
阿里面試官:HashMap 熟悉吧?好的,那就來聊聊 Redis 字典吧!
阿新 • • 發佈:2020-09-09
最近,小黑哥的一個朋友出去面試,回來跟小黑哥抱怨,面試官不按套路出牌,直接打亂了他的節奏。
事情是這樣的,前面面試問了幾個 Java 的相關問題,我朋友回答還不錯,接下來面試官就問了一句:看來 Java 基礎還不錯,Java HashMap 你熟悉吧?
我朋友回答。工作經常用,有看過原始碼。
我朋友本來想著,你隨便來吧,這個問題之前已經準備好了,隨便問吧。
誰知道,面試官下面一句:
**那好的,我們來聊聊 Redis 字典吧。**
直接將他整蒙逼。

小黑哥的朋友由於沒怎麼研究過 Redis 字典,所以這題就直接回答不知道了。
**當然,如果面試中真不知道,那就回答不瞭解,直接下一題,不要亂答。**
不過這一題,小黑哥覺得還是很可惜,其實 Redis 字典基本原理與 HashMap 差不多,那我們其實可以套用這其中的原理,不求回答滿分,但是怎麼也可以得個及格分吧~
面試過程真要碰到這個問題,我們可以從下面三個方面回答。
- 資料結構
- 元素增加過程
- 擴容
## 字典資料結構
說起字典,也許大家比較陌生,但是我們都知道 Redis 本身提供 KV 查詢的方式,這個 KV 就是其實通過底層就是通過字典儲存。
另外,Redis 支援多種資料型別,其中一種型別為 Hash 鍵,也可以用來儲存 KV 資料。
小黑哥剛開始瞭解的這個資料結構的時候,本來以為這個就是使用字典實現。其實並不是這樣的,初始建立 Hash 鍵,預設使用另外一種資料結構-**ZIPLIST**(壓縮列表),以此節省記憶體空間。
不過一旦以下任何條件被滿足,Hash 鍵的資料結構將會變為字典,加快查詢速度。
- 雜湊表中某個鍵或某個值的長度大於 `server.hash_max_ziplist_value` (預設值為 `64` )。
- 壓縮列表中的節點數量大於 `server.hash_max_ziplist_entries` (預設值為 `512` )。
Redis 字典新建時預設將會建立一個雜湊表陣列,儲存兩個雜湊表。
其中 `ht[0]` 雜湊表在第一次往字典中新增鍵值時分配記憶體空間,而另一個 `ht[1]` 將會在下文中擴容/縮容才會進行空間分配。
