
ElasticSearch 叢集基本概念及常用操作彙總(建議收藏)
阿新 • • 發佈:2020-11-10
內容來源於本人的印象筆記,簡單彙總後釋出到部落格上,供大家需要時參考使用。
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
目錄:
* [ElasticSearch叢集特性](#elasticsearch叢集特性)
* [es部署安裝,要踩的坑少不了](#es部署安裝,要踩的坑少不了)
* [ElasticSearch CRUD操作](#elasticsearchcrud操作)
* [ElasticSearch Search操作](#elasticsearchsearch操作)
* [ElasticSearch 分詞器analyzer](#elasticsearch分詞器analyzer)
# ElasticSearch,叢集特性
ES的叢集是基於Master Slave架構的
叢集中一個節點被選舉為主節點後,
它將負責管理叢集範圍內的所有變更,例如增加、刪除索引,或者增加、刪除節點等;
而主節點並不需要涉及到文件級別的變更和搜尋等操作,所以當叢集只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸。 任何節點都可以成為主節點;
作為使用者,我們可以將請求傳送到 叢集中的任何節點 ,包括主節點。 每個節點都知道任意文件所處的位置,並且能夠將我們的請求直接轉發到儲存我們所需文件的節點。 無論我們將請求傳送到哪個節點,它都能負責從各個包含我們所需文件的節點收集回資料,並將最終結果返回給客戶端。
## 分片
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/routing-value.html#routing-value
Elasticsearch 是利用分片將資料分發到叢集內各處的。分片是資料的容器,文件儲存在分片內,分片又被分配到叢集內的各個節點裡。 當你的叢集規模擴大或者縮小時, Elasticsearch 會自動的在各節點中遷移分片,使得資料仍然均勻分佈在叢集裡;
一個分片可以是 主 分片或者 副本 分片。 索引內任意一個文件都歸屬於一個主分片,所以主分片的數目決定著索引能夠儲存的最大資料量。
```
技術上來說,一個主分片最大能夠儲存 Integer.MAX_VALUE - 128 個文件,但是實際最大值還需要參考你的使用場景:包括你使用的硬體, 文件的大小和複雜程度,索引和查詢文件的方式以及你期望的響應時長。
```
一個副本分片只是一個主分片的拷貝。**副本分片作為硬體故障時保護資料不丟失的冗餘備份,併為搜尋和返回文件等讀操作提供服務。**
**在索引建立的時候就已經確定了主分片數,但是副本分片數可以隨時修改。**
注:索引建立的時候就需要確定好主分片的數量,因為索引一旦建立完成後,主分片的數量將不可以再變更,只能動態的修改副本分片數,而副本分片數只能提供搜尋和返回文件等讀操作時提供相關的服務,所以通過增加副本數可以增加叢集讀操作的可用性;但是對於索引中資料的儲存,還是隻能儲存在主分片上,所以,合理的確定主分片的值,對於後續的叢集的擴充套件是很有必要和好處的;
### 建立資料時的路由策略
當索引一個文件的時候,文件會被儲存到一個主分片中。 Elasticsearch 如何知道一個文件應該存放到哪個分片中呢?當我們建立文件時,它如何決定這個文件應當被儲存在分片 1 還是分片 2 中呢
首先這肯定不會是隨機的,否則將來要獲取文件的時候我們就不知道從何處尋找了。實際上,這個過程是根據下面這個公式決定的:shard = hash(routing) % number_of_primary_shards
routing 是一個可變值,預設是文件的 _ id ,也可以設定成一個自定義的值。 routing 通過 hash 函式生成一個數字,然後這個數字再除以 number_of_primary_shards (主分片的數量)後得到 餘數 。這個分佈在 0 到 number_of_primary_shards-1 之間的餘數,就是我們所尋求的文件所在分片的位置;
這就解釋了為什麼我們要在建立索引的時候就確定好主分片的數量 並且永遠不會改變這個數量:因為如果數量變化了,那麼所有之前路由的值都會無效,文件也再也找不到了。
那麼前期如何更好的設計好我們的ES叢集的主分片數,來保證可以支撐後續的業務呢?
