
原來 8 張圖,就可以搞懂「零拷貝」了

前言
磁碟可以說是計算機系統最慢的硬體之一,讀寫速度相差記憶體 10 倍以上,所以針對優化磁碟的技術非常的多,比如零拷貝、直接 I/O、非同步 I/O 等等,這些優化的目的就是為了提高系統的吞吐量,另外作業系統核心中的磁碟快取記憶體區,可以有效的減少磁碟的訪問次數。
這次,我們就以「檔案傳輸」作為切入點,來分析 I/O 工作方式,以及如何優化傳輸檔案的效能。
正文
為什麼要有 DMA 技術?
在沒有 DMA 技術前,I/O 的過程是這樣的:
- CPU 發出對應的指令給磁碟控制器,然後返回;
- 磁碟控制器收到指令後,於是就開始準備資料,會把資料放入到磁碟控制器的內部緩衝區中,然後產生一箇中斷;
- CPU 收到中斷訊號後,停下手頭的工作,接著把磁碟控制器的緩衝區的資料一次一個位元組地讀進自己的暫存器,然後再把暫存器裡的資料寫入到記憶體,而在資料傳輸的期間 CPU 是無法執行其他任務的。
為了方便你理解,我畫了一副圖:

可以看到,整個資料的傳輸過程,都要需要 CPU 親自參與搬運資料的過程,而且這個過程,CPU 是不能做其他事情的。
簡單的搬運幾個字元資料那沒問題,但是如果我們用千兆網絡卡或者硬碟傳輸大量資料的時候,都用 CPU 來搬運的話,肯定忙不過來。
電腦科學家們發現了事情的嚴重性後,於是就發明了 DMA 技術,也就是直接記憶體訪問(Direct Memory Access) 技術。
什麼是 DMA 技術?簡單理解就是,在進行 I/O 裝置和記憶體的資料傳輸的時候,資料搬運的工作全部交給 DMA 控制器,而 CPU 不再參與任何與資料搬運相關的事情,這樣 CPU 就可以去處理別的事務。
那使用 DMA 控制器進行資料傳輸的過程究竟是什麼樣的呢?下面我們來具體看看。
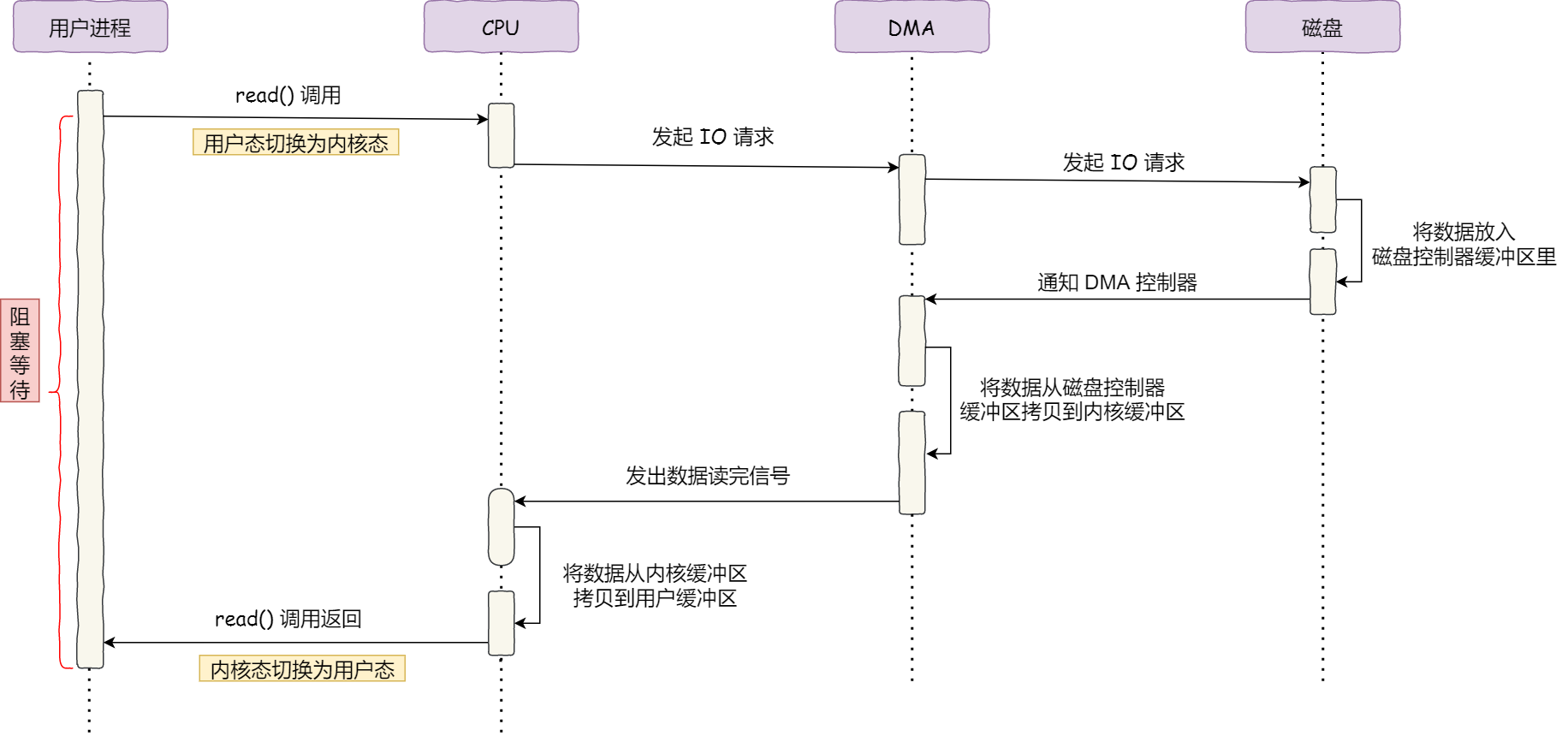
具體過程:
- 使用者程序呼叫 read 方法,向作業系統發出 I/O 請求,請求讀取資料到自己的記憶體緩衝區中,程序進入阻塞狀態;
- 作業系統收到請求後,進一步將 I/O 請求傳送 DMA,然後讓 CPU 執行其他任務;
- DMA 進一步將 I/O 請求傳送給磁碟;
- 磁碟收到 DMA 的 I/O 請求,把資料從磁碟讀取到磁碟控制器的緩衝區中,當磁碟控制器的緩衝區被讀滿後,向 DMA 發起中斷訊號,告知自己緩衝區已滿;
- DMA 收到磁碟的訊號,將磁碟控制器緩衝區中的資料拷貝到核心緩衝區中,此時不佔用 CPU,CPU 可以執行其他任務;
- 當 DMA 讀取了足夠多的資料,就會發送中斷訊號給 CPU;
- CPU 收到 DMA 的訊號,知道資料已經準備好,於是將資料從核心拷貝到使用者空間,系統呼叫返回;
