
K近鄰演算法:機器學習萌新必學演算法
摘要:K近鄰(k-NearestNeighbor,K-NN)演算法是一個有監督的機器學習演算法,也被稱為K-NN演算法,由Cover和Hart於1968年提出,可以用於解決分類問題和迴歸問題。
1. 為什麼要學習k-近鄰演算法
k-近鄰演算法,也叫KNN演算法,是一個非常適合入門的演算法
擁有如下特性:
● 思想極度簡單
● 應用數學知識少(近乎為零)
● 對於各位開發者來說,很多不擅長數學,而KNN演算法幾乎用不到數學專業知識
● 效果好
○ 雖然演算法簡單,但效果出奇的好
○ 缺點也是存在的,後面會進行講解
● 可以解釋機器學習演算法使用過程中的很多細節問題
○我們會利用KNN演算法打通機器學習演算法使用過程,研究機器學習演算法使用過程中的細節問題
● 更完整的刻畫機器學習應用的流程
○ 對比經典演算法的不同之處
○ 利用pandas、numpy學習KNN演算法
2. 什麼是K-近鄰演算法
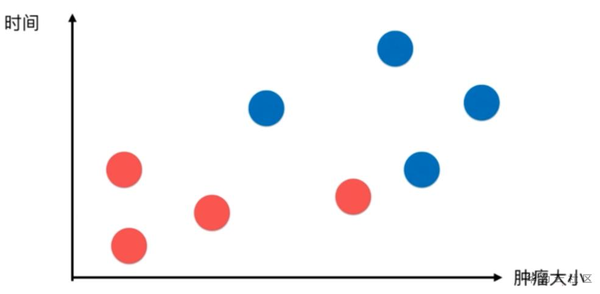
上圖中的資料點是分佈在一個特徵空間中的,通常我們使用一個二維的空間演示
橫軸表示腫瘤大小,縱軸表示發現時間。
惡性腫瘤用藍色表示,良性腫瘤用紅色表示。
此時新來了一個病人
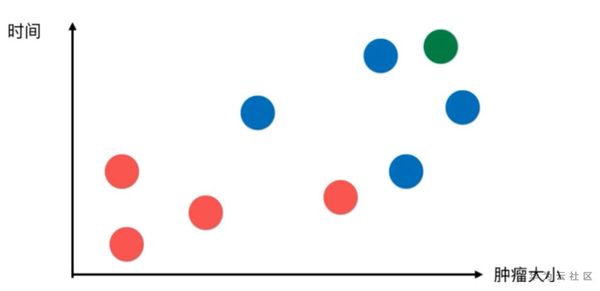
如上圖綠色的點,我們怎麼判斷新來的病人(即綠色點)是良性腫瘤還是惡性腫瘤呢?
k-近鄰演算法的做法如下:
取一個值k=3(此處的k值後面介紹,現在大家可以理解為機器學習的使用者根據經驗取得了一個經驗的最優值)。
k近鄰判斷綠色點的依據就是在所有的點中找到距離綠色點最近的三個點,然後讓最近的點所屬的類別進行投票,我們發現,最近的三個點都是藍色的,所以該病人對應的應該也是藍色,即惡性腫瘤。
本質:兩個樣本足夠相似,那麼他們兩個就具有更高概率屬於同一個類別。
但如果只看一個,可能不準確,所以就需要看K個樣本,如果K個樣本中大多數屬於同一個類別,則被預測的樣本就很可能屬於對應的類別。這裡的相似性就依靠舉例來衡量。
這裡我再舉一個例子
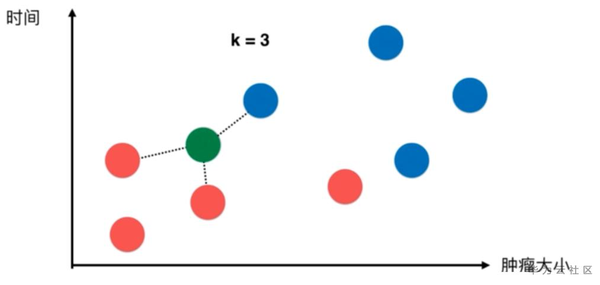
● 上圖中和綠色的點距離最近的點包含兩個紅色和一個藍色,此處紅色點和藍色點的數量比為2:1,則綠色點為紅色的概率最大,最後判斷結果為良性腫瘤。
● 通過上述發現,K近鄰演算法善於解決監督學習中的分類問題
點選關注,第一時間瞭解華為雲新鮮技