詳情可以參考:資料建模-擴容設計章節
https://www.elastic.co/guide/cn/elasticsearch/guide/current/scale.html
**所有的文件 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一個叫做 routing的路由引數 ,通過這個引數我們可以自定義文件到分片的對映。一個自定義的路由引數可以用來確保所有相關的文件——例如所有屬於同一個使用者的文件——都被儲存到同一個分片中。除了索引建立時不支援路由外,其他的資料匯入,搜尋等操作都可以指定路由進行操作;索引建立肯定是由主節點來操作的**
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# ES部署安裝,要踩的坑少不了
此處直接使用的是elasticsearch-7.3.2的版本,所以提示:Elasticsearch的未來版本將需要Java 11;您的Java版本從[/opt/package/jdk1.8.0_241/jre]不滿足此要求,此處直接註釋掉了本地環境變數對JDK的對映,直接使用es自帶的java啟動就行
```
future versions of Elasticsearch will require Java 11; your Java version from [/opt/package/jdk1.8.0_241/jre] does not meet this requirement
```
如下所示:為了安全考慮es不支援直接使用root使用者啟動
```
[2020-06-15T10:24:11,746][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [VM_0_5_centos] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
```
此處新建一個新的elsearch使用者進行啟動
```
新建elsearch使用者組 以及elsearch使用者
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
將對應的elasticsearch-7.3.2目錄授權給elsearch
chown -R elsearch:elsearch /opt/shengheApp/elasticsearch/elasticsearch-7.3.2
切換使用者進行es的啟動
su elsearch #切換賬戶
cd elasticsearch/bin #進入你的elasticsearch目錄下的bin目錄
./elasticsearch
# 指定jvm記憶體啟動,
ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch
後臺啟動模式
./elasticsearch -d
```
修改ES配置為所有IP都可以訪問,network.host修改為 0.0.0.0
```
network.host: 0.0.0.0
````
修改完IP配置項後,啟動將會異常,提示如下:
```
[VM_0_5_centos] publish_address {172.17.0.5:9300}, bound_addresses {[::]:9300}
[2020-06-15T10:46:53,894][INFO ][o.e.b.BootstrapChecks ] [VM_0_5_centos] bound or publishing to a non-loopback address, enforcing bootstrap checks
ERROR: [3] bootstrap checks failed
[1]: initial heap size [536870912] not equal to maximum heap size [1073741824]; this can cause resize pauses and prevents mlockall from locking the entire heap
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解決方式如下:
解決第一個警告:
由於我本機記憶體不足所以啟動的時候,直接指定了JVM引數進行了啟動:ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch
但是:bin/elasticsearch在啟動的時候會去載入config/jvm.options 下的jvm配置,由於jvm.options下Xms和Xmx配置為1g,所以啟動的時候提示衝突了,初始堆大小512M和最大堆大小1g,不匹配;解決方式是,啟動的時候將命令更改為: ES_JAVA_OPTS="-Xms512m -Xmx512M" ./bin/elasticsearch , 或者直接修改jvm.options中Xms和Xmx的大小,然後直接 ./bin/elasticsearch啟動也行
解決第二個警告:
臨時提高了vm.max_map_count的大小,此操作需要root許可權:
sysctl -w vm.max_map_count=262144
sysctl -a|grep vm.max_map_count # 設定完成後可以通過該命令檢視是否設定成功
永久修改vm.max_map_count的大小:
vi /etc/sysctl.conf 新增下面配置: vm.max_map_count=655360 並執行命令: sysctl -p 然後,重新啟動elasticsearch,即可啟動成功。
解決第三個警告:
叢集節點問題,我們現在只啟動一個節點測試,所以修改當前節點的名稱為:node-1,然後配置cluster.initial_master_nodes 初始化節點為自身的node-1節點即可;
配置elasticsearch.yml檔案如下:
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
然後重啟es即可
```
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# ElasticSearch,CRUD操作
**索引受檔案系統的限制。僅可能為小寫字母,不能下劃線開頭**。同時需遵守下列規則:
不能包括 , /, *, ?, ", <, >, |, 空格, 逗號, #
7.0版本之前可以使用冒號:,但不建議使用並在7.0版本之後不再支援
不能以這些字元 -, _, + 開頭
不能包括 . 或 …
長度不能超過 255 個字元
以上這些命名限制是因為當Elasticsearch使用索引名稱作為磁碟上的目錄名稱,這些名稱必須符合不同作業系統的約定。
我猜想未來可能會放開這些限制,因為我們使用uuid關聯索引放在磁碟上,而不使用索引名稱。
型別
型別名稱可以包括除了null的任何字元,不能以下劃線開頭。7.0版本之後不再支援型別,預設為_doc.
