
一個爬蟲的故事:這是人乾的事兒?
爬蟲原理
我是一個爬蟲,每天穿行於網際網路之上,爬取我需要的一切。

說起來還要感謝HTTP協議,因為它,全世界的網站和瀏覽器才能夠連線通訊,而我也是藉助HTTP協議,獲取我想要的資料。
我只需要偽裝成一個瀏覽器,向伺服器傳送HTTP請求,就能拿到網頁HTML檔案。
接著,我再按照HTML的格式規範,去解析其中的圖片<img>、連結<a>、表單<form>等等我關注的資訊。

獲取連結標籤以後,我又可以進一步爬取連結背後的網頁,如此反覆,要不了多久,一個網站中暴露出來的內容我就能爬個乾淨。
當然了,咱們做爬蟲也還是有底線的。幹我們這一行,有一個約定俗成的規定,那就是Robots協議。
只要你在網站的根目錄下放置一個叫robots.txt的檔案,裡面寫上哪些目錄禁止訪問,我就會繞道而行,就像這樣:
User-agent: *
Disallow: /a/
Disallow: /b/
Disallow: /c/
就像程式設計師們經常互相鄙視一樣,在咱們爬蟲的圈子裡,也存在鄙視鏈。
地位最高的要數搜尋引擎的爬蟲了,他們高高在上,正大光明的爬,各個網站歡迎還來不及,都想被他們收錄到搜尋引擎之中,給網站帶來流量。這些爬蟲,都是圈子裡的大佬,我們惹不起。

另外有一些爬蟲,他們有的不遵守robots協議,隨意亂爬,有的一天天的淨知道爬美女圖片,把人家伺服器爬崩潰了,這些爬蟲我們也是看不起的。
像我這樣老實本分的爬蟲,平日的工作就是爬取一些網站的資料,像購物網站、點評網站等等。雖然我們很守規矩,但這些個網站還是很不待見我們,為了拿到資料,我們展開了曠日持久的拉鋸戰。

反爬蟲技術
現在很多網站都上雲了,雲上的資源可昂貴了,CPU、記憶體、儲存這些都價格不菲,尤其是網路頻寬,價格是真心貴。

那些網站不待見咱們這些爬蟲也就可以理解了,我們不像搜尋引擎爬蟲可以給他們帶來好處,相反,還會消耗他們的伺服器效能,花掉他們寶貴的流量,那可是白花花的人民幣,誰不心疼啊?
所以這些網站加了一個措施:一旦在HTTP請求中的user-agent欄位發現這是一個爬蟲,那就不搭理我們了。

這個user-agent是HTTP協議中表示客戶端名字的欄位,那個時候我剛剛入行,沒什麼經驗,不懂得偽裝,很容易就被發現。
為了能夠繼續爬資料,我只好改頭換面,偽裝成了瀏覽器的名字,圈子裡有的兄弟還偽裝成了搜尋引擎爬蟲的名字,我可不像他們那樣沒下線。
這一招管用了沒多久,這些網站就升級了策略,通過我們的行為來識別是不是真的瀏覽器。我們畢竟是程式,那速度比人類點選快多了,網站一旦發現我們短時間內發起了很多請求,那就掐斷連線。
我只好降低爬取的頻率,避免被拉入黑名單。
有些網站更狠,在網頁裡面插入一些假的圖片,只有幾個畫素那種,人類的眼睛是看不見的,但是我們不知道啊,對我來說都是<img>標籤,我一訪問就中計了!立刻被拉入黑名單。
沒有辦法,攤上這種事,我只好想辦法換個IP再去爬,真是難頂。
聽說圈子裡有些大佬用上了分散式技術,組團去爬,很多個IP地址,其中一個或者幾個封了也不用怕,我真是很羨慕。
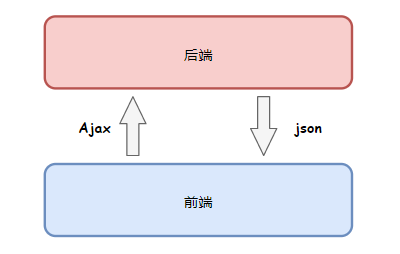
前後端分離
在我的職業生涯中,遇到過一些奇怪的網站,明明網頁中有資料,但是我一訪問拿到的HTML中啥也沒有,一度讓我很鬱悶。
後來才知道,原來他們用上了一個叫前後端分離開發的技術,資料不再從伺服器渲染到HTML網頁中,而是瀏覽器通過單獨的API介面拿到後再動態加載出來,難怪我拿到的只是一個空殼子。
為了拿到資料,我只好也學著去請求這些資料介面,不過因為這些網站都有API閘道器,會檢查請求的Token或者Authorization之類的認證欄位,再加上我不知道他們的介面引數格式,導致我經常拿不到資料。
到了最近兩年,我拿到的網頁HTML越來越簡單了,在瀏覽器中豐富多彩的頁面,一檢視原始碼竟然只有簡單幾行,真是見了鬼了!
終於有一天,一個前輩告訴我,現在流行單頁應用SPA了,頁面全都是在前端動態生成的,拿到的HTML根本沒有價值。

