
從四個問題透析Linux下C++編譯&連結
摘要:編譯&連結對C&C++程式設計師既熟悉又陌生,熟悉在於每份程式碼都要經歷編譯&連結過程,陌生在於大部分人並不會刻意關注編譯&連結的原理。本文通過開發過程中碰到的四個典型問題來探索64位linux下C++編譯&連結的那些事。
編譯原理:
將如下最簡單的C++程式(main.cpp)編譯成可執行目標程式,實際上可以分為四個步驟:預處理、編譯、彙編、連結,可以通過
g++ main.cpp –v看到詳細的過程,不過現在編譯器已經把預處理和編譯過程合併。
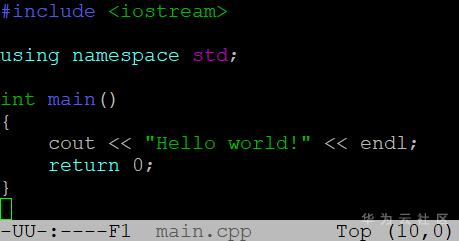
預處理:g++ -E main.cpp -o main.ii,-E表示只進行預處理。預處理主要是處理各種巨集展開;新增行號和檔案識別符號,為編譯器產生除錯資訊提供便利;刪除註釋;保留編譯器用到的編譯器指令等。
編譯:g++ -S main.ii –o main.s,-S表示只編譯。編譯是在預處理檔案基礎上經過一系列詞法分析、語法分析及優化後生成彙編程式碼。
彙編:g++ -c main.s –o main.o。彙編是將彙編程式碼轉化為機器可以執行的指令。
連結:g++ main.o。連結生成可執行程式,之所以需要連結是因為我們程式碼不可能像main.cpp這麼簡單,現代軟體動則成百上千萬行,如果寫在一個main.cpp既不利於分工合作,也無法維護,因此通常是由一堆cpp檔案組成,編譯器分別編譯每個cpp,這些cpp裡會引用別的模組中的函式或全域性變數,在編譯單個cpp的時候是沒法知道它們的準確地址,因此在編譯結束後,需要連結器將各種還沒有準確地址的符號(函式、變數等)設定為正確的值,這樣組裝在一起就可以形成一個完整的可執行程式。
問題一:標頭檔案遮擋
在編譯過程中最詭異的問題莫過於標頭檔案遮擋,如下程式碼中main.cpp包含標頭檔案common.h,真正想用的標頭檔案是圖中最右邊那個包含name

成員的檔案(所在目錄為./include),但在編譯過程中中間的common.h(所在目錄為./include1)搶先被發現,導致編譯器報錯:Test結構沒有name成員,對程式設計師來講,自己明明定義了name成員,居然說沒有name這個成員,如果第一次碰到這種情況可能會懷疑人生。應對這種詭異的問題,我們可以用-E引數看下編譯器預處理後的輸出,如下圖。
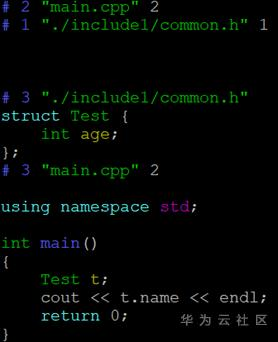
預處理檔案格式如下:# linenum filename flag,表示之後的內容是從檔名為filaname的檔案中第linenum行展開的,flag的取值可以是1,2,3,4,可以是用空格分開的多值,1表示接下來要展開一個新檔案;2表示一個檔案展開完畢;3表示接下來內容來自一個系統標頭檔案;4表示接下來的內容應該看做是extern C形式引入的。
從展開後的輸出我們可以清楚地看到Test結構確實沒有定義name這個成員,並且Test這個結構是在./include1中的common.h中定義的,到此真相大白,編譯器壓根就沒用我們定義的Test結構,而是被別的同名標頭檔案截胡了。我們可以通過調整-I或者在標頭檔案中帶上部分路徑更詳細制定標頭檔案位置來解決。
目標檔案:
編譯連結最終會生成各種目標檔案,Linux下目標檔案格式為ELF(Executable Linkable Format),詳細定義見/usr/include/elf.h標頭檔案,常見的目標檔案有:可重定位目標檔案,也即.o結尾的目標檔案,當然靜態庫也歸為此類;可執行檔案,比如預設編譯出的a.out檔案;共享目標檔案.so;核心轉儲檔案,也就是core dump後產出的檔案。Linux檔案格式可以通過file命令檢視。