可以看到, 整個資料傳輸的過程,CPU 不再參與資料搬運的工作,而是全程由 DMA 完成,但是 CPU 在這個過程中也是必不可少的,因為傳輸什麼資料,從哪裡傳輸到哪裡,都需要 CPU 來告訴 DMA 控制器。
早期 DMA 只存在在主機板上,如今由於 I/O 裝置越來越多,資料傳輸的需求也不盡相同,所以每個 I/O 裝置裡面都有自己的 DMA 控制器。
傳統的檔案傳輸有多糟糕?
如果服務端要提供檔案傳輸的功能,我們能想到的最簡單的方式是:將磁碟上的檔案讀取出來,然後通過網路協議傳送給客戶端。
傳統 I/O 的工作方式是,資料讀取和寫入是從使用者空間到核心空間來回複製,而核心空間的資料是通過作業系統層面的 I/O 介面從磁碟讀取或寫入。
程式碼通常如下,一般會需要兩個系統呼叫:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
程式碼很簡單,雖然就兩行程式碼,但是這裡面發生了不少的事情。
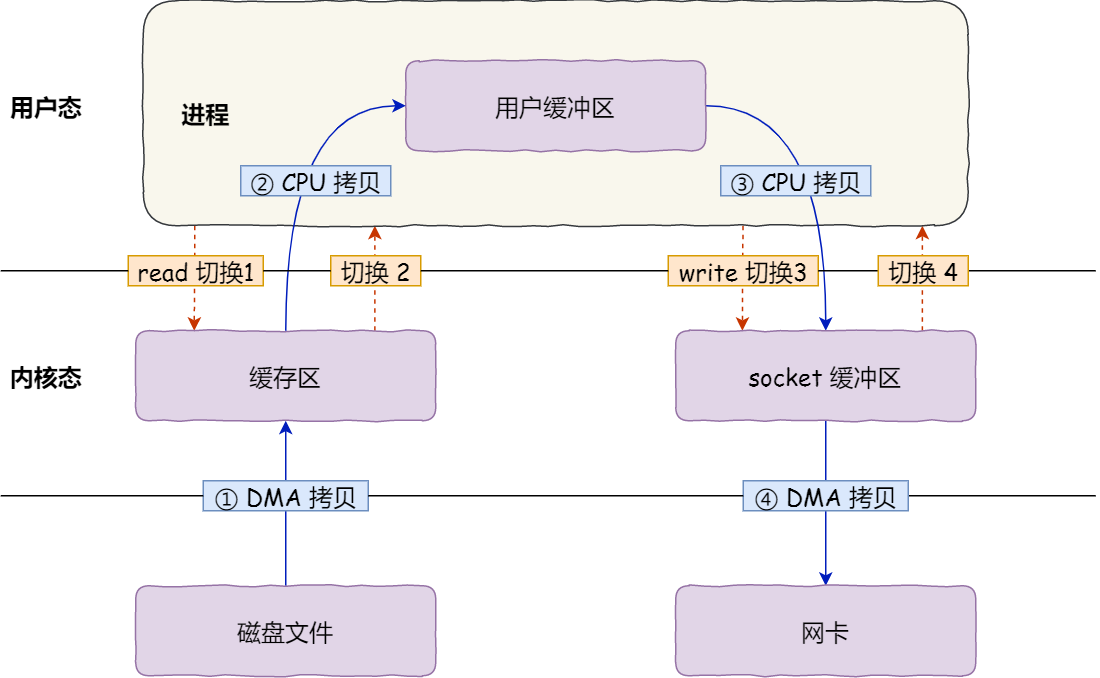
首先,期間共發生了 4 次使用者態與核心態的上下文切換,因為發生了兩次系統呼叫,一次是 read() ,一次是 write(),每次系統呼叫都得先從使用者態切換到核心態,等核心完成任務後,再從核心態切換回使用者態。
上下文切換到成本並不小,一次切換需要耗時幾十納秒到幾微秒,雖然時間看上去很短,但是在高併發的場景下,這類時間容易被累積和放大,從而影響系統的效能。
其次,還發生了 4 次資料拷貝,其中兩次是 DMA 的拷貝,另外兩次則是通過 CPU 拷貝的,下面說一下這個過程:
- 第一次拷貝,把磁碟上的資料拷貝到作業系統核心的緩衝區裡,這個拷貝的過程是通過 DMA 搬運的。
- 第二次拷貝,把核心緩衝區的資料拷貝到使用者的緩衝區裡,於是我們應用程式就可以使用這部分資料了,這個拷貝到過程是由 CPU 完成的。
- 第三次拷貝,把剛才拷貝到使用者的緩衝區裡的資料,再拷貝到核心的 socket 的緩衝區裡,這個過程依然還是由 CPU 搬運的。
- 第四次拷貝,把核心的 socket 緩衝區裡的資料,拷貝到網絡卡的緩衝區裡,這個過程又是由 DMA 搬運的。
我們回過頭看這個檔案傳輸的過程,我們只是搬運一份資料,結果卻搬運了 4 次,過多的資料拷貝無疑會消耗 CPU 資源,大大降低了系統性能。
這種簡單又傳統的檔案傳輸方式,存在冗餘的上文切換和資料拷貝,在高併發系統裡是非常糟糕的,多了很多不必要的開銷,會嚴重影響系統性能。
所以,要想提高檔案傳輸的效能,就需要減少「使用者態與核心態的上下文切換」和「記憶體拷貝」的次數。
如何優化檔案傳輸的效能?
