
重磅解讀:K8s Cluster Autoscaler模組及對應華為雲外掛Deep Dive
摘要:本文將解密K8s Cluster Autoscaler模組的架構和程式碼的Deep Dive,及K8s Cluster Autoscaler 華為雲外掛。
背景資訊
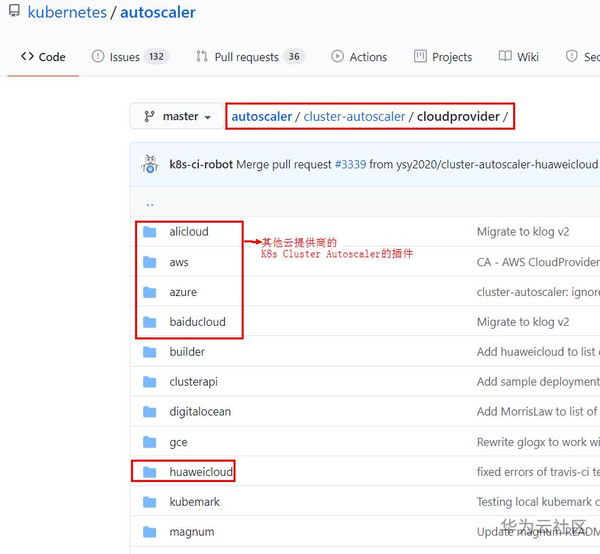
基於業務團隊(Cloud BU 應用平臺)在開發Serverless引擎框架的過程中完成的K8s Cluster Autoscaler華為雲外掛。 目前該外掛已經貢獻給了K8s開源社群,見下圖:
本文將會涉及到下述內容:
1. 對K8s Cluster Autoscaler模組的架構和程式碼的Deep Dive,尤其是核心功能點的所涉及的演算法的介紹。
2. K8s Cluster Autoscaler 華為雲外掛模組的介紹。
3. 作者本人蔘與K8s開源專案的一點心得。(如:何從開源社群獲取資訊和求助,在貢獻開源過程中需要注意的點)
直入主題,這裡不再贅述K8s的基本概念。
什麼是K8s Cluster Autoscaler (CA)?
什麼是彈性伸縮?
顧名思義是根據使用者的業務需求和策略,自動調整其彈性計算資源的管理服務,其優勢有:
1. 從應用開發者的角度:能夠讓應用程式開發者專注實現業務功能,無需過多考慮系統層資源
2. 從系統運維者的角度:極大的降低運維負擔, 如果系統設計合理可以實現“零運維”
3. 是實現Serverless架構的基石,也是Serverless的主要特性之一
在具體解釋CA概念之前,咋們先從巨集觀上了解一下K8s所支援的幾種彈性伸縮方式(CA只是其中的一種)。
K8s支援的幾種彈性伸縮方式:
注: 為了描述精確性,介紹下面幾個關鍵概念時,先引用K8S官方解釋鎮一下場 :)。"簡而言之"部分為作者本人的解讀。
VPA (Vertical Pod Autoscaler)
A set of components that automatically adjust the amount of CPU and memory requested by Pods running in the Kubernetes Cluster. Current state - beta.
簡而言之: 對於某一個POD,對其進行擴縮容(由於使用場景不多,不做過多介紹)
HPA(Horizontal Pod Autoscaler) - Pod級別伸縮
A component that scales the number of pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization (or, with beta support, on some other, application-provided metrics).
簡而言之: 對於某一Node, 根據預先設定的伸縮策略(如CPU, Memory使用率某設定的閥值),增加/刪減其中的Pods。
- HPA伸縮策略:
HPA依賴metrics-server元件收集Pod上metrics, 然後根據預先設定的伸縮策略(如:CPU使用率大於50%),來決定擴縮容Pods。計算CPU/Memory使用率時,是取所有Pods的平均值。關於具體如何計算的,點選此處有詳細演算法介紹。
注:metrics-server預設只支援基於cpu和memory監控指標伸縮策略 - HPA架構圖:
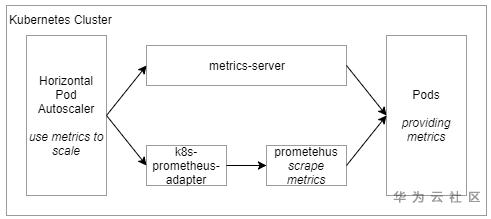
圖中下半部門Prometheus監控系統和K8s Prometheus Adapter元件的引入是為了能夠使用自定義的metrics來設定伸縮策略,由於不是本文的重點,這裡不做過多介紹, K8s官方文件有個Walkthrough案例一步一步在實操中掌握和理解該模組。如果使用者只需要依據cpu/memory的監控指標來設定伸縮策略,只要deploy預設的metrics-server元件(其安裝對K8s來說就是一次deployment,非常方便, 上面的連結裡有安裝步驟)
CA (Cluster Autoscaler)- Node級別伸縮
A component that automatically adjusts the size of a Kubernetes Cluster so that: all pods have a place to run and there are no unneeded nodes.
