
談談Netty記憶體管理
阿新 • • 發佈:2020-09-25
## 前言
正是Netty的易用性和高效能成就了Netty,讓其能夠如此流行。
而作為一款通訊框架,首當其衝的便是對IO效能的高要求。
不少讀者都知道Netty底層通過使用Direct Memory,減少了核心態與使用者態之間的記憶體拷貝,加快了IO速率。但是頻繁的向系統申請Direct Memory,並在使用完成後釋放本身就是一件影響效能的事情。為此,Netty內部實現了一套自己的記憶體管理機制,在申請時,Netty會一次性向作業系統申請較大的一塊記憶體,然後再將大記憶體進行管理,按需拆分成小塊分配。而釋放時,Netty並不著急直接釋放記憶體,而是將記憶體回收以待下次使用。
這套記憶體管理機制不僅可以管理Directory Memory,同樣可以管理Heap Memory。
## 記憶體的終端消費者——ByteBuf
這裡,我想向讀者們強調一點,ByteBuf和記憶體其實是兩個概念,要區分理解。
ByteBuf是一個物件,需要給他分配一塊記憶體,它才能正常工作。
而記憶體可以通俗的理解成我們作業系統的記憶體,雖然申請到的記憶體也是需要依賴載體儲存的:堆記憶體時,通過byte[], 而Direct記憶體,則是Nio的ByteBuffer(因此Java使用Direct Memory的能力是JDK中Nio包提供的)。
為什麼要強調這兩個概念,是因為Netty的記憶體池(或者稱記憶體管理機制)涉及的是針對記憶體的分配和回收,而Netty的ByteBuf的回收則是另一種叫做物件池的技術(通過Recycler實現)。
雖然這兩者總是伴隨著一起使用,但這二者是獨立的兩套機制。可能存在著某次建立ByteBuf時,ByteBuf是回收使用的,而記憶體卻是新向作業系統申請的。也可能存在某次建立ByteBuf時,ByteBuf是新建立的,而記憶體卻是回收使用的。
因為對於一次建立過程而言,可以分成三個步驟:
1. 獲取ByteBuf例項(可能新建,也可能是之間快取的)
2. 向Netty記憶體管理機制申請記憶體(可能新向作業系統申請,也可能是之前回收的)
3. 將申請到的記憶體分配給ByteBuf使用
本文只關注記憶體的管理機制,因此不會過多的對物件回收機制做解釋。
## Netty中記憶體管理的相關類
Netty中與記憶體管理相關的類有很多。框架內部提供了`PoolArena`,`PoolChunkList`,`PoolChunk`,`PoolSubpage`等用來管理一塊或一組記憶體。
而對外,提供了`ByteBufAllocator`供使用者進行操作。
接下來,我們會先對這幾個類做一定程度的介紹,在通過`ByteBufAllocator`瞭解記憶體分配和回收的流程。
為了篇幅和可讀性考慮,本文不會涉及到大量很詳細的程式碼說明,而主要是通過圖輔之必要的程式碼進行介紹。
針對程式碼的註解,可以見我GitHub上的[netty](https://github.com/insaneXs/netty)專案。
## PoolChunck——Netty向OS申請的最小記憶體
上文已經介紹了,為了減少頻繁的向作業系統申請記憶體的情況,Netty會一次性申請一塊較大的記憶體。而後對這塊記憶體進行管理,每次按需將其中的一部分分配給記憶體使用者(即ByteBuf)。這裡的記憶體就是`PoolChunk`,其大小由ChunkSize決定(預設為16M,即一次向OS申請16M的記憶體)。
## Page——PoolChunck所管理的最小記憶體單位
PoolChunk所能管理的最小記憶體叫做Page,大小由PageSize(預設為8K),即一次向PoolChunk申請的記憶體都要以Page為單位(一個或多個Page)。
當需要由PoolChunk分配記憶體時,PoolChunk會檢視通過內部記錄的資訊找出滿足此次記憶體分配的Page的位置,分配給使用者。
## PoolChunck如何管理Page
我們已經知道PoolChunk內部會以Page為單位組織記憶體,同樣以Page為單位分配記憶體。
那麼PoolChunk要如何管理才能兼顧分配效率(指儘可能快的找出可分配的記憶體且保證此次分配的記憶體是連續的)和使用效率(儘可能少的避免記憶體浪費,做到物盡其用)的?