------------
基於ES7.0+版本
1、
```
新增一個文件
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
```
如上,建立一個twitter的索引,並且建立一個叫做_doc的type,並插入一個文件1,(在ES7中,一個index只能有一個type,如果建立多個type將會提示異常,預設情況下因為只能建立一個type,所以預設叫做_doc即可;)
新插入的資料一般不會實時參與到搜尋中,可以通過呼叫如下介面,使ES強勢進行一次refersh操作;(除此之外在建立index時也可以設定referch的週期,預設為1,也就是每一秒重新整理一下新的資料到索引中,)
2、
```
新增資料並實時重新整理到索引中
PUT twitter/_doc/1?refresh=true
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
```
預設情況下執行(上述1的)dsl語句, 第一步判斷是確定插入的文件是否指定id,如果沒有指定id,系統會預設生成一個唯一id,上述我們指定了id為(1),所以插入es時,將按照我們指定的id進行插入,
並且,如果當前該Id是在es中已經存在的,那麼此時將會進行第二次判斷,檢查插入時是否指定了_version,如果插入時沒有指定_version,那麼對於已有的doc資料,_version會進行遞增,並將文件進行更新覆蓋,如果插入時指定了_version,那麼判斷當前所指定的_version於現有的文件的_version是否相等,相等則覆蓋,不相等則插入失敗(注意:這裡則類似於一個樂觀鎖的操作了,如果有類似的資料插入時的場景通過該_version則可以實現一個樂觀鎖的操作);
除此之外,在插入資料時,如果不想做修改操作,那麼可以使用
```
使用create型別,表示只新增,資料存在時不做修改操作
PUT twitter/_doc/1?optype=create
或者
PUT twitter/_create/1
```
這兩個語法都表示使用型別為create的方式來建立文件,如果當前文件已經存在,則直接報錯,不會進行覆蓋更新;
optype的型別有兩個,index和create,我們預設使用 PUT twitter/_doc/1 建立資料時,其實就等價於 PUT twitter/_doc/1?optype=index
### 使用post新增文件
在上面,特意為我們的文件分配了一個ID。其實在實際的應用中,這個並不必要。相反,當我們分配一個ID時,在資料匯入的時候會檢查這個ID的文件是否存在,如果是已經存在,那麼就更新器版本。如果不存在,就建立一個新的文件。如果我們不指定文件的ID,轉而讓Elasticsearch自動幫我們生成一個ID,這樣的速度更快。在這種情況下,我們必須使用POST,而不是PUT
```
使用POST請求不指定ID時,es自動對應生成ID
POST twitter/_doc
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
```
### GET資料
```
獲取twitter索引文件為1的資料
GET twitter/_doc/1
獲取twitter索引文件為1的資料,並且只返回這個文件的 _source 部分
GET twitter/_doc/1/_source
只獲取source的部分欄位
GET twitter/_doc/1?_source=city,age,province
```
### _MGET資料
```
獲取多個文件的資料
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1
},
{
"_index": "twitter",
"_id": 2
}
]
}
獲取多個文件的資料,並且只返回部分欄位
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1,
"_source":["age", "city"]
},
{
"_index": "twitter",
"_id": 2,
"_source":["province", "address"]
}
]
}
直接獲取id為1和2的資料,(簡化後的寫法)
GET twitter/_doc/_mget
{
"ids": ["1", "2"]
}
```
### 修改文件(全量修改,指定欄位修改,先查詢再修改)
```
使用PUT的方式預設就會進行資料的更新新增,這個上述也都提到過,但是使用PUT的方式是全量更新,如果那些欄位不指定的話,將會更新為一個空值;
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "北京",
"province": "北京",
"country": "中國",
"location":{
"lat":"29.084661",
"lon":"111.335210"
}
}
所以可以使用POST的方式進行更新,只需要將待修改的欄位列出來即可;
POST twitter/_update/1
{
"doc": {
"city": "成都",
"province": "四川"
}
}
先查詢再更新_update_by_query
POST twitter/_update_by_query
{
"query": {
"match": {
"user": "GB"
