
《kubernetes + .net core 》dev ops部分
阿新 • • 發佈:2020-10-03
[TOC]
# 1.kubernetes 預備知識
kubernetes是一個用go語言寫的容器編排框架,常與docker搭配使用。
kubernetes是谷歌內部的容器編排框架的開源實現。可以用來方便的管理容器叢集。具有很多 優點,要了解這些優點,需要先來了解一下kubernetes中的叢集資源。這裡指的是kubernetes裡的原生的資源,kubernetes也支援自定義的資源。
## 1.1 叢集資源
不區分名稱空間
+ cluster role
+ namespace
+ node
+ persistent volume
+ storage class
### 1.1.1 role
+ 普通角色 role
+ 叢集角色 culster role
群集預設採用`RBAC(role base access control)`進行叢集資源的訪問控制,可以將角色作用於`使用者user`或`服務service`,限制它們訪問群集資源的許可權範圍。
其中角色又區分為 `叢集角色 cluster role` 和`普通的角色 role` ,他們的區別是可以作用的範圍不一致。
普通角色必有名稱空間限制,只能作用於與它同名稱空間的使用者或服務。
叢集角色沒有名稱空間限制,可以用於所有名稱空間的使用者或服務。下面的目錄中會詳細介紹。先在這裡提一下
### 1.1.2 namespace
不指定時預設作用default名稱空間,服務在跨名稱空間訪問其他服務時 域名需要加上名稱空間後輟才能訪問
### 1.1.3 node
+ 主節點 master
+ 工作節點 none
+ 邊緣節點 none
是一個包含作業系統的機器,作業系統可以是Linux也可以是windwos,可以是實體機也可以是虛擬機器,其中的區別下面的其他目錄會詳細說明
### 1.1.4 persistent volume
持久卷 ,支援的型別很多,包括谷歌 亞馬遜 阿里云云服務提供商的各種儲存.
由於我們的專案一般是用於區域網內的,所以這裡我著重介紹`nfs(network file system)`
### 1.1.5 storage class
儲存類,用於根據pvc 自動建立/自動掛載/自動回收 對應的nfs目錄前
## 1.2 工作量資源 (消耗cpu ram)
+ pod
+ job
+ cron job
+ replica set
+ deployment
+ daemon set
+ statefull set
### 1.2.1 pod
工作量的最小單位是pod 其他的型別的工作量都是控制Pod的。
pod相當於docker 中的docker composite,可以由單個或多個容器組成,每個pod有自己的docker網路,pod裡的container處於同個區域網中。
其他的控制器都有一個pod template,用於建立Pod
### 1.2.2 job
工作,一但應用到叢集將會建立一個pod做一些工作,具體的工作內容由Pod的實現決定,工作完成後Pod自動終結。
### 1.2.3 cron job
定時工作任務,一但應用到叢集,叢集將會定時建立pod 做一些工作,工作完成後pod自動終結
### 1.2.4 replica set
複製集或稱為副本集,一但應用到叢集,會建立相n個相同的 pod,並且會維護這個pod的數量,如果有pod異常終結,replica set會建立一個新的Pod 以維護使用者指定的數量
### 1.2.5 deplyoment
deplyoment常用來建立無狀態的應用叢集。
部署,deplyoment依賴於replicaset ,它支援滾動更新,滾動更新的原理是,在原有的一個replica set的基礎上建立一個新版本的replica set ,
舊版本的replicaset 逐個減少 ,新版本的replicaset逐個新增, 可以設定一個引數指定滾動更新時要保持的最小可用pod數量。
### 1.2.6 daemon set
守護程序集 ,顧名思義,他的作用就是維護某個作業系統(node)的某個程序(pod)始終工作。當一個dameon set被應用到k8s叢集,所有它指定的節點上都會建立某個pod
比如日誌採集器 一個節點上有一個,用daemon set就十分應景。
### 1.2.7 stateful set
stateful set常用於建立有狀態的服務叢集,它具有以下特點
+ 穩定的唯一網路識別符號
+ 穩定,持久的儲存
+ 有序,順暢的部署和擴充套件
+ 有序的自動滾動更新
舉個例子,你有一個容器需要存資料,比如mysql容器,這時你用deplyoment就不合適,因為多個mysql例項各自應該有自己的儲存,DNS名稱。
這個時候就應該使用statefull set。它原理是建立無頭服務(沒有叢集ip的服務)和有序號的Pod,並把這個無頭服務的域名+有序號的主機名(pod名稱),獲得唯一的DNS名稱
比如設定stateful set的名稱為web,redplica=2,則會有序的建立兩個Pod:web-0 web-1,當web-0就緒後才會建立web-1,如果是擴容時也是這樣的,而收容的時候順序而是反過來的,會從序號大的Pod開始刪除多餘的Pod
如果把一個名稱為nginx的無頭服務指向這個statufulset,則web-0的dns名稱應該為 web-0.nginx
並且 stateful set會為這兩個Pod建立各自的pvc,由於pod的名稱是唯一的,所以故障重建Pod時,可以把新的Pod關聯到原有的儲存捲上