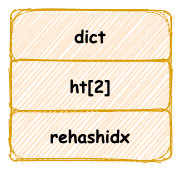
字典中雜湊表其實就等同於Java HashMap,我們知道 Java 採用陣列加連結串列/紅黑樹的實現方式,其實雜湊表也是使用類似的資料結構。
雜湊表結構如下所示:
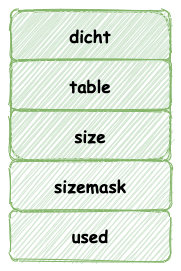
其中 `table` 屬性是個陣列, 其中陣列元素儲存一種 `dictEntry` 的結構,這個結構完全類似與 HashMap 中的 `Entry` 型別,這個結構儲存一個 KV 鍵值對。
同時,為了解決 hash 碰撞的問題,`dictEntry` 存在一個 next 指標,指向下一個`dictEntry` ,這樣就形成 `dictEntry` 的連結串列。
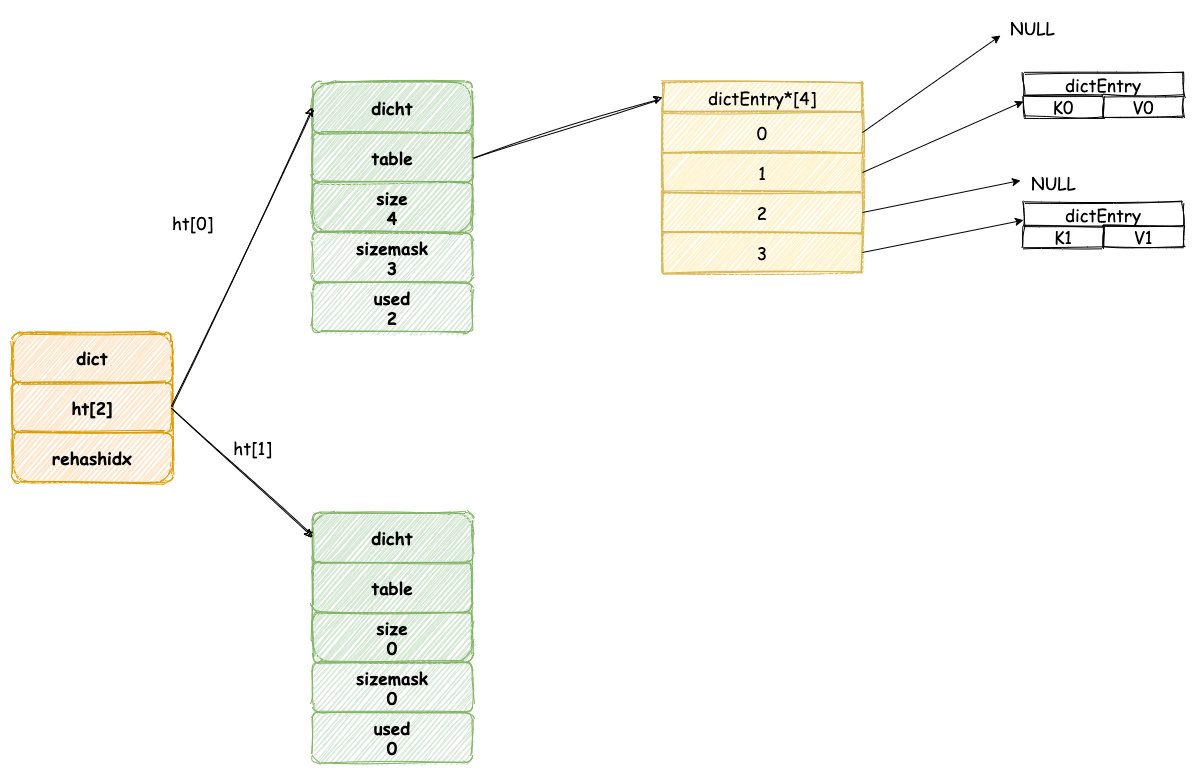
現在,我們回頭對比 Java 中 HashMap,可以發現兩者資料結構基本一致。
只不過 HashMap 為了解決連結串列過長問題導致查詢變慢,JDK1.8 時在連結串列元素過多時採用紅黑樹的資料結構。
