
CDH+Kylin三部曲之二:部署和設定
阿新 • • 發佈:2020-10-23
### 歡迎訪問我的GitHub
[https://github.com/zq2599/blog_demos](https://github.com/zq2599/blog_demos)
內容:所有原創文章分類彙總及配套原始碼,涉及Java、Docker、Kubernetes、DevOPS等;
### 本篇概覽
本文是《CDH+Kylin三部曲》系列的第二篇,上一篇[《CDH+Kylin三部曲之一:準備工作》](https://blog.csdn.net/boling_cavalry/article/details/105449630)已將所需的機器和檔案準備完畢,可以部署CDH和Kylin了;
### 執行ansible指令碼部署CDH和Kylin(ansible電腦)
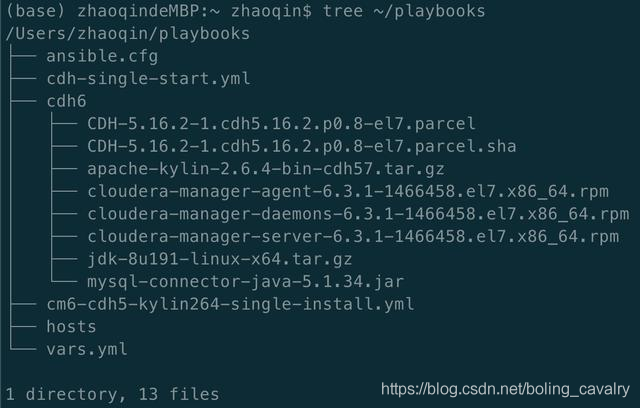
1. 進入ansible電腦的~/playbooks目錄,經過上一篇的準備工作,該目錄下應該是下圖這些內容:
2. 檢查ansible遠端操作CDH伺服器是否正常,執行命令ansible deskmini -a "free -m",正常情況下顯示CDH伺服器的記憶體資訊,如下圖:

3. 執行命令開始部署:ansible-playbook cm6-cdh5-kylin264-single-install.yml
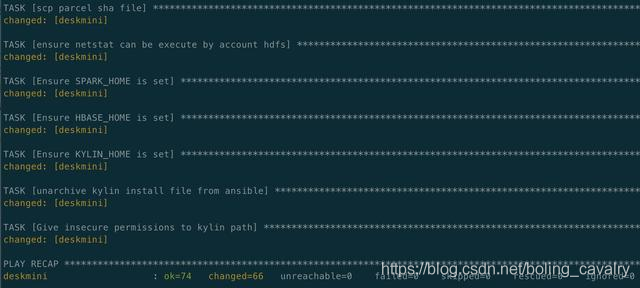
4. 整個部署過程涉及線上安裝、傳輸大檔案等耗時的操作,請耐心等待(半小時左右),如果部署期間出錯退出(例如網路問題),只需重複執行上述命令即可,ansible保證了操作的冪等性;
5. 部署成功如下圖所示:
### 重啟CDH伺服器
由於修改了selinux和swap的設定,需要重啟作業系統才能生效,因此請重啟CDH伺服器;
### 執行ansible指令碼啟動CDH服務(ansible電腦)
1. 等待CDH伺服器重啟成功;
2. 登入ansible電腦,進入~/playbooks目錄;
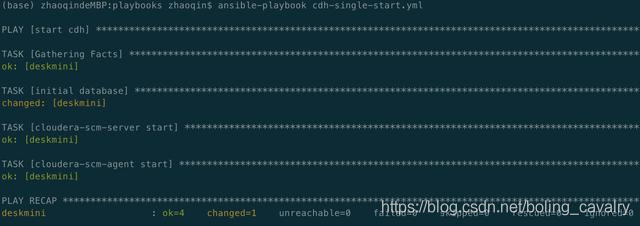
3. 執行初始化資料庫和啟動CDH的指令碼:ansible-playbook cdh-single-start.yml
4. 啟動完成輸出如下資訊:
5. ssh登入CDH伺服器,執行此命令觀察CDH服務的啟動情況:tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log,看到下圖紅框中的內容時,表示啟動完成,可以用瀏覽器登入了:

### 設定(瀏覽器操作)
現在CDH服務已經啟動了,可以通過瀏覽器來操作:
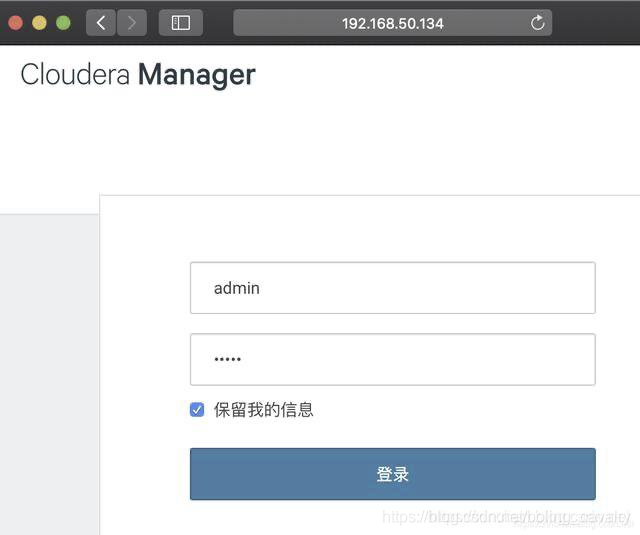
1. 瀏覽器訪問:http://192.168.50.134:7180 ,如下圖,賬號密碼都是admin:
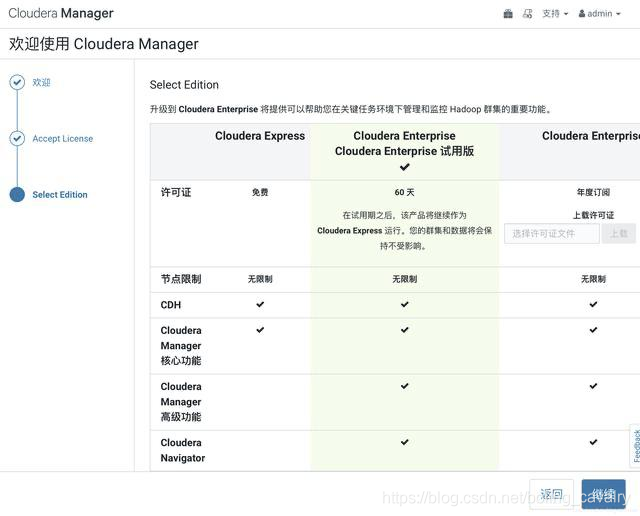
2. 一路next,在選擇版本頁面選擇60天體驗版:
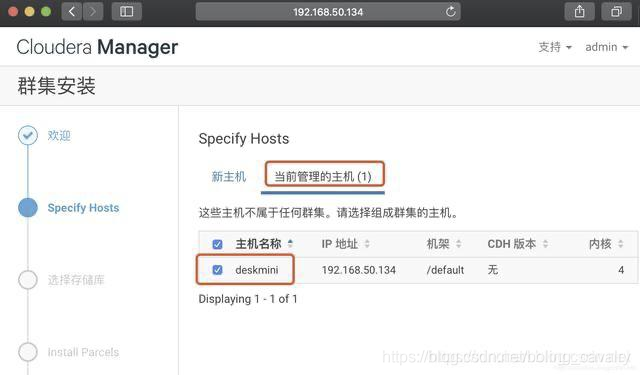
3. 選擇主機頁面可見CDH伺服器(deskmini):
4. 在選擇CDH版本的頁面,請選擇下圖紅框中的5.16.2-1:

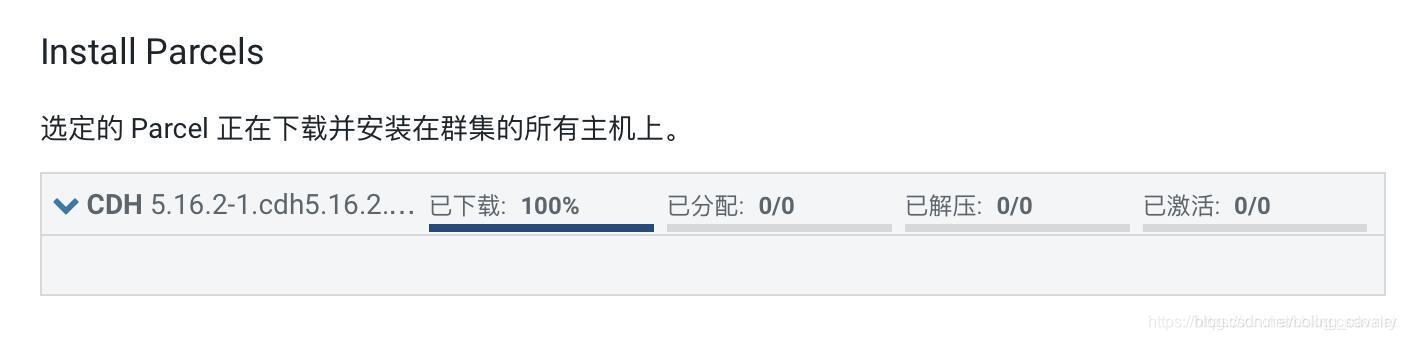
5. 進入安裝Parcel的頁面,由於提前上傳了離線parcle包,因此下載進度瞬間變成百分之百,此時請等待分配、解壓、啟用的完成:
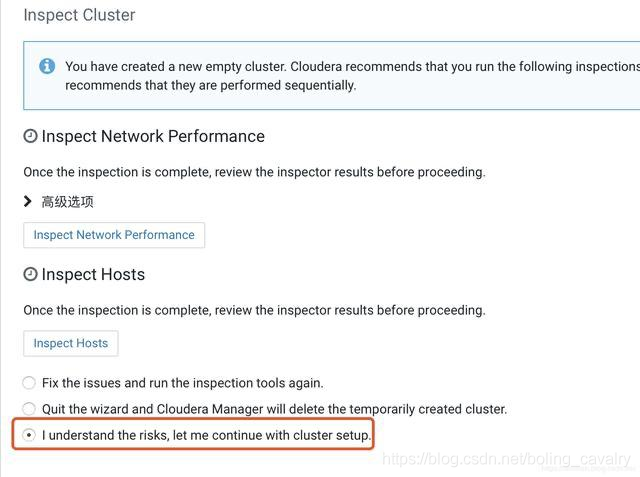
6. 接下來有一些推薦操作,這裡選擇如下圖紅框,即可跳過:
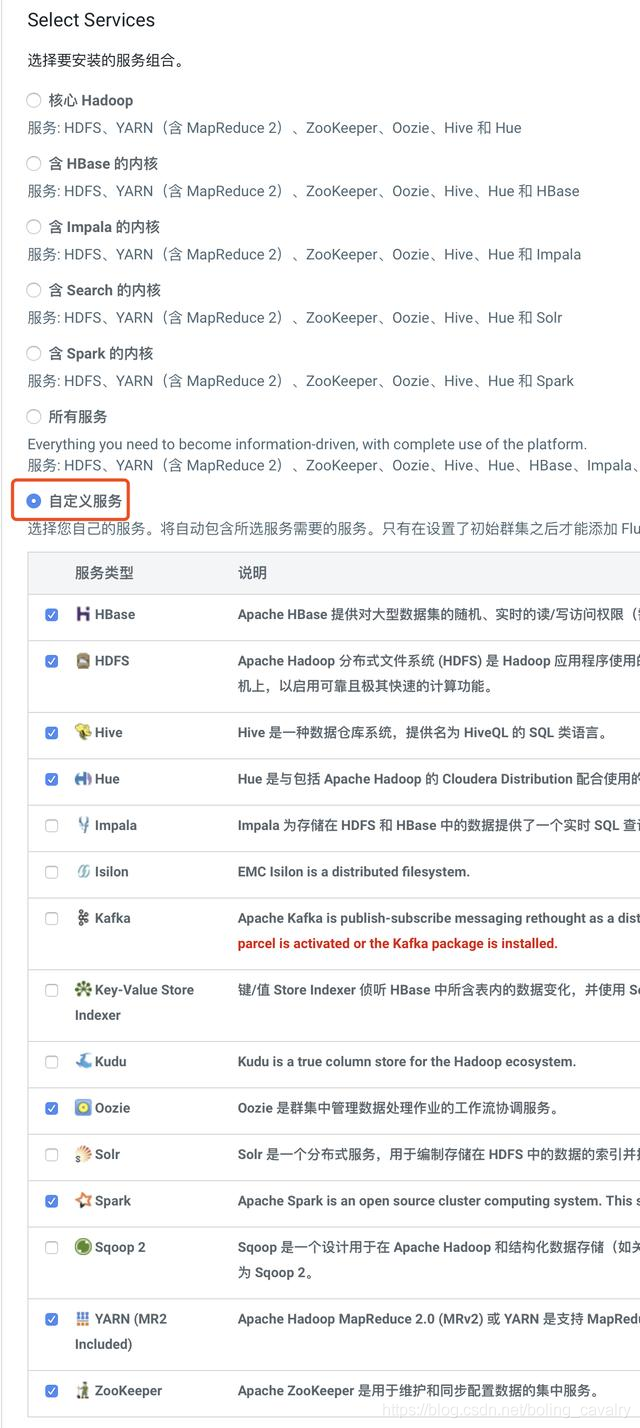
7. 接下來是選擇服務的頁面,我選擇了自定義服務,然後選擇了HBase、HDFS、Hive、Hue、Oozie、Spark、YARN、Zookeeper這八項,可以滿足執行Kylin的需要:
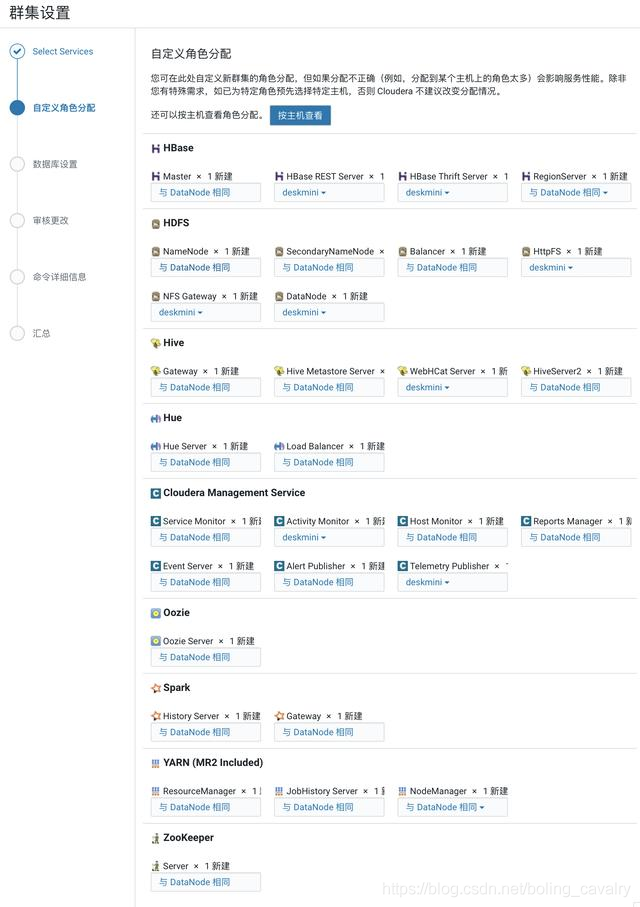
8. 在選擇主機的頁面,都選擇CDH伺服器:
9. 接下來是資料庫設定的頁面,您填寫的內容必須與下圖保持一致,即主機名為localhost,Hive的資料庫、使用者、密碼都是hive,Activity Monitor的資料庫、使用者、密碼都是amon,Reports Manager的資料庫、使用者、密碼都是rman,Oozie Server的資料庫、使用者、密碼都是oozie,Hue的資料庫、使用者、密碼都是hue,這些內容在ansible指令碼中已經固定了,此處的填寫必須保持一致:

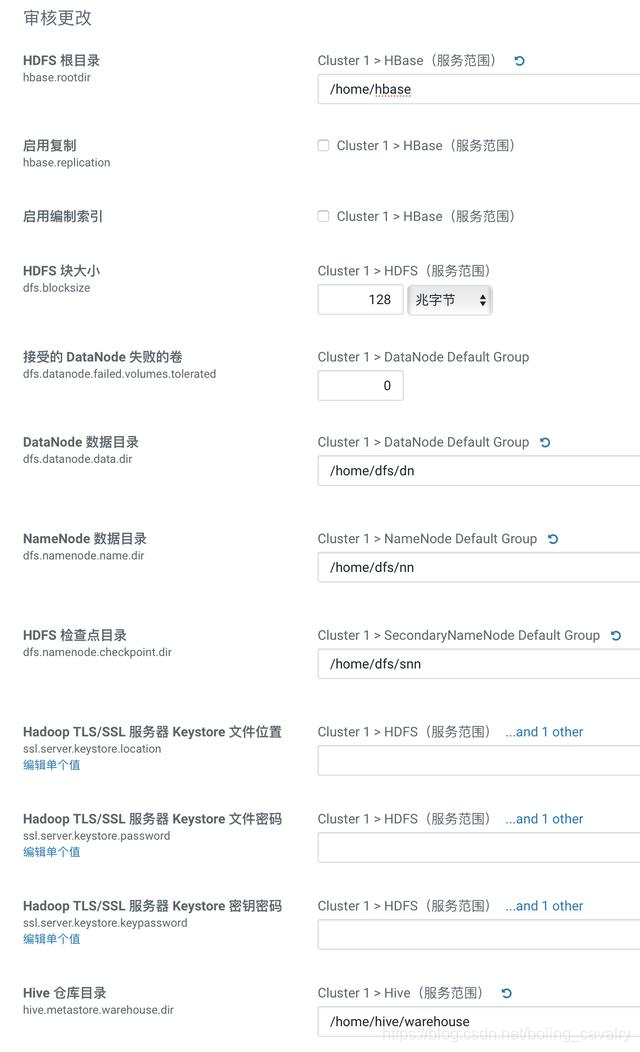