Netty採用了Jemalloc的想法。
首先PoolChunk通過一個完全二叉樹來組織內部的記憶體。以預設的ChunkSize為16M, PageSize為8K為例,一個PoolChunk可以劃分成2048個Page。將這2048個Page看作是葉子節點的寬度,可以得到一棵深度為11的樹(2^11=2048)。
我們讓每個葉子節點管理一個Page,那麼其父節點管理的記憶體即為兩個Page(其父節點有左右兩個葉子節點),以此類推,樹的根節點管理了這個PoolChunk所有的Page(因為所有的葉子結點都是其子節點),而樹中某個節點所管理的記憶體大小即是以該節點作為根的子樹所包含的葉子節點管理的全部Page。
這樣做的好處就是當你需要記憶體時,很快可以找到從何處分配記憶體(你只需要從上往下找到所管理的記憶體為你需要的記憶體的節點,然後將該節點所管理的記憶體分配出去即可),並且所分配的記憶體還是連續的(只要保證相鄰葉子節點對應的Page是連續的即可)。
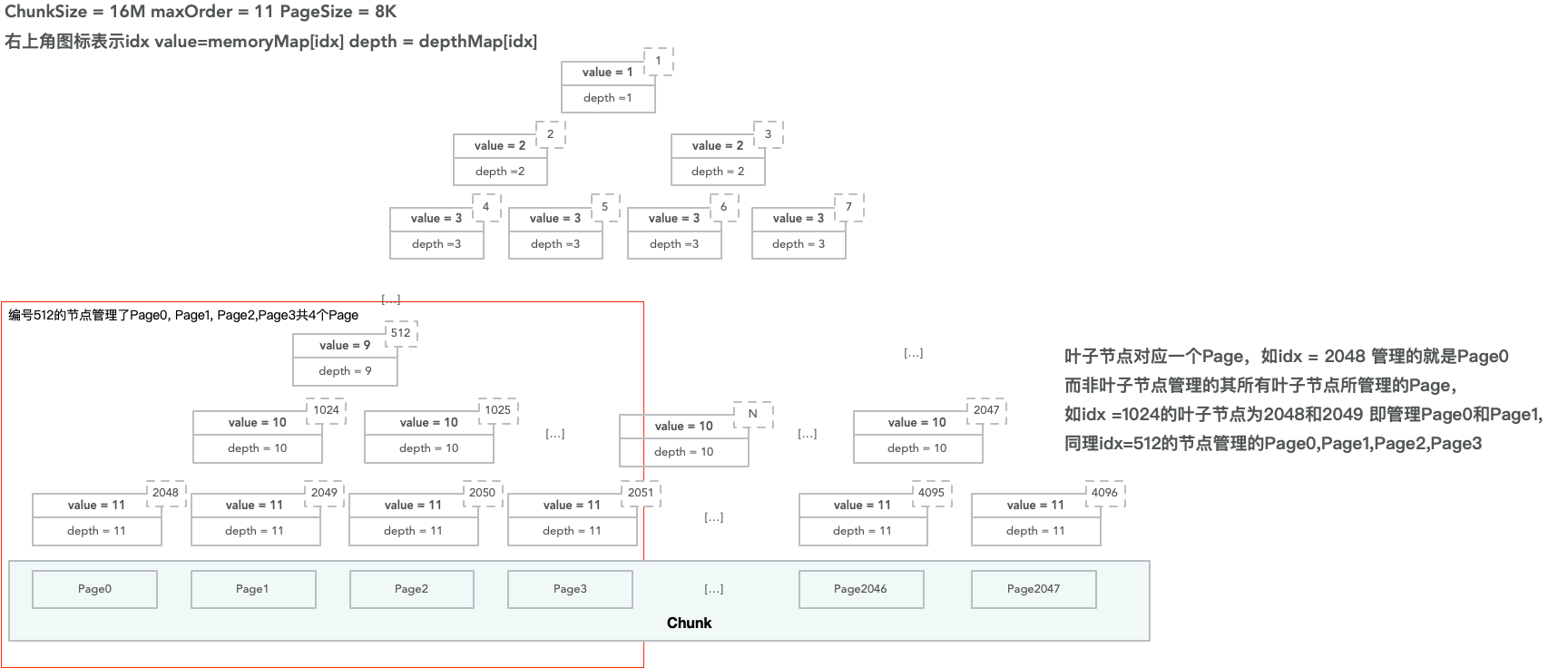
上圖中編號為512的節點管理了4個Page,為Page0, Page1, Page2, Page3(因為其下面有四個葉子節點2048,2049,2050, 2051)。
而編號為1024的節點管理了2個Page,為Page0和Page1(其對應的葉子節點為Page0和Page1)。
當需要分配32K的記憶體時,只需要將編號512的節點分配出去即可(512分配出去後會預設其下所有子節點都不能分配)。而當需要分配16K的記憶體時,只需要將編號1024的節點分配出去即可(一旦節點1024被分配,下面的2048和2049都不允許再被分配)。
瞭解了PoolChunk內部的記憶體管理機制後,讀者可能會產生幾個問題:
- PoolChunk內部如何標記某個節點已經被分配?