下面我們開始新增新元素,瞭解這其中的原理。
## 元素增加過程
當我們往一個新字典中新增元素,預設將會為字典中 `ht[0]` 雜湊表分配空間,預設情況下雜湊表 table 陣列大小為 4(**DICT_HT_INITIAL_SIZE**)。
新新增元素的鍵值將會經過雜湊演算法,確定雜湊表陣列的位置,然後新增到相應的位置,如圖所示:
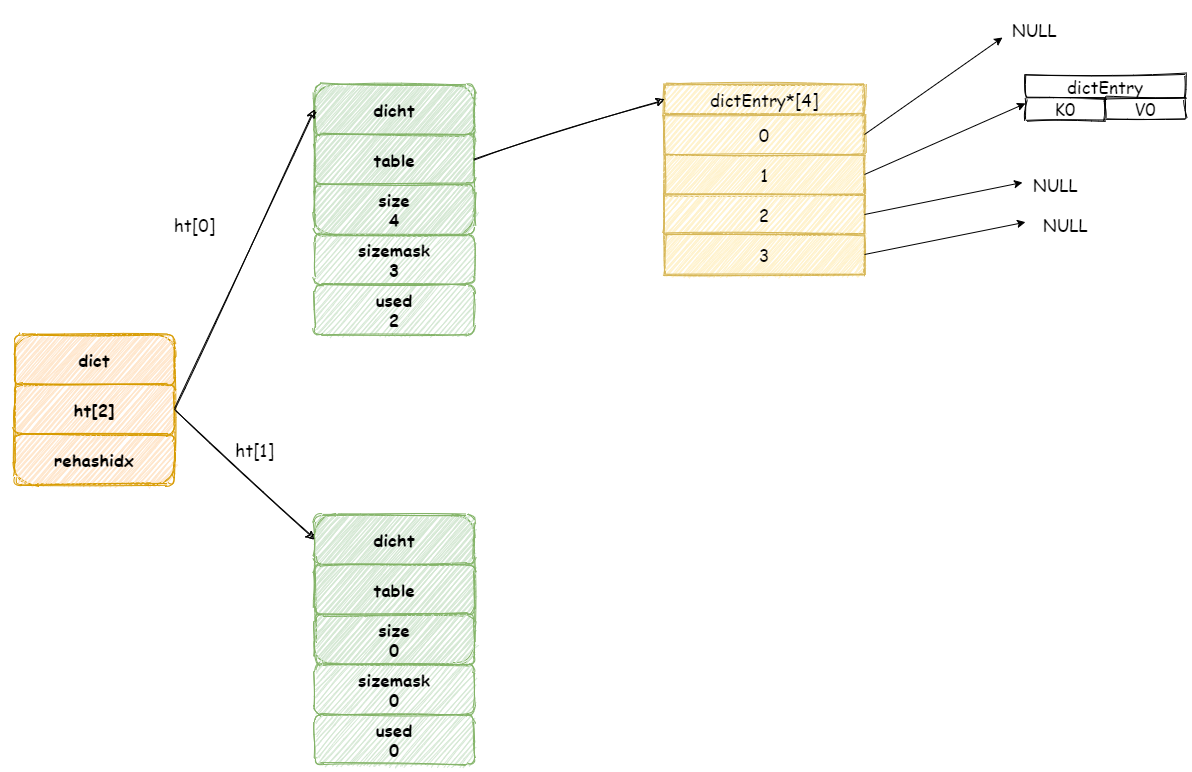
繼續增加元素,此時如果兩個不同鍵經過雜湊演算法產生相同的雜湊值,這樣就發生了雜湊碰撞。
假設現在我們雜湊表中擁有是三個元素,:
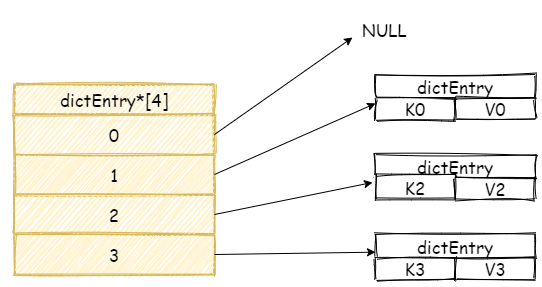
我們再增加一個新元素,如果此時剛好在陣列 3 號位置上發生碰撞,此時 Redis 將會採用連結串列的方式解決雜湊碰撞。
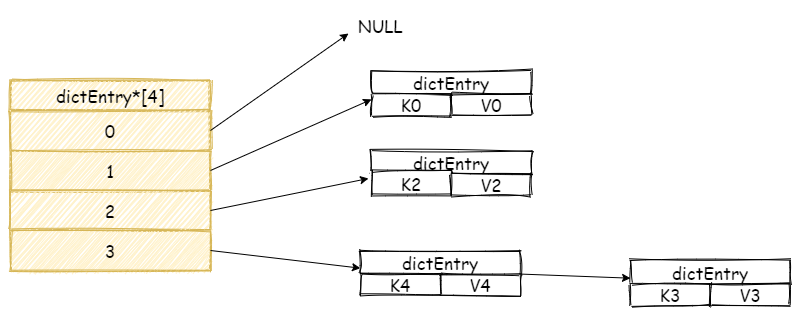