10. 在設定引數的頁面,請按照您的硬碟實際情況設定,我這裡/home目錄下空間充足,因此儲存位置都改為/home目錄下:
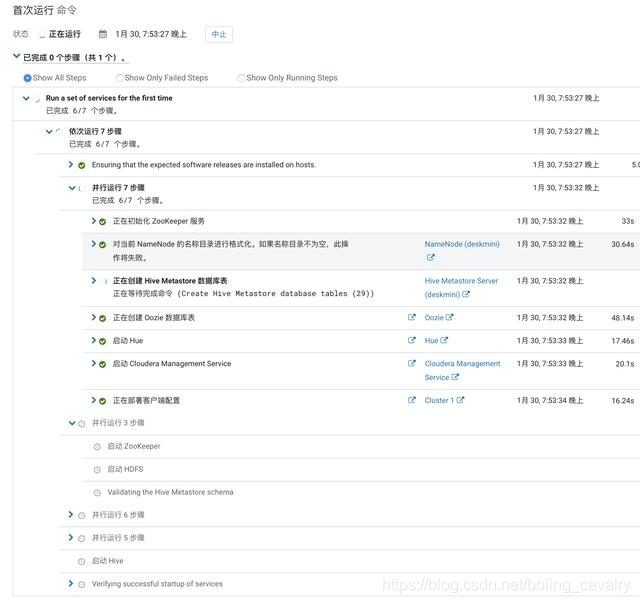
11. 等待服務啟動:
12. 各服務啟動完成:
### HDFS設定
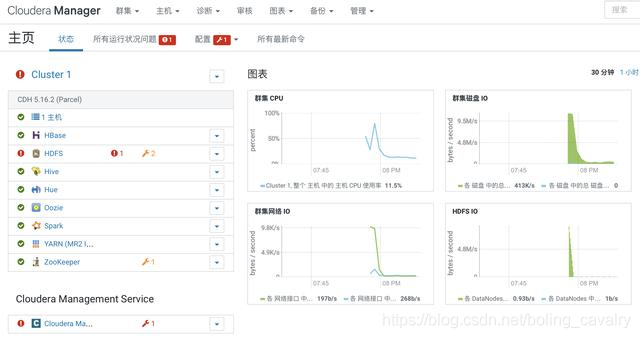
1. 如下圖紅框所示,HDFS服務存在問題:
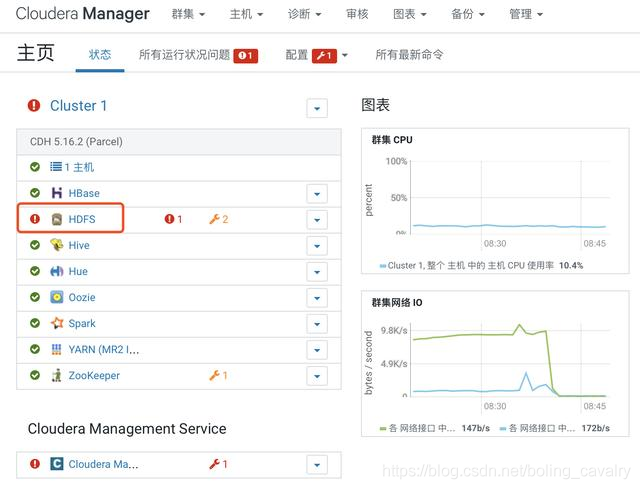
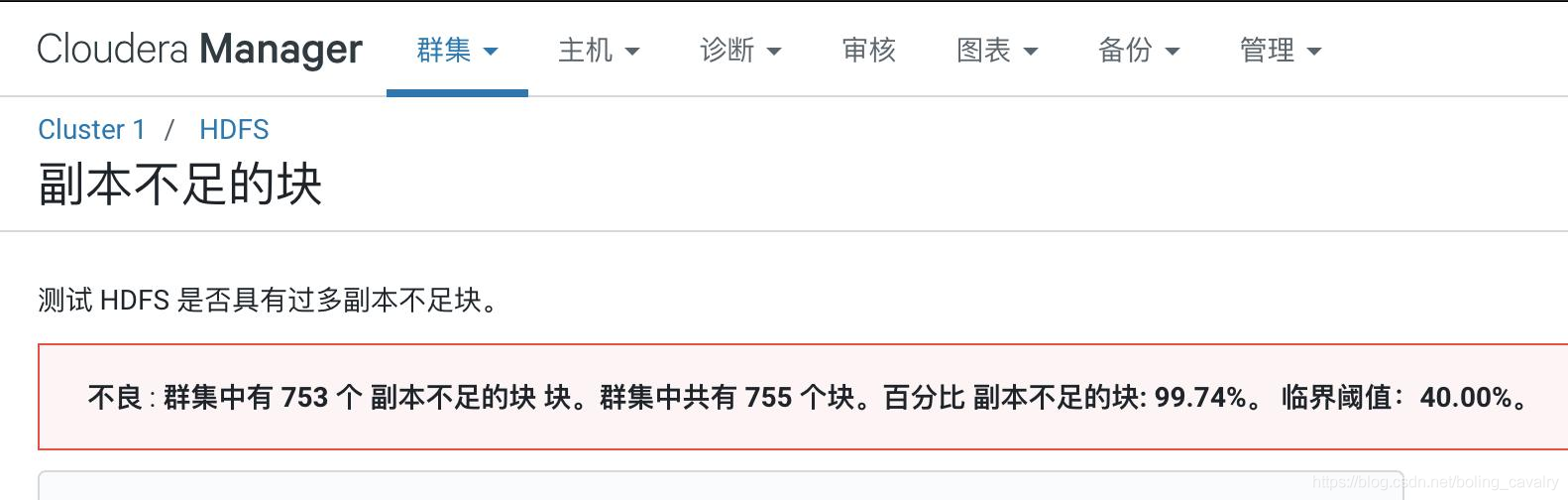
2. 點選上圖中紅色感嘆號可見問題詳情,如下圖,是常見的副本問題:
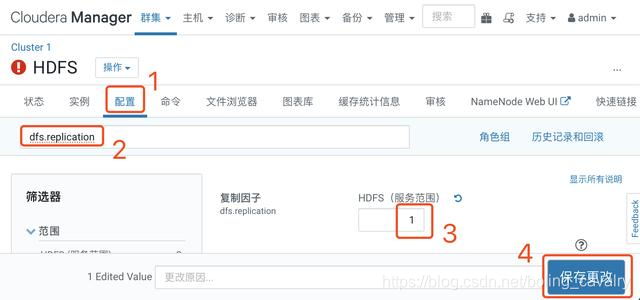
3. 操作如下圖,在HDFS的引數設定頁面,將dfs.replication的值設定為1(只有一個數據節點):
4. 經過上述設定,副本數已經調整為1,但是已有檔案的副本數還沒有同步,需要重新做設定,SSH登入到CDH伺服器上;
5. 執行命令su - hdfs切換到hdfs賬號,再執行以下命令即可完成副本數設定:
```shell
hadoop fs -setrep -R 1 /