先來看看,如何減少「使用者態與核心態的上下文切換」的次數呢?
讀取磁碟資料的時候,之所以要發生上下文切換,這是因為使用者空間沒有許可權操作磁碟或網絡卡,核心的許可權最高,這些操作裝置的過程都需要交由作業系統核心來完成,所以一般要通過核心去完成某些任務的時候,就需要使用作業系統提供的系統呼叫函式。
而一次系統呼叫必然會發生 2 次上下文切換:首先從使用者態切換到核心態,當核心執行完任務後,再切換回使用者態交由程序程式碼執行。
所以,要想減少上下文切換到次數,就要減少系統呼叫的次數。
再來看看,如何減少「資料拷貝」的次數?
在前面我們知道了,傳統的檔案傳輸方式會歷經 4 次資料拷貝,而且這裡面,「從核心的讀緩衝區拷貝到使用者的緩衝區裡,再從使用者的緩衝區裡拷貝到 socket 的緩衝區裡」,這個過程是沒有必要的。
因為檔案傳輸的應用場景中,在使用者空間我們並不會對資料「再加工」,所以資料實際上可以不用搬運到使用者空間,因此使用者的緩衝區是沒有必要存在的。
如何實現零拷貝?
零拷貝技術實現的方式通常有 2 種:
- mmap + write
- sendfile
下面就談一談,它們是如何減少「上下文切換」和「資料拷貝」的次數。
mmap + write
在前面我們知道,read() 系統呼叫的過程中會把核心緩衝區的資料拷貝到使用者的緩衝區裡,於是為了減少這一步開銷,我們可以用 mmap() 替換 read() 系統呼叫函式。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系統呼叫函式會直接把核心緩衝區裡的資料「對映」到使用者空間,這樣,作業系統核心與使用者空間就不需要再進行任何的資料拷貝操作。
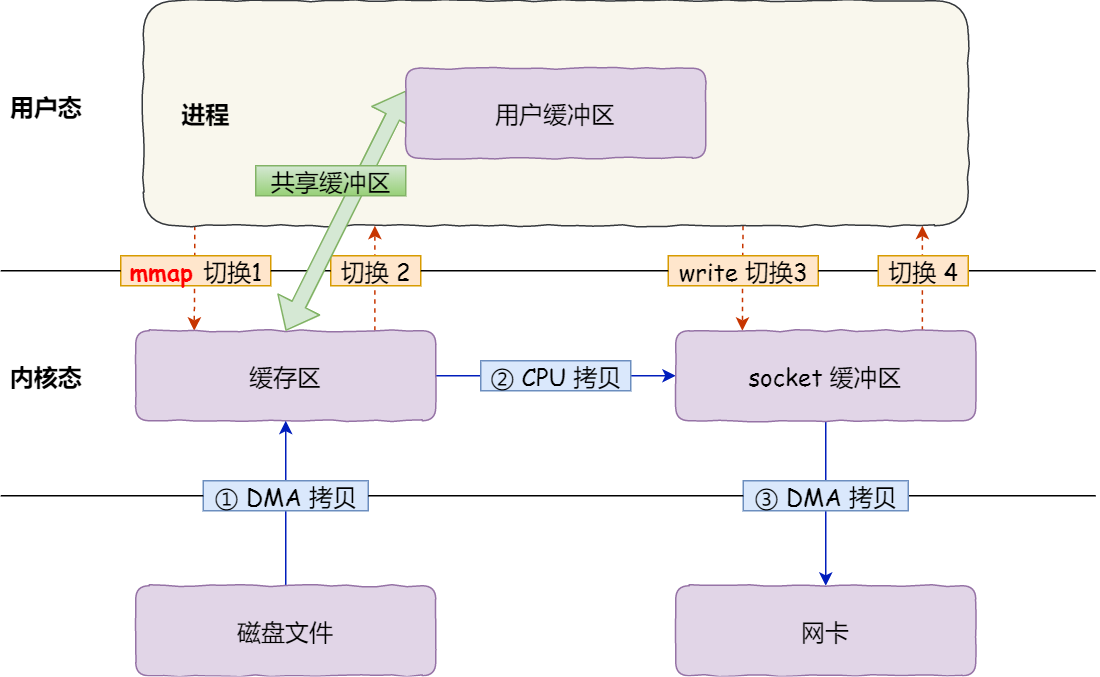
具體過程如下:
- 應用程序呼叫了
mmap()後,DMA 會把磁碟的資料拷貝到核心的緩衝區裡。接著,應用程序跟作業系統核心「共享」這個緩衝區; - 應用程序再呼叫
write(),作業系統直接將核心緩衝區的資料拷貝到 socket 緩衝區中,這一切都發生在核心態,由 CPU 來搬運資料; - 最後,把核心的 socket 緩衝區裡的資料,拷貝到網絡卡的緩衝區裡,這個過程是由 DMA 搬運的。
