
Lane-Detection 近期車道線檢測論文閱讀總結
阿新 • • 發佈:2020-10-09
近期閱讀的幾篇關於車道線檢測的論文總結。
## 1. 車道線檢測任務需求分析
### 1.1 問題分析
針對車道線檢測任務,需要明確的問題包括:
(1)如何對車道線建模,即用什麼方式來表示車道線。
從應用的角度來說,最終需要的是車道線在世界座標系下的方程。而神經網路更適合提取影象層面的特徵,直接回歸方程引數不是不可能,但限制太多。
由此,網路推理輸出和最終結果之間存在一個Gap,需要相對複雜的後處理去解決。
(2)網路推理做到哪一步。
人在開車時觀察車道線,會同時關注兩方面資訊:
- 繪製在路面上的車道線標識本身
- 通過車道線標識,表徵的抽象的車道分隔邊界線
同樣,在網路結構設計時,也可以把推理目標設定為這兩類:
- 影象分割方案傾向於識別第一種資訊,對每一個畫素是否屬於車道線標識,以及標識的類別進行判斷。
- 類影象檢測方案傾向於識別第二種資訊,在設定的一系列anchor中判斷是否存在車道線,以及迴歸車道線的位置引數。
### 1.2 面臨挑戰
針對車道線檢測任務,面臨的挑戰主要有:
(1)車道線這種細長的形態結構,需要更加強大的高低層次特徵融合,來同時獲取全域性的空間結構關係,和細節處的定位精度。
(2)車道線的形態有很多不確定性,比如被遮擋,磨損,以及道路變化時本身的不連續性。需要網路針對這些情況有較強的推測能力。
(3)在實際應用中,車輛穩定行駛在車道中央的工況並不算關鍵工況,**車輛的偏離或換道過程才是關鍵工況**,此時會產生自車所在車道的切換,車道線也會發生左/右線的切換。
據此,一些提前給車道線賦值固定序號的方法,在實際使用中是有巨大缺陷的,在換道過程中會產生歧義的情況。
這種方法在刷資料集指標的時候可能效果OK,但在應用中,從網路結構設計的角度,無法應對換道這種關鍵工況。
## 2. 論文要點解讀
> 按照arXiv上釋出的時間順序。
### 《Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks》
[論文連結](https://arxiv.org/abs/1903.02193)
將車道線檢測作為一個分割問題來處理,最後輸出車道線前景和背景的2值分割圖。
網路整體上使用了CNN+RNN的結構。