}
},
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;ctx._source.country = params.country",
"lang": "painless",
"params": {
"city": "上海",
"province": "上海",
"country": "中國"
}
}
}
```
### 修改一個文件,如果當前文件不存在則新增該文件
```
doc_as_upsert引數檢查具有給定ID的文件是否已經存在,並將提供的doc與現有文件合併。 如果不存在具有給定ID的文件,則會插入具有給定文件內容的新文件。
下面的示例使用doc_as_upsert合併到ID為3的文件中,或者如果不存在則插入一個新文件:
POST /catalog/_update/3
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}
```
### 檢查文件是否存在
```
HEAD twitter/_doc/1
```
### 刪除一個文件
```
DELETE twitter/_doc/1
搜尋並刪除_delete_by_query
POST twitter/_delete_by_query
{
"query": {
"match": {
"city": "上海"
}
}
}
```
### _bulk批量操作
使用_bulk可以執行批量的資料插入,批量的資料更新,批量的資料刪除,
```
批量的資料插入,使用index型別,表示存在即更新,不存在則新增
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"雙榆樹-張三","message":"今兒天氣不錯啊,出去轉轉去","uid":2,"age":20,"city":"北京","province":"北京","country":"中國","address":"中國北京市海淀區","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"東城區-老劉","message":"出發,下一站雲南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中國","address":"中國北京市東城區臺基廠三條3號","location":{"lat":"39.904313","lon":"116.412754"}}
批量資料插入,使用 create型別,id不存在則插入,存在則拋異常不作任何操作
POST _bulk
{ "create" : { "_index" : "twitter", "_id": 1} }
{"user":"雙榆樹-張三","message":"今兒天氣不錯啊,出去轉轉去","uid":2,"age":20,"city":"北京","province":"北京","country":"中國","address":"中國北京市海淀區","location":{"lat":"39.970718","lon":"116.325747"}}
批量資料刪除 ,delete型別
POST _bulk
{ "delete" : { "_index" : "twitter", "_id": 1 }}
批量資料更新
POST _bulk
{ "update" : { "_index" : "twitter", "_id": 2 }}
{"doc": { "city": "長沙"}}
```
### 系統命令
檢視ES資訊
GET /
----------
關閉索引(關閉索引後,將阻止讀/寫操作)
POST twitter/_close
開啟索引
POST twitter/_open
--------
凍結索引(凍結索引後,該索引將阻止寫操作)
POST twitter/_freeze
索引凍結後,搜尋時需加上ignore_throttled=false引數來進行搜尋
POST twitter/_search?ignore_throttled=false
索引解凍
POST twitter/_unfreeze
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# ElasticSearch,Search操作
query進行全域性搜尋,aggregation可以進行全域性的資料統計和分析
## 搜尋所有文件
```
搜尋該cluster下的所有index,預設返回10個
GET /_search = GET /_all/_search
GET /_search?size=20
同時對多個index進行搜尋
POST /index1,index2,index3/_search
針對所有以index為開頭的索引來進行搜尋,但是排除index3索引
POST /index*,-index3/_search
只搜尋索引名為twitter的索引
GET twitter/_search
```
## 搜尋後設置只返回指定的欄位
```
使用_source表示只返回 user,和city欄位
GET twitter/_search
{
"_source": ["user", "city"],
"query": {
"match_all": {
}
}
}
設定_source 為false表示不返回任何的_source資訊
GET twitter/_search