## 1.3 儲存和配置資源 (消耗儲存)
+ config map
+ secret map
+ persistent volume claim
### 1.3.1 config map
ConfigMap 允許你將配置檔案與映象檔案分離,以使容器化的應用程式具有可移植性。
+ 如何建立
+ 如何使用
建立:
```bash
# 從資料夾建立(資料夾裡的文字檔案將會被建立成config map
kubectl create configmap my-config --from-file=path/to/bar
# 從檔案建立
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# 從字串建立
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
# 從鍵值文字建立
kubectl create configmap my-config --from-file=path/to/bar
# 從env檔案建立
kubectl create configmap my-config --from-env-file=path/to/bar.env
```
使用:
+ 作為pod的環境變數
+ 作為儲存卷掛載到Pod
### 1.3.2 secrets
Secret 是一種包含少量敏感資訊例如密碼、令牌或金鑰的物件。 這樣的資訊可能會被放在 Pod 規約中或者映象中。 使用者可以建立 Secret,同時系統也建立了一些 Secret。
### 1.3.3 pvc
+ 由叢集管理員管理
+ 由storage class管理
如果由叢集管理員管理,由開發人員應向叢集管理員申請Pv ,叢集管理員要手動的建立Pv,pvc,把pvc給開發人員,開發人員手動掛載pvc到pod
如果由storage class管理,則叢集管理員只要建立一個provider, 之後provider會自動監視叢集中的Pvc 和pod ,自動建立pv和掛載
# 2.kubernetes node 元件
kubernetes叢集中,至少要有一個主節點,主節點應該有以下元件
+ kubelet
+ kuber-proxy
+ cni網路外掛
+ etcd
+ kube-apiserver
+ coreDNS
+ kube-controller-manager
+ kube-schedule
普通節點的元件
+ kubelet
+ kube-proxy
+ cni網路外掛
## 2.1 kubectl
kubernetes節點代理元件,每個node上都需要有,他不是Kubernetes建立的容器,所以在叢集中查不到。
他的主要做的工作是
1.向kube api以hostname為名註冊節點
2.監視pod執行引數,使Pod以引數預期的狀態執行,所以Pod有異常通常都能查詢Kubelet的日誌來排查錯誤
## 2.2 kube-proxy
kubernetes 的服務相關的元件,每個Node上都需要有,除了無頭服務,其他所有服務都由他處理流量
k8s叢集在初始化的時候,會指定服務網段和pod網段,其中服務網段的ip都是虛擬Ip
他主要做的工作是:
監視叢集的服務,如果服務滿足某些條件,則通過ipvs 把這個服務的流量轉發到各個後端Pod (cluster ip)
## 2.3 cni網路外掛
cni: container network interface
k8s稱之為視窗編排叢集,他的核心思想是把不同的容器網路聯合起來,使所有的pod都在一個扁平的網路裡,可以互換訪問
為達這個目的就需要容器網路外掛,下面介紹一下主流的cni外掛,並大致說明一下優劣
+ flannel
+ calico
+ 其他
### 2.3.1 flannel

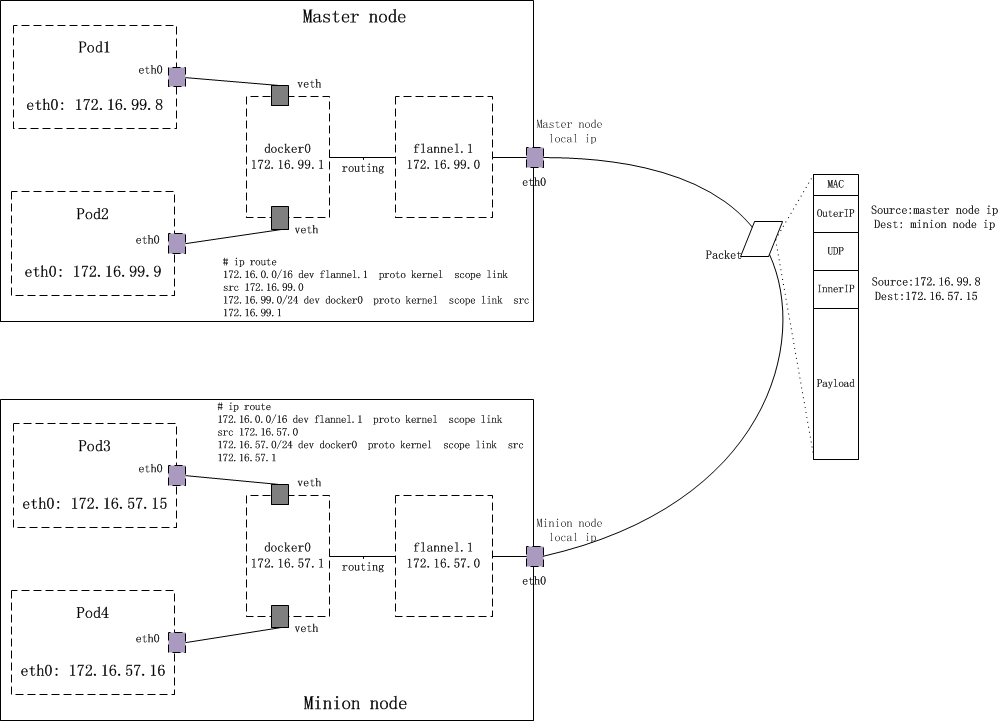
flanel是橋接模式的代表外掛,
他的工作原理是用daemonset在每個節點上部署flannel外掛,外掛設定容器網路並把容器網路資訊通過 kube api儲存到etcd中 。
這樣就確保不會重複註冊網段了,與不同node上的Pod通過 kube-proxy打包 發給其他Node的kuber proxy,kuber proxy再拆包,發給pod
以達到跨node的扁平網路訪問. 這種方式也稱vxlan 或overlay
優點:
+ 網路協議簡單,容易分析。
+ 社群規模比較大,成功案例比較多,資料比較全面,入門比較簡單
缺點:
+ 由於有打包 拆包, 所以通訊效率比較低下
+ 不支援網路策略
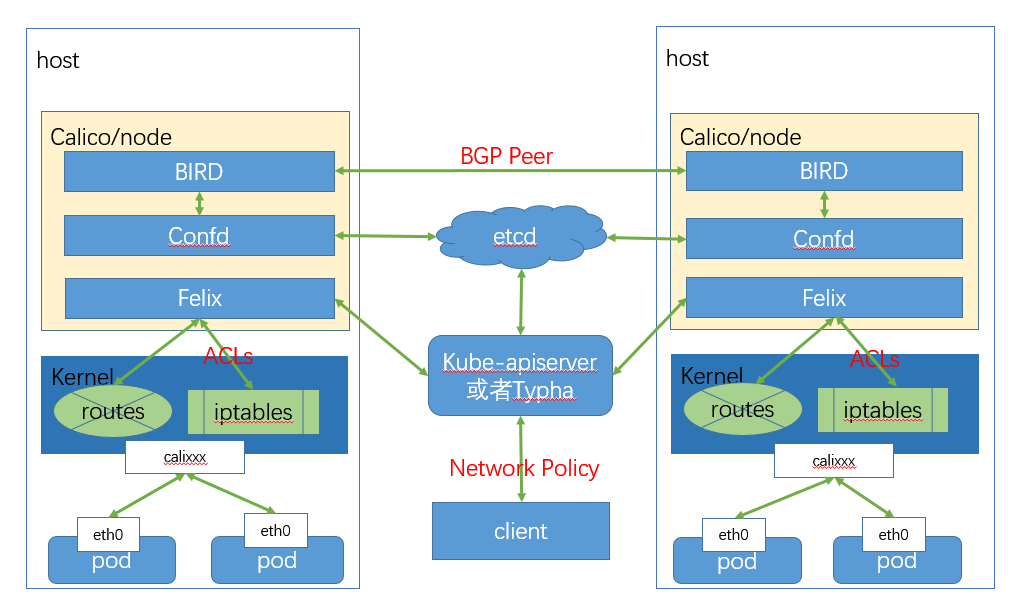
### 2.3.2 calico
calico 是閘道器模式的代表外掛。 它主要由以下幾部分構成
它基於邊界閘道器協議 BGP(border gateway protocol)
他的工作原理是用daemonset在每個節點上部署calico node, 來構成扁平化容器網路
calico node由以下幾個元件
+ felix
+ confid
+ BIRD(BGP Internet route daemon)
felix 負責編寫路由和訪問控制列表
confid 用於把 felix生成的資料記錄到etcd,用於持久化規則
BIRD 用於廣播felix寫到系統核心的路由規則和訪問控制列表acl和calico的網路
當叢集規模比較大的時候還可以可選的安裝 BGP Rotue Reflector(BIRD) 和 Typha