這簡直欺人太甚了!
一不做二不休,我決定弄一個真正的瀏覽器進來,這個內嵌的瀏覽器沒有介面,專門為我服務,嵌入到我的程式中,讓他去真正的渲染網頁,渲染完成後我再去取資料!
這是真正意義上模擬人類去訪問網站了,再也不用模擬繁瑣的資料介面訪問,也不用擔心單頁應用,前端渲染就前端渲染,我再也不怕了!
驗證碼
到後來,不知道是誰發明的,網站們紛紛用上了一種叫驗證碼的技術,給我們出了難題。
開始的驗證碼還算比較簡單,一般都是些簡單的數字、英文字元做了些變形,就像這樣:
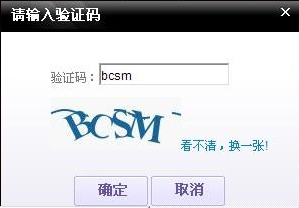
圈子裡很快有大佬教我們用文字識別技術OCR來自動識別這種驗證碼,我也折騰了一下,費了老大勁終於可以識別出來,準確率不敢說100%,99%還是有的。
不過沒多久,這驗證碼就變得越來越複雜,什麼漢字識別,物體識別,滑動解鎖,一個比一個難,根本超出了我的理解範圍,你瞧瞧下面這些驗證碼,這是人乾的事兒嗎?
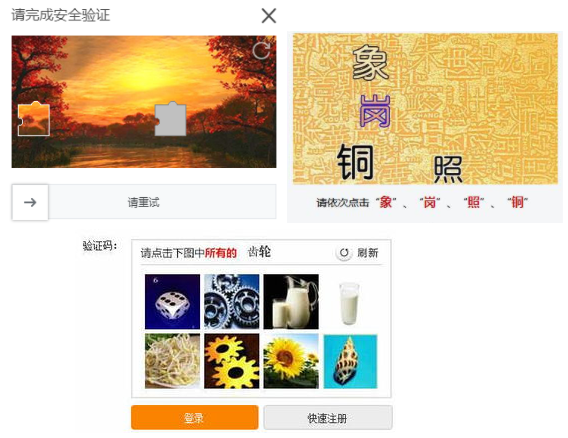
哎,這還真是人才能幹的事,不是我們爬蟲能幹的~
如今,這些網站的反爬蟲技術越來越先進,我們能發揮的空間被一步步擠壓。
前段時間,有個愣頭青爬蟲把一家公司的伺服器給爬崩潰了,把人家正常業務都弄停掉了,他還被抓了起來,現在監管越來越嚴,搞得大家人心惶惶。
內憂外患不斷,不少爬蟲兄弟失業的失業,轉行的轉行,爬蟲這碗飯,真是越來越不好吃了。。。
往期TOP5文章
我是Redis,MySQL大哥被我害慘了!
CPU明明8個核,網絡卡為啥拼命折騰一號核?
因為一個跨域請求,我差點丟了飯碗
完了!CPU一味求快出事兒了!
雜湊表哪家強?幾大程式語言吵起來了!
