
深入理解RabbitMQ中的prefetch_count引數
阿新 • • 發佈:2020-10-18

## 前提
在某一次使用者標籤服務中大量用到非同步流程,使用了`RabbitMQ`進行解耦。其中,為了提高消費者的處理效率針對了不同節點任務的消費者執行緒數和`prefetch_count`引數都做了調整和測試,得到一個相對合理的組合。這裡深入分析一下`prefetch_count`引數在`RabbitMQ`中的作用。
## prefetch_count引數的含義
先從`AMQP`(`Advanced Message Queuing Protocol`,即高階訊息佇列協議,`RabbitMQ`實現了此協議的`0-9-1`版本的大部分內容)和`RabbitMQ`的具體實現去理解`prefetch_count`引數的含義,可以查閱對應的文件(見文末參考資料)。`AMQP 0-9-1`定義了`basic.qos`方法去限制消費者基於某一個`Channel`或者`Connection`上未進行`ack`的最大訊息數量上限。`basic.qos`方法支援兩個引數:
- `global`:布林值。
- `prefetch_count`:整數。
這兩個引數在`AMQP 0-9-1`定義中的含義和`RabbitMQ`具體實現時有所不同,見下表:
|`global`引數值|`AMQP 0-9-1`中`prefetch_count`引數的含義|`RabbitMQ`中`prefetch_count`引數的含義|
|:-:|:-:|:-:|
|`false`|`prefetch_count`值在當前`Channel`的所有消費者共享|`prefetch_count`對於基於當前`Channel`建立的消費者生效|