前者用於快速廣播協議,後者用於直接與ETCD通訊,減小 kubeapi的壓力
優點:
+ pod跨node的網路流量 直接進系統核心 走路由表,效率極高
+ 支援網路策略
缺點:
+ 跨node的資料包經過DNAT和SNAT後,分析網路封包會比較複雜
+ 部署也比較複雜

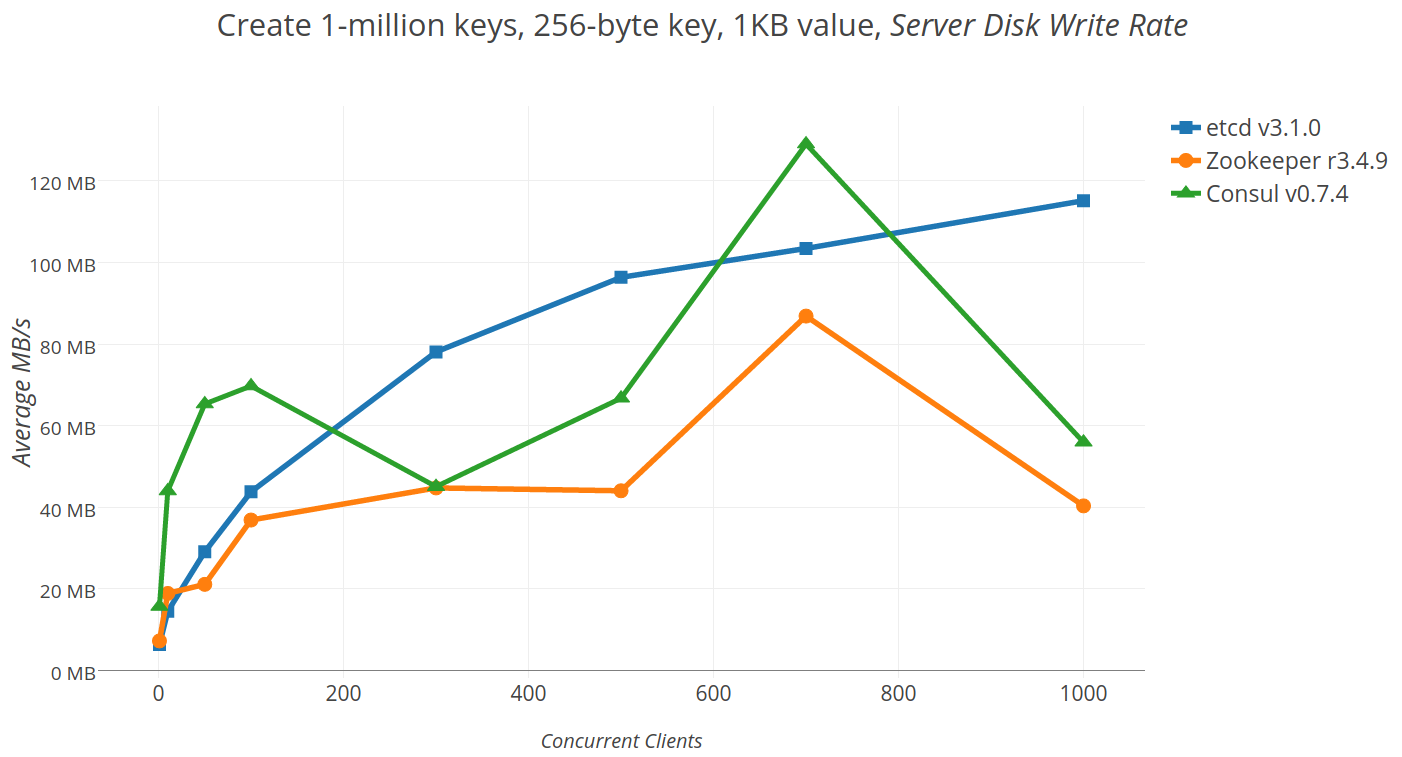
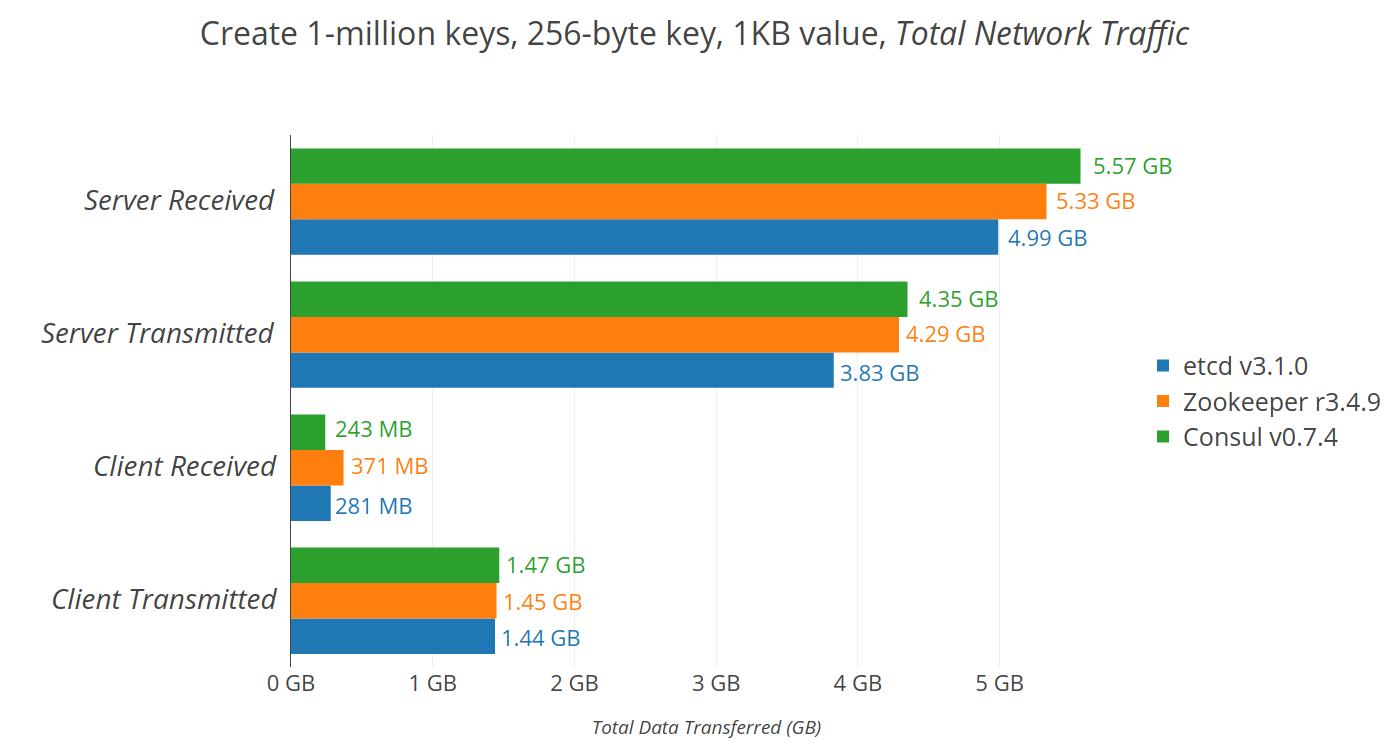
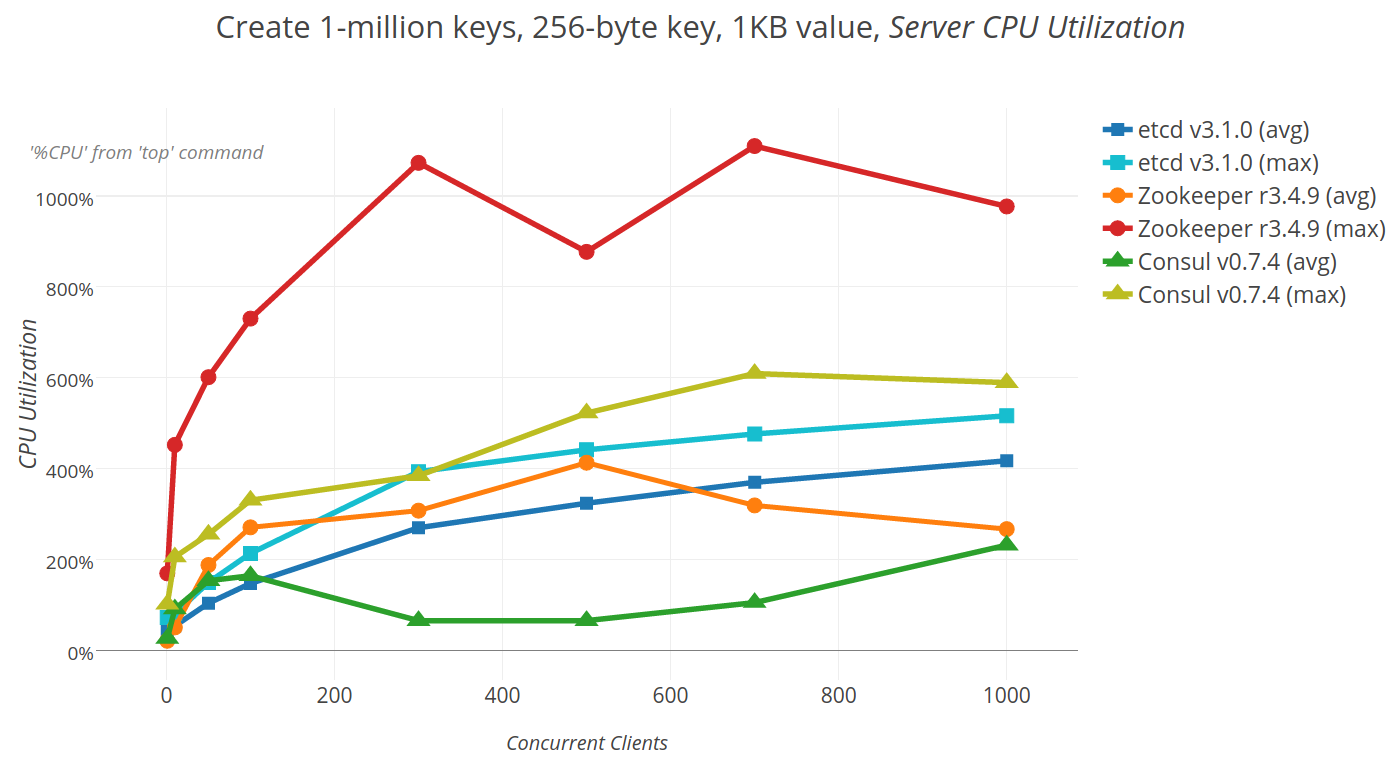
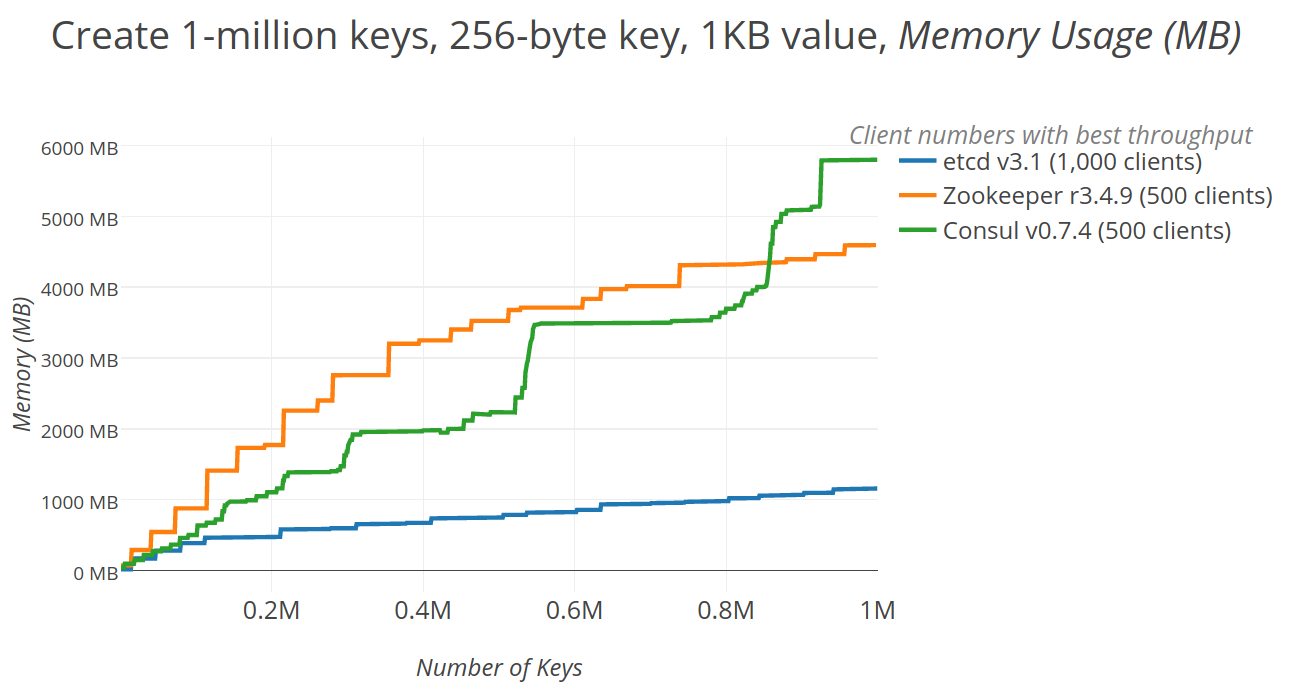
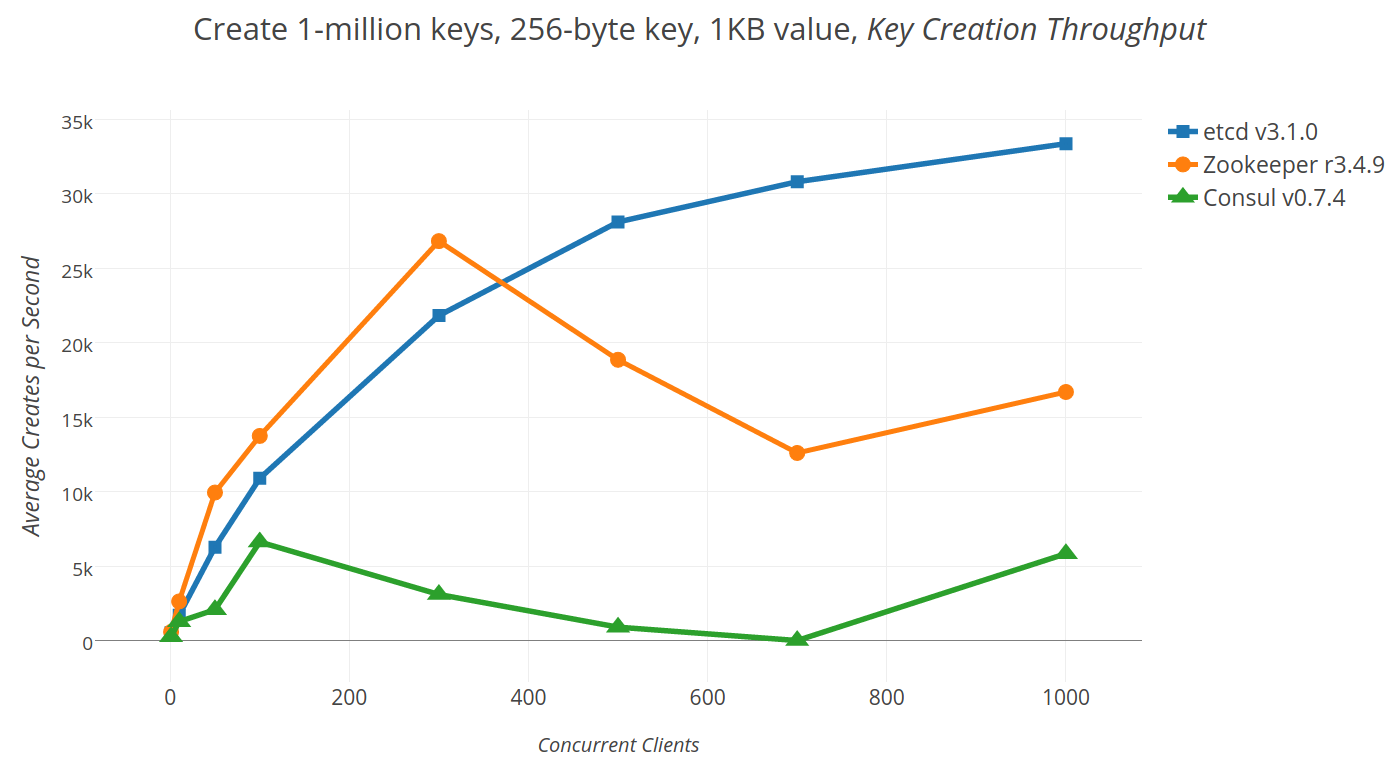
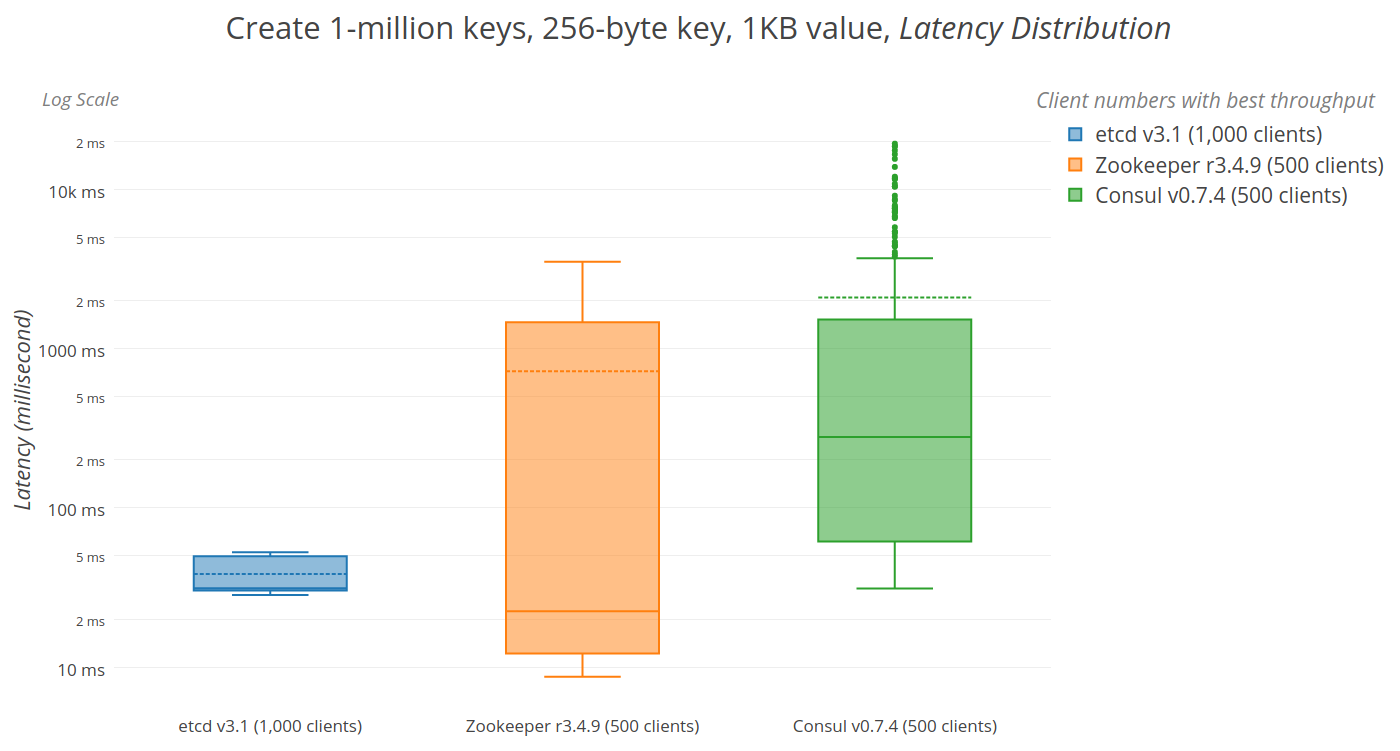
## 2.4 etcd
etc distributed ,一款使用go語言編寫的基於raft共識演算法的分散式KV快取框架 ,
不像redis重效能,而像zookeeper 一樣重資料一致性
特點是有較高的寫入效能






## 2.5 kube-apiserver
k8s 暴露給外部的web api,用於叢集的互動 有各種語言的api client開源專案 ,程式設計師也可以在程式中引用,監視一些叢集資源
## 2.6 coreDNS
用於叢集中的service 和 pod的域名解析,
也可以配置對叢集外的域名應該用哪個DNS解析
## 2.7 kube-controller-manager
用於 各種控制器(消耗cpu ram)的管理
## 2.8 kube-schedule
用於 管理控制 Pod排程相關
# 3.叢集的高可用
+ 分散式共識演算法 Raft
+ keepalived
+ haproxy

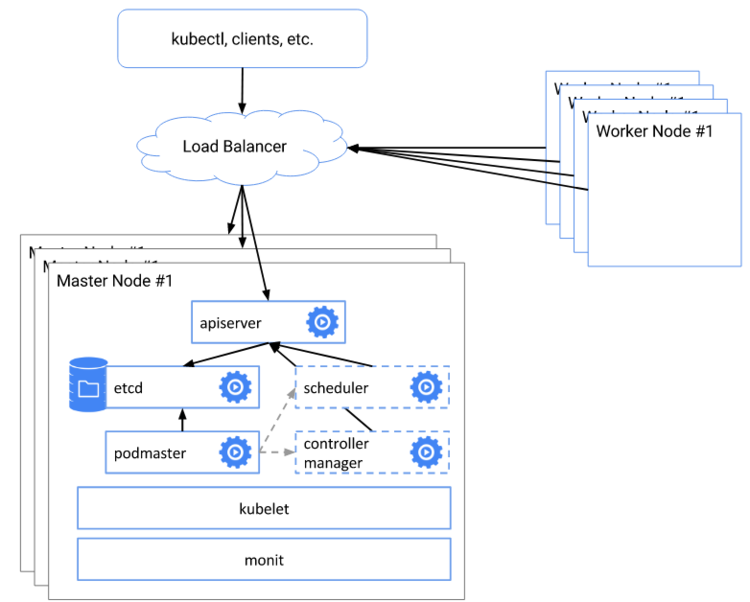
## 3.1 etcd的raft演算法
[raft](http://thesecretlivesofdata.com/raft/)
raft是etcd的共識演算法,kubernetes用etcd來儲存叢集的配置。config map /secret都是基於etcd。
理解raft共識演算法可以知道
+ 為什麼高可用叢集主節點是3個 5個 7個 而不是 2個 4個 6個
+ kubernetes的主節點發生單點故障的時候, 儲存的行為會有什麼改變
## 3.2 keepalived
在高可用環境, keepalived用於虛擬ip的選舉,一旦持有虛擬Ip的節點發生故障,其他的主節點會選擇出新的主節點持有虛擬ip。並且可以配置smtp資訊,當節點故障的時候發郵件通知相關的責任人
```bash
onfiguration File for keepalived
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
lvs_sync_daemon_inteface eth0
virtual_router_id 79
advert_int 1
priority 100 #權重 m1 100 m2 90 m3 80
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.44.200/24 dev eth0
}
}
```
## 3.3 haproxy
每個主節點都部署了haproxy代理kube api埠, 所以當它持有虛擬ip的時候,會把所有對kube api的請求負載均衡到所有的主節點上。
```bash
global
chroot /var/lib/haproxy
daemon
group haproxy
user haproxy
log 127.0.0.1:514 local0 warning
pidfile /var/lib/haproxy.pid
maxconn 20000
spread-checks 3
nbproc 8
defaults
log global
mode tcp
retries 3
option redispatch
listen https-apiserver
bind *:8443
mode tcp
balance roundrobin
timeout server 900s
timeout connect 15s
server m1 192.168.44.201:6443 check port 6443 inter 5000 fall 5
server m2 192.168.44.202:6443 check port 6443 inter 5000 fall 5
server m3 192.168.44.203:6443 check port 6443 inter 5000 fall 5
```
# 4 認證/授權
## 4.1 authentication
kubernetes叢集中的認證物件分為
1. 使用者
2. 服務
除此之外,還有一些其他的非kubernetes叢集管理的服務會需要訪問叢集資源的情況
但是這個暫時不實踐,因為haoyun目前不會使用到這種情況
### 4.1.1 使用者
使用者不是kuebrnetes 的資源,所以單獨拎出來講。
#### 4.1.1.1 檢視使用者
master node在加入叢集時,會提示我們手動複製預設的管理員使用者到 `$HOME/.kube `資料夾
所以檢視 $HOME/.kube/config檔案可以知道叢集 使用者 認證上下文
