
如何讓服務在流量暴增的情況下保持穩定輸出
阿新 • • 發佈:2020-10-22
# 服務自適應降載保護設計
## 設計目的
* 保證系統不被過量請求拖垮
* 在保證系統穩定的前提下,儘可能提供更高的吞吐量
## 設計考慮因素
* 如何衡量系統負載
* 是否處於虛機或容器內,需要讀取cgroup相關負載
* 用1000m表示100%CPU,推薦使用800m表示系統高負載
* 儘可能小的Overhead,不顯著增加RT
* 不考慮服務本身所依賴的DB或者快取系統問題,這類問題通過熔斷機制來解決
## 機制設計
* 計算CPU負載時使用滑動平均來降低CPU負載抖動帶來的不穩定,關於滑動平均見參考資料
* 滑動平均就是取之前連續N次值的近似平均,N取值可以通過超參beta來決定
* 當CPU負載大於指定值時觸發降載保護機制
* 時間視窗機制,用滑動視窗機制來記錄之前時間視窗內的QPS和RT(response time)
* 滑動視窗使用5秒鐘50個桶的方式,每個桶儲存100ms時間內的請求,迴圈利用,最新的覆蓋最老的
* 計算maxQPS和minRT時需要過濾掉最新的時間沒有用完的桶,防止此桶內只有極少數請求,並且RT處於低概率的極小值,所以計算maxQPS和minRT時按照上面的50個桶的引數只會算49個
* 滿足以下所有條件則拒絕該請求
1. 當前CPU負載超過預設閾值,或者上次拒絕時間到現在不超過1秒(冷卻期)。冷卻期是為了不能讓負載剛下來就馬上增加壓力導致立馬又上去的來回抖動
2. `averageFlying > max(1, QPS*minRT/1e3)`
* averageFlying = MovingAverage(flying)
* 在算MovingAverage(flying)的時候,超參beta預設取值為0.9,表示計算前十次的平均flying值
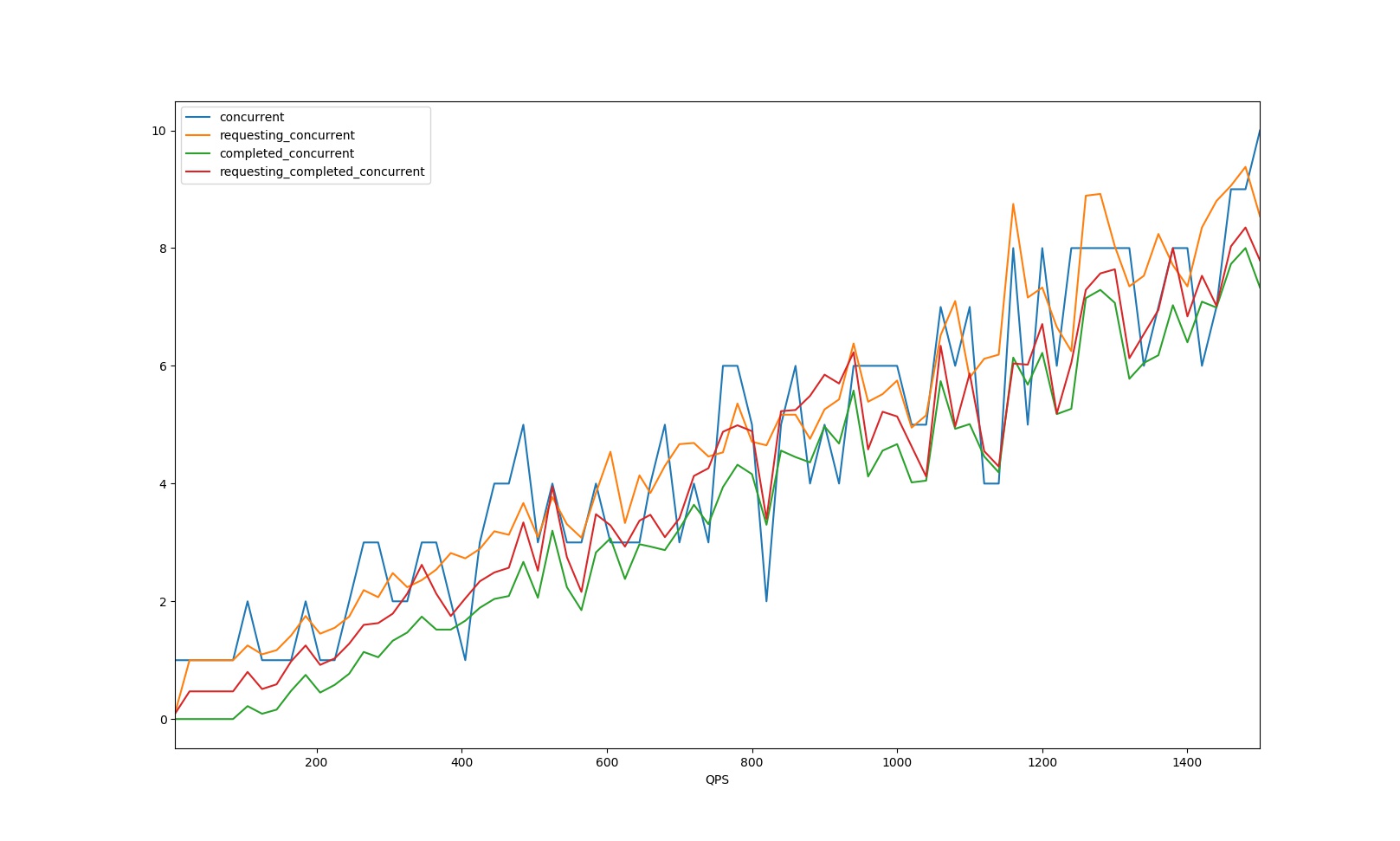
* 取flying值的時候,有三種做法:
1. 請求增加後更新一次averageFlying,見圖中橙色曲線
2. 請求結束後更新一次averageFlying,見圖中綠色曲線
3. 請求增加後更新一次averageFlying,請求結束後更新一次averageFlying
我們使用的是第二種,這樣可以更好的防止抖動,如圖:
* QPS = maxPass * bucketsPerSecond
* maxPass表示每個有效桶裡的成功的requests
* bucketsPerSecond表示每秒有多少個桶
* 1e3表示1000毫秒,minRT單位也是毫秒,QPS*minRT/1e3得到的就是平均每個時間點有多少併發請求
## 降載的使用
* 已經在rest和zrpc框架裡增加了可選啟用配置
* CpuThreshold,如果把值設定為大於0的值,則啟用該服務的自動降載機制
* 如果請求被drop,那麼錯誤日誌裡會有`dropreq`關鍵字
## 參考資料
* [滑動平均](https://www.cnblogs.com/wuliytTaotao/p/9479958.html)
* [Sentinel自適應限流](https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81)
## 專案地址
[https://github.com/tal-tech/go-zero](https://github.com/tal-tech/go-zero)
> 好未