|`true`|`prefetch_count`值在當前`Connection`的所有消費者共享|`prefetch_count`值在當前`Channel`的所有消費者共享|
或者用簡潔的英文表格理解:
|`global`|`prefetch_count` in `AMQP 0-9-1`|`prefetch_count` in `RabbitMQ`|
|:-:|:-:|:-:|
|`false`|`Per channel limit`|`Per customer limit`|
|`true`|`Per connection limit`|`Per channel limit`|
這裡畫一個圖理解一下:
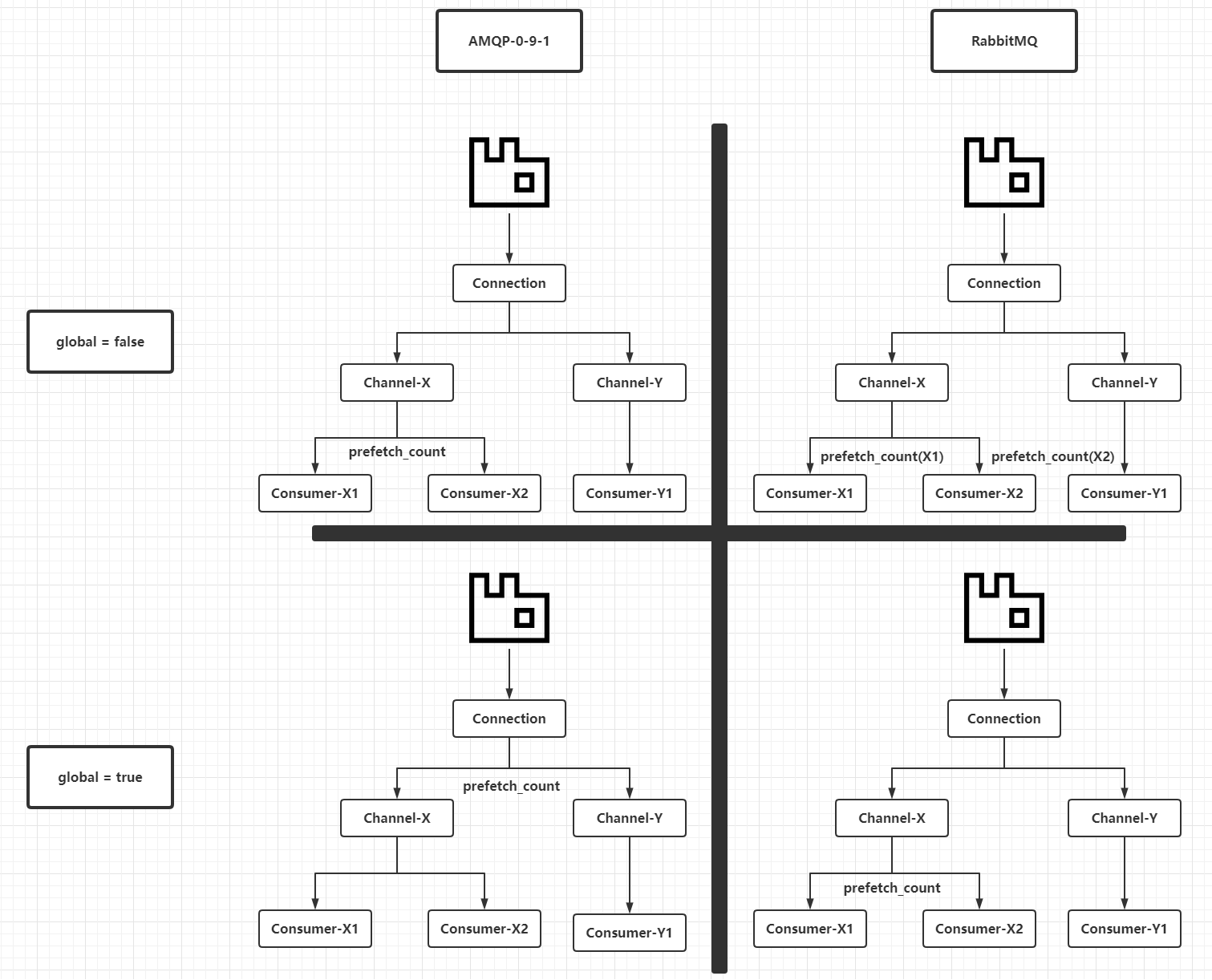
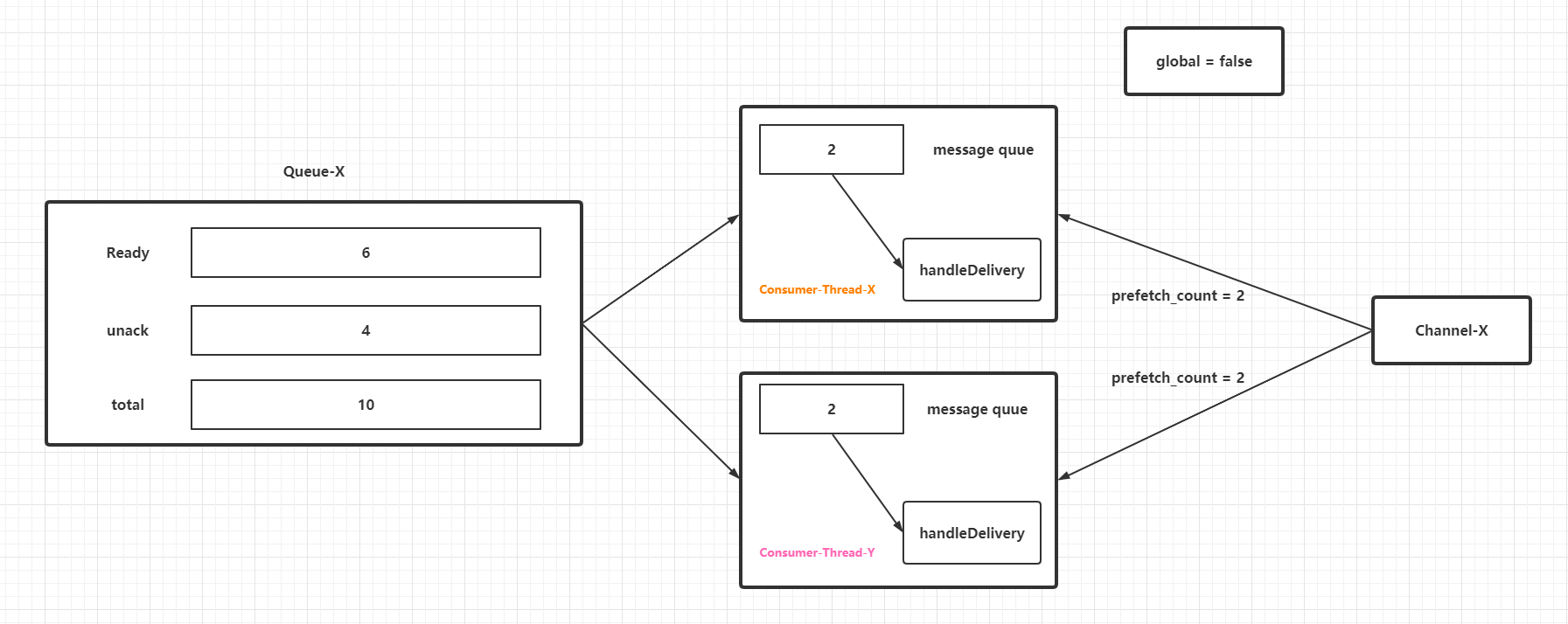
上圖僅僅為了區分協議本身和`RabbitMQ`中實現的不同,接著說說`prefetch_count`對於消費者(執行緒)和待消費訊息的作用。假定一個前提:`RabbitMQ`客戶端從`RabbitMQ`服務端獲取到佇列訊息的速度比消費者執行緒消費速度快,目前有兩個消費者執行緒共用一個`Channel`例項。當`global`引數為`false`時候,效果如下:
而當`global`引數為`true`時候,效果如下:
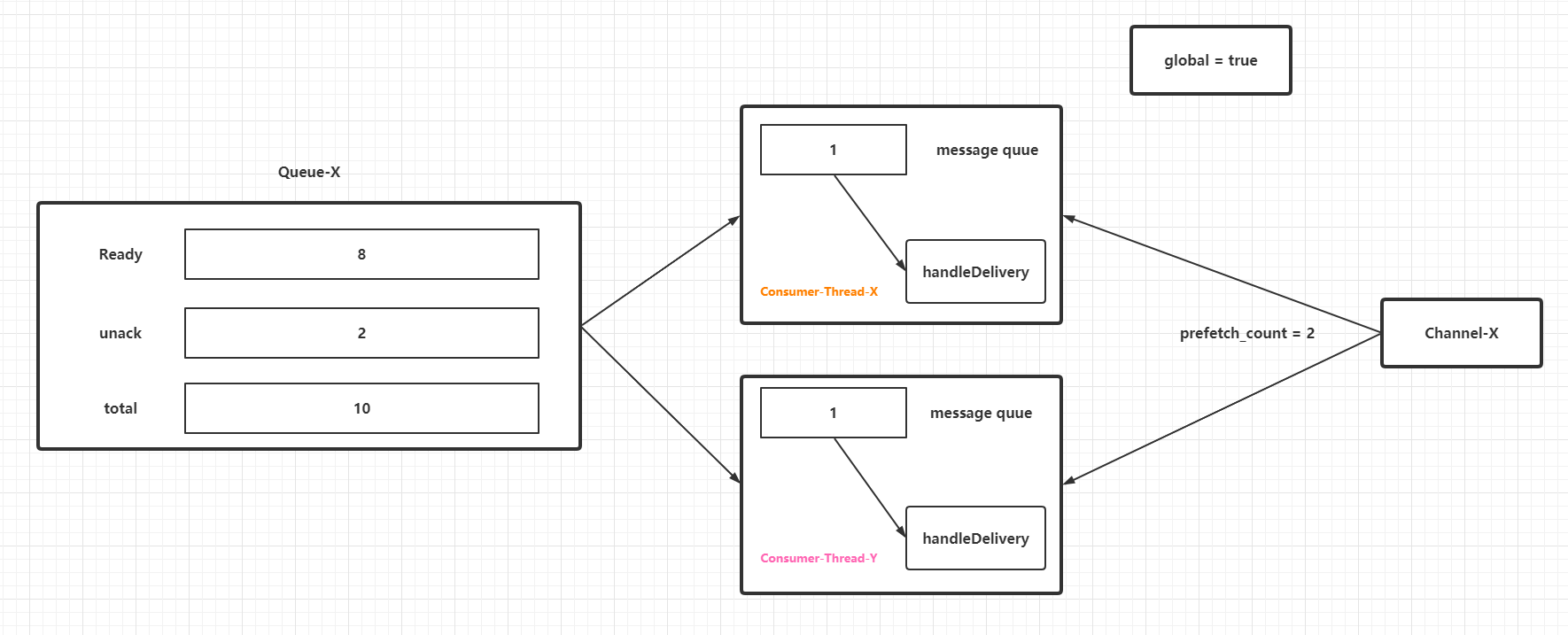