- 當某個節點被分配後,其父節點所能分配的記憶體如何更新?即一旦節點2048被分配後,當你再需要16K的記憶體時,就不能從節點1024分配,因為現在節點1024可用的記憶體僅有8K。
為了解決以上這兩點問題,PoolChunk都是內部維護了的byte[] memeoryMap和byte[] depthMap兩個變數。
這兩個陣列的長度是相同的,長度等於樹的節點數+1。因為它們把根節點放在了1的位置上。而陣列中父節點與子節點的位置關係為:
```math
假設parnet的下標為i,則子節點的下標為2i和2i+1
```
> 用陣列表示一顆二叉樹,你們是不是想到了堆這個資料結構。
已經知道了兩個陣列都是表示二叉樹,且陣列中的每個元素可以看成二叉樹的節點。那麼再來看看元素的值分別程式碼什麼意思。
對於depthMap而言,該值就代表該節點所處的樹的層數。例如:depthMap[1] == 1,因為它是根節點,而depthMap[2] = depthMap[3] = 2,表示這兩個節點均在第二層。由於樹一旦確定後,結構就不在發生改變,因此depthMap在初始化後,各元素的值也就不發生變化了。
而對於memoryMap而言,其值表示該節點下可用於完整記憶體分配的最小層數(或者說最靠近根節點的層數)。
這話理解起來可能有點彆扭,還是用上文的例子為例 。
首先在記憶體都未分配的情況下,每個節點所能分配的記憶體大小就是該層最初始的狀態(即memoryMap的初始狀態和depthMap的一致的)。而一旦其有個子節點被分配出後去,父節點所能分配的完整記憶體(完整記憶體是指該節點所管理的連續的記憶體塊,而非該節點剩餘的記憶體大小)就減小了(記憶體的分配和回收會修改關聯的mermoryMap中相關節點的值)。
譬如,節點2048被分配後,那麼對於節點1024來說,能完整分配的記憶體(原先為16K)就已經和編號2049節點(其右子節點)相同(減為了8K),換句話說節點1024的能力已經退化到了2049節點所在的層節點所擁有的能力。
這一退化可能會影響所有的父節點。
而此時,512節點能分配的完整記憶體是16K,而非24K(因為記憶體分配都是按2的冪進行分配,儘管一個消費者真實需要的記憶體可能是21K,但是Netty的記憶體管理機制會直接分配32K的記憶體)。