我們可以得知,通過使用 mmap() 來代替 read(), 可以減少一次資料拷貝的過程。
但這還不是最理想的零拷貝,因為仍然需要通過 CPU 把核心緩衝區的資料拷貝到 socket 緩衝區裡,而且仍然需要 4 次上下文切換,因為系統呼叫還是 2 次。
sendfile
在 Linux 核心版本 2.1 中,提供了一個專門傳送檔案的系統呼叫函式 sendfile(),函式形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前兩個引數分別是目的端和源端的檔案描述符,後面兩個引數是源端的偏移量和複製資料的長度,返回值是實際複製資料的長度。
首先,它可以替代前面的 read() 和 write() 這兩個系統呼叫,這樣就可以減少一次系統呼叫,也就減少了 2 次上下文切換的開銷。
其次,該系統呼叫,可以直接把核心緩衝區裡的資料拷貝到 socket 緩衝區裡,不再拷貝到使用者態,這樣就只有 2 次上下文切換,和 3 次資料拷貝。如下圖:
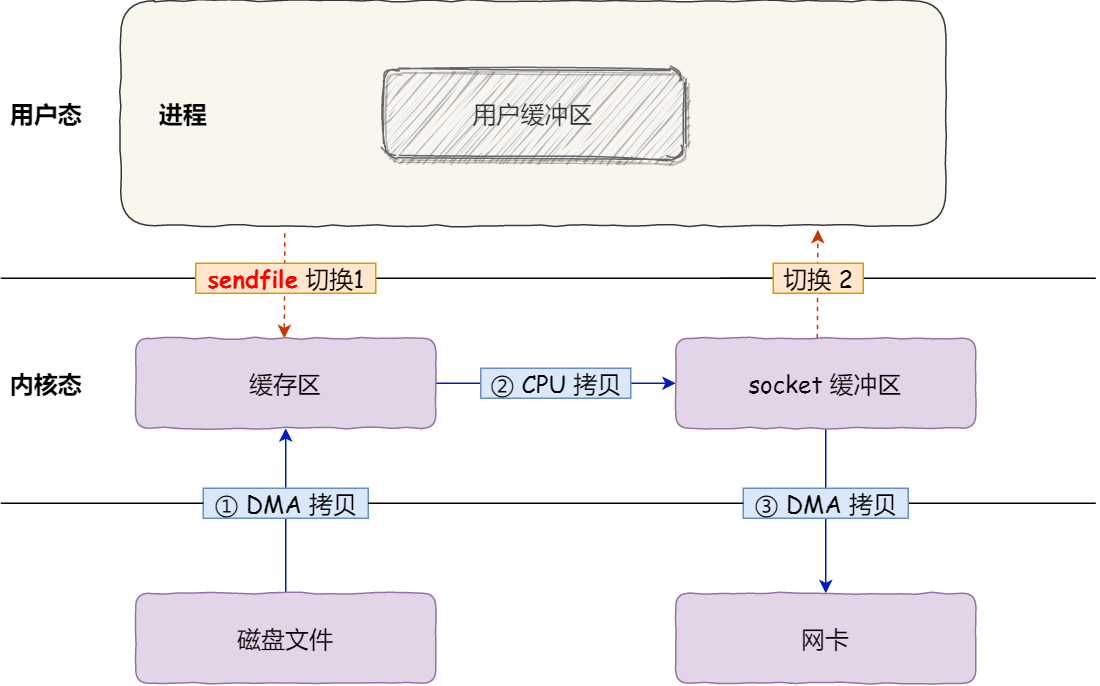
但是這還不是真正的零拷貝技術,如果網絡卡支援 SG-DMA(The Scatter-Gather Direct Memory Access)技術(和普通的 DMA 有所不同),我們可以進一步減少通過 CPU 把核心緩衝區裡的資料拷貝到 socket 緩衝區的過程。
你可以在你的 Linux 系統通過下面這個命令,檢視網絡卡是否支援 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
於是,從 Linux 核心 2.4 版本開始起,對於支援網絡卡支援 SG-DMA 技術的情況下, sendfile() 系統呼叫的過程發生了點變化,具體過程如下:
- 第一步,通過 DMA 將磁碟上的資料拷貝到核心緩衝區裡;
- 第二步,緩衝區描述符和資料長度傳到 socket 緩衝區,這樣網絡卡的 SG-DMA 控制器就可以直接將核心快取中的資料拷貝到網絡卡的緩衝區裡,此過程不需要將資料從作業系統核心緩衝區拷貝到 socket 緩衝區中,這樣就減少了一次資料拷貝;