CNN的部分採用了常規的Encoder-Decoder結構。
在Encoder和Decoder之間插入`ConvLSTM`模組,通過`ConvLSTM`對Encoder部分提取的Feature-map進行處理,提取有用的隱含歷史資訊。如下圖所示:
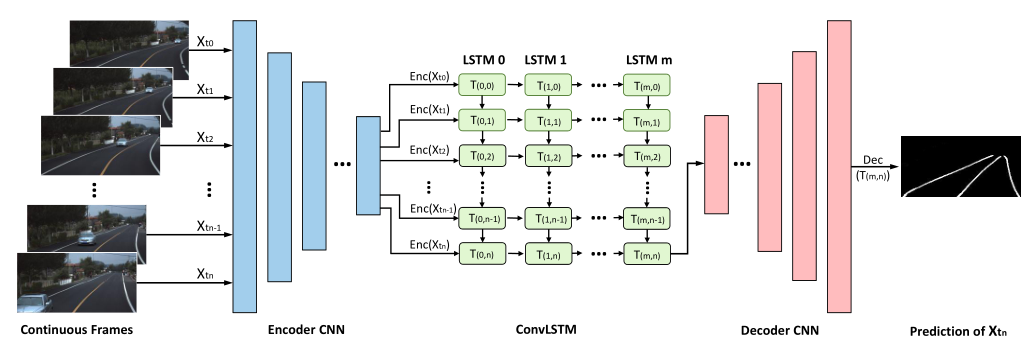
在**訓練**階段,針對Tusimple資料集,將連續5幀作為輸入,並在帶有標註的最後一幀計算Loss。
在**推理**階段,連續幀影象持續輸入,每一幀影象經過處理都會輸出對應的推理結果。
### 《**CurveLane-NAS: Unifying Lane-Sensitive Architecture Search and Adaptive Point Blending**》
[論文連結](https://arxiv.org/abs/2007.12147)
參考了`Dense Prediction Based`(分割的思路)和` Proposal Based`(檢測的思路)兩種車道線檢測的框架,以後者為基礎,採用了NAS的方法,獲得了一個更適合車道線檢測任務的網路結構。
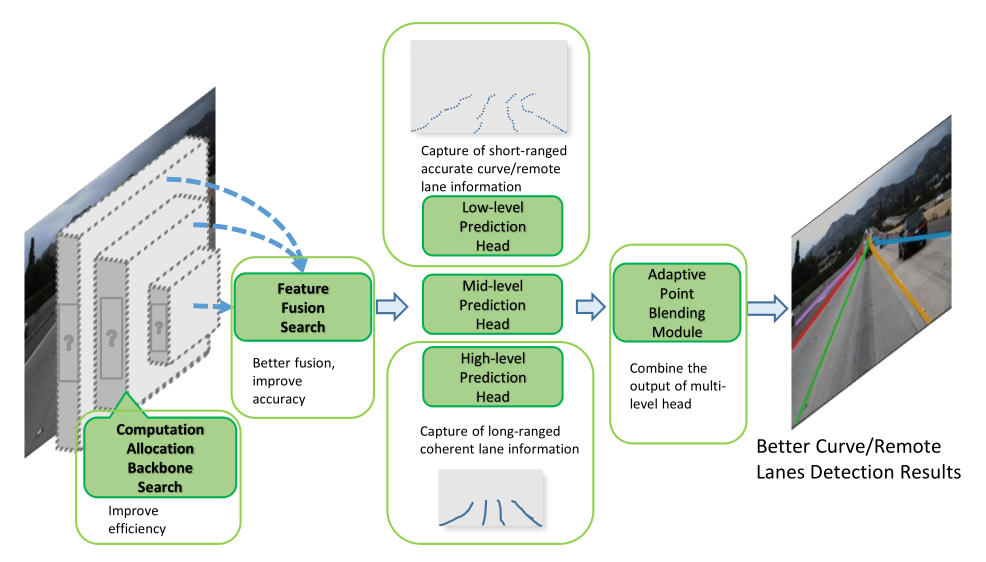
網路整體上可以分為以下幾個部分:
- 特徵提取及多尺度融合,在這兩個階段均引入了NAS的方法;
- 多尺度檢測輸出,以充分獲取大範圍內的全域性結構特徵,以及小範圍內的精確定位
- 結果融合,採用一種叫做`Adaptive Point Blending Search`的方法(類似於一種NMS方法,將低層輸出中位置精度迴歸較高的點逐步向高層輸出替換,得到最後融合優化的車道線點輸出)
而這篇文章還有一個**重大的貢獻**,即釋出了一個大規模的車道線檢測公開資料集[Curvelanes](https://github.com/xbjxh/CurveLanes)。在此之前,只有Tusimple和CULane,Curvelanes的體量跟CULane相當,場景更加多樣化。
### 《Heatmap-based Vanishing Point boosts Lane Detection》
[論文連結](https://arxiv.org/abs/2007.15602)
