
技術心得丨一種有效攻擊BERT等模型的方法
Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment
作者機構:MIT,香港大學,A* STAR
論文發表:AAAI2020
論文連線:http://aaai.org/Papers/AAAI/2020GB/AAAI-JinD.7014.pdf
概要:機器學習模型對對抗樣本敏感,在對抗樣本上效果下降明顯。本文提出了一個生成對抗樣本的模型,TEXTFOOLER。通過替換樣本中的重要詞彙獲得對抗樣本,在對抗樣本上模型的效果急劇下降。該方法可以用於資料增廣,提升模型的魯棒性和泛化能力。
背景介紹
對抗樣本攻擊是指通過某種方法生成一些樣本,已經訓練好的模型在這些生成的對抗樣本上的效果急劇下降,模型非常脆弱。對抗樣本攻擊在計算機視覺領域研究的比較多,但是文字領域相對較少。本文提出了一種對抗樣本生成模型,TEXTFOOLER,可以有效的生成對抗樣本,並且生成的樣本在語法、語義上都比較合理,其計算複雜度是線性的。
方法
TEXTFOOLER
輸入:是候選樣本X、樣本的標註標籤Y、已經訓練好的模型F、句子相似度計算模型Sim,句子相似度閾值、整個語料詞典對應的詞向量Emb
輸出:候選樣本的對抗樣本,即新生成的樣本。
主要分兩步:
第一步:詞重要性排序,即獲得基於重要性分數排序的詞集合W。
第二步:對抗樣本生成,即基於集合W對原始樣本進行詞替換獲得對抗樣本。
1. 詞重要性排序
目標是獲得輸入樣本中每個詞在模型預測過程中的重要性。
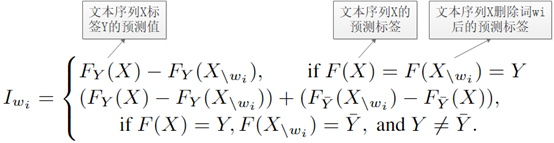
Equation 1 詞重要性分數
詞的重要性分數按上述公式計算,即如果對抗樣本標籤原始樣本標籤一樣,則重要性分數等於模型預測值得差值,若標籤不一樣,則重要性分數為標籤為原始標籤的模型預測值差值和標籤為預測標籤的模型預測值差值之和。得到每個詞的重要性分數後,基於NLTK和spaCy過濾掉停用詞,獲得最終的詞重要性排序集合W。
2. 對抗樣本生成
目標是找到最終的每個詞的替換詞並用替換詞替換樣本得到最終的對抗樣本集合。
1)同義詞提取:對W中的每個詞wj,根據詞向量從詞典中找到Top N的同義詞,並通過詞性過濾後得到候選替換詞集合CANDIDATES。
2)句子相似度檢查:對CANDIDATES中每個詞ck,用ck替換wj得到新的對抗樣本 同時計算原始樣本X和對抗樣本之間的相似度 (通過Universal Sentence Encoder得到句子的向量表示,然後計算餘弦距離作為相似度)。作為兩個句子的語義相似度。相似度高於給定閾值的替換詞放進最終的替換詞候選集合FINCANDIDATES.
3)對於FINCANDIDATES的每個詞,如果有候選詞改變了模型的預測的類別,那麼選擇句子相似度最大的詞作為最終候選詞。如果沒有改變模型的預測類別,選擇預測置信度最低的詞作為最終的替換詞。
4)重複1)-3)的操作。

圖 1 生成的對抗樣本的例子
實驗結果
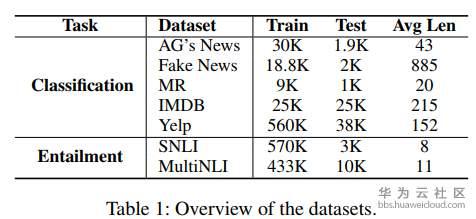
實驗資料主要包含:
- 文字分類任務:預測文字的某個標籤。
- 文字蘊含任務:預測文字對中兩個句子的關係,即蘊含關係、矛盾關係或者中性。
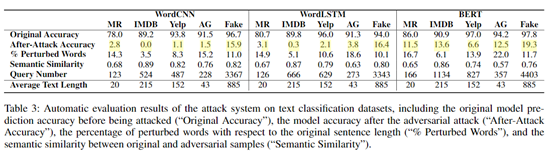
圖 2 在分類任務上的對抗結果
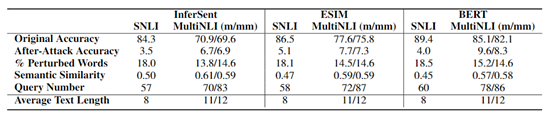
圖 3 在文字蘊含上的對抗結果
結果:對測試集進行對抗樣本替換後,準確率急劇下降,甚至到0.
和其他對抗模型比較
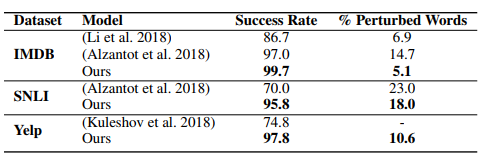
圖 4 和其他對抗模型比較
結論:從替換詞比例和攻擊成功率(模型預測錯誤的比例)兩個維度都比基線模型好。
人工評價
人工評價對抗樣本的語法、人工標籤、是否保留了原始樣本的語義這三個維度。
結論:對抗樣本語法合理,人工標籤和原始樣本標籤在MR資料集上一致率達92%,句子語義相似度達0.91.
控制變數實驗
通過控制變數的方法驗證各個步驟對模型效果的影響。
詞重要性排序
通過取消詞重要性排序的步驟看該步驟對模型效果的影響。

圖 5 取消詞重要性排序的結果(Random)
結論:詞重要性排序很重要。
語義相似度約束
通過取消候選替換詞中的語義相似度約束看該步驟對模型效果的影響。
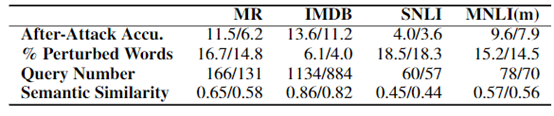
圖 6 語義相似度約束對比 “/”前後表示有和無語義相似度約束的結果對比
結論:語義相似度約束對結果影響很大。
可遷移性
由一個模型生成的對抗樣本是否可以使得其他模型出錯。
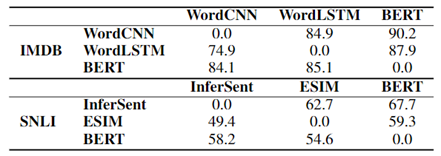
圖 7 對抗樣本的可遷移性。行i,列j表示模型i生成的對抗樣本在模型j上的準確率
結論:模型效果越好,基於該模型生成的對抗樣本的可遷移性越高。
對抗訓練
生成的對抗樣本可以用於訓練模型,增強模型的魯棒性和泛化能力。
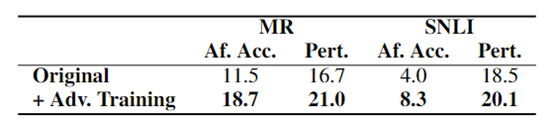
圖 8 基於對抗樣本的對抗訓練結果
結論:對抗訓練可顯著提高模型效果。
啟發:
1. 可以通過此方法生成對抗樣本可以用於資料增廣,加入到訓練資料中來增強模型的魯棒性和泛化能力。
2. 可通過文字的重要性詞彙排序方法篩選標籤相關的主題詞彙,如構建情感詞典、主題詞挖掘、關鍵詞挖掘等。
點選關注,第一時間瞭解華為雲新鮮技