{
"_source": false,
"query": {
"match": {
"user": "張三"
}
}
}
使用萬用字元的方式表示只返回 user*以及location*的資料,但是對於*.lat欄位則不進行返回
GET twitter/_search
{
"_source": {
"includes": [
"user*",
"location*"
],
"excludes": [
"*.lat"
]
},
"query": {
"match_all": {}
}
}
```
### 創造返回欄位script_fields
當我們的想要獲取的field可能在_source里根本沒有時,那麼我們可以使用script field來生成這些field;
```
GET twitter/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"years_to_100": {
"script": {
"lang": "painless",
"source": "100-doc['age'].value"
}
},
"year_of_birth":{
"script": "2019 - doc['age'].value"
}
}
}
返回結果是:
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"years_to_100" : [
80
],
"year_of_birth" : [
1999
]
}
},
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"fields" : {
"years_to_100" : [
70
],
"year_of_birth" : [
1989
]
}
},
...
]
必須注意的是這種使用script的方法來生成查詢的結果對於大量的文件來說,可能會佔用大量資源。
```
## match和term的區別解釋
term是代表完全匹配,也就是精確查詢,搜尋前不會再對所要搜尋的詞進行分詞拆解。
https://www.jianshu.com/p/d5583dff4157
而使用match進行搜尋的時候,會先將所要搜尋的詞進行分詞拆分,拆完後再來進行匹配;
## 建立一個索引資料結構mapping
```
後續的演示都是基於如下的結構進行的演示;
PUT twitter/_mapping
{
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"location": {
"type": "geo_point"
},
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"uid": {
"type": "long"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
```
## 查詢資料(Match query 搜尋詞分詞匹配)
```
搜尋 twitter索引中user欄位為“朝陽區-老賈”的詞;(注意,此處我們使用的是match,也就是會將我們的“朝陽區-老賈”按照預設分詞器 分詞後再進行相關搜尋匹配)
GET twitter/_search
{
"query": {
"match": {
"user": "朝陽區-老賈"
}
}
}
當我們使用上述的 match query 進行查詢的時候,預設的操作是OR的關係,比如上述的DSL語句實際上於以下語句是對等的:
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": "朝陽區-老賈",
"operator": "or"
}
}
}
}
預設的match query的操作就是or的關係:上述的dsl語句的查詢結果是任何的文件只要匹配:
“朝”,“陽”,“區”,“老”及“賈”這5個字中的任何一個字,則都將會被匹配到;
預設情況下我們指定搜尋的詞,如果不指定分詞器的話,也就是使用的預設分詞器,預設分詞器在進行中文分詞的時候,就只是會把對應的中文詞進行一個一個拆開進行分詞,所以我們上述由於是使用的match,檢索的“朝陽區-老賈”所以分詞後的結果就是“朝“陽”區”“老”賈”;所以只要是文件user中存在這幾個詞中的任何一個,則都會被檢索出來
```
### 設定最少匹配的詞的數量minimum_should_match
```
使用minimum_should_match來設定至少匹配的索引詞term,也就是說我們的搜尋結果中:
至少要匹配到:
“朝”,“陽”,“區”,“老”及“賈這5箇中的3個字才可以
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": "朝陽區-老賈",
"operator": "or",
"minimum_should_match": 3
}
}
}
}
```
### 更改為and關係的match query
```
預設情況下我們的match query是or的關係,這個上述已經說明過了,不過我們也可以動態的將其更改為and的關係,比如,如下的dsl語句:
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": "朝陽區-老賈",
"operator": "and"
}
}
}
}
