
java安全編碼指南之:字串和編碼
阿新 • • 發佈:2020-09-16
[toc]
# 簡介
字串是我們日常編碼過程中使用到最多的java型別了。全球各個地區的語言不同,即使使用了Unicode也會因為編碼格式的不同採用不同的編碼方式,如UTF-8,UTF-16,UTF-32等。
我們在使用字元和字串編碼的過程中會遇到哪些問題呢?一起來看看吧。
# 使用變長編碼的不完全字元來建立字串
在java中String的底層儲存char[]是以UTF-16進行編碼的。
> 注意,在JDK9之後,String的底層儲存已經變成了byte[]。
StringBuilder和StringBuffer還是使用的是char[]。
那麼當我們在使用InputStreamReader,OutputStreamWriter和String類進行String讀寫和構建的時候,就需要涉及到UTF-16和其他編碼的轉換。
我們來看一下從UTF-8轉換到UTF-16可能會遇到的問題。
先看一下UTF-8的編碼:
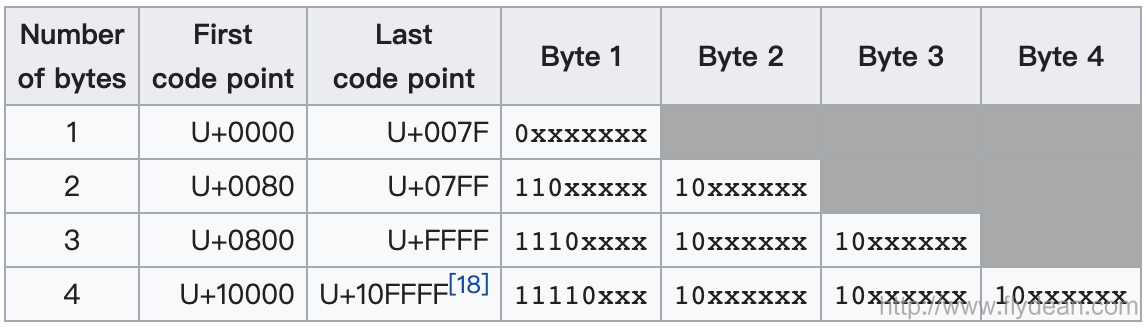
UTF-8使用1到4個位元組表示對應的字元,而UTF-16使用2個或者4個位元組來表示對應的字元。
轉換起來可能會出現什麼問題呢?
~~~java
public String readByteWrong(InputStream inputStream) throws IOException {
byte[] data = new byte[1024];
int offset = 0;
int bytesRead = 0;
String str="";
while ((bytesRead = inputStream.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, bytesRead, "UTF-8");
offset += bytesRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
~~~
上面的程式碼中,我們從Stream中讀取byte,每讀一次byte就將其轉換成為String。很明顯,UTF-8是變長的編碼,如果讀取byte的過程中,恰好讀取了部分UTF-8的程式碼,那麼構建出來的String將是錯誤的。
我們需要下面這樣操作:
~~~java
public String readByteCorrect(InputStream inputStream) throws IOException {
Reader r = new InputStreamReader(inputStream, "UTF-8");
char[] data = new char[1024];
int offset = 0;
int charRead = 0;
String str="";
while ((charRead = r.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, charRead);
offset += charRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
~~~
我們使用了InputStreamReader,reader將會自動把讀取的資料轉換成為char,也就是說自動進行UTF-8到UTF-16的轉換。
所以不會出現問題。
# char不能表示所有的Unicode
因為char是使用UTF-16來進行編碼的,對於UTF-16來說,U+0000 to U+D7FF 和 U+E000 to U+FFFF,這個範圍的字元,可以直接用一個char來表示。
但是對於U+010000 to U+10FFFF是使用兩個0xD800–0xDBFF和0xDC00–0xDFFF範圍的char來表示的。
這種情況下,兩個char合併起來才有意思,單獨一個char是沒有任何意義的。
考慮下面的我們的的一個subString的方法,該方法的本意是從輸入的字串中找到第一個非字母的位置,然後進行字串擷取。
~~~java
public static String subStringWrong(String string) {
char ch;
int i;
for (i = 0; i < string.length(); i += 1) {
ch = string.charAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
~~~
上面的例子中,我們一個一個的取出string中的char字元進行比較。如果遇到U+010000 to U+10FFFF範圍的字元,就可能報錯,誤以為該字元不是letter。
我們可以這樣修改:
~~~java
public static String subStringCorrect(String string) {
int ch;
int i;
for (i = 0; i < string.length(); i += Character.charCount(ch)) {
ch = string.codePointAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
~~~
我們使用string的codePointAt方法,來返回字串的Unicode code point,然後使用該code point來進行isLetter的判斷就好了。
# 注意Locale的使用
為了實現國際化支援,java引入了Locale的概念,而因為有了Locale,所以會導致字串在進行轉換的過程中,產生意想不到變化。
考慮下面的例子:
~~~java
public void toUpperCaseWrong(String input){
if(input.toUpperCase().equals("JOKER")){
System.out.println("match!");
}
}
~~~
我們期望的是英語,如果系統設定了Locale是其他語種的話,input.toUpperCase()可能得到完全不一樣的結果。
幸好,toUpperCase提供了一個locale的引數,我們可以這樣修改:
~~~java