```bash
[root@www .kube]# cat config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZ...#略
server: https://www.haoyun.vip:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDR...#略
client-key-data: LS0tLS1CRUdJTiBS..#.略
```
#### 4.1.1.2 新增使用者
建立1使用者,並進入使用者資料夾
```bash
[root@www .kube]# useradd hbb && cd /home/hbb
```
建立私鑰
```bash
[root@www hbb]# openssl genrsa -out hbb_privateKey.key 2048
Generating RSA private key, 2048 bit long modulus
............................................................+++
.............................................................................................................................................................+++
e is 65537 (0x10001)
```
建立x.509證書籤名請求 (CSR) ,CN會被識別為使用者名稱 O會被識別為組
```bash
openssl req -new -key hbb_privateKey.key \
-out hbb.csr \
-subj "/CN=hbb/O=hbbGroup1/O=hbbGroup2"
#O可以省略也可以寫多個
```
為CSR簽入kubernetes 的證書和證書公鑰,生成證書
```bash
openssl x509 -req -in hbb.csr \
-CA /etc/kubernetes/pki/ca.crt \
-CAkey /etc/kubernetes/pki/ca.key \
-CAcreateserial \
-out hbb.crt -days 50000
#證書有效天數 50000天
```
建立證書目錄 ,存入把公鑰(hbb.crt)和私鑰(hbb_private.key) 放進去
```bash
[root@www hbb]# mkdir .certs
[root@www hbb]# cd .certs/
[root@www .certs]# mv ../hbb_privateKey.key ../hbb.crt .
[root@www .certs]# ll
total 8
-rw-r--r--. 1 root root 940 Sep 5 15:41 hbb.csr
-rw-r--r--. 1 root root 1679 Sep 5 15:29 hbb_privateKey.key
```
建立叢集使用者
```bash
kubectl config set-credentials hbb \
--client-certificate=/home/hbb/.certs/hbb.crt \
--client-key=/home/hbb/.certs/jean_privatekey.key
```
建立使用者上下文
```bash
kubectl config set-context hbb-context \
--cluster=kubernetes --user=hbb
```
這時原有的config檔案裡就多了Hbb這個使用者了
```yaml
users:
- name: hbb
user:
client-certificate: /home/hbb/.certs/hbb.crt
client-key: /home/hbb/.certs/hbb_privatekey.key
```
複製 原有的.kube/config檔案到hbb使用者資料夾 ,在副本上刪除kubernetes-admin的上下文和使用者資訊。
```bash
[root@www .kube]# mkdir /home/hbb/.kube
[root@www .kube]# cp config /home/hbb/.kube/
[root@www .kube]# cd /home/hbb/.kube
[root@www .kube]# vim config
[root@www .kube]# cat config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJU...#略
server: https://www.haoyun.vip:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: hbb
name: hbb-context
current-context: hbb-context
kind: Config
preferences: {}
users:
- name: hbb
user:
client-certificate: /home/hbb/.certs/hbb.crt
client-key: /home/hbb/.certs/hbb_privateKey.key