更改為and關係後,也就是每個分詞後的結果都是and的關係,及我們的分詞結果
“朝”,“陽”,“區”,“老”“賈”這幾個詞之間都是and關係,也就是說,我們的搜尋結果中是必須要包含這幾個詞,才可以;
這種寫法,其實和直接使用 term 很相似,因為使用term的搜尋詞,則都不會進行分詞處理,預設是必須精確匹配,所以對於上述的這種使用場景,直接使用term效率會更高一些,省略了match的分詞這個步驟,並且結果也都是獲取精確匹配後的結果;
```
## Multi_query(匹配多個欄位)
在上述的搜尋中,我們都是特別的指明瞭個一個user欄位來進行的搜尋查詢,但是在實際使用中,我們可能並不知道那個欄位含有這個關鍵詞,所以對於這種情況下則可以使用multi_query來進行搜尋;
```
GET twitter/_search
{
"query": {
"multi_match": {
"query": "朝陽",
"fields": [
"user",
"address^3",
"message"
],
"type": "best_fields"
}
}
}
上述同時對三個fields: user,adress及message進行搜尋,
同時對address含有 “朝陽” 的文件的分數進行3倍的加權;
加權的作用是為了計算返回結果的相似度的值,比如此處對“address”進行了3倍的加權,那麼此時如果是address中包含“朝陽時”所對應的返回結果的相似度就相對最高,所對應的排名的順序就越靠前;
預設情況下如果不使用order by進行排序的話,則全部是按照相似度的高低來進行排序的;
```
## Prefix query(只匹配字首)
```
返回在提供的欄位中包含特定字首的文件。(是隻匹配字首,)
GET twitter/_search
{
"query": {
"prefix": {
"user": {
"value": "朝"
}
}
}
}
```
## Term query(精確匹配)
Term query會在給定欄位中進行精確的字詞匹配,搜尋前不會再對搜尋詞進行分詞拆解。
```
GET twitter/_search
{
"query": {
"term": {
"user.keyword": {
"value": "朝陽區-老賈"
}
}
}
}
Term query 是精確匹配一個字詞,如果是匹配多個字詞,則將會無效,如下所示:
查詢“朝陽區“空格”老賈“ 因為有空格的存在,所以預設情況下這是兩個詞了,所以對於搜尋的結果,
可能會是無效的(未驗證,待驗證具體效果是否真的如此)
GET twitter/_search
{
"query": {
"term": {
"user.keyword": {
"value": "朝陽區 老賈"
}
}
}
}
```
## Terms query(多個詞同時精確匹配)
所以,對於兩個詞的精確匹配,則應該是使用 terms
```
使用terms進行匹配,預設情況下是精確匹配對應的多個詞,並且是OR的關係;也就是說:只要匹配“朝陽區”或者“老賈”則都算是匹配完成;
所以,此處使用term解決了多精確匹配的問題,但是如果是對於要精確匹配到“朝陽區 老賈”這樣一個詞的場景的話,則使用Terms也是不合適的,此時則需要使用boot query進行must 的 term and term的判斷了;
所以其實這也就是一個對應的場景問題了,如果在錄入這個資料的時候是按照“朝陽區-老賈”而不是空格來錄入的話,那麼查詢起來則也就方便很多了,但其實不同的query查詢器,對應的應用場景則也是各有好處和優劣了;
GET twitter/_search
{
"query": {
"terms": {
"user.keyword": [
"朝陽區",
"老賈
]
}
}
}
city在我們的mapping中是一個multi-field項。它既是text也是keyword型別。對於一個keyword型別的項來說,這個項裡面的所有字元都被當做一個字串。它們在建立文件時,不需要進行index。keyword欄位用於精確搜尋,aggregation和排序(sorting),所以我們此處也是使用的term來進行的匹配;
```
## bool query(複合查詢)
符合查詢通過將上述的多個查詢方式組合起來,從而形成更大的複雜的查詢邏輯,
bool query的查詢格式一般情況下是:
------------
must: 必須匹配。貢獻算分 (多個term之間是 and 關係)
must_not:過濾子句,必須不能匹配,但不貢獻算分 (and 關係)
should: 選擇性匹配,至少滿足一條。貢獻算分 (多個term之間是or的關係)
filter: 過濾子句,必須匹配,但不貢獻算分(filter 確定是否包含在檢索結果中,後續再針對性說明)
```
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
```
表示查詢,user欄位既包含 朝陽區 又包含老賈的詞,然後進行返回
```
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"user": "朝陽區"
}
},
{
"match": {
"user": "老賈"
}
}
]
}
}
}
```
以下dsl的意思是,age必須是30歲,但是如果文件裡含有“Hanppy birthday”,相關性會更高,那麼搜尋得到的結果會排在前面;
```