簡而言之: 對於K8S叢集,增加/刪除其中的Nodes,達到叢集擴縮容的目的。
Kubernetes(K8s) Cluster Autoscaler(CA)模組原始碼解析:
前面做了這麼多鋪墊,是時候切入本文主題了。下面我將主要從架構和程式碼兩個維度來揭開CA模組的神祕面紗,並配合FAQ的形式解答常見的問題。
CA整體架構及所含子模組
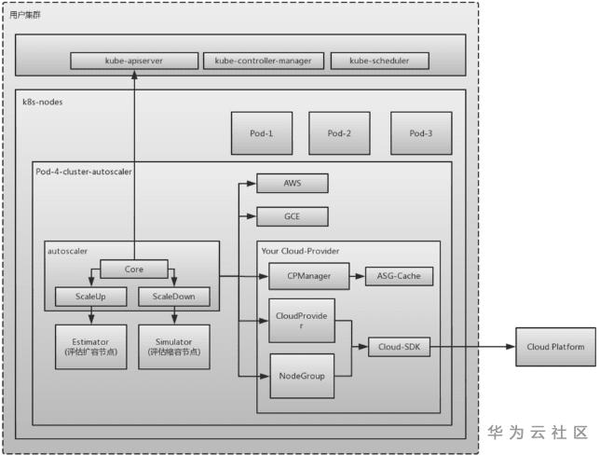
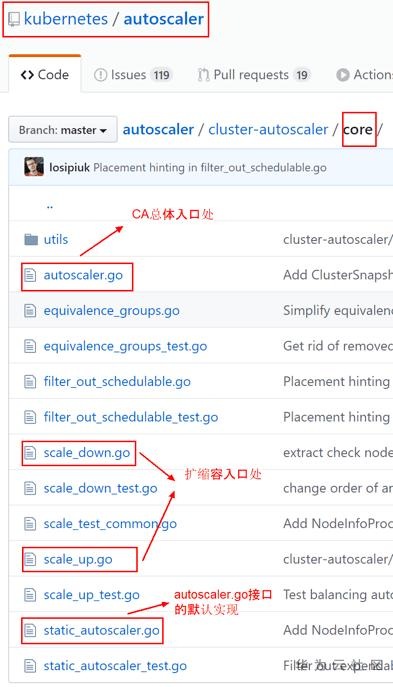
如上圖所示, CA模組包含以下幾個子模組, 詳見K8S CA模組在Github的原始碼:
- autoscaler: 核心模組,包含核心Scale Up和Scale Down功能(對應Github裡 core Package)。
1. 在擴容時候:其ScaleUp函式會呼叫estimator模組來評估所需節點數
2. 在縮容時:其ScaleDown函式會呼叫simulator模組來評估縮容的節點數
- estimator: 負責計算擴容需要多少Node (對應Github裡 estimator Package)
- simulator: 負責模擬排程,計算縮容節點 (對應Github裡 simulator Package)
- expander: 負責擴容時,選擇合適的Node的演算法 (對應Github裡 expander Package),可以增加或定製化自己的演算法
- cloudprovider: CA模組提供給具體雲提供商的介面 (對應Github裡cloudprovider Package)。關於這個子模組後面也會著重介紹,也是我們華為雲cloudprovider的擴充套件點。
1. autoscaler通過該模組與具體雲提供商對接(如上圖右下角方框所示 AWS, GCE等雲提供商),並可以排程每個雲提供商提供的Node.