一個典型的ELF檔案格式如下圖所示,檔案有兩種視角:編譯視角,以section頭部表為核心組織程式;執行視角,程式頭部表以segment為核心組織程式。這麼做主要是為了節約儲存,很多細碎的section在執行時由於對齊要求會導致很大的記憶體浪費,執行時通常會將許可權類似的section組織成segment一起載入。

通過命令objdump和readelf可以檢視ELF檔案的內容。
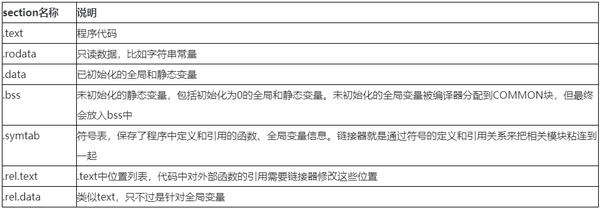
對可重定位目標檔案常見的section有:
符號解析:
連結器會為對外部符號的引用修改為正確的被引用符號的地址,當無法為引用的外部符號找到對應的定義時,連結器會報undefined reference to XXXX的錯誤。另外一種情況是,找到了多個符號的定義,這種情況連結器有一套規則。在描述規則前需要了解強符號和弱符號的概念,簡單講函式和已初始化的全域性變數是強符號,未初始化的全域性變數是弱符號。
針對符號的多重定義連結器處理規則如下(作者在gcc 7.3.0上貌似規則2,3都按1處理):
1. 不允許多個強符號定義,連結器會報告重複定義貌似的錯誤
2. 如果一個強符號和多個弱符號同名,則選擇強符號
3. 如果符號在所有目標檔案中都為弱符號,那麼選擇佔用空間最大的一個
有了這些基礎,我們先來看一下靜態連結過程:
1. 連結器從左到右按照命令列出現順序掃描目標檔案和靜態庫
2. 連結器維護一個目標檔案的集合E,一個未解析符號集合U,以及E中已定義的符號集合D,初始狀態E、U、D都為空
3. 對命令列上每個檔案f,連結器會判斷f是否是一個目標檔案還是靜態庫,如果是目標檔案,則f加入到E,f中未定義的符號加入到U中,已定義符號加入到D中,繼續下一檔案
4. 如果是靜態庫,連結器嘗試到靜態庫目標檔案中匹配U中未定義的符號,如果m中匹配U中的一個符號,那麼m就和上步中檔案f一樣處理,對每個成員檔案都依次處理,直到U、D無變化,不包含在E中的成員檔案簡單丟棄
5. 所有輸入檔案處理完後,如果U中還有符號,則出錯,否則連結正常,輸出可執行檔案
問題二:靜態庫順序
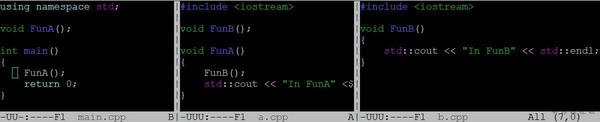
如下圖所示,main.cpp依賴liba.a,liba.a又依賴libb.a,根據靜態連結演算法,如果用g++ main.cpp liba.a libb.a的順序能正常連結,因為解析liba.a時未定義符號FunB會加入到上述演算法的U中,然後在libb.a中找到定義,如果用g++ main.cpp libb.a liba.a的順序編譯,則無法找到FunB的定義,因為根據靜態連結演算法,在解析libb.a的時候U為空,所以不需要做任何解析,簡單拋棄libb.a,但在解析liba.a的時候又發現FunB沒有定義,導致U最終不為空,連結錯誤,因此在做靜態連結時,需要特別注意庫的順序安排,引用別的庫的靜態庫需要放在前面,碰到連結很多庫的時候,可能需要做一些庫的調整,從而使依賴關係更清晰。
動態連結:
之前大部分內容都是靜態連結相關,但靜態連結有很多不足:不利於更新,只要有一個庫有變動,都需要重新編譯;不利於共享,每個可執行程式都單獨保留一份,對記憶體和磁碟是極大的浪費。