> 但是這並不是說節點512管理的另一個8K記憶體就浪費了,8K記憶體還可以用來在申請記憶體為8K的時候分配。
用圖片演示PoolChunk記憶體分配的過程。其中value表示該節點在memoeryMap的值,而depth表示該節點在depthMap的值。
第一次記憶體分配,申請者實際需要6K的記憶體:
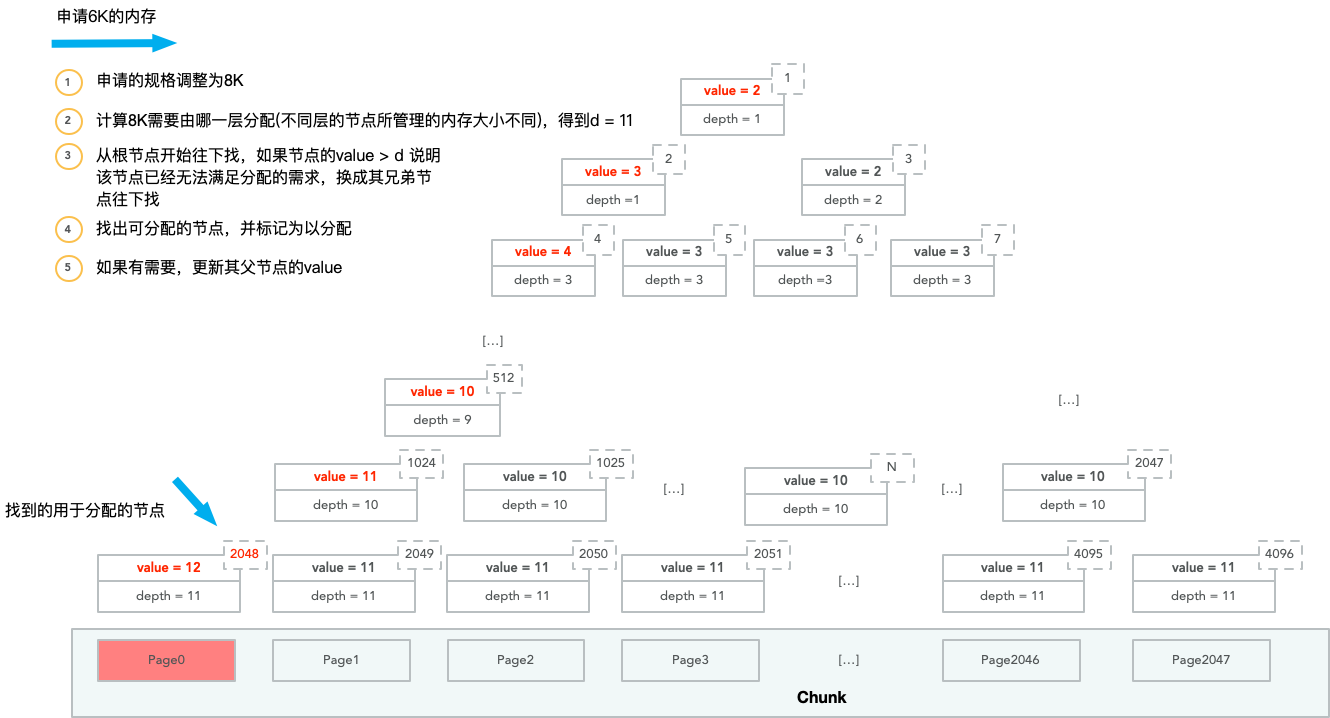
這次分配造成的後果是其所有父節點的memoryMap的值都往下加了一層。
之後申請者需要申請12K的記憶體:
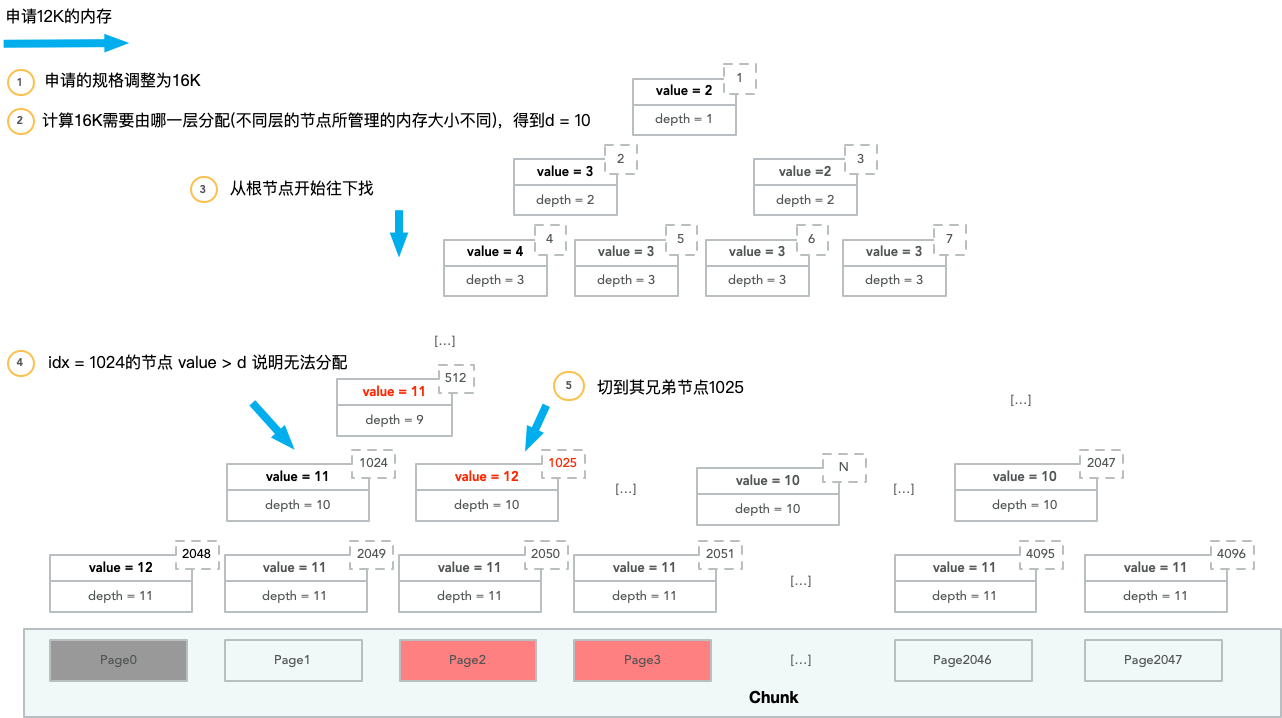
由於節點1024已經無法分配所需的記憶體,而節點512還能夠分配,因此節點512讓其右節點再嘗試。
上述介紹的是記憶體分配的過程,而記憶體回收的過程就是上述過程的逆過程——回收後將對應節點的memoryMap的值修改回去。這裡不過多介紹。
## PoolChunkList——對PoolChunk的管理
PoolChunkList內部有一個PoolChunk組成的連結串列。通常一個PoolChunkList中的所有PoolChunk使用率(已分配記憶體/ChunkSize)都在相同的範圍內。
每個PoolChunkList有自己的最小使用率或者最大使用率的範圍,PoolChunkList與PoolChunkList之間又會形成連結串列,並且使用率範圍小的PoolChunkList會在連結串列中更加靠前。
而隨著PoolChunk的記憶體分配和使用,其使用率發生變化後,PoolChunk會在PoolChunkList的連結串列中,前後調整,移動到合適範圍的PoolChunkList內。
這樣做的好處是,使用率的小的PoolChunk可以先被用於記憶體分配,從而維持PoolChunk的利用率都在一個較高的水平,避免記憶體浪費。
## PoolSubpage——小記憶體的管理者
PoolChunk管理的最小記憶體是一個Page(預設8K),而當我們需要的記憶體比較小時,直接分配一個Page無疑會造成記憶體浪費。
