取值,原始碼只是返回了用例資訊、執行狀態和執行時間,以及失敗時候的msg,那能不能通過msg這個關鍵字來做文章呢,也就是把需要檢視的資料通過msg列印顯示出來,然而發現只有case失敗的時候才顯示用例,成功的時候不顯示,而且資料以log顯示,檢視不是那麼清晰
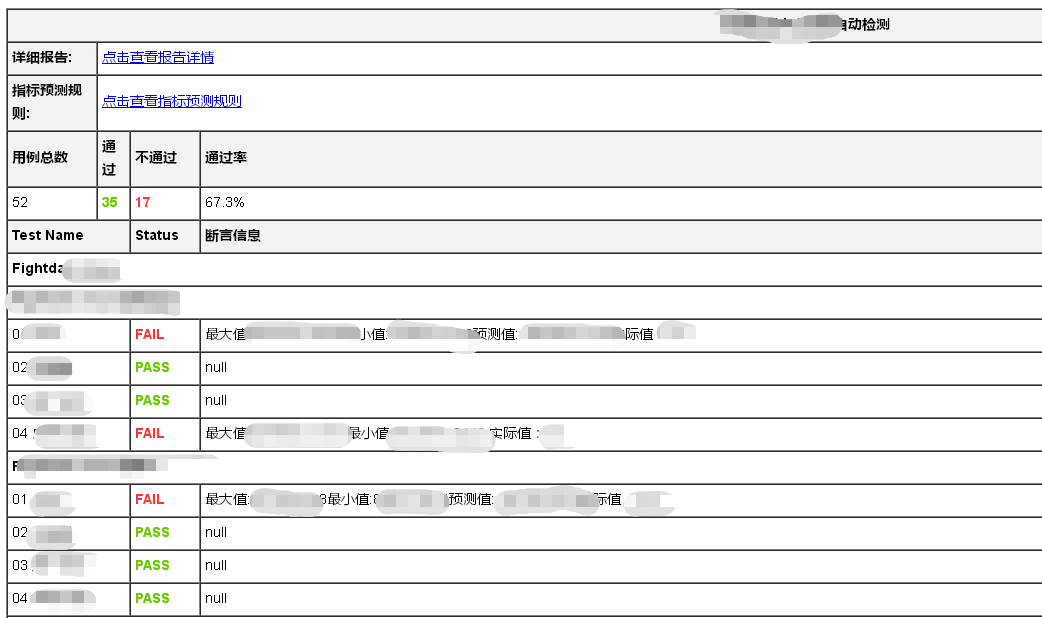
基於上述情況,發現了jinja2這個包,於是就放棄了jenkins的外掛,通過自定義報告模板,然後填充資料的方式,這樣靈活度就大大提高了,後續的個性化需求也方便去定製開發了,目前我們還是依賴jenkins進行測試任務的觸發,我們希望將RF這塊也容器化,這塊你們有相關的實踐嗎,歡迎指導~
福祿ICH·質量保證部
福小
- 專案需求報告格式 
#### 二、解決方案 ##### 2.1 流程圖  - 解析output.xml,將用例的相關資訊和執行結果獲取 - 通過API和資料庫獲取需要展示的資料 - 將上述兩步的資料封裝到一個數據列表中,方便後面進行模板渲染 - 根據需求畫HTML的報告模板 - 對模板進行資料填充渲染,生成報告檔案 - 郵件傳送報告 ##### 2.2 output.xml解析 測試用例相關的資訊和執行結果,我們可以通過解析RF的output.xml檔案來進行獲取 ###### 2.2.1獲取用例執行情況的統計  ``` import xml.dom.minidom import xml.etree.ElementTree # 開啟xml文件 dom = xml.dom.minidom.parse('E:\\robot\\fightdata_yuce\\results\\output.xml') root2 = xml.etree.ElementTree.parse('E:\\robot\\fightdata_yuce\\results\\output.xml') # 得到文件元素物件 root = dom.documentElement total = root.getElementsByTagName('total'); total_len = len(total) # total的stat節點個數 total2 = root2.getiterator("total") total_stat_num = len(total2[total_len-1].getchildren()) statlist = root.getElementsByTagName('stat'); def get_total_statistics(): list = [] for i in range(0,total_stat_num): d = dict() d['fail'] = int(statlist[i].getAttribute("fail"))#失敗用例數 d['pass'] = int(statlist[i].getAttribute("pass"))#成功用例數 d['total'] = d['fail']+d['pass']#用例總數 d['percent'] = ('{:.2%}'.format(d['pass'] / d['total']))#用例百分比 list.append(d) return list ``` ###### 2.2.2 獲取用例資訊 - 用例的組織結構  - 獲取用例資訊和執行結果 用例結構是多個suite,每個suite下有4條case  ``` import xml.dom.minidom import xml.etree.ElementTree # 開啟xml文件 dom = xml.dom.minidom.parse('E:\\robot\\xxx\\results\\output.xml') root2 = xml.etree.ElementTree.parse('E:\\robot\\xxx\\results\\output.xml') tree3=root2.getroot() # 獲取suite下的子節點 def getcase(): casedict = {} testlist2 = [] for elem in tree3.iterfind('suite/suite'): a = elem.attrib suitedict = {} testlist2.append(suitedict) #每一個用例集合存入列表 testlist = [] suitename = a['name']#獲取用例結合的名字 for test in elem.iter(tag='test'): b=test.attrib for data in test.iterfind('status'): casename = b['name'] #獲取用例的名字 c=data.attrib status=c['status'] #獲取每條用例的執行結果 casedict['casename'] = casename #用例名字存入字典 casedict['status'] = status #用例執行結果存入字典 testlist.append(casedict) #每一條用例的名字和執行結果作為字典存入列表 casedict = {} suitedict['suitename']=suitename suitedict['test']=testlist return testlist2 #最終返回的就是[{'suitename': 'xxx', 'test': [{'casename': '01 xxx', 'status': 'PASS'}, #{'casename': '02 xxx', 'status': 'PASS'} ``` ##### 2.3 資料填充 通過前面獲取的獲取,填充到jinja2的模板中,會生成另外一個有資料的html檔案 ``` from jinja2 import Environment, FileSystemLoader import parsexml def generate_html(data): env = Environment(loader=FileSystemLoader('./')) # 載入模板 template = env.get_template('report.html') # template.stream(body).dump('result.html', 'utf-8') data=parsexml.get_total_statistics()#獲取解析的xml的用例統計資料 data2=parsexml.getcase()#獲取測試用例資訊和執行結果 with open("result.html", 'w',encoding='utf-8') as fout: html_content = template.render(data=data,data2=data2) fout.write(html_content) # 寫入模板 生成html ``` ##### 2.4 jinja2模板介紹 jinja2模板的原理就是,通過先建立一個html的模板檔案,然後將資料渲染到模板檔案,生成一個渲染後的html檔案,該檔案會顯示填充的資料 ```
| 戰娃利潤中心日報自動檢測 | ||||||||||||
| 指標預測規則: | 點選檢視指標預測規則 | |||||||||||
| 用例總數 |
通過 | 不通過 | 通過率 | |||||||||
| {{data['total']}} | {{data['pass']}} | {{data['fail']}} | {{data['percent']}} | |||||||||
| Test Name | 執行結果 | 預測上限 | 預測下限 | 預測值 | 實際值 | 差值(預測-實際) | 差值百分比 | |||||
| {{data['suitename']}} | ||||||||||||
| {{c2['casename']}} | {% if c2['status']=='PASS' %}{{c2['status']}} | {% else %}{{c2['status']}} | {% endif %}{{c2['max']}} | {{c2['min']}} | {% if c2['casename']=='01 GMV' %}{{c2['yhat']}} | {% else %}-- | {% endif %}{{c2['real']}} | {% if c2['casename']=='01 GMV' %}{{c2['reduce']}} | {% else %}-- | {% endif %} {% if c2['casename']=='01 GMV' %}{{c2['percent']}} | {% else %}-- | {% endif %}|