
Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念
Elasticsearch有幾個核心的概念,花幾分鐘時間瞭解一下,有助於後面章節的學習。
NRT
Near Realtime,近實時,有兩個層面的含義,一是從寫入一條資料到這條資料可以被搜尋,有一段非常小的延遲(大約1秒左右),二是基於Elasticsearch的搜尋和分析操作,耗時可以達到秒級。
Cluster
叢集,對外提供索引和搜尋的服務,包含一個或多個節點,每個節點屬於哪個叢集是通過叢集名稱來決定的(預設名稱是elasticsearch),叢集名稱搞錯了後果很嚴重。命名建議是研發、測試環境、準生產、生產環境用不同的名稱增加區分度,例如研發使用es-dev,測試使用es-test,準生產使用es-stg,生產環境使用es-pro這樣的名字來區分。如果是中小型應用,叢集可以只有一個節點。
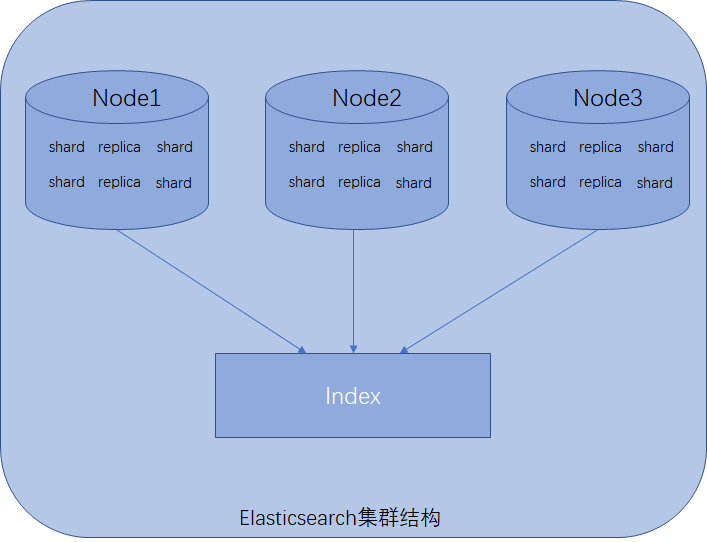
Node
單獨一個Elasticsearch伺服器例項稱為一個node,node是叢集的一部分,每個node有獨立的名稱,預設是啟動時獲取一個UUID作為名稱,也可以自行配置,node名稱特別重要,Elasticsearch叢集是通過node名稱進行管理和通訊的,一個node只能加入一個Elasticsearch叢集當中,叢集提供完整的資料儲存,索引和搜尋的功能,它下面的每個node分攤上述功能(每條資料都會索引到node上)。
shard
分片,是單個Lucene索引,由於單臺機器的儲存容量是有限的(如1TB),而Elasticsearch索引的資料可能特別大(PB級別,並且30GB/天的寫入量),單臺機器無法儲存全部資料,就需要將索引中的資料切分為多個shard,分佈在多臺伺服器上儲存。利用shard可以很好地進行橫向擴充套件,儲存更多資料,讓搜尋和分析等操作分佈到多臺伺服器上去執行,提升叢集整體的吞吐量和效能。
shard在使用時比較簡單,只需要在建立索引時指定shard的數量即可,剩下的都交給Elasticsearch來完成,只是建立索引時一旦指定shard數量,後期就不能再更改了。
replica
索引副本,完全拷貝shard的內容,shard與replica的關係可以是一對多,同一個shard可以有一個或多個replica,並且同一個shard下的replica資料完全一樣,replica作為shard的資料拷貝,承擔以下三個任務:
- shard故障或宕機時,其中一個replica可以升級成shard。
- replica保證資料不丟失(冗餘機制),保證高可用。
- replica可以分擔搜尋請求,提升整個叢集的吞吐量和效能。
shard的全稱叫primary shard,replica全稱叫replica shard,primary shard數量在建立索引時指定,後期不能修改,replica shard後期可以修改。預設每個索引的primary shard值為5,replica shard值為1,含義是5個primary shard,5個replica shard,共10個shard。