PoolSubPage就是用來管理這類細小記憶體的管理者。
> 小記憶體是指小於一個Page的記憶體,可以分為Tiny和Smalll,Tiny是小於512B的記憶體,而Small則是512到4096B的記憶體。如果記憶體塊大於等於一個Page,稱之為Normal,而大於一個Chunk的記憶體塊稱之為Huge。
而Tiny和Small內部又會按具體記憶體的大小進行細分。
對Tiny而言,會分成16,32,48...496(以16的倍數遞增),共31種情況。
對Small而言,會分成512,1024,2048,4096四種情況。
PoolSubpage會先向PoolChunk申請一個Page的記憶體,然後將這個page按規格劃分成相等的若干個記憶體塊(一個PoolSubpage僅會管理一種規格的記憶體塊,例如僅管理16B,就將一個Page的記憶體分成512個16B大小的記憶體塊)。
每個PoolSubpage僅會選一種規格的記憶體管理,因此處理相同規格的PoolSubpage往往是通過連結串列的方式組織在一起,不同的規格則分開存放在不同的地方。
並且總是管理一個規格的特性,讓PoolSubpage在記憶體管理時不需要使用PoolChunk的完全二叉樹方式來管理記憶體(例如,管理16B的PoolSubpage只需要考慮分配16B的記憶體,當申請32B的記憶體時,必須交給管理32B的記憶體來處理),僅用 long[] bitmap (可以看成是位陣列)來記錄所管理的記憶體塊中哪些已經被分配(第幾位就表示第幾個記憶體塊)。
實現方式要簡單很多。
## PoolArena——記憶體管理的統籌者
PoolArena是記憶體管理的統籌者。
它內部有一個PoolChunkList組成的連結串列(上文已經介紹過了,連結串列是按PoolChunkList所管理的使用率劃分)。
此外,它還有兩個PoolSubpage的陣列,PoolSubpage[] tinySubpagePools 和 PoolSubpage[] smallSubpagePools。