所以,這個過程之中,只進行了 2 次資料拷貝,如下圖:
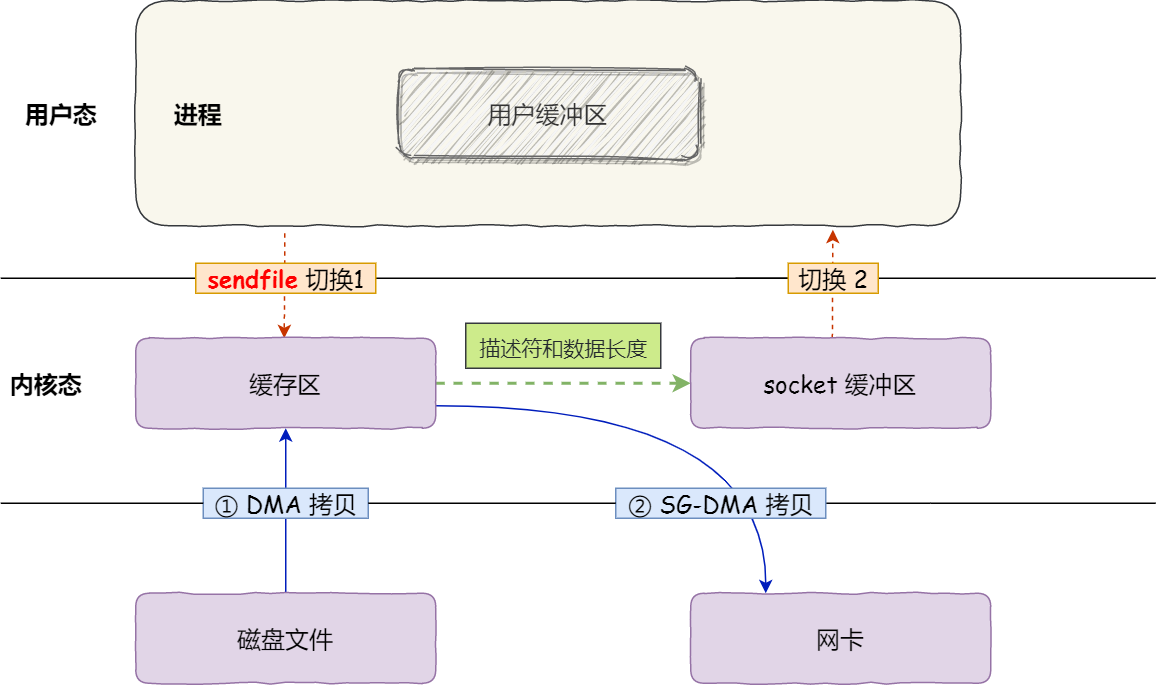
這就是所謂的零拷貝(Zero-copy)技術,因為我們沒有在記憶體層面去拷貝資料,也就是說全程沒有通過 CPU 來搬運資料,所有的資料都是通過 DMA 來進行傳輸的。。
零拷貝技術的檔案傳輸方式相比傳統檔案傳輸的方式,減少了 2 次上下文切換和資料拷貝次數,只需要 2 次上下文切換和資料拷貝次數,就可以完成檔案的傳輸,而且 2 次的資料拷貝過程,都不需要通過 CPU,2 次都是由 DMA 來搬運。
所以,總體來看,零拷貝技術可以把檔案傳輸的效能提高至少一倍以上。
使用零拷貝技術的專案
事實上,Kafka 這個開源專案,就利用了「零拷貝」技術,從而大幅提升了 I/O 的吞吐率,這也是 Kafka 在處理海量資料為什麼這麼快的原因之一。
如果你追溯 Kafka 檔案傳輸的程式碼,你會發現,最終它呼叫了 Java NIO 庫裡的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
如果 Linux 系統支援 sendfile() 系統呼叫,那麼 transferTo() 實際上最後就會使用到 sendfile() 系統呼叫函式。
曾經有大佬專門寫過程式測試過,在同樣的硬體條件下,傳統檔案傳輸和零拷拷貝檔案傳輸的效能差異,你可以看到下面這張測試資料圖,使用了零拷貝能夠縮短 65% 的時間,大幅度提升了機器傳輸資料的吞吐量。
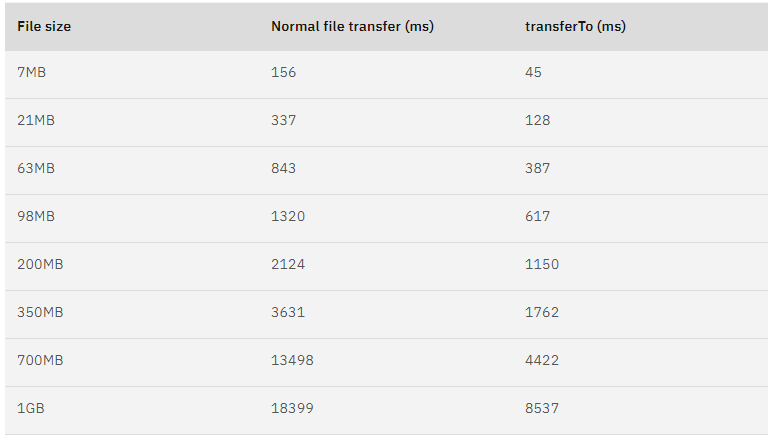 資料來源於:https://developer.ibm.com/articles/j-zerocopy/
資料來源於:https://developer.ibm.com/articles/j-zerocopy/
另外,Nginx 也支援零拷貝技術,一般預設是開啟零拷貝技術,這樣有利於提高檔案傳輸的效率,是否開啟零拷貝技術的配置如下:
http {
...
sendfile on
...