```
6. 回到網頁,重啟HDFS服務,如下圖:
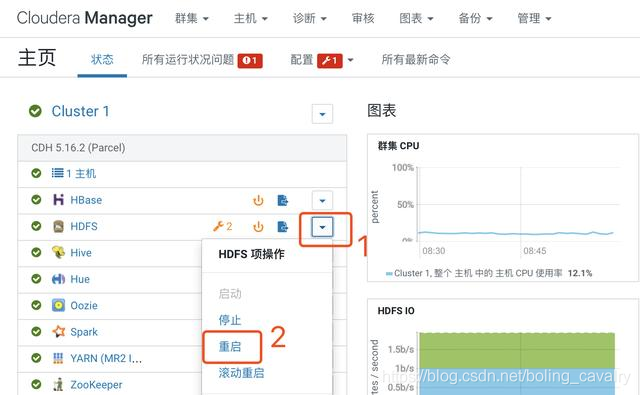
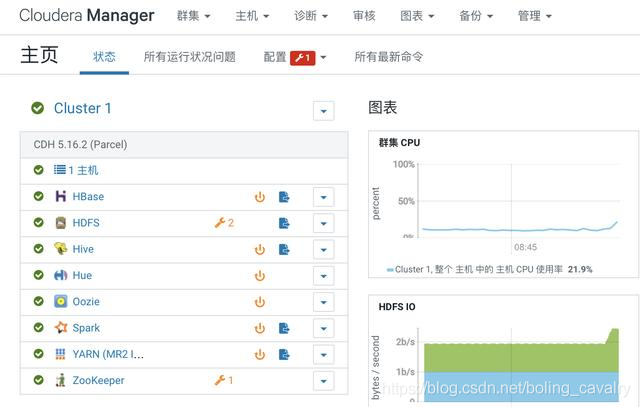
7. 重啟後HDFS服務正常:
### YARN設定
預設的YARN引數是非常保守的,需要做一些設定才能順利執行Spark任務:
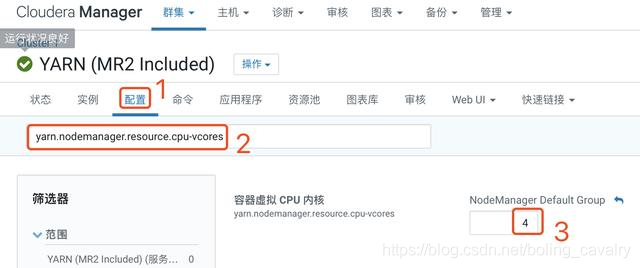
1. 進入YARN管理頁;
2. 如下圖所示,檢查引數yarn.nodemanager.resource.cpu-vcores的值,該值必須大於1,否則提交Spark任務後YARN不分配資源執行任務,(如果您的CDH伺服器是虛擬機器,當CPU只有單核時,則此引數就會被設定為1,解決辦法是先提升虛擬機器CPU核數,再來修改此引數):
3. yarn.scheduler.minimum-allocation-mb:單個容器可申請的最小記憶體,我這裡設定為1G
4. yarn.scheduler.maximum-allocation-mb:單個容器可申請的最大記憶體,我這裡設定為8G