**注意,新元素將會放在連結串列頭結點,這麼做目的是因為新增加的元素,很大概率上會被再次訪問,放在頭結點增加訪問速度。**
這裡我們在對比一下元素新增過程,可以發現 Redis 流程其實與 JDK 1.7 版本的 HashMap 類似。
當我們元素增加越來越多時,雜湊碰撞情況將會越來越頻繁,這就會導致連結串列長度過長,極端情況下 O(1) 查詢效率退化成 O(N) 的查詢效率。
為此,字典必須進行擴容,這樣就會使觸發字典 rehash 操作。
## 擴容
當 Redis 進行 Rehash 擴容操作,首先將會為字典沒有用到 `ht[1]` 雜湊表分配更大空間。
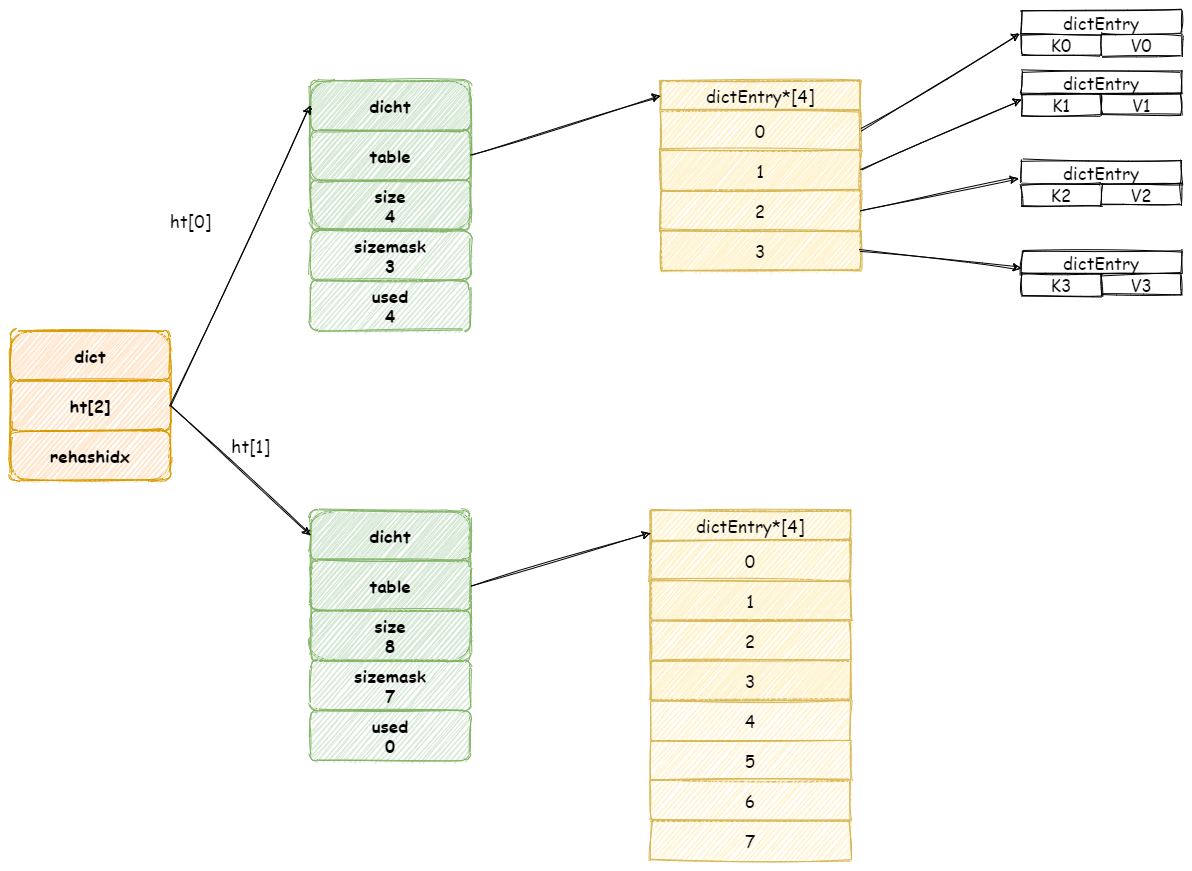
> 畫外音:`ht[1]` 雜湊表大小為第一個大於等於 `ht[0].used*2` 的 2^2(2的n 次方冪)
然後再將 `ht[0]` 中所有鍵值對都遷移到 `ht[1]` 中。
當節點全部遷移完畢,將會釋放 `ht[0]`佔用空間,並將 `ht[1]` 設定為 `ht[0]`。
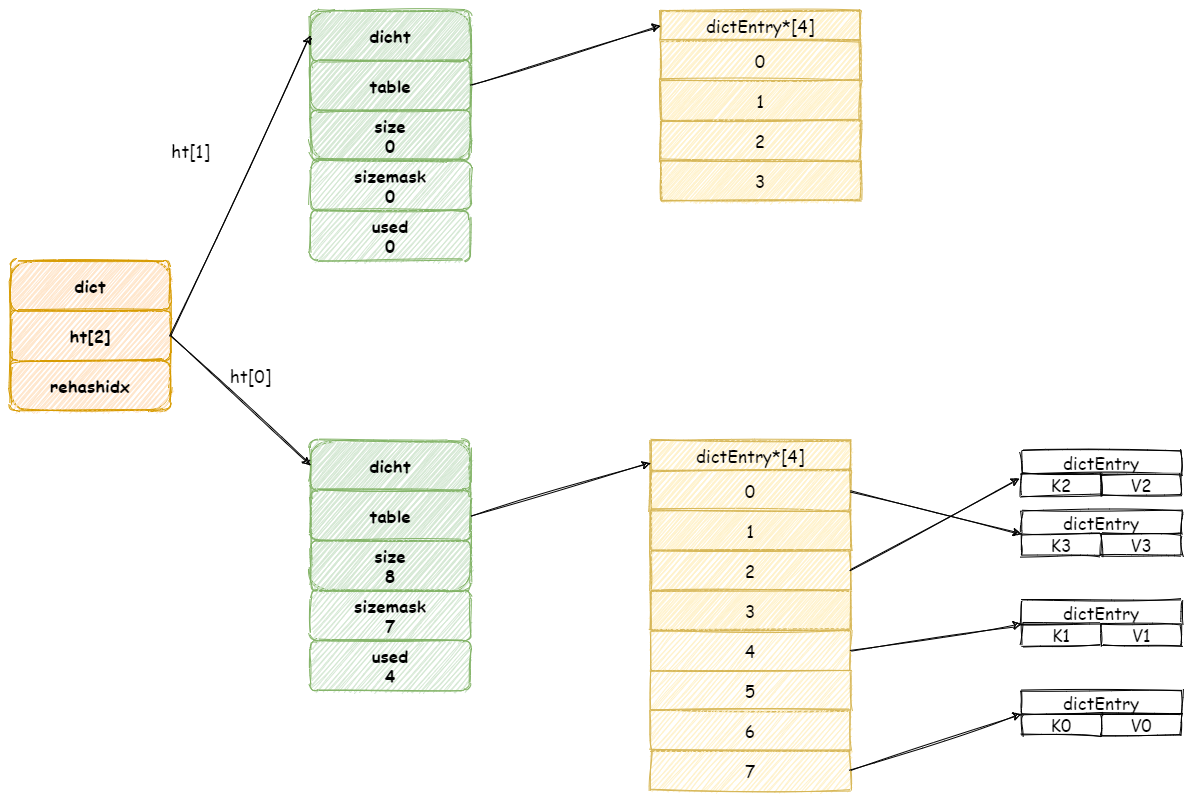