```
之後把hbb使用者資料夾授權給hbb使用者
```bash
[root@www .kube]# chown -R hbb: /home/hbb/
#-R 遞迴資料夾
#hbb: 只設置了使用者沒有設定組
```
這樣就建立一個使用者了,此時退出root使用者,使用hbb使用者登上去,預設就是使用Hbb的user去訪問叢集
但是這時還沒有給hbb授權,所以基本上什麼操作都執行不了,因為沒有許可權
```bash
[hbb@www .certs]$ kubectl get pod -A
Error from server (Forbidden): pods is forbidden: User "hbb" cannot list resource "pods" in API group "" at the cluster scope
```
## 4.2 authorization (RBAC)
[官方文件](https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/)
相關的kubernetes 資源
+ namespace
+ roles/clusterRoles
+ rolebindings/clusterRolebindings
### 4.2.1 namespace
roles和rolebindings 如果要建立關聯,他們必須是同一個名稱空間內。
clusterRoles和clusterRolebindings 沒有名稱空間的限制,它們的規則作用於叢集範圍
### 4.2.2 roles/clusterRoles
在 RBAC API 中,一個角色包含一組相關許可權的規則。許可權是純粹累加的(不存在拒絕某操作的規則)。 角色可以用 `Role` 來定義到某個名稱空間上, 或者用 `ClusterRole` 來定義到整個叢集作用域。
一個 `Role` 只可以用來對某一名稱空間中的資源賦予訪問許可權。 下面的 `Role` 示例定義到名稱為 "default" 的名稱空間,可以用來授予對該名稱空間中的 Pods 的讀取許可權:
```yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default #如果是clusterRoles 則沒刪除這一行
name: pod-reader
rules:
- apiGroups: [""] # "" 指定 API 組
resources: ["pods","pods/log"] #子資源
verbs: ["get", "watch", "list"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-configmap"] #具體名稱的資源
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
#下面這個只有clusterRoles 才可以使用
- nonResourceURLs: ["/healthz", "/healthz/*"] # '*' 在 nonResourceURL 中的意思是字尾全域性匹配。
verbs: ["get", "post"]
```
clusterRoles比 roles 多出以下的能力
- 叢集範圍資源 (比如 nodes)
- 非資源端點(比如 "/healthz")
- 跨名稱空間訪問的有名字空間作用域的資源(如 get pods --all-namespaces)
### 4.2.3 rolebindings/clusterRolebindings
rolebindings也可以使用ClusterRoles,會將裡面的資源的作用域限定到rolebindings的名稱空間範圍內。
```yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User #使用者
name: jane
apiGroup: rbac.authorization.k8s.io
- kind: Group #使用者組
name: "frontend-admins"
apiGroup: rbac.authorization.k8s.io
- kind: ServiceAccount #服務帳戶
name: default
namespace: kube-system
- kind: Group # 所有myNamespace名稱空間下的服務
name: system:serviceaccounts:myNamespace
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有名稱空間的所有服務
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有認證過的使用者
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有未誰的使用者
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role #可以是叢集名角或普通的角色
name: pod-reader
apiGroup: rbac.authorization.k8s.io
```
# 5.服務
[官方文件](https://kubernetes.io/zh/docs/concepts/services-networking/service/#publishing-services-service-types)