5. yarn.nodemanager.resource.memory-mb:節點最大可用記憶體,我這裡設定為8G
6. 上述三個引數的值,是基於我的CDH伺服器有32G記憶體的背景,請您按照自己硬體資源自行調整;
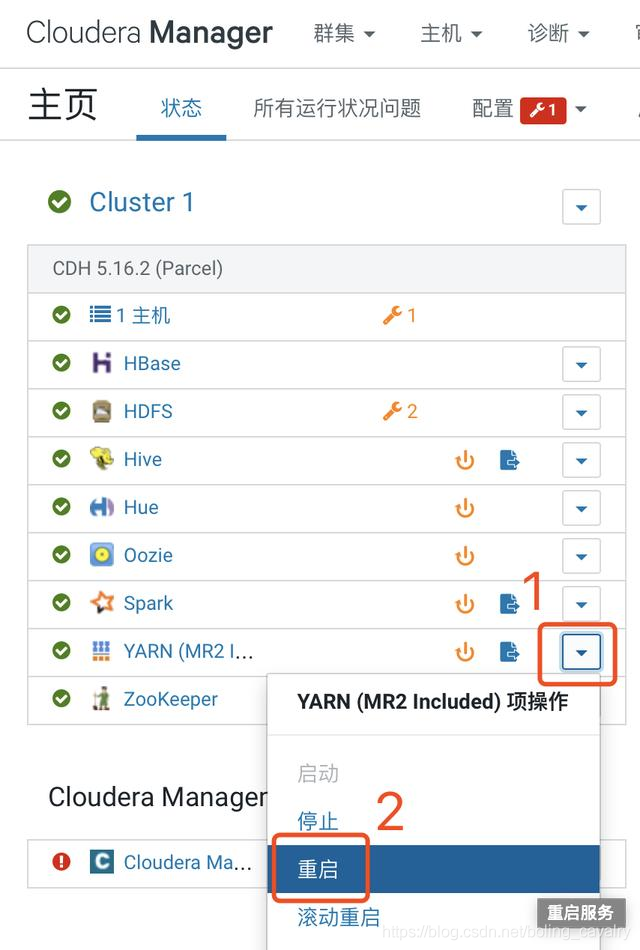
7. 設定完畢後重啟YARN服務,操作如下圖所示:
### Spark設定(CDH伺服器)
需要在Spark環境準備一個目錄以及相關的jar,否則Kylin啟動會報錯(提示spark not found, set SPARK_HOME, or run bin/download-spark.sh),以root身份SSH登入CDH伺服器,執行以下命令:
```shell
mkdir $SPARK_HOME/jars \
&& cp $SPARK_HOME/assembly/lib/*.jar $SPARK_HOME/jars/ \
&& chmod -R 777 $SPARK_HOME/jars
```
### 啟動Kylin(CDH伺服器)
1. SSH登入CDH伺服器,執行su - hdfs切換到hdfs賬號;
2. 按照官方推薦,先執行檢查環境的命令:$KYLIN_HOME/bin/check-env.sh