因此Elasticsearch最小的高可用配置是2臺伺服器。
Index
索引,具有相同結構的文件集合,類似於關係型資料庫的資料庫例項(6.0.0版本type廢棄後,索引的概念下降到等同於資料庫表的級別)。一個叢集裡可以定義多個索引,如客戶資訊索引、商品分類索引、商品索引、訂單索引、評論索引等等,分別定義自己的資料結構。
索引命名要求全部使用小寫,建立索引、搜尋、更新、刪除操作都需要用到索引名稱。
type
型別,原本是在索引(Index)內進行的邏輯細分,但後來發現企業研發為了增強可閱讀性和可維護性,制訂的規範約束,同一個索引下很少還會再使用type進行邏輯拆分(如同一個索引下既有訂單資料,又有評論資料),因而在6.0.0版本之後,此定義廢棄。
Document
文件,Elasticsearch最小的資料儲存單元,JSON資料格式,類似於關係型資料庫的表記錄(一行資料),結構定義多樣化,同一個索引下的document,結構儘可能相同。
工作原理
簡單地瞭解一下Elasticsearch的工作原理。
啟動過程
當Elasticsearch的node啟動時,預設使用廣播尋找叢集中的其他node,並與之建立連線,如果叢集已經存在,其中一個節點角色特殊一些,叫coordinate node(協調者,也叫master節點),負責管理叢集node的狀態,有新的node加入時,會更新叢集拓撲資訊。如果當前叢集不存在,那麼啟動的node就自己成為coordinate node。
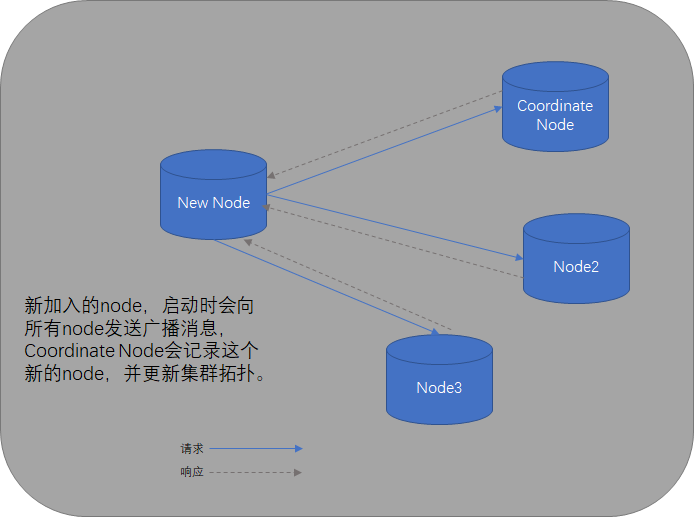
應用程式與叢集通訊過程
雖然Elasticsearch設定了Coordinate Node用來管理叢集,但這種設定對客戶端(應用程式)來說是透明的,客戶端可以請求任何一個它已知的node,如果該node是叢集當前的Coordinate,那麼它會將請求轉發到相應的Node上進行處理,如果該node不是Coordinate,那麼該node會先將請求轉交給Coordinate Node,再由Coordinate進行轉發,搓著各node返回的資料全部交由Coordinate Node進行彙總,最後返回給客戶端。
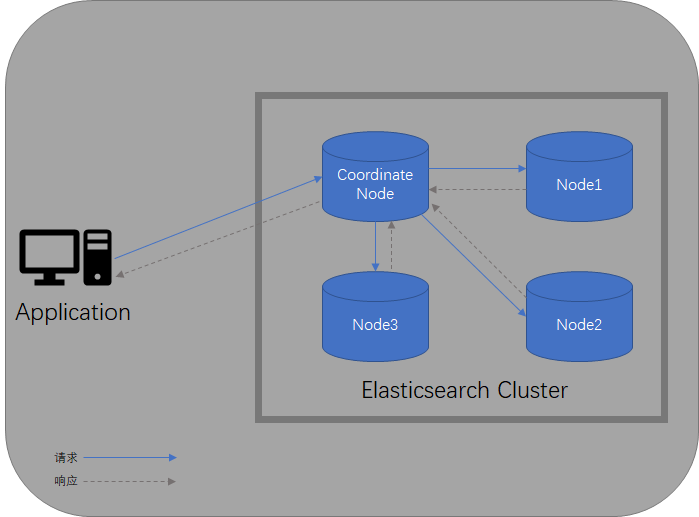
叢集內node有效性檢測
正常工作時,Coordinate Node會定期與拓撲結構中的Node進行通訊,檢測例項是否正常工作,如果在指定的時間週期內,Node無響應,那麼叢集會認為該Node已經宕機。叢集會重新進行均衡:
- 重新分配宕機的Node,其他Node中有該Node的replica shard,選出一個replica shard,升級成為primary shard。
- 重新安置新的shard。
- 拓撲更新,分發給該Node的請求重新對映到目前正常的Node上。
小結
本篇章簡單的向大家介紹了一下Elasticsearch的基本概念和工作原理,讓大家有個比較淺顯的認識,後續會結合實際的例子,來了解一下Elasticsearch基本的用法。
專注Java高併發、分散式架構,更多技術乾貨分享與心得,請關注公眾號:Java架構社群