服務是微服務抽象,常用於通過選擇符訪問一組Pod, 也可以訪問其他物件,
+ 叢集外部的服務
+ 其他名稱空間的服務
上面這兩種情況,服務的選擇符可以省略。
## 5.1 代理模式
kubernetes v1.0時使用使用者空間代理 (userspace)
v1.1添加了iptable代理模式,
v1.2預設使用iptables代理模式
v1.11新增ipvs 模式
當Node上不支援ipvs會回退使用iptables模式
### 5.1.1 userSpace模式

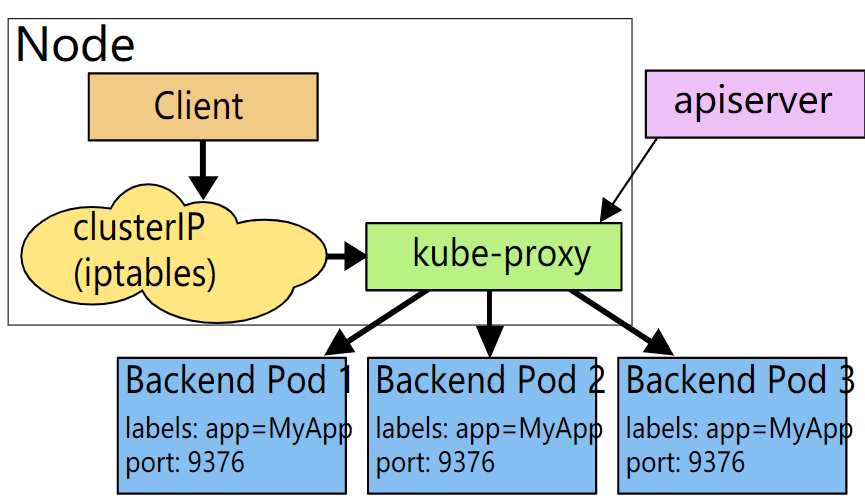
每個結點上部署kube-proxy ,它會監視主結點的apiserver對service 和 endpoints的增刪改
為每個server隨機開一個埠,並寫入叢集Ip寫入iptables,把對叢集服務的叢集Ip的流量 轉發到這個隨機的埠上 ,
然後再轉發到後端的Pod上, 一般是採用輪詢的規則,根據服務上的sessionAnfinity來設定連線的親和性
### 5.1.2 iptables模式


與userspace的區別是 不僅把service寫入Iptables,同時把endpoints也寫入了iptables,
所以不用在核心空間和使用者空間之間來回切換,效能提升
### 5.1.3 ipvs

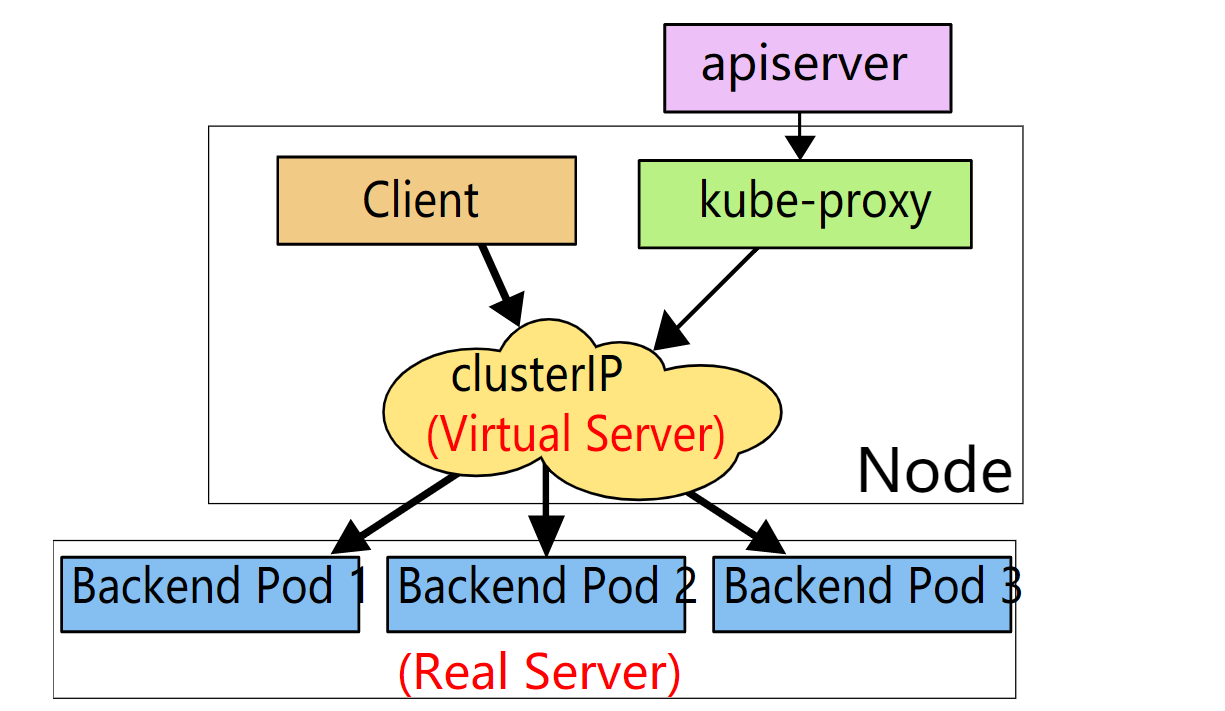
ipvs(ip virtrual server)和iptables都是基於netfilter ,但ipvs以雜湊表做為基礎資料結構,並工作在核心空間
相比iptables,所以他有更好的效能,也支援更多的負載均衡演算法
+ rr: round-robin 輪詢
+ lc: least connection (smallest number of open connections) 最少連線
+ dh: destination hashing 目標雜湊
+ sh: source hashing 源雜湊
+ sed: shortest expected delay 最低延遲
+ nq: never queue 不排隊
如果需要粘性會話,可以在服務中設定
service.spec.sessionAffinity 為 clusterip ,預設是none
service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 可以調整會話最長時間,預設是10800秒
## 5.2 服務發現
服務可以通過環境變數和DNS的方式來發現服務,推薦的做法是通過DNS
### 5.2.1 通過環境變數
一個名稱為 "redis-master" 的 Service 暴露了 TCP 埠 6379, 同時給它分配了 Cluster IP 地址 10.0.0.11 ,
這個 Service 生成了如下環境變數:
```bash
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
```
如果需要在pod中使用這些環境變數,需要在啟動pod之前先啟動服務。
### 5.2.2 通過DNS
服務直接用服務名稱為域名,
Pod會在服務之前加上ip為域名
例如在名稱空間 hbb下有服務 hbb-api, 服務指向的後端pod Ip地址是10-244-6-27.,則會有dns記錄
```bash
# 服務
hscadaexapi.hbb.svc.cluster.local
```
```bash
# pod
10-244-6-27.hscadaexapi.hbb.svc.cluster.local
```
dns應該儘可能使用,最好不要使用環境變數的方式
## 5.3 服務型別
+ clusterip 叢集IP
+ nodeport 結點IP
+ loadbalance 外部負載均衡器
+ external ip 外部IP
+ none 無頭服務(有狀態服務)
+ externalname 外部服務
### 5.3.1 clusterip 叢集IP
虛擬的ip ,通常指向一組pod (真實ip)
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
```
### 5.3.2 nodeport 結點IP
每個主結點上的具體埠,通常把 node ip+埠 轉發到 一組pod(真實ip)
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: MyApp
ports:
# 預設情況下,為了方便起見,`targetPort` 被設定為與 `port` 欄位相同的值。
- port: 80
targetPort: 80
# 可選欄位
# 預設情況下,為了方便起見,Kubernetes 控制平面會從某個範圍內分配一個埠號(預設:30000-32767)
nodePort: 30007
```
### 5.3.3 loadbalance 外部負載均衡器
通常把 外部流量 轉發到 一組pod(真實ip) ,外部ip一般是在雙網絡卡的邊緣節點上
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
```
### 5.3.4 external IP
將外部的流量引入服務 ,這種外部Ip 不由叢集管理,由由叢集管理員維護
```yaml