擴容 操作需要將 `ht[0]`所有鍵值對都 `Rehash` 到 `ht[1]` 中,如果鍵值過多,假設存在十億個鍵值對,這樣一次性的遷移,勢必導致伺服器會在一段時間內停止服務。
另外如果每次 `rehash` 都會阻塞當前操作,這樣對於客戶端處理非常不友好。
為了避免 `rehash`對伺服器的影響,Redis 採用漸進式的遷移方式,慢慢將資料遷移分散到多個操作步驟。
這個操作依賴字典中一個屬性 `rehashidx`,這是一個索引位置計數器,記錄下一個雜湊表 table 陣列上元素,預設情況為值為 **-1**。
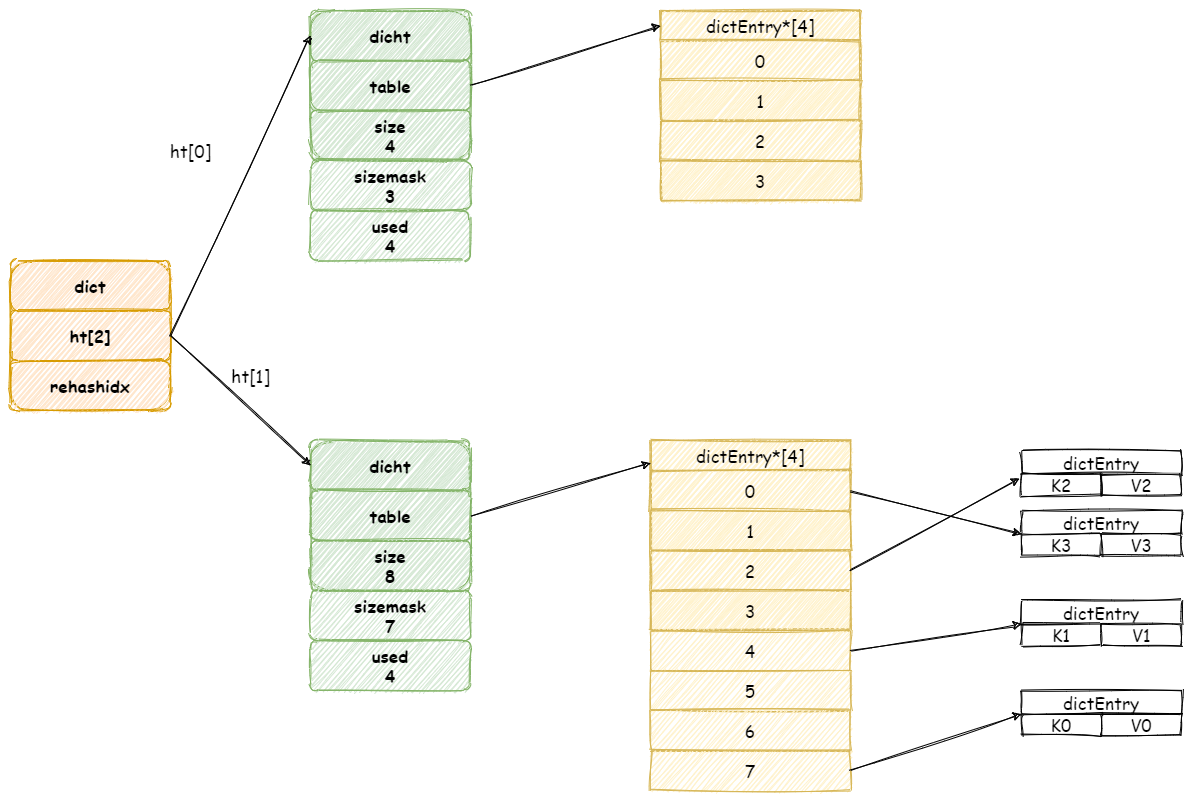
假設此時擴容前字典如圖所示:
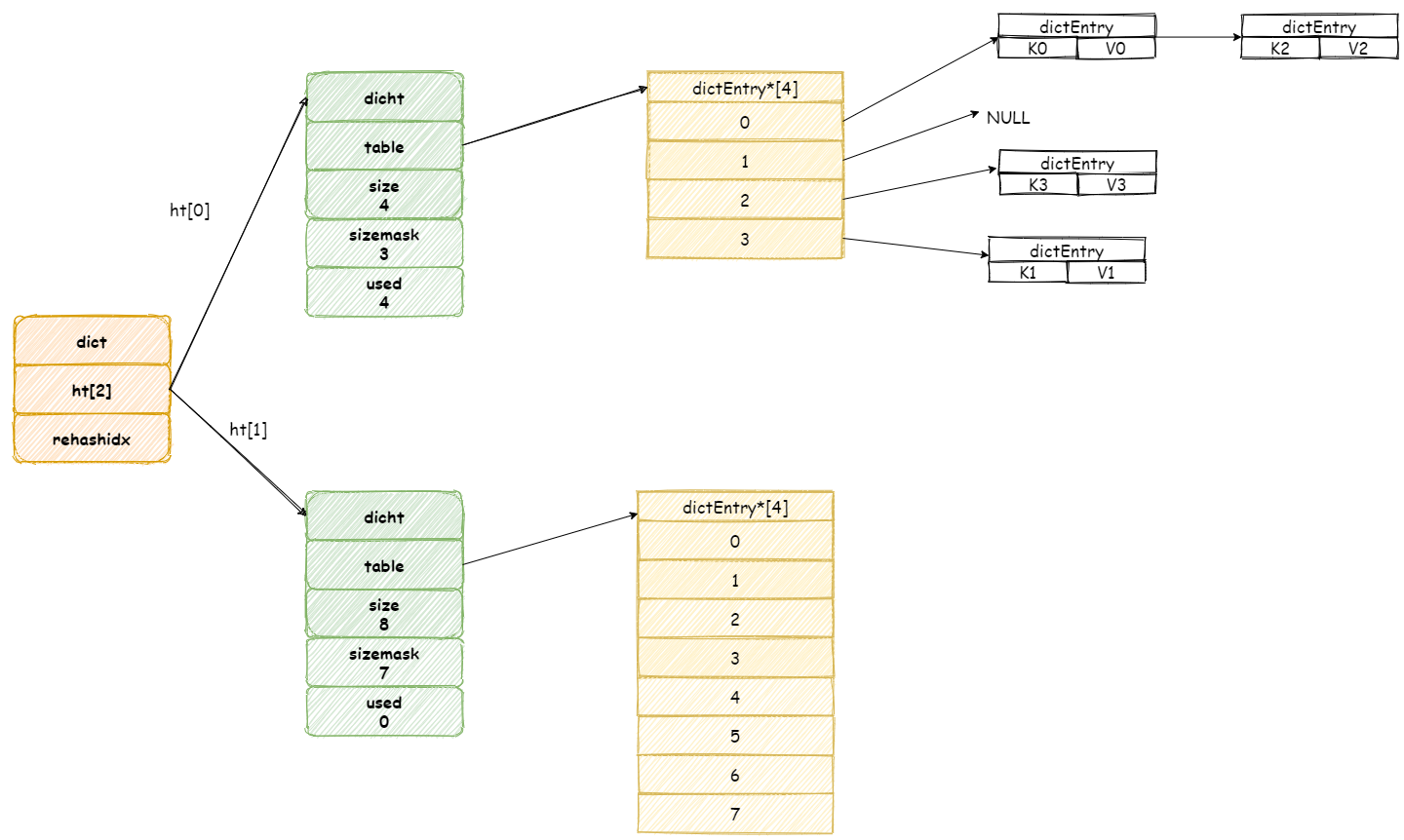
當開始 rehash 操作,`rehashidx`將會被設定為 **0** 。
這個期間每次收到增加,刪除,查詢,更新命令,除了這些命令將會被執行以外,還會順帶將 `ht[0]`雜湊表在 `rehashidx` 位置的元素 rehash 到 `ht[1]` 中。