網路整體上同樣採用Encoder-Decoder結構,在車道線的預測Head以外,增加了一個Head,用於消失點的預測。
將消失點看做一種特殊的關鍵點,採用Heatmap的方式來預測。
通過這種方式,將消失點預測任務作為一種限制和引導因素,來優化車道線檢測的結果。
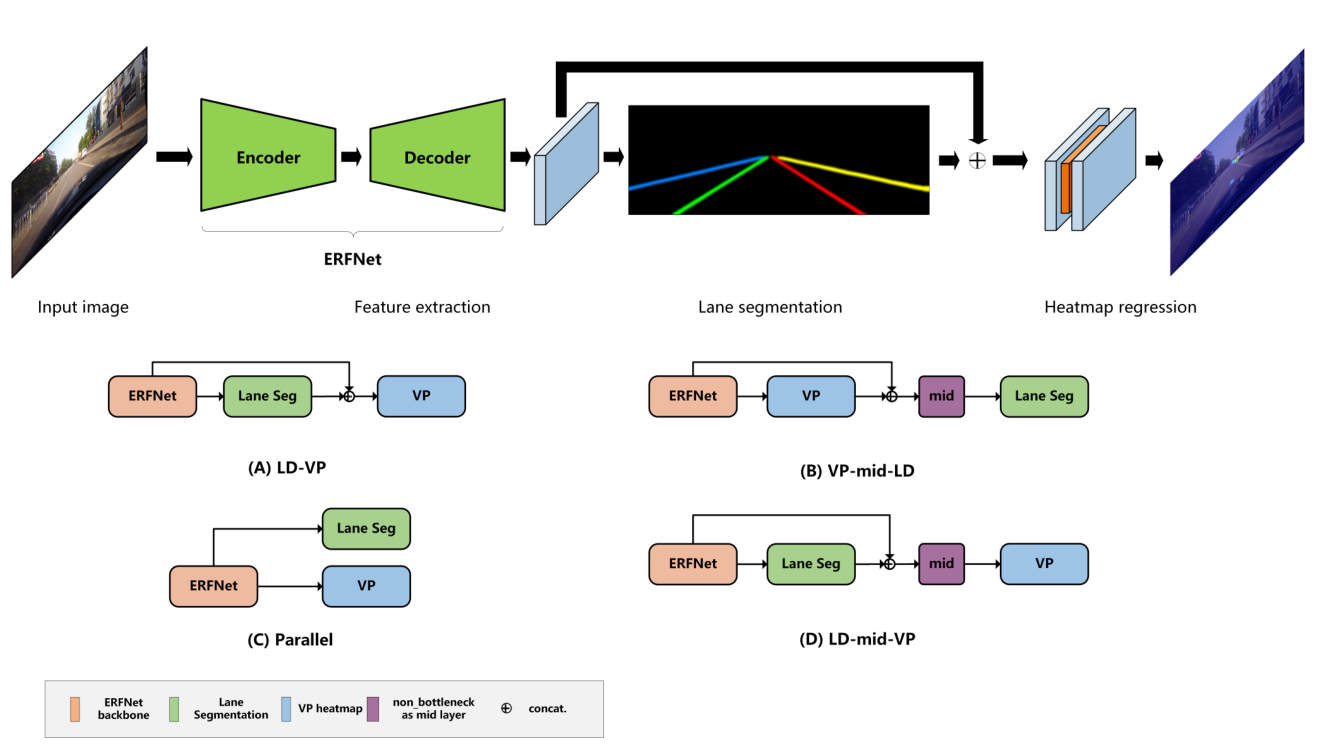
車道線檢測和消失點檢測,兩個任務有多種組合方式。
經試驗,LD-mid-VP的結構,在CULane資料集上能夠獲得最好的結果。這種結構將特徵提取階段的輸出和車道線預測的輸出進行資訊融合,再經過一些卷積層(mid部分)的處理後,輸出消失點的預測結果。
從直觀層面理解,人根據視覺判斷消失點,也是根據車道線的位置關係,來推測消失點位置,具有一定的因果關係。因此把消失點預測任務後置,反過來也能夠促進前端的車道線預測任務更好地收斂。
在此之前,還有一篇較有代表性的文章 [VPGNet](https://arxiv.org/abs/1710.06288),同樣是通過消失點來引導網路學習,以期獲得更好的收斂效果。不同的是VPGNet是通過四象限分割的方式來定義消失點位置,感覺不如Heatmap的方式更加符合直覺。
### 《**Lane Detection Model Based on Spatio-Temporal Network with Double ConvGRUs**》
[論文連結](https://arxiv.org/abs/2008.03922)
整體思路與[第一篇論文](https://arxiv.org/abs/1903.02193)比較類似。都是Encoder+RNN+Decoder。結構如下圖所示:
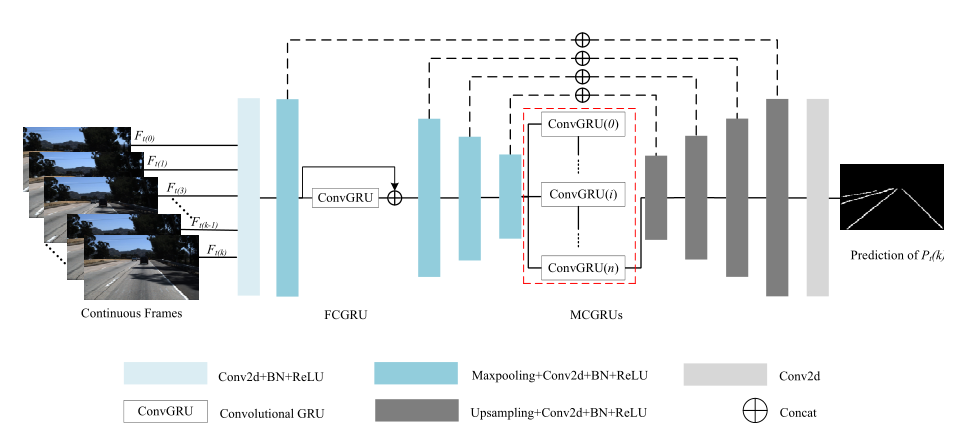
不同的是,它的RNN部分由兩個ConvGRU組成,`Front-ConvGRU`和`Middle-ConvGRUs`。
`Front-ConvGRU`位於Encoder部分的第二個卷積模組之後。理論依據主要是認為視覺感知和記憶之間存在聯絡,因此在低層特徵中引入RNN模組。
> 此處有一點沒有理解,從文中給出的結構圖看,FCGRU這個模組,並沒有在前後幀的時序上產生聯絡(對比MCGRU的畫法可以發現),連線關係類似一個普通的Conv模組,只有一個輸入,一個輸出。