public void toUpperCaseRight(String input){
if(input.toUpperCase(Locale.ENGLISH).equals("JOKER")){
System.out.println("match!");
}
}
~~~
同樣的, DateFormat也存在著問題:
~~~java
public void getDateInstanceWrong(Date date){
String myString = DateFormat.getDateInstance().format(date);
}
public void getDateInstanceRight(Date date){
String myString = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.US).format(date);
}
~~~
我們在進行字串比較的時候,一定要考慮到Locale影響。
# 檔案讀寫中的編碼格式
我們在使用InputStream和OutputStream進行檔案對寫的時候,因為是二進位制,所以不存在編碼轉換的問題。
但是如果我們使用Reader和Writer來進行檔案的物件,就需要考慮到檔案編碼的問題。
如果檔案是UTF-8編碼的,我們是用UTF-16來讀取,肯定會出問題。
考慮下面的例子:
~~~java
public void fileOperationWrong(String inputFile,String outputFile) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(inputFile));
PrintWriter writer = new PrintWriter(new FileWriter(outputFile));
int line = 0;
while (reader.ready()) {
line++;
writer.println(line + ": " + reader.readLine());
}
reader.close();
writer.close();
}
~~~
我們希望讀取原始檔,然後插入行號到新的檔案中,但是我們並沒有考慮到編碼的問題,所以可能會失敗。
上面的程式碼我們可以修改成這樣:
~~~java
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(inputFile), Charset.forName("UTF8")));
PrintWriter writer = new PrintWriter(new OutputStreamWriter(new FileOutputStream(outputFile), Charset.forName("UTF8")));
~~~
通過強制指定編碼格式,從而保證了操作的正確性。
# 不要將非字元資料編碼為字串
我們經常會有這樣的需求,就是將二進位制資料編碼成為字串String,然後儲存在資料庫中。
二進位制是以Byte來表示的,但是從我們上面的介紹可以得知不是所有的Byte都可以表示成為字元。如果將不能表示為字元的Byte進行字元的轉化,就有可能出現問題。
看下面的例子:
~~~java
public void convertBigIntegerWrong(){
BigInteger x = new BigInteger("1234567891011");
System.out.println(x);
byte[] byteArray = x.toByteArray();
String s = new String(byteArray);
byteArray = s.getBytes();
x = new BigInteger(byteArray);
System.out.println(x);
}
~~~
上面的例子中,我們將BigInteger轉換為byte數字(大端序列),然後再將byte數字轉換成為String。最後再將String轉換成為BigInteger。
先看下結果:
~~~java
1234567891011
80908592843917379
~~~
發現沒有轉換成功。
雖然String可以接收第二個引數,傳入字元編碼,目前java支援的字元編碼是:ASCII,ISO-8859-1,UTF-8,UTF-8BE, UTF-8LE,UTF-16,這幾種。預設情況下String也是大端序列的。
上面的例子怎麼修改呢?
~~~java
public void convertBigIntegerRight(){
BigInteger x = new BigInteger("1234567891011");
String s = x.toString(); //轉換成為可以儲存的字串
byte[] byteArray = s.getBytes();
String ns = new String(byteArray);
x = new BigInteger(ns);
System.out.println(x);
}
~~~
我們可以先將BigInteger用toString方法轉換成為可以表示的字串,然後再進行轉換即可。
我們還可以使用Base64來對Byte陣列進行編碼,從而不丟失任何字元,如下所示:
~~~java
public void convertBigIntegerWithBase64(){
BigInteger x = new BigInteger("1234567891011");
byte[] byteArray = x.toByteArray();
String s = Base64.getEncoder().encodeToString(byteArray);
byteArray = Base64.getDecoder().decode(s);
x = new BigInteger(byteArray);
System.out.println(x);
}
~~~
本文的程式碼:
[learn-java-base-9-to-20/tree/master/security](https://github.com/ddean2009/learn-java-base-9-to-20/tree/master/security)
>