}
sendfile 配置的具體意思:
- 設定為 on 表示,使用零拷貝技術來傳輸檔案:sendfile ,這樣只需要 2 次上下文切換,和 2 次資料拷貝。
- 設定為 off 表示,使用傳統的檔案傳輸技術:read + write,這時就需要 4 次上下文切換,和 4 次資料拷貝。
當然,要使用 sendfile,Linux 核心版本必須要 2.1 以上的版本。
PageCache 有什麼作用?
回顧前面說道檔案傳輸過程,其中第一步都是先需要先把磁碟檔案資料拷貝「核心緩衝區」裡,這個「核心緩衝區」實際上是磁碟快取記憶體(PageCache)。
由於零拷貝使用了 PageCache 技術,可以使得零拷貝進一步提升了效能,我們接下來看看 PageCache 是如何做到這一點的。
讀寫磁碟相比讀寫記憶體的速度慢太多了,所以我們應該想辦法把「讀寫磁碟」替換成「讀寫記憶體」。於是,我們會通過 DMA 把磁盤裡的資料搬運到記憶體裡,這樣就可以用讀記憶體替換讀磁碟。
但是,記憶體空間遠比磁碟要小,記憶體註定只能拷貝磁盤裡的一小部分資料。
那問題來了,選擇哪些磁碟資料拷貝到記憶體呢?
我們都知道程式執行的時候,具有「區域性性」,所以通常,剛被訪問的資料在短時間內再次被訪問的概率很高,於是我們可以用 PageCache 來快取最近被訪問的資料,當空間不足時淘汰最久未被訪問的快取。
所以,讀磁碟資料的時候,優先在 PageCache 找,如果資料存在則可以直接返回;如果沒有,則從磁碟中讀取,然後快取 PageCache 中。
還有一點,讀取磁碟資料的時候,需要找到資料所在的位置,但是對於機械磁碟來說,就是通過磁頭旋轉到資料所在的扇區,再開始「順序」讀取資料,但是旋轉磁頭這個物理動作是非常耗時的,為了降低它的影響,PageCache 使用了「預讀功能」。
比如,假設 read 方法每次只會讀 32 KB 的位元組,雖然 read 剛開始只會讀 0 ~ 32 KB 的位元組,但核心會把其後面的 32~64 KB 也讀取到 PageCache,這樣後面讀取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,程序讀取到它了,收益就非常大。
所以,PageCache 的優點主要是兩個:
- 快取最近被訪問的資料;
- 預讀功能;
這兩個做法,將大大提高讀寫磁碟的效能。
但是,在傳輸大檔案(GB 級別的檔案)的時候,PageCache 會不起作用,那就白白浪費 DMA 多做的一次資料拷貝,造成效能的降低,即使使用了 PageCache 的零拷貝也會損失效能
這是因為如果你有很多 GB 級別檔案需要傳輸,每當使用者訪問這些大檔案的時候,核心就會把它們載入 PageCache 中,於是 PageCache 空間很快被這些大檔案佔滿。
另外,由於檔案太大,可能某些部分的檔案資料被再次訪問的概率比較低,這樣就會帶來 2 個問題:
- PageCache 由於長時間被大檔案佔據,其他「熱點」的小檔案可能就無法充分使用到 PageCache,於是這樣磁碟讀寫的效能就會下降了;
- PageCache 中的大檔案資料,由於沒有享受到快取帶來的好處,但卻耗費 DMA 多拷貝到 PageCache 一次;
所以,針對大檔案的傳輸,不應該使用 PageCache,也就是說不應該使用零拷貝技術,因為可能由於 PageCache 被大檔案佔據,而導致「熱點」小檔案無法利用到 PageCache,這樣在高併發的環境下,會帶來嚴重的效能問題。
大檔案傳輸用什麼方式實現?
那針對大檔案的傳輸,我們應該使用什麼方式呢?