2. cloudprovider預先設定了一些列介面,供具體的雲提供商實現,來完成排程其提供的Node的目的
通過對K8s CA模組的架構和原始碼的織結構的介紹,我總結有以下幾點最佳實踐值得學習和借鑑, 可以適用在任何程式語言上:
1. SOLID設計原則無處不在,具體反映在:
1. 每個子模組僅負責解決某一特定問題 - 單一職責
2. 每個子模組都預留有擴充套件點 - 開閉原則
3. 每個子模組的介面隔離做的很清晰 - 介面分離原則
…
清晰的子模組包的組織結構
外掛式的擴充套件點設計
關於CA模組的使用者常見問題
1. CA和k8s其他彈性伸縮方式的關係?
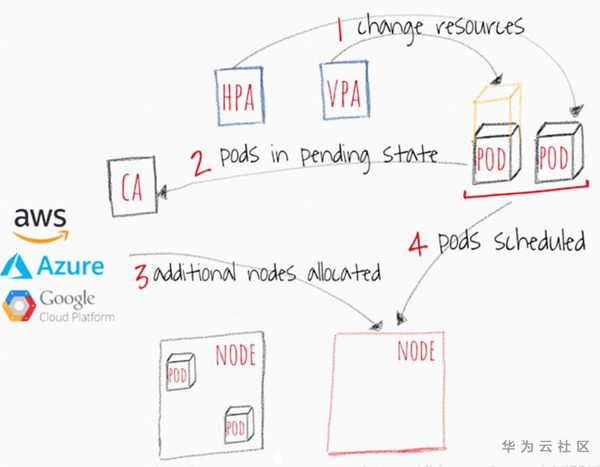
1. VPA更新已經存在的Pod使用的resources
2. HPA更新已經存在的Pod副本數
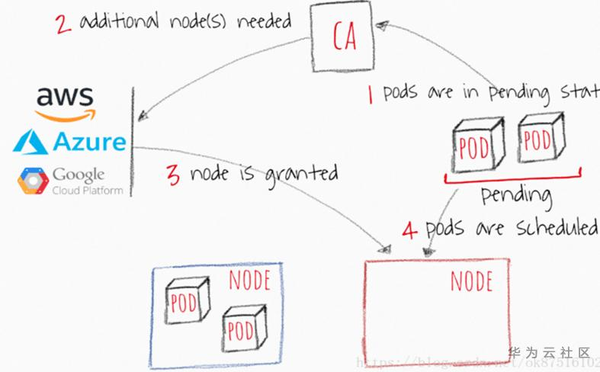
3. 如果沒有足夠的節點在可伸縮性事件後執行POD,則CA會擴容新的Node到叢集中,之前處於Pending狀態的Pods將會被排程到被新管理的node上
2. CA何時調整K8S叢集大小?
- 何時擴容: 當資源不足,Pod排程失敗,即存在一直處於Pending狀態的Pod(見下頁流程圖), 從Cloud Provider處新增NODE到叢集中
- 何時縮容: Node的資源利用率較低,且Node上存在Pod都能被重新排程到其它Node上去
3. CA多久檢查一次Pods的狀態?
CA每隔10s檢查是否有處於pending狀態的Pods
4. 如何控制某些Node不被CA在縮容時刪除?