在消費者執行緒處理速度遠低於`RabbitMQ`客戶端從`RabbitMQ`服務端獲取到佇列訊息的速度的場景下,`prefetch_count`條未進行`ack`的訊息會暫時存放在一個佇列(準確來說是阻塞佇列,然後阻塞佇列中的訊息任務會流轉到一個列表中遍歷回撥消費者控制代碼,見下一節的原始碼分析)中等待被消費者處理。這部分訊息會佔據`JVM`的堆記憶體,所以在效能調優或者設定應用程式的初始化和最大堆記憶體的時候,如果剛好用到`RabbitMQ`的消費者,必須要考慮這些"預取訊息"的記憶體佔用量。不過值得注意的是:**`prefetch_count`是`RabbitMQ`服務端的引數,它的設定值或者快照都不會存放在`RabbitMQ`客戶端**。同時需要注意`prefetch_count`生效的條件和特性(從引數設定的一些`demo`和原始碼上感知):
- `prefetch_count`引數僅僅在`basic.consume`的`autoAck`引數設定為`false`的前提下才生效,也就是不能使用自動確認,自動確認的訊息沒有辦法限流。
- `basic.consume`如果在非自動確認模式下忘記了手動呼叫`basic.ack`,那麼`prefetch_count`正是未`ack`訊息數量的最大上限。
- `prefetch_count`是由`RabbitMQ`服務端控制,一般情況下能保證各個消費者執行緒中的未`ack`訊息分發是均衡的,這點筆者猜測是`consumerTag`起到了關鍵作用。
## RabbitMQ客戶端中prefetch_count原始碼跟蹤
> 編寫本文的時候引入的RabbitMQ客戶端版本為:com.rabbitmq:amqp-client:5.9.0