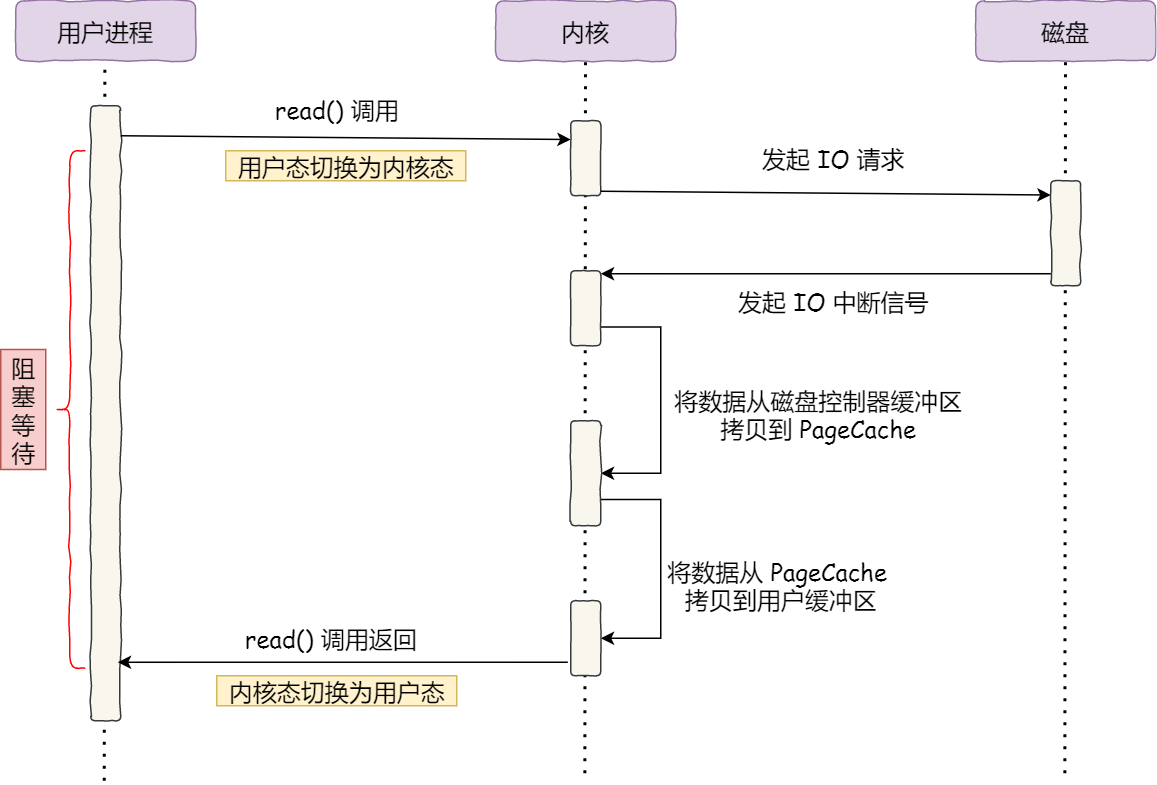
我們先來看看最初的例子,當呼叫 read 方法讀取檔案時,程序實際上會阻塞在 read 方法呼叫,因為要等待磁碟資料的返回,如下圖:
具體過程:
- 當呼叫 read 方法時,會阻塞著,此時核心會向磁碟發起 I/O 請求,磁碟收到請求後,便會定址,當磁碟資料準備好後,就會向核心發起 I/O 中斷,告知核心磁碟資料已經準備好;
- 核心收到 I/O 中斷後,就將資料從磁碟控制器緩衝區拷貝到 PageCache 裡;
- 最後,核心再把 PageCache 中的資料拷貝到使用者緩衝區,於是 read 呼叫就正常返回了。
對於阻塞的問題,可以用非同步 I/O 來解決,它工作方式如下圖:
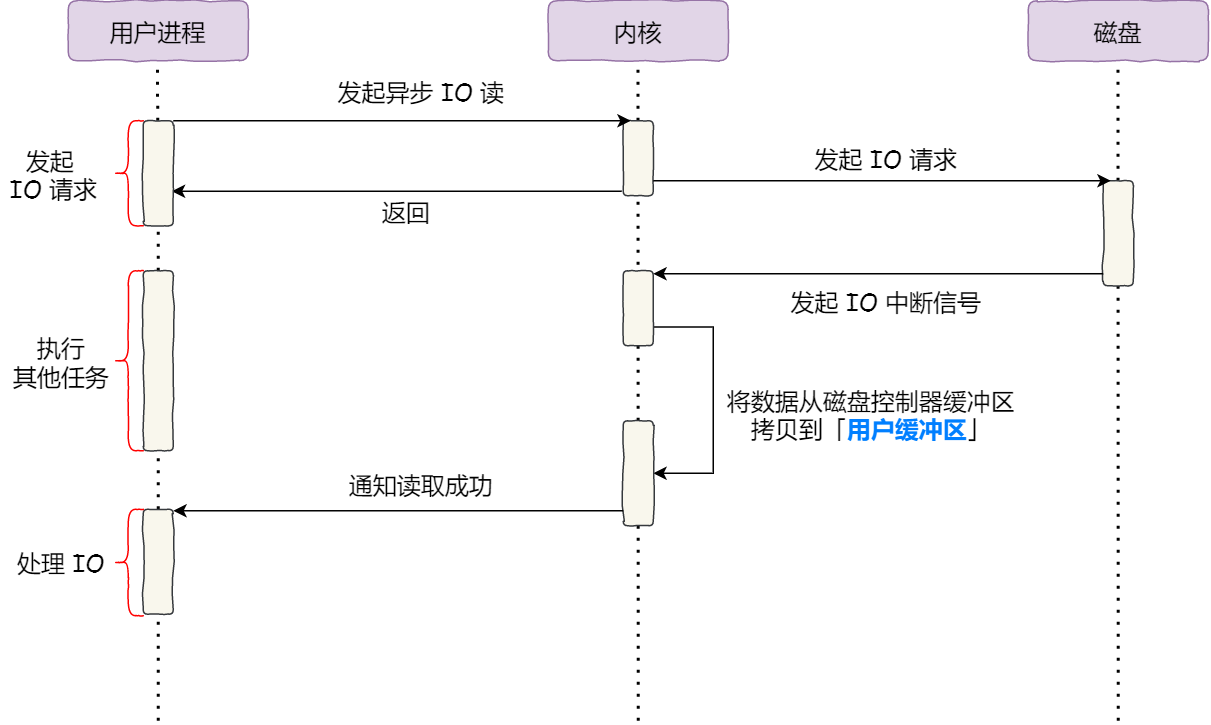
它把讀操作分為兩部分:
- 前半部分,核心向磁碟發起讀請求,但是可以不等待資料就位就可以返回,於是程序此時可以處理其他任務;
- 後半部分,當核心將磁碟中的資料拷貝到程序緩衝區後,程序將接收到核心的通知,再去處理資料;
而且,我們可以發現,非同步 I/O 並沒有涉及到 PageCache,所以使用非同步 I/O 就意味著要繞開 PageCache。
繞開 PageCache 的 I/O 叫直接 I/O,使用 PageCache 的 I/O 則叫快取 I/O。通常,對於磁碟,非同步 I/O 只支援直接 I/O。
前面也提到,大檔案的傳輸不應該使用 PageCache,因為可能由於 PageCache 被大檔案佔據,而導致「熱點」小檔案無法利用到 PageCache。
於是,在高併發的場景下,針對大檔案的傳輸的方式,應該使用「非同步 I/O + 直接 I/O」來替代零拷貝技術。
直接 I/O 應用場景常見的兩種:
- 應用程式已經實現了磁碟資料的快取,那麼可以不需要 PageCache 再次快取,減少額外的效能損耗。在 MySQL 資料庫中,可以通過引數設定開啟直接 I/O,預設是不開啟;
- 傳輸大檔案的時候,由於大檔案難以命中 PageCache 快取,而且會佔滿 PageCache 導致「熱點」檔案無法充分利用快取,從而增大了效能開銷,因此,這時應該使用直接 I/O。
另外,由於直接 I/O 繞過了 PageCache,就無法享受核心的這兩點的優化:
- 核心的 I/O 排程演算法會快取儘可能多的 I/O 請求在 PageCache 中,最後「合併」成一個更大的 I/O 請求再發給磁碟,這樣做是為了減少磁碟的定址操作;
- 核心也會「預讀」後續的 I/O 請求放在 PageCache 中,一樣是為了減少對磁碟的操作;
於是,傳輸大檔案的時候,使用「非同步 I/O + 直接 I/O」了,就可以無阻塞地讀取檔案了。