0. Node上有Pod被PodDisruptionBudget控制器限制。PodDisruptionBudgetSpec
1. Node上有名稱空間是kube-system的Pods。
2. Node上Pod被Evict之後無處安放,即沒有其他合適的Node能排程這個pod
3. Node有annotation: “cluster-autoscaler.kubernetes.io/scale-down-disabled”: “true”
4. Node上存有如下annotation的Pod:“cluster-autoscaler.kubernetes.io/safe-to-evict”: “false”.點選見詳情
若想更進一步瞭解和學習,請點選這裡檢視更完整的常見問題列表及解答。
CA模組原始碼解析
由於篇幅關係,只對核心子模組深入介紹,通過結合核心子模組與其他子模組之間如何協調和合作的方式順帶介紹一下其他的子模組。
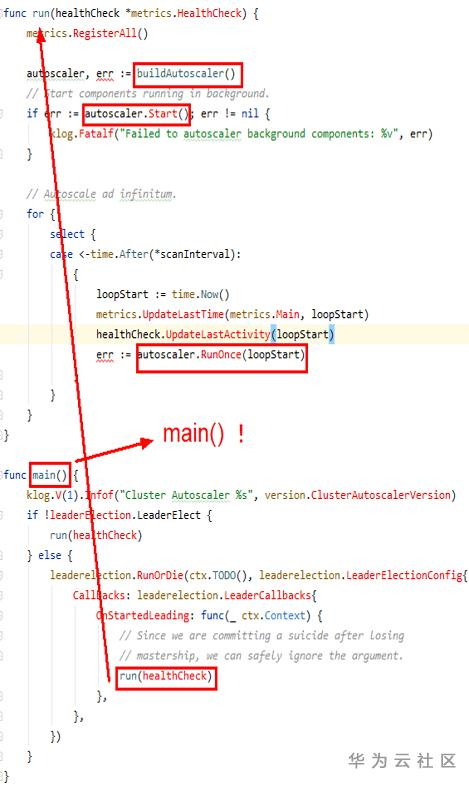
CA模組整體入口處
程式啟動入口處:kubernetes/autoscaler/cluster-autoscaler/main.go
CA的autoscaler子模組
如上圖所示,autoscaler.go是介面,其預設的實現是static_autoscaler.go, 該實現會分別呼叫scale_down.go和scale_up.go裡的ScaleDown以及ScaleUp函式來完成擴縮容。
那麼問題來了,合適ScaleUp和ScaleDown方法會被呼叫呢,咋們按照順序一步一步來捋一下, 回到CA整體入口,那裡有一個RunOnce(在autoscaler介面的預設實現static_autoscaler.go裡)方法,會啟動一個Loop 一直執行listen和watch系統裡面是否有那些處於pending狀態的Pods(i.e. 需要協助找到Node的Pods), 如下面程式碼片段(static_autoscaler.go裡的RunOnce函式)所示, 值得注意的是,在實際呼叫ScaleUp之前會有幾個 if/else 判斷是否符合特定的條件:

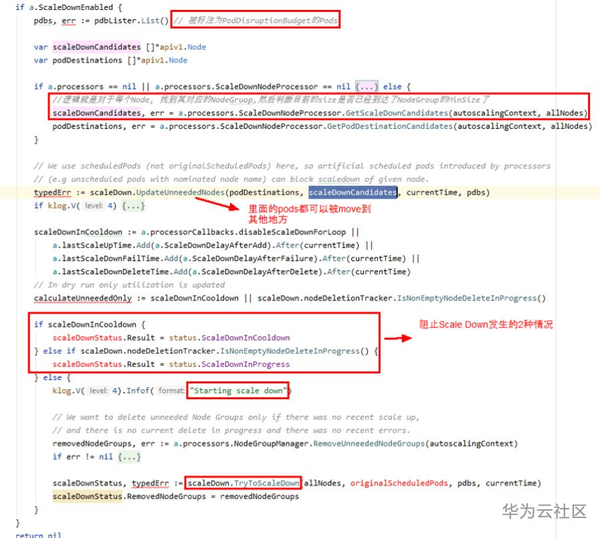
對於ScaleDown函式的呼叫,同理,也在RunOnce函式裡, ScaleDown主要邏輯是遵循如下幾步:
1. 找出潛在的利用率低的Nodes (即程式碼裡的scaleDownCandidates陣列變數)
2. 然後為Nodes裡的Pods找到“下家”(即可以被安放的Nodes,對應程式碼裡的podDestinations陣列變數)
3. 然後就是下面截圖所示,幾個if/else判斷符合ScaleDown條件,就執行TryToScaleDown函式
通過上面的介紹結合程式碼片段,我們瞭解到何時ScaleUp/ScaleDown函式會被呼叫。接下來,我們來看看當這兩個核心函式被呼叫時,裡面具體都發生了什麼。
先來看一下ScaleUp:

從上圖程式碼片段,以及我裡面標註的註釋,可以看到,這裡發生了下面幾件事:
1. 通過cloudprovider子模組(下面專門介紹這個子模組)從具體雲提供商處獲取可以進行擴容的的NodeGroups