上面說了這麼多都只是根據官方的文件或者部落格中的理論依據進行分析,其實更加根本的分析方法是直接閱讀`RabbitMQ`的`Java`客戶端原始碼,主要是針對`basic.qos`和`basic.consume`兩個方法,對應的是`com.rabbitmq.client.impl.ChannelN#basicQos()`和`com.rabbitmq.client.impl.ChannelN#basicConsume()`兩個方法。先看`ChannelN#basicQos()`:
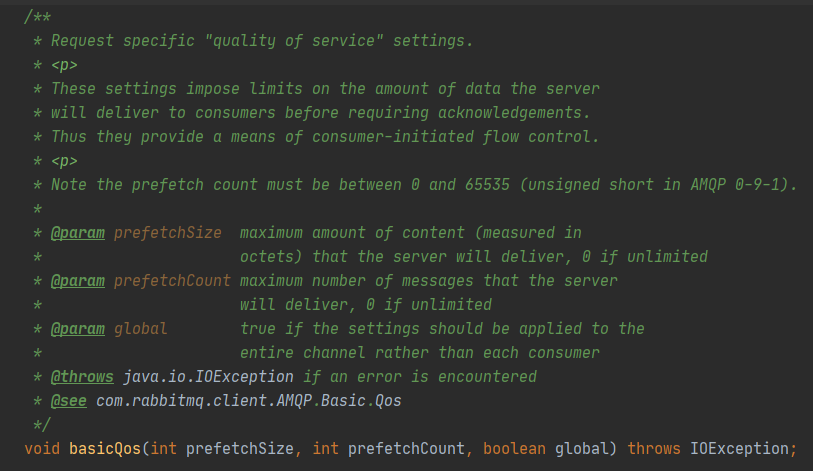
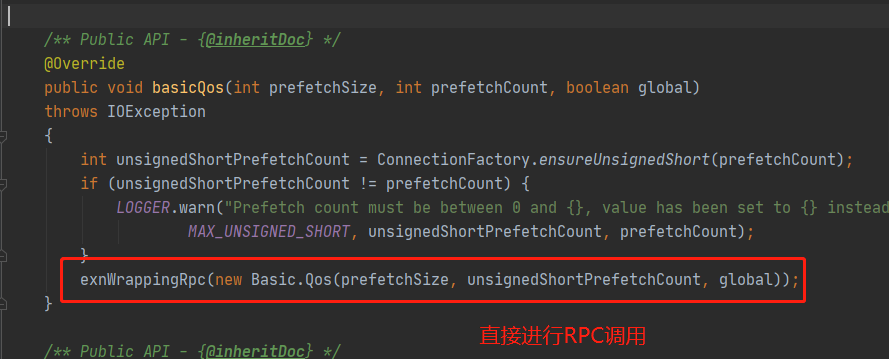
這裡的`basicQos()`方法多了一個`prefetchSize`引數,用於限制分發內容的大小上限,預設值`0`代表無限制,而`prefetchCount`的取值範圍是`[0,65535]`,取值為`0`也是代表無限制。這裡的`ChannelN#basicQos()`實現中直接封裝`basic.qos`方法引數進行一次`RPC`呼叫,意味著直接更變`RabbitMQ`服務端的配置,即時生效,同時引數值完全沒有儲存在客戶端程式碼中,印證了前面一節的結論。接著看`ChannelN#basicConsume()`方法:
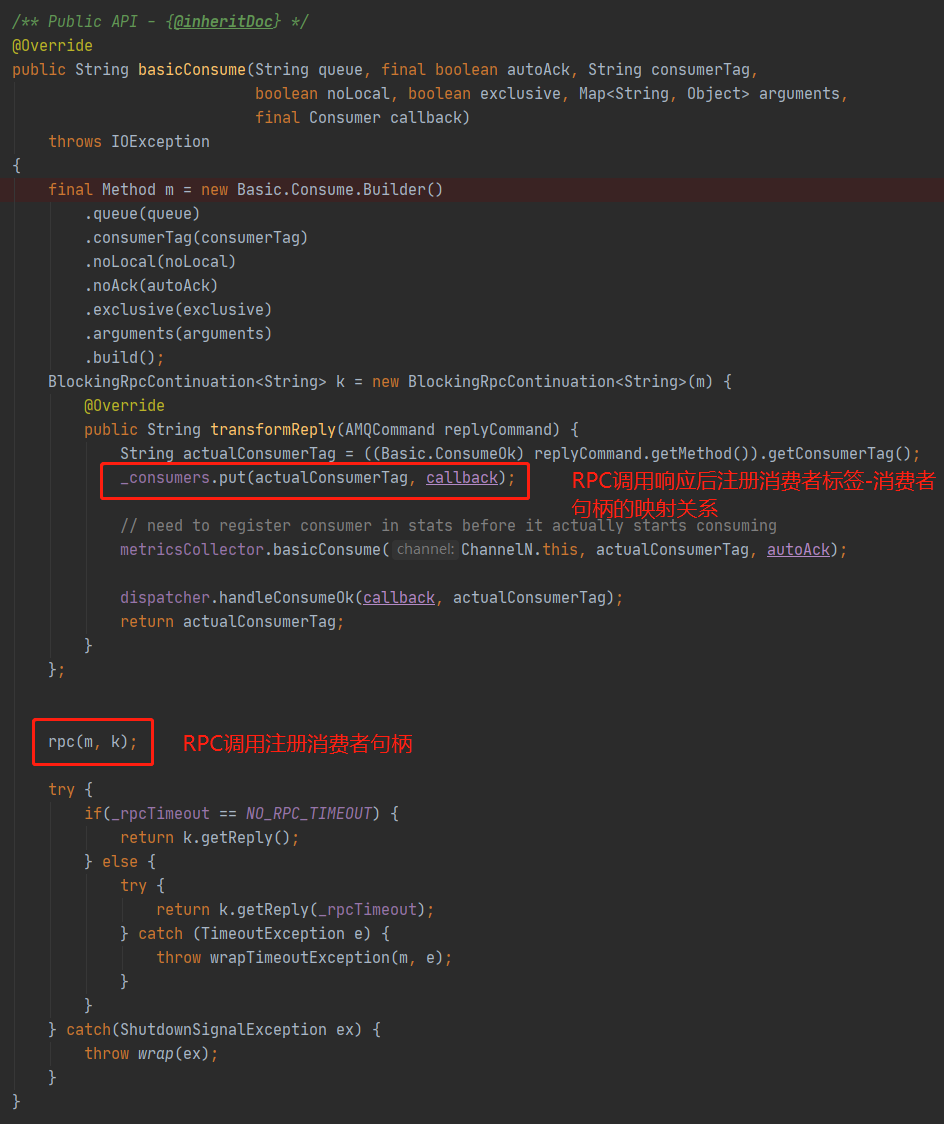
上圖已經把關鍵部分用紅圈圈出,因為整個訊息消費過程是非同步的,涉及太多的類和方法,這裡不全量貼出,整理了一個流程圖:
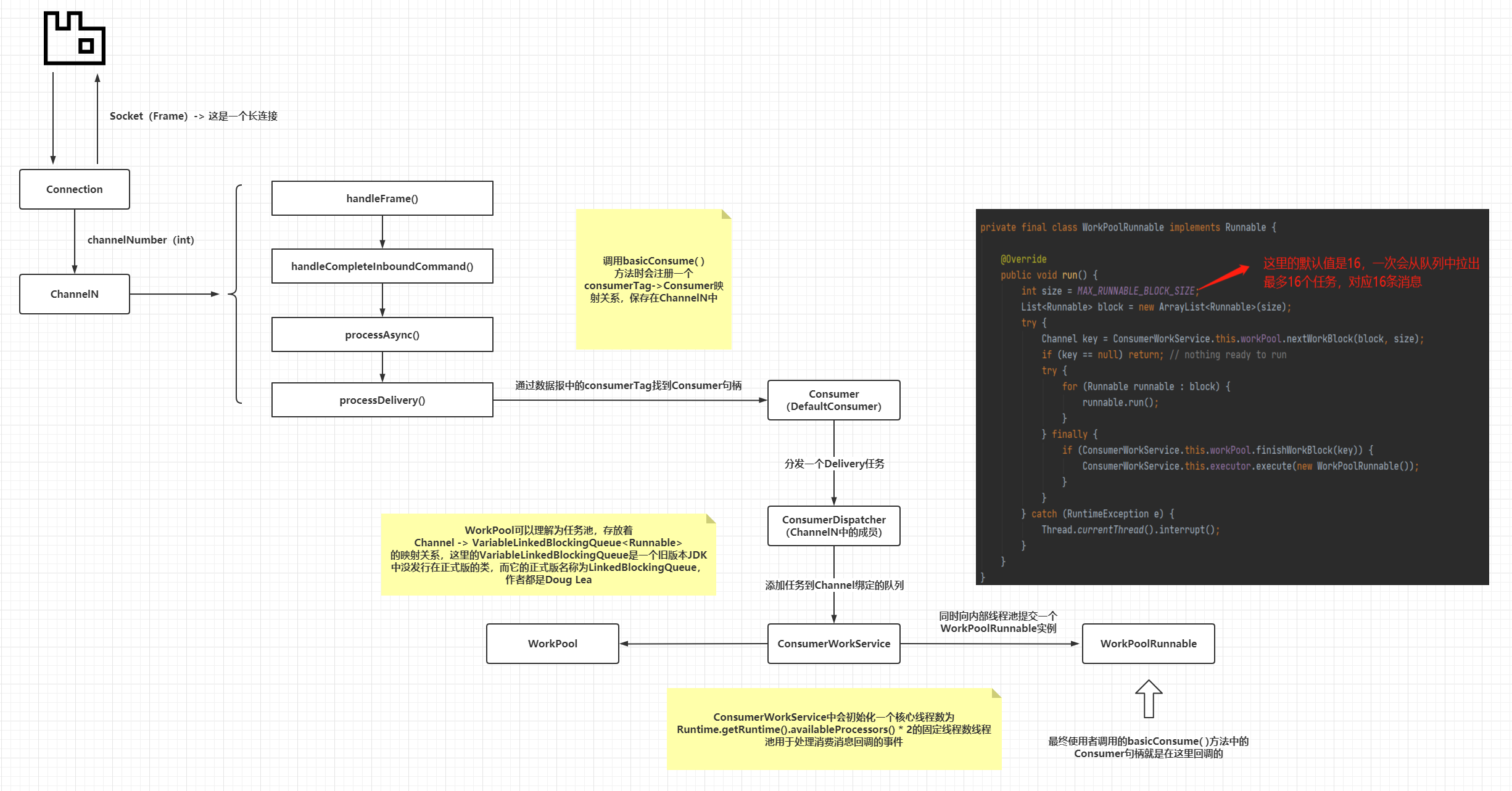