3. 檢查通過的話控制檯輸出如下:

4. 啟動Kylin:$KYLIN_HOME/bin/kylin.sh start
5. 控制檯輸出以下內容說明啟動Kylin成功:
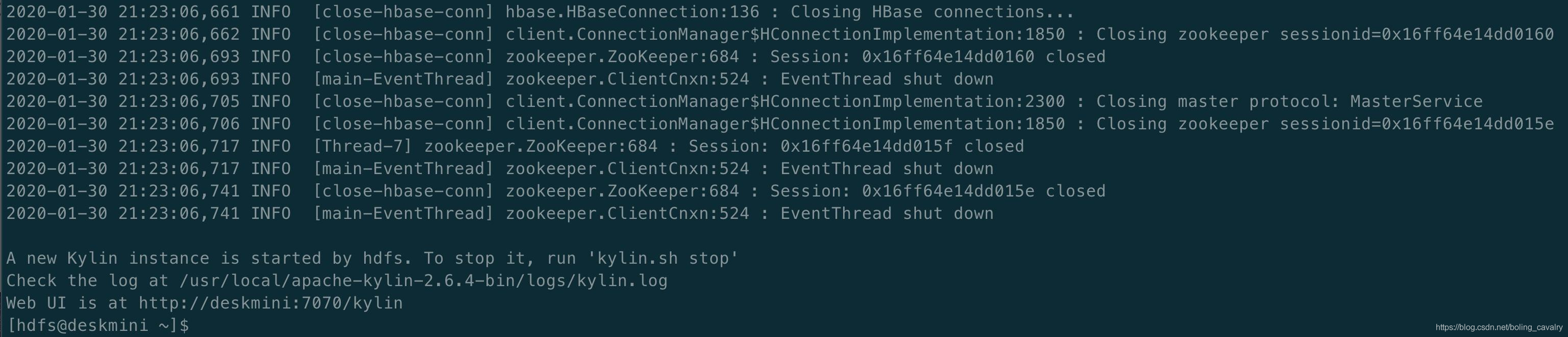
### 登入Kylin
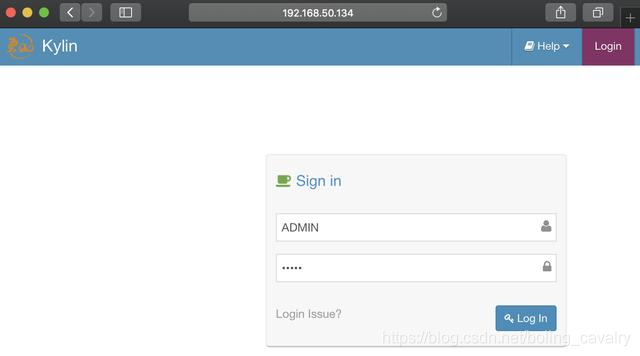
1. 瀏覽器訪問:http://192.168.50.134:7070/kylin,如下圖,賬號ADMIN,密碼KYLIN(賬號和密碼都是大寫):
2. 登入成功,可以使用了:
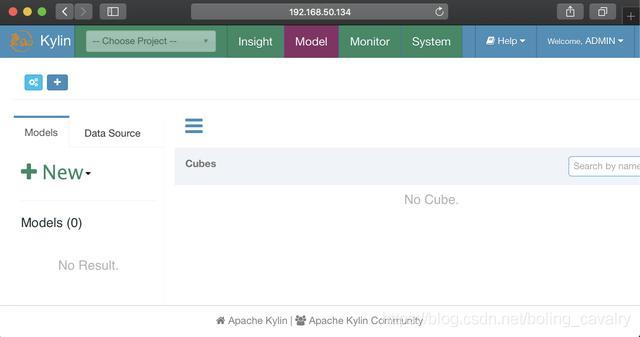
至此,CDH和Kylin的部署、設定、啟動都已完成,Kylin已經可用了,在下一篇文章中,我們就在此環境執行Kylin的官方demo,體驗Kylin;
### 歡迎關注公眾號:程式設計師欣宸
> 微信搜尋「程式設計師欣宸」,我是欣宸,期待與您一同暢遊Java世界...
[https://github.com/zq2599/blog_demos](https://github.com/zq2599/blo