2. 把那些Unschedulable Pods按照擴容需求進行分組(對應上面程式碼裡的對buildPodEquivalenceGroups函式的呼叫)
3. 把第1步得到的所有可用的NodeGroups和第2步得到的待分配的Pods, 作為輸入,送入給estimator子模組的裝箱演算法(該呼叫發生對上圖中computeExpansionOption函式呼叫內部) ,得到一些候選的Pods排程/分配方案。由於estimator子模組的核心就是裝箱演算法,下圖就是實現了裝箱演算法的Estimate函式,這裡實現有個小技巧,就是演算法開始之前,先呼叫calculatePodScore把兩維問題降為一維問題(即Pod對CPU和Memory的需求),然後就是傳統的裝箱演算法,兩個for loop來給 Pods找到合適的Node. 至於具體如何降維的,詳見binpacking.estimator.go裡的calculatePodScore函式原始碼。
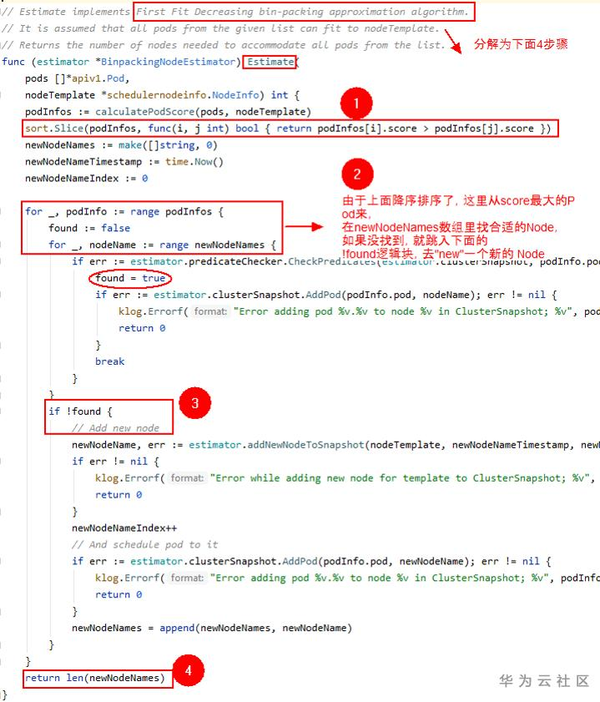
4. 把第3步得到的一些方案,送入給 expander子模組,得到最優的分配方案(對應程式碼片段中ExpanderStrategy.BestOption的函式呼叫)expander提供了下面截圖中的集中策略,使用者可以通過實現expander介面的BestOption函式,來實現自己的expander策略
CA的cloudprovider子模組
與具體的雲提供商(i.e. AWS, GCP, Azure, Huawei Cloud)對接來對對應雲平臺上的Node Group(有的雲平臺叫Node Pool)裡的Node進行增刪操作已達到擴縮容的目的。其程式碼對應於與之同名的cloudprovider package。詳見Github程式碼。 沒個雲提供商,都需要按照k8s約定的方式進行擴充套件,開發自家的cloudprovider外掛,如下圖:
下文會專門介紹華為雲如何擴充套件該模組的。
華為雲cloudprovider外掛開發及開源貢獻心得
華為雲cloudprovider外掛如何擴充套件和開發的?
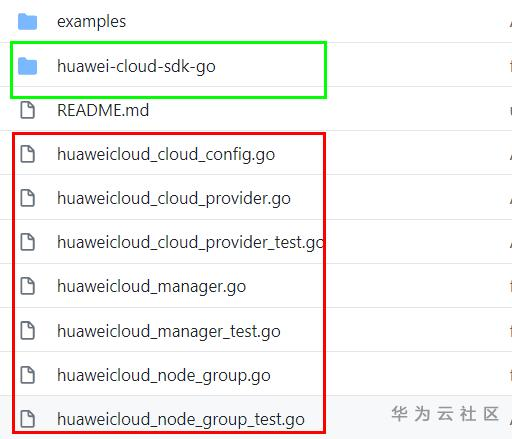
下圖是華為cloudprovider外掛的大致的程式碼結構, 綠色框裡是SDK實際是對CCE(雲容器引擎 CCE) 進行必要操作所需要的 (對Node Pool/Group裡的Node 進行增加和刪除)。 按理說我們不需要自己寫這一部分,不過由於咋們雲CCE 團隊的SDK實在是不完善,所以我們開發了一些必要的對CCE進行操作的SDK。重點是紅色框中的程式碼:
huaweicloud_cloud_provider.go是入口處,其負責總huaweicloud_cloud_config.go讀取配置,並例項化huaweicloud_manager.go物件。huaweicloud_manager.go物件裡通過呼叫藍色框部門裡的CCE SDK來獲取CCE整體的資訊。 CCE整體的資訊被獲取到後,可以呼叫huaweicloud_node_group.go 來完成對該CCE繫結的Node Group/Pool進行Node的擴縮容已達到對整體CCE的Node伸縮。
如何從開源社群獲取所需資源及開源過程中需要注意的點?