整個訊息消費過程,`prefetch_count`引數並未出現在客戶端程式碼中,又再次印證了前面一節的結論,即`prefetch_count`引數的行為和作用完全由`RabbitMQ`服務端控制。而最終`Customer`或者常用的`DefaultCustomer`控制代碼是在`WorkPoolRunnable`中回撥的,這類任務的執行執行緒來自於`ConsumerWorkService`內部的執行緒池,而這個執行緒池又使用了`Executors.newFixedThreadPool()`去構建,使用了預設的執行緒工廠類,因此在`Customer#handleDelivery()`方法內部列印的執行緒名稱的樣子是`pool-1-thread-*`。
> 這裡VariableLinkedBlockingQueue就是前一節中的message queue的原型
## prefetch_count引數使用
設定`prefetch_count`引數比較簡單,就是呼叫`Channel#basicQos()`方法:
```java
public class RabbitQos {
static String QUEUE = "qos.test";
public static void main(String[] args) throws Exception {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("localhost");
connectionFactory.setPort(5672);
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE, true, false, false, null);
channel.basicQos(2);
channel.basicConsume("qos.test", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("1------" + Thread.currentThread().getName());
sleep();
}
});
channel.basicConsume("qos.test", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("2------" + Thread.currentThread().getName());
sleep();
}
});
for (int i = 0; i < 20; i++) {
channel.basicPublish("", QUEUE, MessageProperties.TEXT_PLAIN, String.valueOf(i).getBytes());
}
sleep();
}
private static void sleep() {
try {
Thread.sleep(Long.MAX_VALUE);
} catch (Exception ignore) {
}
}
}
```
上面是原生的`amqp-client`的寫法,如果使用了`spring-amqp`(`spring-boot-starter-amqp`),可以通過配置檔案中的`spring.rabbitmq.listener.direct.prefetch`屬性指定所有消費者執行緒的`prefetch_count`,如果要針對部分消費者執行緒進行該屬性的設定,則需要針對`RabbitListenerContainerFactory`進行改造。