要生成動態連結庫需要用到引數“-shared -fPIC”表示要生成位置無關PIC(Position Independent Code)的共享目標檔案。對靜態連結,在生成可執行目標檔案時整個連結過程就完成了,但要想實現動態連結的效果,就需要把程式按照模組拆分成相對獨立的部分,在程式執行時將他們連結成一個完整的程式,同時為了實現程式碼在不同程式間共享要保證程式碼是和位置無關的(因為共享目標檔案在每個程式中被載入的虛擬地址都不一樣,要保證它不管被載入在哪都能工作),而為了實現位置無關又依賴一個前提:資料段和程式碼段的距離總是保持不變。
由於不管在記憶體中如何載入一個目標模組,資料段和程式碼段間的距離是不變的,編譯器在資料段前面引入了一個全域性偏移表GOT(Global Offset Table),被引用的全域性變數或者函式在GOT中都有一條記錄,同時編譯器為GOT中每個條目生成一個重定位記錄,因為資料段是可以修改的,動態連結器在載入時會重定位GOT中的每個條目,這樣就實現了PIC。
大體原理基本就這樣,但具體實現時,對函式的處理和全域性變數有所不同。由於大型程式函式成千上萬,而程式很可能只會用到其中的一小部分,因此沒必要載入的時候把所有的函式都做重定位,只有在用到的時候才對地址做修訂,為此編譯器引入了過程連結表PLT(Procedure Linkage Table)來實現延時繫結。PLT在程式碼段中,它指向了GOT中函式對應的地址,第一次呼叫時候,GOT存放的不是函式的實際地址,而是PLT跳轉到GOT程式碼的後一條指令地址,這樣第一次通過PLT跳轉到GOT,然後通過GOT又調回到PLT的下一條指令,相當於什麼也沒做,緊接著PLT後面的程式碼會將動態連結需要的引數入棧,然後呼叫動態連結器修正GOT中的地址,從這以後,PLT中程式碼跳轉到GOT的地址就是函式真正的地址,從而實現了所謂的延時繫結。
對共享目標檔案而言,有幾個需要關注的section:

有了以上基礎後,我們看一下動態連結的過程:
1. 裝載過程中程式執行會跳轉到動態連結器
2. 動態連結器自舉通過GOT、.dynamic資訊完成自身的重定位工作
3. 裝載共享目標檔案:將可執行檔案和連結器本身符號合併入全域性符號表,依次廣度優先遍歷共享目標檔案,它們的符號表會不斷合併到全域性符號表中,如果多個共享物件有相同的符號,則優先載入的共享目標檔案會遮蔽掉後面的符號
4. 重定位和初始化
問題三:全域性符號介入
動態連結過程中最關鍵的第3步可以看到,當多個共享目標檔案中包含一個相同的符號,那麼會導致先被載入的符號佔住全域性符號表,後續共享目標檔案中相同符號被忽略。當我們程式碼中沒有很好的處理命名的話,會導致非常奇怪的錯誤,幸運的話立刻core dump,不幸的話直到程式執行很久以後才莫名其妙的core dump,甚至永遠不會core dump但是結果不正確。
如下圖所示,main.cpp中會用到兩個動態庫libadd.so,libadd1.so的符號,我們把重點
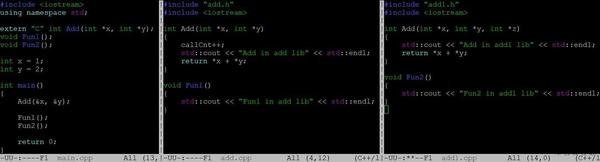
放在Add函式的處理上,當我們以g++ main.cpp libadd.so libadd1.so編譯時,程式輸出“Add in add lib”說明Add是用的libadd.so中的符號(add.cpp),當我們以g++ main.cpp libadd1.so libadd.so編譯時,程式輸出“Add in add1 lib”說明Add是用的libadd1.so中的符號,這時候問題就大了,呼叫方main.cpp中認為Add只有兩個引數,而add1.cpp中認為Add有三個引數,程式中如果有這樣的程式碼,可以預見很可能造成巨大的混亂。具體符號解析我們可以通過LD_DEBUG=all ./a.out來觀察Add的解析過程,如下圖所示:左邊是對應libadd.so在編譯時放在前面的情況,Add繫結在libadd.so中,右邊對應libadd1.so放前面的情況,Add繫結在libadd1.so中。