預設情況下,tinySubpagePools的長度為31,即存放16,32,48...496這31種規格的PoolSubpage(不同規格的PoolSubpage存放在對應的陣列下標中,相同規格的PoolSubpage在同一個陣列下標中形成連結串列)。
同理,預設情況下,smallSubpagePools的長度為4,存放512,1024,2048,4096這四種規格的PoolSubpage。
PoolArena會根據所申請的記憶體大小決定是找PoolChunk還是找對應規格的PoolSubpage來分配。
值得注意的是,PoolArena在分配記憶體時,是會存在競爭的,因此在關鍵的地方,PoolArena會通過sychronize來保證執行緒的安全。
Netty對這種競爭做了一定程度的優化,它會分配多個PoolArena,讓執行緒儘量使用不同的PoolArena,減少出現競爭的情況。
## PoolThreadCache——執行緒本地快取,減少記憶體分配時的競爭
PoolArena免不了產生競爭,Netty除了建立多個PoolArena減少競爭外,還讓執行緒在釋放記憶體時快取已經申請過的記憶體,而不立即歸還給PoolArena。
快取的記憶體被存放在PoolThreadCache內,它是一個執行緒本地變數,因此是執行緒安全的,對它的訪問也不需要上鎖。
PoolThreadCache內部是由MemeoryRegionCache的快取池(陣列),同樣按等級可以分為Tiny,Small和Normal(並不快取Huge,因為Huge效益不高)。
其中Tiny和Small這兩個等級下的劃分方式和PoolSubpage的劃分方式相同,而Normal因為組合太多,會有一個引數控制快取哪些規格(例如,一個Page, 兩個Page和四個Page等...),不在Normal快取規格內的記憶體塊將不會被快取,直接還給PoolArena。
再看MemoryRegionCache, 它內部是一個佇列,同一佇列內的所有節點可以看成是該執行緒使用過的同一規格的記憶體塊。同時,它還有個size屬性控制佇列過長(佇列滿後,將不在快取該規格的記憶體塊,而是直接還給PoolArena)。
當執行緒需要記憶體時,會先從自己的PoolThreadCache中找對應等級的快取池(對應的陣列)。然後再從陣列中找出對應規格的MemoryRegionCache。最後從其佇列中取出記憶體塊進行分配。