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
```
### 5.3.5 none 無頭服務(有狀態服務)
kube-proxy元件不對無頭服務進行代理,無頭服務 加上序號 指向 Pod,固定搭配,
所以即使 服務的pod掛了, 重啟來的服務的 域名也不會換一個,用於有狀態的服務。
後面講到Pod控制器statefulset會再細講
### 5.3.6 externalname 外部服務
kube-proxy元件不會對外部服務進行代理則是對映到dns 用於描述一個叢集外部的服務,有解耦合的作用,
所以它和無頭服務一樣沒有選擇器,他也不由叢集管理,而是由叢集管理員維護
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
```
## 5.4 叢集入口 ingress
由於iptables代理模組或亦 ipvs代理模式都是4層負載均衡,無法對7層協議進行負載均衡,所以對於外部的流量 ,常使用入口資源來進行負載均衡,把外部的流量均衡到服務上
+ ingress contorller
+ ingress 資源
### 5.4.1 ingress controller
ingress controller 是負載均衡器例項,一個叢集中可以部署多個, 每個又可以自為一個負載均衡叢集
在建立ingress資源的時候,可以用 註解Annotations:來指定要使用哪個ingress controller
````yaml
kubernetes.io/ingress.class: nginx
````
這個nginx是controller容器啟動時 用命令列的方式指定的
```bash
Args:
/nginx-ingress-controller
--default-backend-service=kube-system/my-nginx-ingress-default-backend
--election-id=ingress-controller-leader
--ingress-class=nginx
```
### 5.4.2 ingress 資源
[Ingress](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/#ingress-v1beta1-networking-k8s-io) 公開了從叢集外部到叢集內服務的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 資源上定義的規則控制。
可以將 Ingress 配置為服務提供外部可訪問的 URL、負載均衡流量、終止 SSL/TLS,以及提供基於名稱的虛擬主機等能力。 Ingress 控制器 通常負責通過負載均衡器來實現 Ingress,儘管它也可以配置邊緣路由器或其他前端來幫助處理流量。
Ingress 不會公開任意埠或協議。 將 HTTP 和 HTTPS 以外的服務公開到 Internet 時,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 型別的服務
#### 5.4.2.1 捕獲重寫Path 轉發
```yaml
`apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: test-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
serviceName: test
servicePort: 80
```
#### 5.4.2.2 基於主機域名轉發
```yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: service1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: service2
servicePort: 80
```
# 6.配置和儲存
+ config map
+ secrets
+ nfs persistent volume
+ empty/hostpath
## 6.1 config map
ConfigMap 允許你將配置檔案與映象檔案分離,以使容器化的應用程式具有可移植性。
### 6.1.1 建立config map
```bash
# 從資料夾建立(資料夾裡的文字檔案將會被建立成config map
kubectl create configmap my-config --from-file=path/to/bar
# 從檔案建立
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# 從字串建立
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
# 從鍵值文字建立
kubectl create configmap my-config --from-file=path/to/bar
# 從env檔案建立
kubectl create configmap my-config --from-env-file=path/to/bar.env
```
### 6.1.2 使用config map
+ 作為pod的環境變數
+ 作為儲存卷掛載到Pod
#### 6.1.2.1 作為pod的環境變數
建立1個config map 配置檔案,在default名稱空間裡
```bash