## prefetch_count引數最佳實踐
關於`prefetch_count`引數的設定,`RabbitMQ`官方有一篇文章進行了分析:[《Finding bottlenecks with RabbitMQ 3.3》](https://www.rabbitmq.com/blog/2014/04/14/finding-bottlenecks-with-rabbitmq-3-3)。該文章分析了訊息流控的整個流程,其中提到了`prefetch_count`引數的一些指標:

這裡指出了,如果`prefetch_count`的值超過了`30`,那麼網路頻寬限制開始占主導地位,此時進一步增加`prefetch_count`的值就會變得收效甚微。也就是說,**官方是建議把`prefetch_count`設定為`30`**。這裡再參看一下`spring-boot-starter-amqp`中對此引數定義的預設值,具體是`AbstractMessageListenerContainer`中的`DEFAULT_PREFETCH_COUNT`:
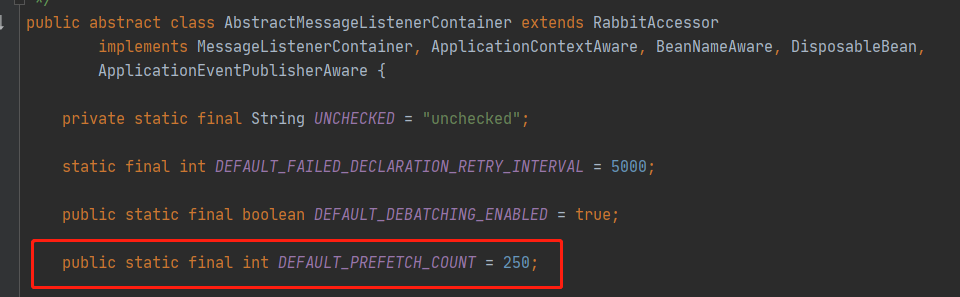
如果沒有通過`spring.rabbitmq.listener.direct.prefetch`進行覆蓋,那麼使用`spring-boot-starter-amqp`中的註解定義的消費者執行緒中設定的`prefetch_count`就是`250`。