執行時載入動態庫:
有了動態連結和共享目標檔案的加持,Linux提供了一種更加靈活的模組載入方式:通過提供dlopen,dlsym,dlclose,dlerror幾個API,可以實現在執行的時候動態載入模組,從而實現外掛的功能。
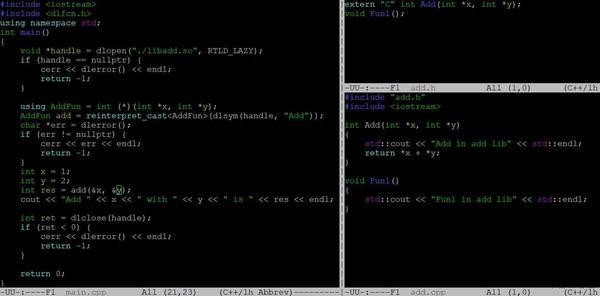
如下程式碼演示了動態載入Add函式的過程,add.cpp按照正常編譯“g++ -fPIC –shared –o libadd.so add.cpp”成libadd.so,main.cpp通過“g++ main.cpp -ldl”編譯為a.out。main.cpp中首先通過dlopen介面取得一個控制代碼void *handle,然後通過dlsym從控制代碼中查詢符號Add,找到後將其轉化為Add函式,然後就可以按照正常的函式使用,最後dlclose關閉控制代碼,期間有任何錯誤可以通過dlerror來獲取。
問題四:靜態全域性變數與動態庫導致double free
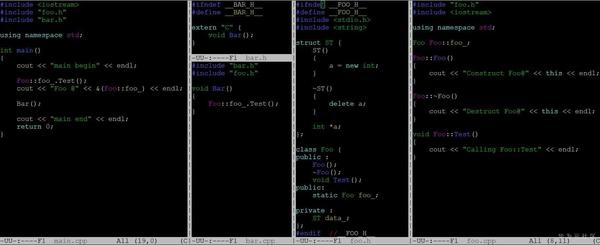
在全面瞭解了動態連結相關知識後,我們來看一個靜態全域性變數和動態庫糾結在一起引發的問題,程式碼如下,foo.cpp中有一個靜態全域性物件foo_,foo.cpp會編譯成一個libfoo.a,bar.cpp依賴libfoo.a庫,它本身會編譯成libbar.so,main.cpp既依賴於libfoo.a又依賴libbar.so。
編譯的makefile如下:
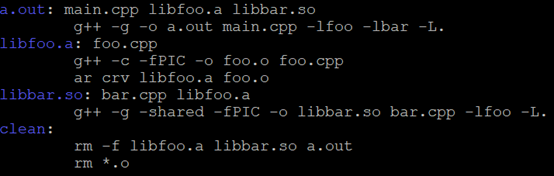
執行a.out會導致double free的錯誤。這是由於在一個位置上呼叫了兩次解構函式造成的。之所以會這樣是因為連結的時候先連結的靜態庫,將foo_的符號解析為靜態庫中的全域性變數,當動態連結libbar.so時,由於全域性已經有符號foo_,因此根據全域性符號介入,動態庫中對foo_的引用會指向靜態庫中版本,導致最後在同一個物件上析構了兩次。

解決辦法如下:
1. 不使用全域性物件
2. 編譯時候調換庫的順序,動態庫放在前面,這樣全域性只會有一個foo_物件
3. 全部使用動態庫
4. 通過編譯器引數來控制符號的可見性。
總結:
通過四個編譯連結中碰到的問題,基本把編譯連結的這些事覆蓋了一遍,有了這些基礎,在日常工作中應對一般的編譯連結問題應該可以做到遊刃有餘。由於篇幅有限,文章省略了大量的細節,主要集中在大的框架原理性梳理,如果想進一步深挖相關的細節,可參與相關參考文獻,以及閱讀elf.h相關的標頭檔案。
參考文獻:
1. 《連結器和載入器》
2. 《深入理解計算機系統》
3. 《程式設計師的自我修養》
4. http://www.gnu.org/software/binutils/
注1:本文所涉及工具可從http://www.gnu.org/software/binutils/獲取詳細資訊
注2:本文示例程式碼圖片中,每個視窗下面的白色區域有這份程式碼對應的檔名稱,注意匹配對應文中說明
點選關注,第一時間瞭解華為雲新鮮技