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": "30"
}
}
],
"should": [
{
"match_phrase": {
"message": "Happy birthday"
}
}
]
}
}
}
```
如果是在不使用must,must_not以及filter的情況下,直接使用should進行匹配,則是表示 or 的關係;一個或者更多的should必須有一個匹配才會有搜尋結果;
## query range(範圍查詢)
```
查詢年齡介於30到40歲的文件資料
GET twitter/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
```
## 查詢欄位是否存在(query exists)
如果文件裡只要city這個欄位不為空,那麼就會被返回。反之,如果一個文件裡city這個欄位是空的,那麼就不會返回。
```
GET twitter/_search
{
"query": {
"exists": {
"field": "city"
}
}
}
```
## 匹配短語(query match_phrase)
query match_phrase 要求所有的分詞必須同時出現在文件中,同時位置必須緊鄰一致,
使用slop 1表示Happy和birthday之前是可以允許一個 詞 的差別。
```
GET twitter/_search
{
"query": {
"match_phrase": {
"message": {
"query": "Happy birthday",
"slop": 1
}
}
},
"highlight": {
"fields": {
"message": {}
}
}
}
```
## Profile API
Profile API是除錯工具。 它添加了有關執行的詳細資訊搜尋請求中的每個元件。 它為使用者提供有關搜尋的每個步驟的洞察力請求執行並可以幫助確定某些請求為何緩慢。
```
GET twitter/_search
{
"profile": "true",
"query": {
"match": {
"city": "北京"
}
}
}
```
在上面,我們加上了"profile":"true"後,除了顯示搜尋的結果之外,還顯示profile的資訊:
```
"profile" : {
"shards" : [
{
"id" : "[ZXGhn-90SISq1lePV3c1sA][twitter][0]",
"searches" : [
{
"query" : [
{
"type" : "BooleanQuery",
"description" : "city:北 city:京",
"time_in_nanos" : 1390064,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 5,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 31728,
"match" : 3337,
"next_doc_count" : 5,
"score_count" : 5,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 22347,
"advance_count" : 1,
"score" : 16639,
"build_scorer_count" : 2,
"create_weight" : 342219,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 973775
},
"children" : [
{
"type" : "TermQuery",
"description" : "city:北",
"time_in_nanos" : 107949,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 5,
"compute_max_score_count" : 3,
"compute_max_score" : 11465,
"advance" : 3477,
"advance_count" : 6,
"score" : 5793,
"build_scorer_count" : 3,
"create_weight" : 34781,
"shallow_advance" : 18176,
"create_weight_count" : 1,
"build_scorer" : 34236
}
},
{
"type" : "TermQuery",
"description" : "city:京",
"time_in_nanos" : 49929,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 5,
"compute_max_score_count" : 3,
"compute_max_score" : 5162,
"advance" : 15645,
"advance_count" : 6,
"score" : 3795,
"build_scorer_count" : 3,
"create_weight" : 13562,
"shallow_advance" : 1087,
"create_weight_count" : 1,