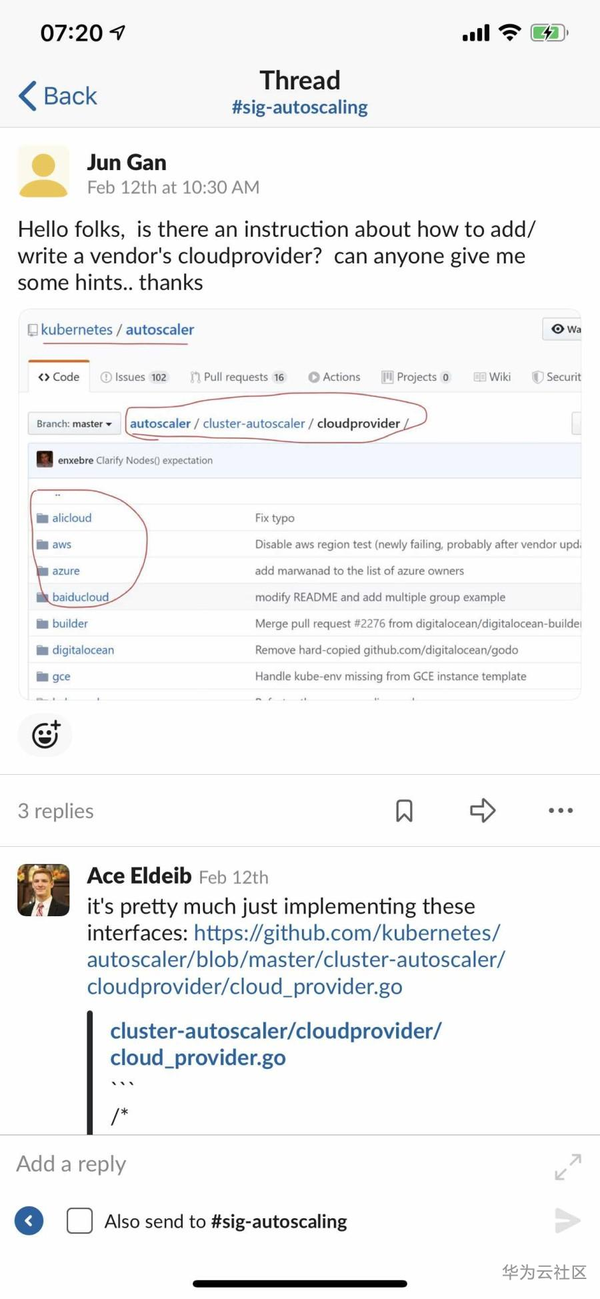
我剛開始接受該專案的時候,一頭霧水,不知道該如何下手。K8s關於這一塊的文件寫的又不是很清楚。以往的經驗以及K8s Github README中提供的資訊,我加入他們的Slack組織,找到相應的興趣組channel( 對應我的情況就是sig-autoscaling channel),提出了我的問題(如下面截圖)。 基於K8s程式碼倉的大小,如果沒找到合適的擴充套件點,幾乎無法改動和擴充套件的。
劃重點: 現在幾乎所有的開源組中都有Slack群組,加入找到相應的興趣組,裡面大牛很多,提出問題,一般會有人熱心解答的。 郵件列表也可以,不過我認為Slack高效實時一點,強烈推薦。對於我本人平常接觸到的開源專案,我一般都會加入到其 Slack中,有問題隨時提問。 當然,中國貢獻的開源專案,好多以微信群的方式溝通 :)譬如咋們華為開源出去的微服務框架專案 ServiceComb,我也有加微信群。總之, 對於開源專案,一定要找到高效的和組織溝通的方式。

另外,對於貢獻程式碼過程中,如果使用到了三方開原始碼,由於版權和二次分發的問題,儘量避免直接包含三方原始碼, 如果實在需要,可以對其進行擴充套件,並在新擴充套件的檔案附上華為的版權資訊與免責宣告。
點選關注,第一時間瞭解華為雲新鮮技