> 我不確定是示意圖畫的問題,還是此處的GRU模組有什麼特殊的用法。
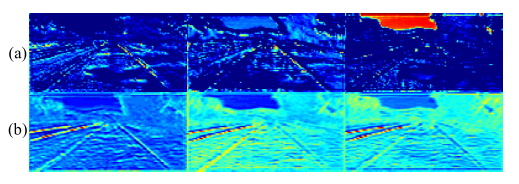
按論文的說法,經FCGRU處理前後的Feature-map視覺化結果。車道線特徵更加明顯突出。
`Middle-ConvGRUs`位於Encoder和Decoder部分之間,作用主要是用於提取連續幀輸入的時序關聯資訊,與前文所說的`ConvLSTM`是類似的。
### 《**RESA: Recurrent Feature-Shift Aggregator for Lane Detection**》
[論文連結](https://arxiv.org/abs/2008.13719)
網路同樣基於Encoder-Decoder結構進行改進。在Encoder和Decoder部分之間,插入`RESA`模組,增強空間結構資訊在全域性的傳播能力。結構如下圖所示:
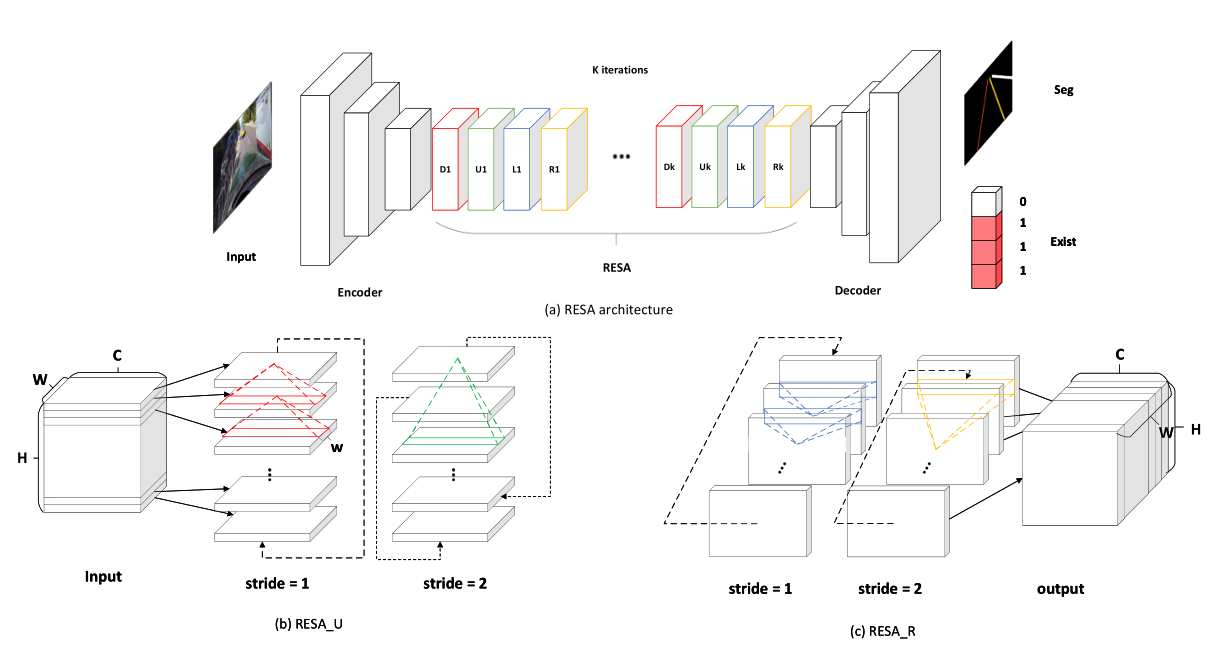
同樣的思路可以回溯到[SCNN這篇文章](https://arxiv.org/abs/1712.06080)。
同樣是通過在Encoder-Decoder之間插入一個`SCNN`模組,來增強網路感知空間結構資訊的能力。
按論文的說法,`RESA`模組比`SCNN`模組的效率要高,時間複雜度與尺度的關係為$log_2L$。
## 3. 總體趨勢分析
總結近期車道線檢測領域的論文,有如下一些發展趨勢:
- 車道線檢測的應用場景具有很明顯的時序資訊特徵,為了利用到時序資訊,通常採用`Encoder-RNN-Decoder`這樣的網路架構,利用RNN模組,對Encoder提取的Features進行進一步加工,提取連續幀帶來的歷史資訊。
> 可以參考人的視覺暫留現象,人在開車時觀察車道線,能夠自覺把虛線識別為一條空間上連續的線,也是利用了前後的時序資訊。
- 在全圖分割的思路以外,出現了一些以目標檢測的思路來處理車道線檢測問題的方法。
> 此處還有一篇較有代表性的文章 [PINet](https://arxiv.org/abs/2002.06604),等讀完之後進行補充。
- 除了車道線檢測本身,通過增加一些額外的相關任務,引導網路更好地學習,來獲得更好的