筆者認為,應該綜合頻寬、每條訊息的資料報大小、消費者執行緒處理的速率等等角度去考慮`prefetch_count`的設定。總結如下(個人經驗僅供參考):
- 當消費者執行緒的處理速度十分慢,而佇列的訊息量十分少的場景下,可以考慮把`prefetch_count`設定為`1`。
- 當佇列中的每條訊息的資料報十分大的時候,要計算好客戶端可以容納的未`ack`總訊息量的記憶體極限,從而設計一個合理的`prefetch_count`值。
- 當消費者執行緒的處理速度十分快,遠遠大於`RabbitMQ`服務端的訊息分發,在網路頻寬充足的前提下,設定可以把`prefetch_count`值設定為`0`,不做任何的訊息流控。
- 一般場景下,建議使用`RabbitMQ`官方的建議值`30`或者`spring-boot-starter-amqp`中的預設值`250`。
## 小結
小結一下:
- `prefetch_count`是`RabbitMQ`服務端的引數,設定後即時生效。
- `prefetch_count`對於`AMQP-0-9-1`中的定義與`RabbitMQ`中的實現不完全相同。
- `prefetch_count`值設定建議使用框架提供的預設值或者通過分組實驗結合資料報大小進行計算和評估出一個合理值。
## 彩蛋
筆者把文章釋出到公眾號和朋友圈後,筆者的師傅作了點評,指出其中的一點不足:
確實如此,`prefetch_count`的本質作用就是消費者的流控,官方的那篇文章也提到了網路和頻寬的重要性,所以要考慮`RTT`(`Round-Trip Time`,往返時延),這裡的`RTT`概念來源於《計算機網路原理》:
>