所以,傳輸檔案的時候,我們要根據檔案的大小來使用不同的方式:
- 傳輸大檔案的時候,使用「非同步 I/O + 直接 I/O」;
- 傳輸小檔案的時候,則使用「零拷貝技術」;
在 nginx 中,我們可以用如下配置,來根據檔案的大小來使用不同的方式:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}
當檔案大小大於 directio 值後,使用「非同步 I/O + 直接 I/O」,否則使用「零拷貝技術」。
總結
早期 I/O 操作,記憶體與磁碟的資料傳輸的工作都是由 CPU 完成的,而此時 CPU 不能執行其他任務,會特別浪費 CPU 資源。
於是,為了解決這一問題,DMA 技術就出現了,每個 I/O 裝置都有自己的 DMA 控制器,通過這個 DMA 控制器,CPU 只需要告訴 DMA 控制器,我們要傳輸什麼資料,從哪裡來,到哪裡去,就可以放心離開了。後續的實際資料傳輸工作,都會由 DMA 控制器來完成,CPU 不需要參與資料傳輸的工作。
傳統 IO 的工作方式,從硬碟讀取資料,然後再通過網絡卡向外傳送,我們需要進行 4 上下文切換,和 4 次資料拷貝,其中 2 次資料拷貝發生在記憶體裡的緩衝區和對應的硬體裝置之間,這個是由 DMA 完成,另外 2 次則發生在核心態和使用者態之間,這個資料搬移工作是由 CPU 完成的。
為了提高檔案傳輸的效能,於是就出現了零拷貝技術,它通過一次系統呼叫(sendfile 方法)合併了磁碟讀取與網路傳送兩個操作,降低了上下文切換次數。另外,拷貝資料都是發生在核心中的,天然就降低了資料拷貝的次數。
Kafka 和 Nginx 都有實現零拷貝技術,這將大大提高檔案傳輸的效能。
零拷貝技術是基於 PageCache 的,PageCache 會快取最近訪問的資料,提升了訪問快取資料的效能,同時,為了解決機械硬碟定址慢的問題,它還協助 I/O 排程演算法實現了 IO 合併與預讀,這也是順序讀比隨機讀效能好的原因。這些優勢,進一步提升了零拷貝的效能。
需要注意的是,零拷貝技術是不允許程序對檔案內容作進一步的加工的,比如壓縮資料再發送。
另外,當傳輸大檔案時,不能使用零拷貝,因為可能由於 PageCache 被大檔案佔據,而導致「熱點」小檔案無法利用到 PageCache,並且大檔案的快取命中率不高,這時就需要使用「非同步 IO + 直接 IO 」的方式。
在 Nginx 裡,可以通過配置,設定一個檔案大小閾值,針對大檔案使用非同步 IO 和直接 IO,而對小檔案使用零拷貝。
絮叨

大家好,我是小林,一個專為大家圖解的工具人,如果覺得文章對你有幫助,歡迎分享給你的朋友,這對小林非常重要,謝謝你們,我們下次見!
推薦閱讀
一口氣搞懂「檔案系統」,就靠這 25 張圖了
鍵盤敲入 A 字母時,作業系統期間發生了什麼…