假設此時收到一個 **K3** 鍵的查詢操作,Redis 首先執行查詢操作,接著 Redis 將會為 `ht[0]`雜湊表上` table` 陣列第 `rehashidx`索引上所有節點都遷移到 `ht[1]` 中。
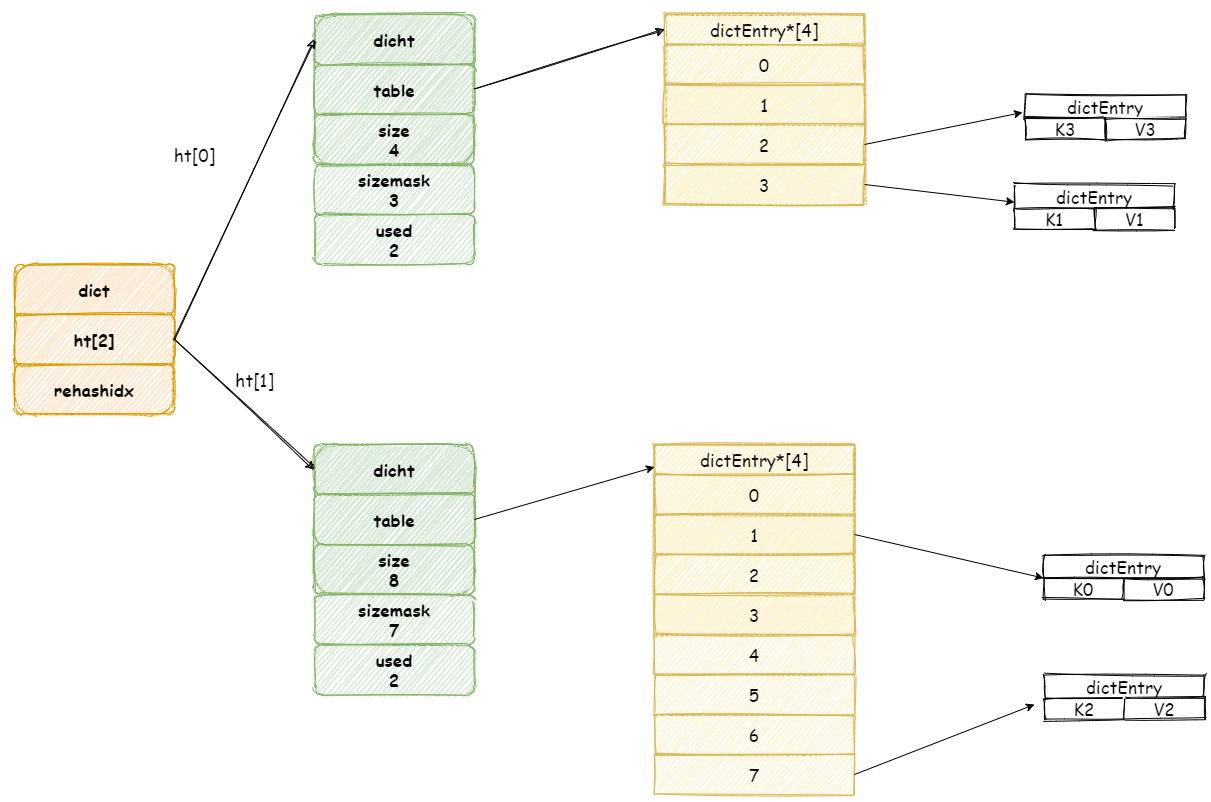
當操作完成之後,再將 `rehashidx` 屬性值加 1。
最後當所有鍵值對都 `rehash` 到 `ht[1]`中時,`rehashidx`將會被重新設定為 -1。
雖然漸進式的 rehash 操作減少了工作量,但是卻帶來鍵值操作的複雜度。
這是因為在漸進式 `rehash` 操作期間,Redis 無法明確知道鍵到底在 `ht[0]`中,還是在 `ht[1]` 中,所以這個時候 Redis 不得不查詢兩個雜湊表。
以查詢為例,Redis 首先查詢 `ht[0]` ,如果沒找到將會繼續查詢 `ht[1]`,除了查詢以外,更新,刪除也會執行如上的操作。
新增操作其實就沒這麼麻煩,因為`ht[0]`不會在使用,那就統一都新增到 `ht[1]` 中就好了。
最後我們再對比一下 Java HashMap 擴容操作,它是一個一次性操作,每次擴容需要將所有鍵值對都遷移到新的陣列中,所以如果資料量很大,消耗時間就會久。
## 總結
Redis 字典使用雜湊表作為底層實現,每個字典包含兩個雜湊表,一個平時使用,一個僅在 rehash 操作中使用。
雜湊表總的來說,跟 Java HashMap 真的很類似,底層實現也是一個數組加連結串列資料結構。
最後,當對雜湊表進行擴容操作時間,將會採用漸進性 rehash 操作,慢慢將所有鍵值對遷移到新雜湊表中。
其實瞭解 Redis 字典的其中的原理,再去比較 Java HashMap ,其實可以發現這兩者有如此多的相似點。
所以學習這類知識時,不要僅僅去背,我們要了解其底層原理,知其然知其所以然。
## 幫助資料
1. https://redisbook.readthedocs.io/en/latest/internal-datastruct/dict.html
> 歡迎關注我的公眾號:程式通事,獲得日常乾貨推送。如果您對我的專題內容感興趣,也可以關注我的部落格:[studyidea.cn](https://studyi