"build_scorer" : 10657
}
}
]
}
],
"rewrite_time" : 17930,
"collector" : [
{
"name" : "CancellableCollector",
"reason" : "search_cancelled",
"time_in_nanos" : 204082,
"children" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 23347
}
]
}
]
}
],
"aggregations" : [ ]
}
]
}
```
從上面我們可以看出來,這個搜尋是搜尋了“北”及“京”,而不是把北京作為一個整體來進行搜尋的。我們可以在以後的文件中可以學習使用中文分詞器來進行分詞搜尋。有興趣的同學可以把上面的搜尋修改為city.keyword來看看。
filter查詢和query查詢的不同:
https://blog.csdn.net/laoyang360/article/details/80468757
如何在搜尋的時候指定分詞器
如何指定分詞器進行欄位的使用,
如何調整java rest client api的執行緒數,還有全域性client api的異常處理的捕獲,超時時間等
es 的叢集負載方式,節點,副本等,以及節點掉線後的資料恢復等(主要是全部節點都掉線後,如何恢復資料?這個應該也不是重點)另外是,如何進行es叢集的遷移,比如把現有叢集的資料遷移到另外一個叢集中,比如升級等操作時,這些可以在elastic 官網上關於es的2.x的版本介紹中有相關的叢集等運維等的說明;
還有垃圾回收器等的說明,這個在文件中:《不要觸碰這些配置中都有詳細的說明》但這些也都的確是需要了解並熟悉的;
https://www.elastic.co/guide/cn/elasticsearch/guide/current/dont-touch-these-settings.html
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# ElasticSearch,分詞器analyzer
ElasticSearch3 分詞器 analyzer
analyzer分析器將輸入的字元流分解為token的過程,主要是發生在兩個場合:
1、在index建立索引的時候(也就是在向index中建立文件資料的時候)
2、在search的時候,也就是在搜尋時,分析需要搜尋的詞語;
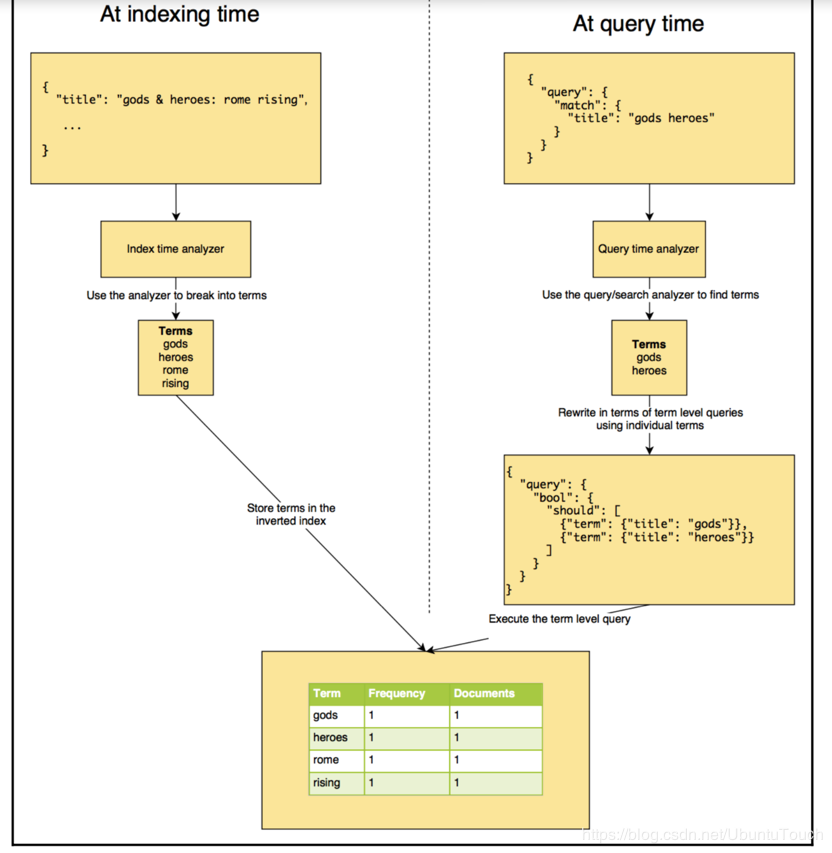
**analyzer 是es在文件儲存之前對文件正文內容執行的過程,以新增到反向索引中;在將文件新增到索引之前,es會為每個待分析的欄位執行對應的analyzer步驟;**
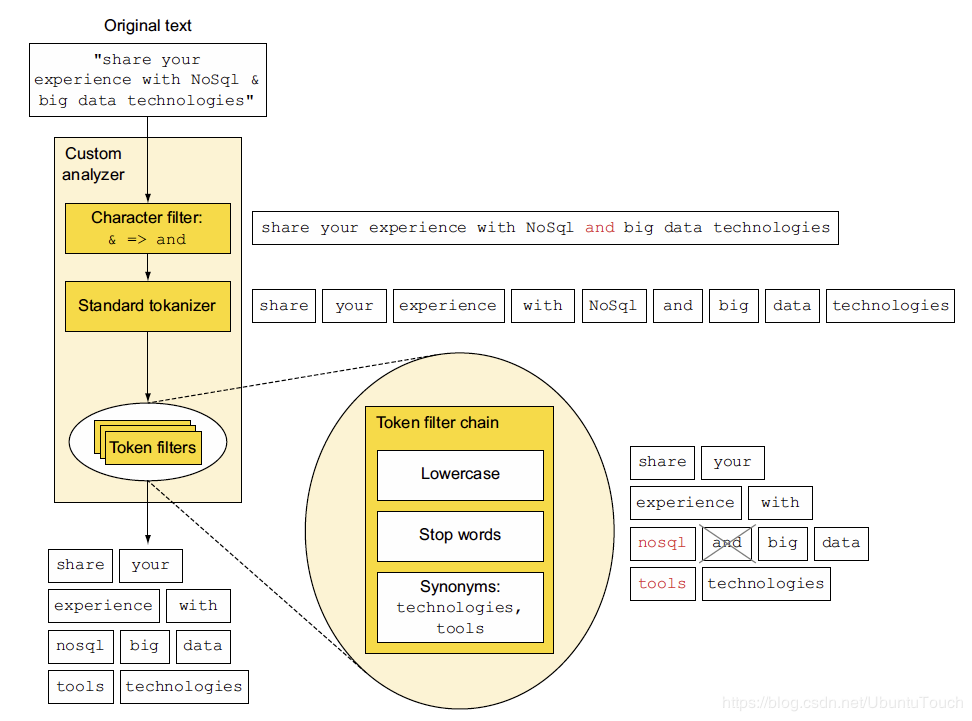
如:我們此時定製化一個新的analyzer,分別是由:character 過濾器,標準的tokenizer及token filter組成;
**下圖表達了一段原始文字,在經過analyzer分析時的整個過程;**
最後在經過了一系列分析後,將所對應的分析後的結果,則新增到對應的反向索引中,如圖1的步驟所示;
## analyzer分析器的組成
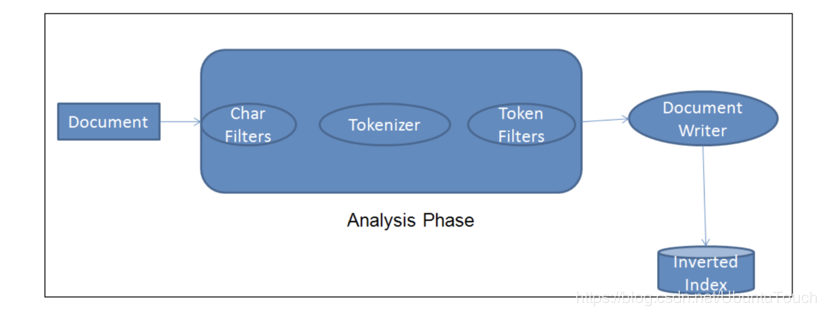
analyzer分析器,常見的分為三個部分組成:
1. Char Filter:字元過濾器的工作是執行清除任務,例如剝離HTML標記。
2. Tokenizer:下一步是將文字拆分為稱為標記的術語。 這是由tokenizer完成的。 可以基於任何規則(例如空格)來完成拆分
3. Token Filter:一旦建立了token,它們就會被傳遞給token filter,這些過濾器會對token進行規範化。 Token filter可以更改token,刪除術語或向token新增術語。
**很重要哦:Elasticsearch已經提供了比較豐富的analyzer分析器。我們可以自己建立自己的token analyzer,甚至可以利用已經有的char filter,tokenizer及token filter來重新組合成一個新的analyzer,並可以對文件中的每一個欄位分別定義自己的analyzer。**
在預設情況下,ES中所使用的分析器是standard analyzer分析器;
standard analyzer分析器所使用的特徵是:
1、沒有Char Filter
2、使用 standard tokonzer
3、把對應字串轉換為小寫,同時有選擇性的刪除一些stop words(停頓詞);預設情況下stop words 為 none,及不過濾任何的stop words(停頓詞)
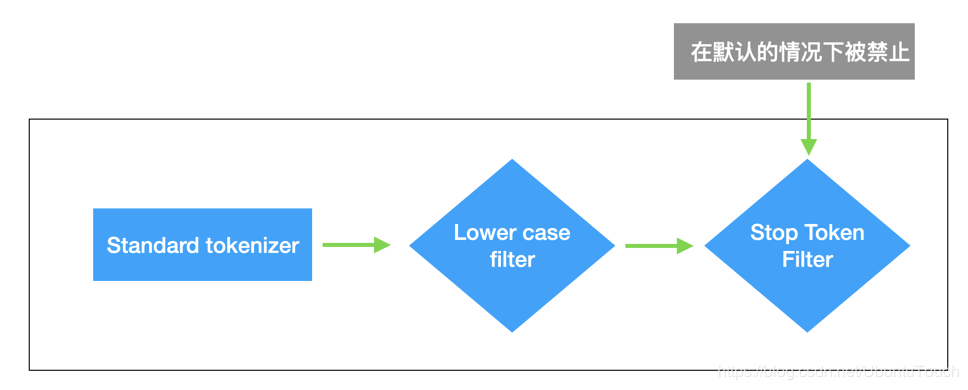
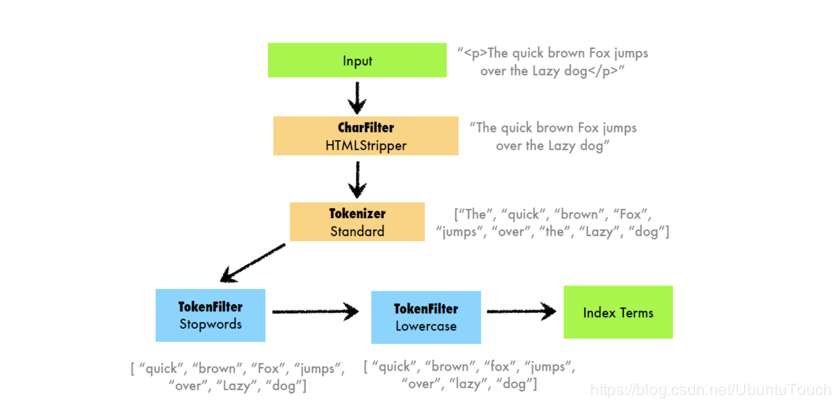
下面另外一張圖說明了,不同的analyzers分析器,對於token的拆分情況:

https://elasticstack.blog.csdn.net/article/details/100392478
https://blog.csdn.net/UbuntuTouch/article/details/100516428
https://blog.csdn.net/UbuntuTouch/article/details/1