## Netty記憶體機構總覽和PooledByteBufAllocator申請記憶體步驟
在瞭解了上述這麼多概念後,通過一張圖給讀者加深下印象。
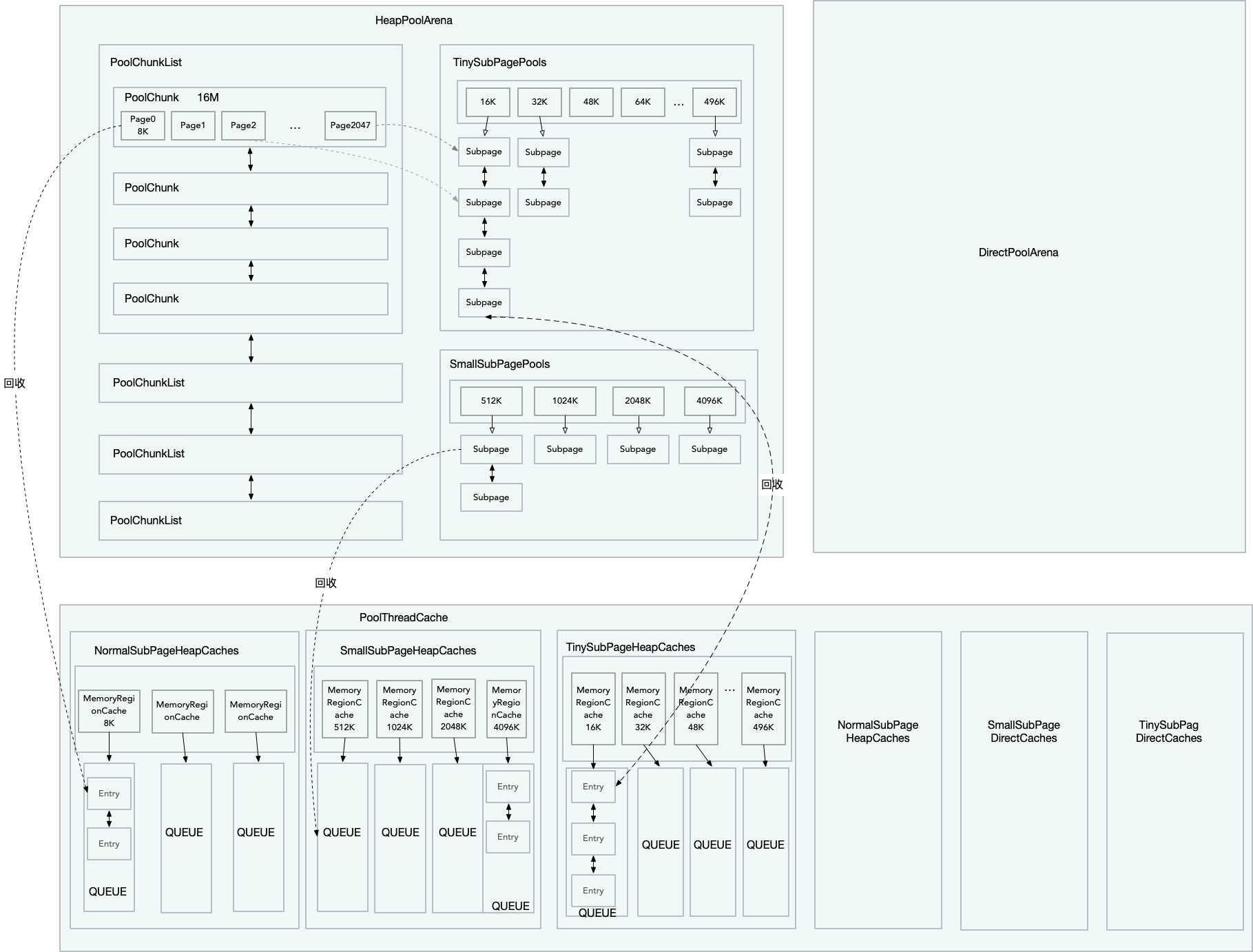
上圖僅詳細畫了針對Heap Memory的部分,Directory Memory也是類似的。
最後在由PooledByteBufAllocator作為入口,重頭梳理一遍記憶體申請的過程:
1. PooledByteBufAllocator.newHeapBuffer()開始申請記憶體
2. 獲取執行緒本地的變數PoolThreadCache以及和執行緒繫結的PoolArena
3. 通過PoolArena分配記憶體,先獲取ByteBuf物件(可能是物件池回收的也可能是建立的),在開始記憶體分配
4. 分配前先判斷此次記憶體的等級,嘗試從PoolThreadCache的找相同規格的快取記憶體塊使用,沒有則從PoolArena中分配記憶體
5. 對於Normal等級記憶體而言,從PoolChunkList的連結串列中找合適的PoolChunk來分配記憶體,如果沒有則先像OS申請一個PoolChunk,在由PoolChunk分配相應的Page
6. 對於Tiny和Small等級的記憶體而言,從對應的PoolSubpage快取池中找記憶體分配,如果沒有PoolSubpage,線會到第5步,先分配PoolChunk,再由PoolChunk分配Page給PoolSubpage使用
7. 對於Huge等級的記憶體而言,不會快取,會在用的時候申請,釋放的時候直接回收
8.將得到的記憶體給ByteBuf使用,就完成了一次記憶體申請的過程
## 總結
Netty的記憶體管理機制還是很巧妙的,但是介紹起來難免有點晦澀。本想盡量通俗易懂的撇開原始碼和大家講講原理,但是不知不覺也寫了一大段的文字。希望上文的幾幅圖能幫助讀者理解。
另外,本文也沒有介紹記憶體釋放的過程。釋放其實就是申請的逆過程,有興趣的讀者可以自己跟一下原始碼,或者是從文章開頭的專案中找原始碼