
Flink的DataSource三部曲之二:內建connector
阿新 • • 發佈:2020-11-06
### 歡迎訪問我的GitHub
[https://github.com/zq2599/blog_demos](https://github.com/zq2599/blog_demos)
內容:所有原創文章分類彙總及配套原始碼,涉及Java、Docker、Kubernetes、DevOPS等;
### 本篇概覽
本文是《Flink的DataSource三部曲》系列的第二篇,上一篇[《Flink的DataSource三部曲之一:直接API》](https://blog.csdn.net/boling_cavalry/article/details/105467076)學習了StreamExecutionEnvironment的API建立DataSource,今天要練習的是Flink內建的connector,即下圖的紅框位置,這些connector可以通過StreamExecutionEnvironment的addSource方法使用:
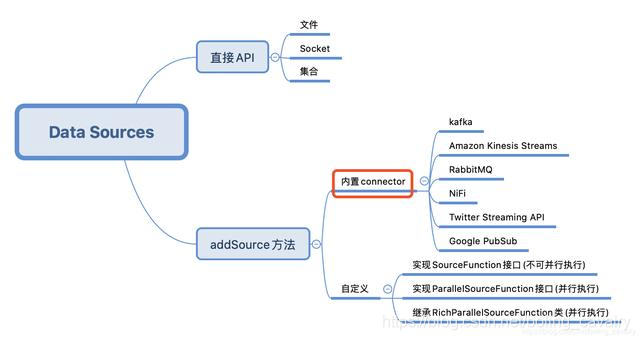
今天的實戰選擇Kafka作為資料來源來操作,先嚐試接收和處理String型的訊息,再接收JSON型別的訊息,將JSON反序列化成bean例項;
### Flink的DataSource三部曲文章連結
1. [《Flink的DataSource三部曲之一:直接API》](https://blog.csdn.net/boling_cavalry/article/details/105467076)
2. [《Flink的DataSource三部曲之二:內建connector》](https://blog.csdn.net/boling_cavalry/article/details/105471798)
3. [《Flink的DataSource三部曲之三:自定義》](https://blog.csdn.net/boling_cavalry/article/details/105472218)
### 原始碼下載
如果您不想寫程式碼,整個系列的原始碼可在GitHub下載到,地址和連結資訊如下表所示(https://github.com/zq2599/blog_demos):
| 名稱 | 連結 | 備註|
| :-------- | :----| :----|
| 專案主頁| https://github.com/zq2599/blog_demos | 該專案在GitHub上的主頁 |
| git倉庫地址(https)| https://github.com/zq2599/blog_demos.git | 該專案原始碼的倉庫地址,https協議 |
| git倉庫地址(ssh)| [email protected]:zq2599/blog_demos.git | 該專案原始碼的倉庫地址,ssh協議 |
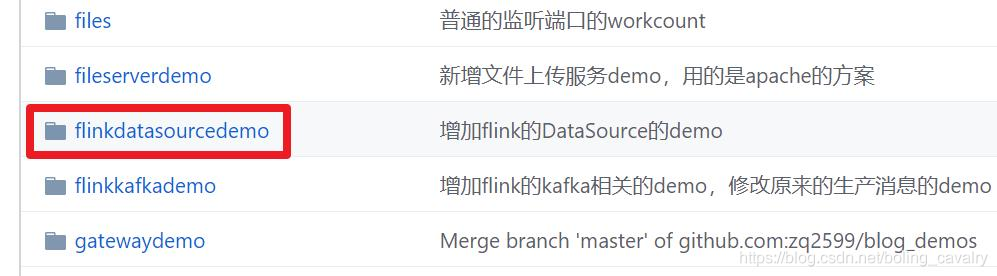
這個git專案中有多個資料夾,本章的應用在flinkdatasourcedemo資料夾下,如下圖紅框所示:
### 環境和版本
本次實戰的環境和版本如下:
1. JDK:1.8.0_211
2. Flink:1.9.2
3. Maven:3.6.0
4. 作業系統:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
5. IDEA:2018.3.5 (Ultimate Edition)
6. Kafka:2.4.0
7. Zookeeper:3.5.5
請確保上述內容都已經準備就緒,才能繼續後面的實戰;
### Flink與Kafka版本匹配
1. Flink官方對匹配Kafka版本做了詳細說明,地址是:https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
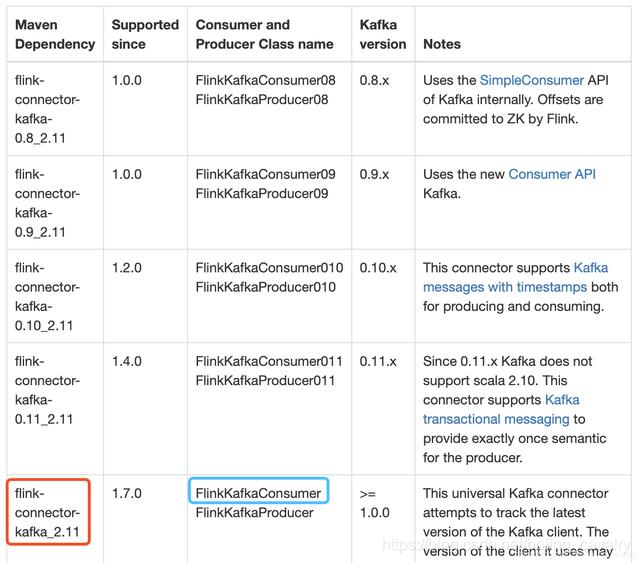
2. 要重點關注的是官方提到的通用版(universal Kafka connector ),這是從Flink1.7開始推出的,對於Kafka1.0.0或者更高版本都可以使用:

3. 下圖紅框中是我的工程中要依賴的庫,藍框中是連線Kafka用到的類,讀者您可以根據自己的Kafka版本在表格中找到適合的庫和類:
### 實戰字串訊息處理
1. 在kafka上建立名為test001的topic,參考命令:
```shell
./kafka-topics.sh \
--create \
--zookeeper 192.168.50.43:2181 \
--replication-factor 1 \
--partitions 2 \
--topic test001
```
2. 繼續使用上一章建立的flinkdatasourcedemo工程,開啟pom.xml檔案增加以下依賴:
```xml
```
3. 新增類Kafka240String.java,作用是連線broker,對收到的字串訊息做WordCount操作:
```java
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import static com.sun.tools.doclint.Entity.para;
public class Kafka240String {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//設定並行度
env.setParallelism(2);
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消費者的groupId
properties.setProperty("group.id", "flink-connector");
//例項化Consumer類
FlinkKafka