kubectl create configmap hbb-config --from-literal=key1=aaa --from-literal=key2=bbb
```
建立一個pod ,使用busybox映象,並把上面的cm 載入到環境變數,在pod 的container裡面加上
```yaml
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
env:
- name: HBBKEY1
valueFrom:
configMapKeyRef:
name: hbb-config
key: key1
- name: HBBKEY2
valueFrom:
configMapKeyRef:
name: hbb-config
key: key2
```
簡易寫法,載入所有hbb-config裡的key value
````yaml
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
envFrom:
- configMapRef:
name: hbb-config
````
經測試,如果修改了config map ,Pod的環境變數是不會自動更新的,除非刪除pod重新建立
#### 6.1.2.2 作為儲存卷掛載到pod
```yaml
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
volumeMounts:
- name: hbb-cm-volume
mountPath: /etc/config
volumes:
- name: hbb-cm-volume
configMap:
name: hbb-config
```
經驗證,修改config map後,去檢視掛載上去的卷,檔案中的值也隨之發生了改變,所以這種方式是比較好的方式。
## 6.2 secrets
Secret 是一種包含少量敏感資訊例如密碼、令牌或金鑰的物件。 這樣的資訊可能會被放在 Pod 規約中或者映象中。 使用者可以建立 Secret,同時系統也建立了一些 Secret。
+ 建立secret
+ 驗證 secret
+ 使用 secret
### 6.2.1 建立secrets
+ 通過檔案生成
+ 通過字串生成
+ 手動建立
+ 通過stringData 應用時加密明文secret
+ 檢視驗證
#### 6.2.1.1 通過檔案生成
```bash
#生成檔案
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
#從檔案生成
kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
```
預設的鍵名就是檔名,如果要另外指定可以--from-file=[key=]source,密碼也是如此
```bash
#從檔案生成
kubectl create secret generic db-user-pass --from-file=hbb-key=./username.txt --from-file=hbb-pas=./password.txt
```
#### 6.2.1.2 通過字串生成
說明:特殊字元(例如 `$`、`*`、`*`、`=` 和 `!`)可能會被 sell轉義,所以要用''括起來
```bash
kubectl create secret generic dev-db-secret \
--from-literal=username=devuser \
--from-literal=password='S!B\*d$zDsb='
```
#### 6.2.1.3 手動建立 secret
加密使用者名稱admin和密碼password
```bash
[root@www ~]# echo -n 'admin' | base64 ; echo -n 'password' |base64
YWRtaW4=
cGFzc3dvcmQ=
```
建立一個mysecret.yaml
```yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
```
用kubectl 建立
```bash
kubectl apply -f ./mysecret.yaml
```
#### 6.2.1.4 通過stringData 應用時加密明文
建立1個 mysecret.yaml
```yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |-
apiUrl: "https://my.api.com/api/v1"
username: hbb
password: hbb-password
```
執行
```bash
kubectl apply -f ./mysecret.yaml
```
將會建立 一個mysecret 資源,裡面有一個config.yaml的key,它的value是一個加密的字串。
注: mysecret.yaml第7行的|- 的意思是:將下面三行字串組合起來,替換右邊的縮排(空格和換行)成一個換行符。
這種方式的好處是,可以和helm一起使用,helm使用go 的模版,可以配置明文的字元
### 6.2.2 檢視驗證secret
```bash
[root@www ~]# kubectl describe secret/dev-db-secret
Name: dev-db-secret
Namespace: default
Labels: