
對hadoop RPC的理解
因為公司hadoop叢集出現了一些瓶頸,在機器不增加的情況下需要進行優化,不管是儲存還是處理效能,更合理的利用現有叢集的資源,所以來學習了一波hadoop的rpc相關的知識和hdfs方面的知識,以及yarn相關的優化,學完之後確實明白了可以在哪些方面進行優化,可以對哪些引數進行調整,有點恍然大悟的感覺,本文的大部分的內容來於《Hadoop 2.x HDFS原始碼剖析》,自認為這本書寫的挺好,確實能學到很多東西,看了本篇部落格如果不懂,還是可以繼續學習這本書,講的很詳細,很清晰。本篇文章主要從RPC的原理、hdfs通訊協議和Hadoop RPC的實現這三部分進行闡述。
一、RPC原理
1.1、RPC框架
RPC(Pemote Procedure CallProtocol)是一種通過網路呼叫遠端計算機服務協議,RPC協議假定存在某些網路傳輸協議,如TCP,UDP,並通過這些傳輸協議為通訊程式之間傳遞訪問請求或者應答資訊。在OSI網路通訊模型中,RPC跨越了傳輸層和應用層。RPC 的主要功能目標是讓構建分散式計算(應用)更容易,在提供強大的遠端呼叫能力時不損失本地呼叫的語義簡潔性。為實現該目標,RPC 框架需提供一種透明呼叫機制讓使用者不必顯式的區分本地呼叫和遠端呼叫。
RPC通常採用客戶機/伺服器模型。請求程式是一個客戶機,而服務提供程式則是一個伺服器。客戶端首先會發送一個有引數的呼叫請求到服務端,等待服務端的響應訊息,在服務端,服務提供程式會保持睡眠狀態直到有呼叫請求到達為止,當接收到請求,服務端會對請求就行呼叫,計算結果,最後返回給客戶端。RPC的框架圖如下圖所示:
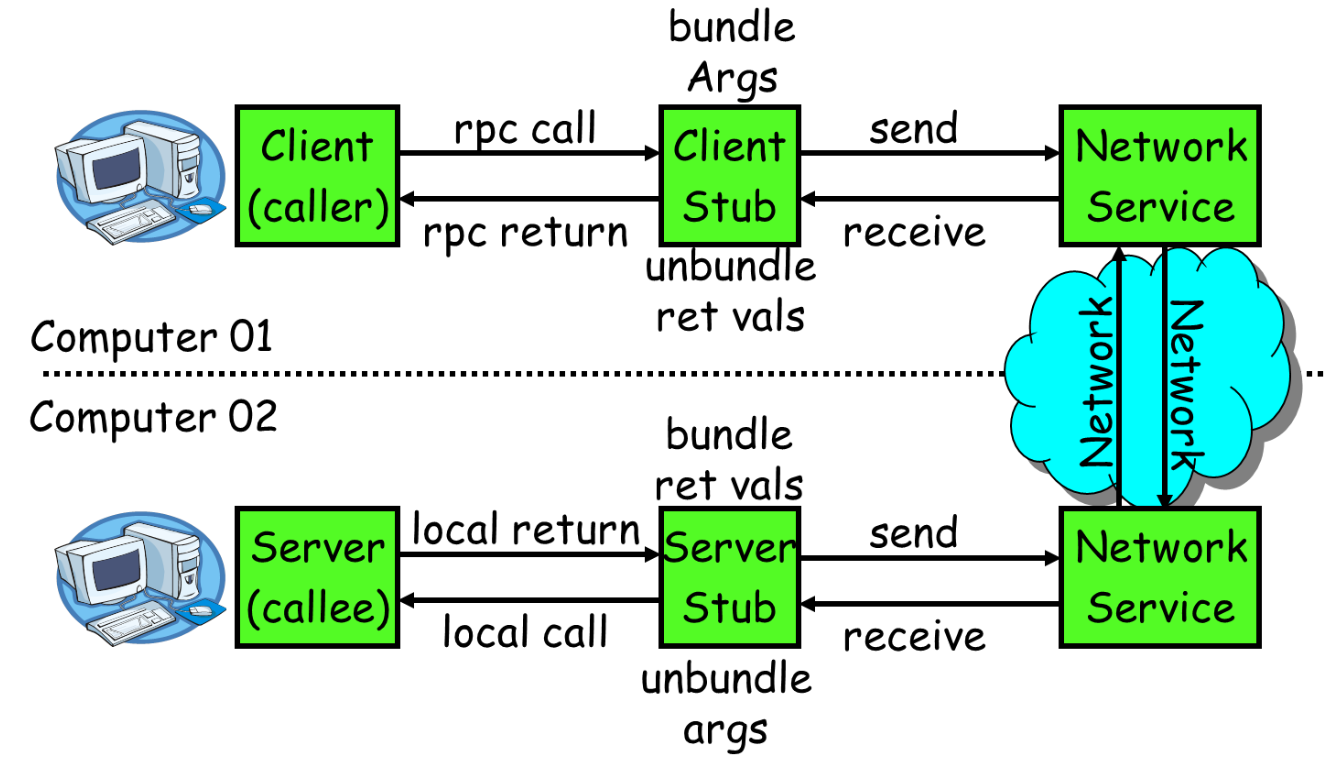
上圖所示,RPC主要包括如下幾個部分:
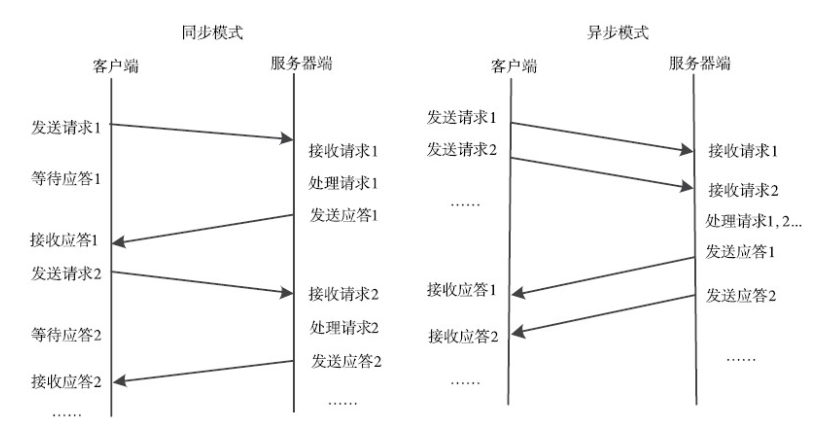
1、通訊模組:傳輸RPC請求和響應的網路通訊模組,可以基於TCP協議,也可以基於UDP協議,它們在客戶和伺服器之間傳遞請求和應答訊息,一般不會對資料包進行任何處理。請求–應答協議的實現方式有同步方式和非同步方式兩種,如下圖所示。
2、客戶端的stub程式:在客戶端stub程式表現為像本地程式一樣,但底層會將呼叫引數和請求序列化並通過通訊模組傳送給伺服器。之後stub會等待伺服器的響應資訊,並將響應資訊反序列化給請求程式。
3、服務端stub程式:stub程式會將客戶端傳送的呼叫請求和引數反序列化,根據呼叫資訊觸發對應的服務程式,然後將服務程式的響應資訊徐麗華併發回給客戶端。
5、服務程式:服務端會接收來自stub的呼叫請求,執行對應的邏輯並返回執行結果。
1.2、RPC特點
- 透明性:遠端呼叫其他機器上的程式,對使用者來說就像呼叫本地方法一樣。
- 高效能:RPC Server能夠併發處理多個來自Client的請求。
- 可控性:JDK中已經提供了一個RPC框架——RMI,但是該PRC框架過於重量級並且可控之處比較少,所以Hadoop RPC實現了自定義的RPC框架。
1.3、RPC請求基本步驟
- 客戶程式以本地方式呼叫系統產生的客戶端的Stub程式;
- 該Stub程式將函式呼叫資訊序列化並按照網路通訊模組的要求封裝成訊息包,並交給通訊模組傳送到遠端伺服器端。
- 遠端伺服器端接收此訊息後,將此訊息傳送給相應的服務端的Stub程式;
- Stub程式拆封訊息,並反序列化,形成被調過程要求的形式,並呼叫對應函式;
- 被呼叫函式按照所獲引數執行,並將結果返回給服務端的Stub程式;
- Stub程式將此結果封裝成訊息,通過網路通訊模組逐級地傳送給客戶程式。
二、HDFS的通訊協議
HDFS通訊協議抽象了HDFS各個節點之間的呼叫介面,主要分為hadoop RPC介面和流式介面
2.1、hadoop RPC介面
1、ClientProtoclo
該介面定義客戶端與namenode節點間的介面,用於客戶端對檔案系統的所有操作,讀寫都需要與該介面互動。
該介面定義了由客戶端發起,namenode響應的操作,主要包括hdfs檔案讀寫的相關操作,hdfs名稱空間,快照,快取相關的操作。
(客戶端與Namenode互動)一般性操作,客戶端會通過getBlockLocations()方法向Namenode獲取檔案的具體位置資訊(指的是儲存這個資料塊副本的所有datanode的資訊),還會使用reportBadBlocks()方式向Namenode彙報錯誤的資料塊。
(寫,追寫資料)首先會使用create()方法通過hdfs檔案系統目錄樹中建立一個新的空檔案,然後呼叫addBlock()方法獲取儲存檔案的資料塊的位置資訊,最後客戶端根據位置資訊與datanode建立資料流管道,寫入資料。追寫略有不同,首先通過append()方法獲取最後一個可寫資料塊的位置資訊並開啟一個已有的檔案(沒有寫滿的),然後建立好資料管道流,並向節點中追寫資料,當寫滿後,則會像create()方法一樣,客戶端會呼叫addBlock()方法獲取新的資料塊。當客戶端完成了整個檔案的寫入操作後,會呼叫complete()方法通知Namenode,這個操作會提交新寫入的HDFS檔案的所有資料塊,當資料塊滿則副本數時,則返回true,否則返回false;會重試。
如上是順利完成,如果在客戶端獲取到一個新申請的資料塊時,無法建立連線,會呼叫abandonBlock()方法放棄喝個資料塊,客戶端會再次通過addBlock()方法獲取新的資料塊。
在客戶端寫某個資料塊時,如果副本節點出了錯誤,客戶端會呼叫getAdditionalDatanode()方法向Namenode申請一個新的datanode來替代故障datanode。然後客戶端呼叫updateBlockForPipeline()方法向Namenode申請為這個資料塊分配新的時間戳,這樣故障節點的資料塊的時間戳就會過期,回本刪除,最後客戶端就可以使用新的時間戳建立新的資料管道流近些寫資料了。
如果在寫的過程中客戶端發生了故障,為了防止故障,對於任意的一個client開啟的檔案都需要client定期呼叫clientProtocol.renewLease()方法更新租約,如果Namenode長時間沒有收到client的租約更新資訊,就會認為client故障,觸發一次租約恢復操作,關閉檔案並且同步所有資料節點上這個檔案資料塊的狀態,確保hdfs系統中這個檔案正確且保持一致。
如果在寫資料的過程中Namenode發生故障呢,則需要HA發揮作用了。
2、ClientDatanodeProtocol
客戶端與datanode間的介面,主要使用者客戶端獲取datanode節點資訊是呼叫,真正的讀寫是通過流式介面進行的。其中主要定義兩部分,一部分是支援HDFS檔案讀寫的操作,例如呼叫getReplicaVisibleLength()獲取datanode節點某個資料塊的真實資料長度和getBlockLocalPathInfo()方法等,另一部分是支援DFSAdmin中與datanode節點管理相關的命令。
3、DatanodeProtocol
datanode與namenode間的通訊介面,包括namenode通過該介面中的方法返回向datanode下發指令。datanode則是通過該介面向namenode進行註冊,彙報塊資訊和快取資訊。DataNode使用這個介面與Namenode握手、註冊、傳送心跳、進行全量以及增量的資料塊彙報,NameNode會在Datanode的心跳響應中攜帶Namenode的指令。該介面主要的方法分為三種類型,Datanode的啟動相關,心跳相關,資料塊的讀寫相關。
(Datanode啟動相關)Datanode啟動會與NameNode進行4次互動,通過versionRequest()與NameNode進行握手操作,然後呼叫refisterDatanode()向NameNode註冊當前的datanode,接著呼叫blockReport()彙報datanode上儲存的所有資料塊資訊,最後呼叫cacheReport()彙報datanode快取的所有資料塊。
握手主要是返回namenode的一些名稱空間ID,叢集ID,hdfs的版本號等,datanode收到資訊後進行校驗對比,判斷是否能夠與該namenode協同工作,能否註冊。
塊彙報後會根據datanode上報資料塊儲存情況建立資料塊與datanode節點的對應關係。blockReport()在啟動的時候和指定時間間隔的情況下發生。cacheReport()和blockReport()方法完全一致。只不過是彙報當前datanode上的快取的所有資料塊。
(心跳相關)datanode會定期的向namenode傳送心跳(dfs.heartbeat.interval=3s),如果namenode很長時間沒有收到datanode的心跳資訊,則認為該datanode失效。每次心跳都會包含datanode節點上的儲存的狀態,快取狀態,正在寫檔案資料的連線數,讀寫資料使用的執行緒等。在開啟了HA的狀態下,datanode需要向兩個namenode同時傳送心跳資訊,不過只有active才會向datanode傳送指令。
(資料塊讀寫相關)datanode會向namenode彙報損壞的資料塊,以及定期性namenode彙報datanode新接手的資料塊或者刪除的資料塊。
4、InterDatanodeProtocol
datanode和datanode間的介面,主要用於資料塊的恢復操作,以及同步datanode節點上儲存資料塊副本的資訊。主要用於租約恢復操作。
客戶端開啟一個檔案進行操作時,首先要獲取這個檔案的租約,並且還需要定期更新這個租約,不然,namenode則會認為該client異常,namenode就會觸發租約恢復操作(同步資料管道中所有datanode上該檔案資料庫的狀態,並強制關閉這個檔案)。
租約恢復不是由namenode控制的負責的,而是namenode在資料管道中選擇出一個datanode的恢復主節點,然後下發恢復指令觸發這個資料節點控制租約恢復操作,也就是有這個恢復主節點協調整個租約恢復操作的的過程。租約恢復操作就是將資料管道中所有的datanode節點儲存同一的資料塊狀態(時間戳和資料塊長度)同步一致。
5、NamenodePortocol
主要用於namenode的ha機制,或者單節點的情況下是secondaryNamenode也namenode之間的通訊介面
2.2、流式介面
流式介面是HDFS中基於TCP或者HTTP實現的介面,在HDFS中,流式介面包括基於TCP的DataTransferProtocol介面,以及HA架構中Active Namenode和Standby Namenode之間的HTTP介面。
1、DataTransferProtocol
DataTransferProtocol是用來描述寫入或者讀出Datanode上資料的基於TCP的流式介面,HDFS客戶端與資料節點以及資料節點與資料節點之間的資料塊的傳輸就是基於DataTransferProtocol介面實現的。
2、Active Namenode和Standby Namenode間的HTTP介面
Namenode會定期將檔案系統的名稱空間儲存在一個fsimage檔案中,以及會將Namenode的名稱空間的修改操作先寫入到editlog檔案中,定期的合併fsimage和editlog檔案。這個合併操作由Secondary Namenode或者Standby Namenode去實現,合併完之後又要同步給Active Namenode,在Active Namenode和Standby Namenode之間的HTTP介面就是用來傳輸的fsimage檔案的。
二、Hadoop RPC的實現
Hadoop作為一個分散式的儲存系統,各個節點之間的通訊和互動是必不可少的,所以在hadoop有一套節點之間的通訊互動機制。RPC(Pemote Procedure CallProtocol,遠端過程呼叫協議)允許本地程式像呼叫本地方法一樣呼叫遠端機器上的應用程式提供服務,Hadop RPC機制是基於IPC實現的,主要用到了java的動態代理,java NIO以及protobuf等基礎技術(沒有基於java的RMI)。
Hadoop RPC框架主要由三個類組成:RPC、Client和Server類,RPC類用於對外提供一個使用Hadoop RPC框架的介面,Client類用於實現客戶端功能,Server類用於實現服務端功能。
3.1、RPC類的實現
客戶端呼叫程式可以通過RPC類提供的waitForProxy()和getProxy()方法獲取指定RPC協議的代理物件,然後RPC客戶端就可以呼叫代理物件的方法傳送RPC請求到伺服器了。
在服務端,服務端程式呼叫RPC內部的Builder.build()方法構造一個RPC.Server類,然後呼叫RPC.server.start()方法啟動Server物件監聽並響應RPC請求。
3.2、Client類的實現
HDFS Client會獲取一個ClientProtocolPB協議的代理物件,並在這個代理物件上呼叫RPC方法,代理物件會呼叫RPC.Client.call()方法將序列化之後的RPC請求傳送到伺服器。
Client傳送請求與接收響應的流程圖如下所示:Client類只有一個入口,即call()方法,代理類會呼叫Client.call()方法將RPC請求傳送到遠端伺服器,然後等待遠端伺服器的響應。
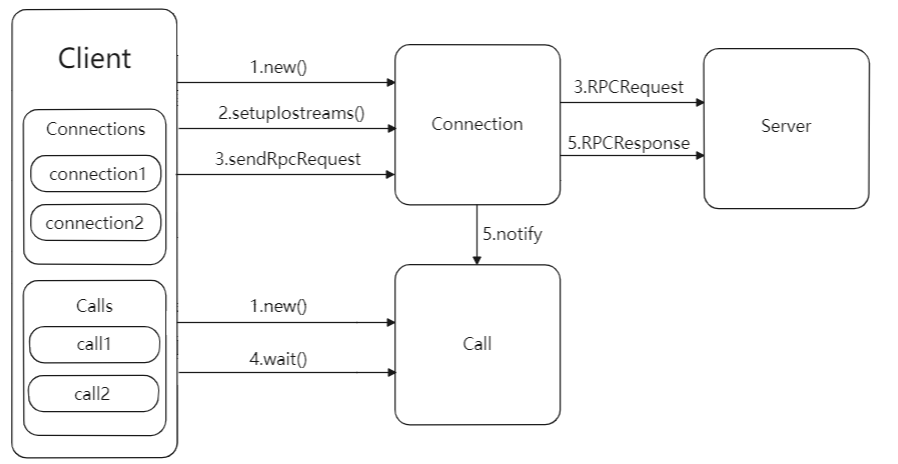
Client傳送請求與接收響應的流程圖如上所示:主要可以分為如下幾個步驟:
- Client.call()方法將RPC請求封裝成一個Call物件,其中儲存了RPC呼叫的完成標誌,返回值資訊以及異常資訊,然後call()方法會建立一個connection物件,用於管理client和server的socket連線。用ConnectionId作為key,將新建的Connection物件放入到Client.connections欄位值儲存,以callId作為key,將構造的Call物件放入Connection.calls欄位中儲存。
- Client.call()方法呼叫Connection.setupIOstreams()方法建立與server的socket連線,setupIOstreams()方法還會啟動connection執行緒,這些執行緒會監聽socket並讀取server發回的響應資訊。
- Client.call()方法呼叫Connection.sendRpcRequest()方法傳送RPC請求到Server。
- Client.call()方法呼叫Call.wait()在Call物件上等待,等待server返回響應資訊。
- Connection執行緒收到Server發回的響應資訊,根據響應中的資訊找到對應的call物件,然後設定Call物件的返回欄位,並呼叫call.notify()喚醒Client.call()方法的執行緒讀取Call物件的返回值。
RPC.Client中傳送請求和接收響應的是由兩個獨立的執行緒進行的,傳送請求執行緒就是呼叫Client.call()方法的執行緒,而接收響應執行緒則是call()啟動的connect執行緒。
內部類Connection是一個執行緒類,提供建立Client到Server的Socket連線,傳送RPC請求以及讀取RPC響應資訊等功能。Client與每個Server之間維護一個通訊連線,與該連線相關的基本資訊及操作被封裝到Connection類中,基本資訊主要包括通訊連線唯一標識(remoteId)、與Server端通訊的Socket(socket)、網路輸入資料流(in)、網路輸出資料流(out)、儲存RPC請求的雜湊表(calls)等。
Call類封裝了一個RPC請求,它包含5個成員變數,分別是唯一標識id、函式呼叫資訊param、函式執行返回值value、出錯或者異常資訊error和執行完成識別符號done。由於Hadoop RPC Server採用非同步方式處理客戶端請求,這使遠端過程呼叫的發生順序與結果返回順序無直接關係,而Client端正是通過id識別不同的函式呼叫的。當客戶端向伺服器端傳送請求時,只需填充id和param兩個變數,而剩下的3個變數(value、error和done)則由伺服器端根據函式執行情況填充。
3.3、Server類的實現
為了提高效能,Server類採用了很多技術提高併發能力,包括執行緒池,javaNIO提供的Reactor模式等。為了更好的理解Server類的設計,我們一步一步的推進:
3.3.1、Reactor模式
RPC服務端的處理流程和所有網路程式服務端處理的流程類似:1、讀取請求;2、反序列化請求;3、處理請求;4、序列化響應;5、發回響應。
Reactor模式是一種廣泛應用在伺服器端的設計模式,也是一種基於事件驅動的設計模式;Reactor的處理流程是:應用程式向一箇中間人註冊IO事件,當中間人監聽到這個IO時間發生後,會通知並喚醒應用程式處理這個事件,這裡所說的中間人其實是一個不斷等待和迴圈的執行緒,它接收所以的應用程式的註冊,並肩擦應用程式註冊的IO事件是否就緒,如果就緒了則通知應用程式進行處理。
一個簡單的基於Reactor模式的網路伺服器設計如下圖所示:主要包括reactor、acceptor以及hadndler等模組,其中reactor負責監聽所有的IO事件,當檢測到一個新的IO事件發生時,reactor就睡喚醒這個事件對應的模組處理。acceptor負責響應socket連線請求事件,會接收請求建立連線,之後構造handler物件,handler負責向reactor註冊IO讀事件,然後進行對應的業務邏輯處理,最後發回響應。
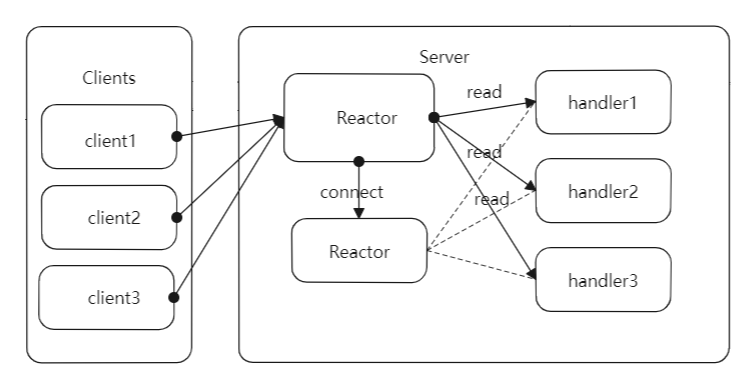
主要的步驟如下:
- 客戶端傳送socket連線請求到服務端,服務端的reactor物件監聽到了這個IO請求,由於acceptor物件在reactor物件上註冊了socket連線請求的iO事件,所以reactor會出發acceptor物件響應socket連線請求。
- acceptor物件會接收到來自客戶端的socket連線請求,併為這個連線建立一個handler物件,handler物件的構造方法在reactor物件上註冊IO讀事件。
- 客戶端建立連線後,會通過socket傳送RPC請求,RPC請求達到reactor後,會有reactor物件分發到對應的handler物件處理。
- handler物件會從網路上讀取RPC請求,然後反序列化請求並執行請求對應的邏輯,最後將響應資訊序列化並通過socket發回給客戶端。
由於上述的設計中服務端只有一個執行緒,所以就要求handler中讀取請求、執行請求以及傳送響應的流程必須能夠迅速處理完成,如果在一個環節中發生了阻塞,則整個伺服器邏輯全部阻塞。所以接下來看多執行緒的Reactor模式的網路伺服器結構。
3.3.2、多執行緒的Reactor模式
在基礎的Reactor模式的基礎上,把佔用時間比較長的讀取請求部分也業務邏輯處理部分進行分開,交給兩個獨立的執行緒池處理,分別為readers的執行緒池和handler的執行緒池。readers執行緒池中包含若干個執行讀取RPC請求任務的Reader執行緒。它們會在Reactor上註冊讀取RPC請求IO事件,然後從網路中讀取RPC請求,並將RPC請求封裝在一個Call物件中,最後將Call物件放入共享訊息佇列MQ中。而handers執行緒池包含很多個handler執行緒,它們會不斷的從共享訊息佇列MQ中取出RPC請求,然後執行業務邏輯並向客戶端傳送響應。這樣就保證了IO事件的監聽和分發,RPC請求的讀取和響應是在不同的執行緒中執行,大大提高了伺服器的併發效能。具體的架構圖如下:
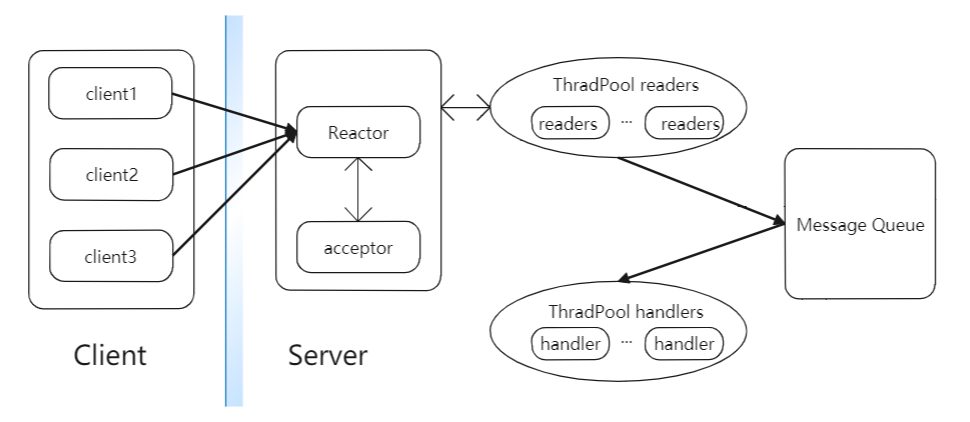
上圖就是多執行緒的Reactor模式版本,IO事件的監聽、RPC請求的讀取和處理就可以併發的進行了,但是像hadoop的Namenode這樣的物件,同一時間會存在很多個socket連線請求以及RPC請求的道道,這樣就會造成Reactor在處理和分發這些IO事件時出現阻塞,導致伺服器效能下降,在這個的基礎上可以拓展為多個reactor的模式。
3.3.3、多個Reactor多執行緒模式
多個Reactor多執行緒模式結構如下圖所示:
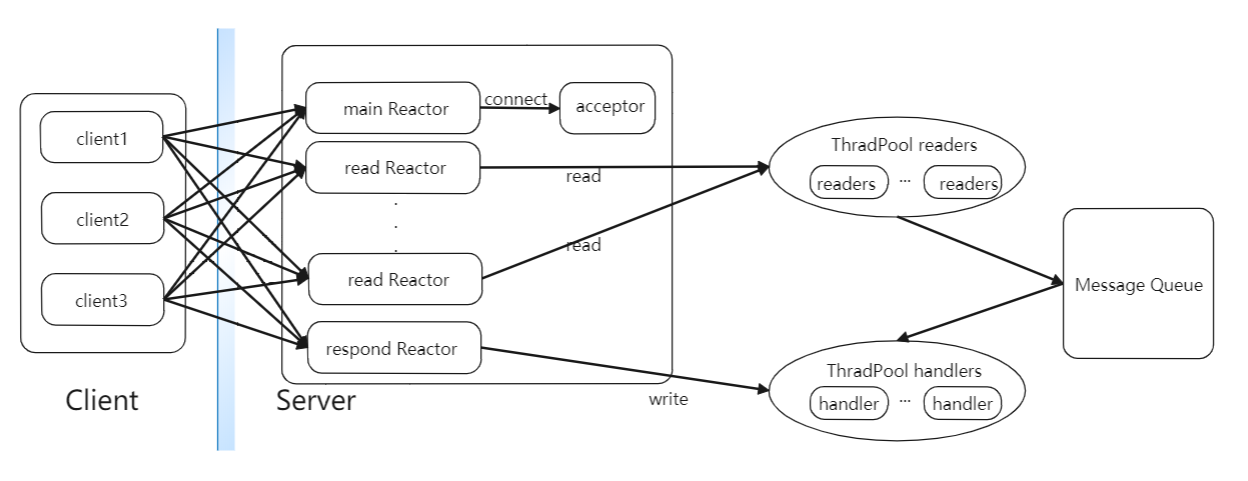
這裡mainReactor負責監聽socket連線事件,readReactor負責監聽IO讀事件,respondSelector負責監聽IO寫事件,這裡會構造多個readReactor降低系統的負載,不同的Reader執行緒會根據一定的邏輯到不同的readReactor上註冊IO讀事件。當acceptor建立了socket連線後,會從readers執行緒池中取出一個reader執行緒去出發RPC請求的流程。Reader執行緒會根據一定的邏輯選出一個readReactor物件並在這個物件上註冊讀取RPC請求的IO事件。之後就會由該readReactor在網路監聽是否有RPC請求到達,並出發Reader執行緒讀取,當handler成功處理一個RPC請求後,就會向respondSelector註冊寫RPC響應IO事件,當socket輸出流管道可以寫資料時,sender類就可以將響應傳送個客戶端了。
3.3.4、server類的設計
server類的設計結構如下所示,基本和多個reactor多執行緒版本的設計模式類似。
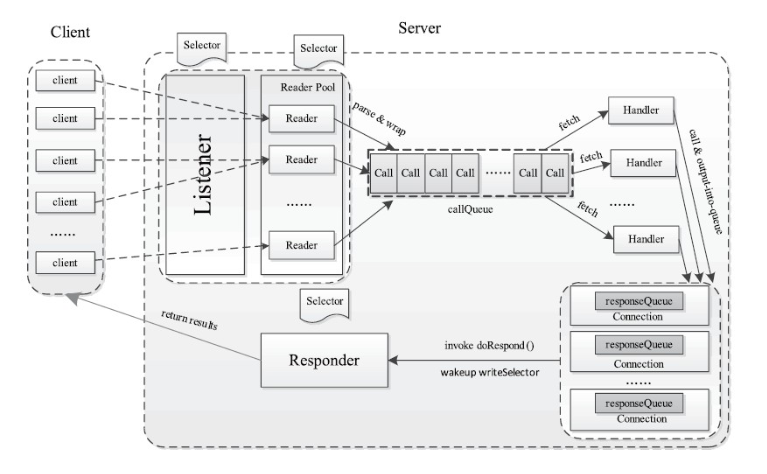
- Listener:類似於Reactor模式中的mainReactor,Listener物件中存在一個Selector物件acceptSelector,負責監聽來自客戶端的Socket請求,當acceptSelector監聽到連線請求後,Listener物件會初始化這個連線,之後採用輪詢的方式從readers執行緒池中選出一個reader執行緒處理RPC請求的讀取操作。
- Reader:與Reactor模式中的Reader執行緒相同,用於RPC讀取請求,Reader執行緒類中存在一個Selector物件readSelector,類似Reactor模式中的readReactor,這個物件用於監聽網路中是否可以讀取的RPC請求。當readSelector堅挺到有可讀的RPC請求後,會喚醒Reader執行緒讀取這個請求,並將請求封裝在一個Call物件中,然後將這個Call物件放入CallQueue佇列中。
- Handler:與Reactor模式中的Handler類似,用於處理RPC請求併發迴響應,Handler物件會從CallQueue中不停的取出RPC請求,然後執行RPC請求對應的本地函式進行處理,最後封裝響應發回給客戶端。
- Responder:用於向客戶端傳送RPC響應,會在Responder內部的respondSelector上註冊一個寫響應事件,這裡的respondSelector和Reactor中的respondSelector概念相同,當respondSelector堅挺到網路情況具備寫響應的條件時,會通知Responder將剩餘的響應發回給客戶端
server類處理RPC請求的處理流程:
- Listener執行緒的acceptSelector在ServerSocketChannel上註冊OP_ACCEPT事件,並且建立readers執行緒池,每個Reader的readSelector此時並不監控任何的Channel。
- Client傳送socket連線請求,出發Listener的acceptSelector喚醒Listener執行緒。
- Listener呼叫ServerSocketChannel.accept()建立一個新的SocketChannel
- Listener從readers執行緒池中挑選一個執行緒,並在Reader的readSelector上註冊OP_READ事件
- Client傳送RPC請求資料報,出發Reader的selector喚醒Reader執行緒
- Reader從socketChannel中讀取資料,封裝成Call物件,然後放入共享對壘CallQueue中
- handlers執行緒池的執行緒都在CallQueue上阻塞,當有Call物件被放入後,其中一個Handler執行緒被喚醒,然後根據Call物件的資訊滴哦用BlockingServer物件的callBlockingMethod()方法,然後Handler將響應寫入SocketChannel中。
- 如果handler發現無法將響應完全寫入到SocketChannel中,將在Responder的respondSelector上註冊一個OP_WRITE時間,當socket恢復正常,Responder將被喚醒繼續寫響應。
Server類的內部類介紹:
- Listener類:是一個執行緒類,整個Server中只會有一個Listener執行緒,用於監聽來自客戶端的Socket連線請求,對於每一個新到達的socket連線請求,Listener都會從readers執行緒池中選擇一個Reader執行緒處理,Listener中定義了一個Selector物件,負責監聽SelectionKey.OP_ACCEPT事件。
- Reader類:是一個執行緒類,每個Reader執行緒都會負責讀取若干個客戶端連線發來的RPC請求,而在Server類中會存在多個Reader執行緒構成一個readers執行緒池,readers執行緒池併發的讀取RPC請求,提高了Server處理RPC請求速度,Reader類定義了自己的readSelector欄位,用於箭筒SelectionKey.OP_READ事件。
- Connection類:維護Server和Client之間的Socket連線,Reader執行緒會呼叫readAndProcess()方法從IO流中讀取一個RPC請求
- Handler類:一個執行緒類,負責執行RPC請求對應的本地函式,然後將結果返回給客戶端。Handler執行緒類的主方法會迴圈從共享佇列CallQueue中取出待處理的Call物件,然後呼叫Server.call()方法執行RPC呼叫對應的本地函式。
- Responder類:一個執行緒類,一個Server中只有一個Responder物件,Responder內部包含一個Selector物件responseSelector,用於監聽SelectionKey.OP_WRITE事件。responseSelector會迴圈監控網路環境中是否具備傳送資料的條件,之後responseSelector會觸發Responder執行緒傳送未完成的響應結果到客戶端。
3.4、基於RPC的優化
知道了RPC的原理後,下面的優化自然而然就懂了。
- Handler執行緒數目。在Hadoop中,ResourceManager和NameNode分別是YARN和HDFS兩個子系統中的RPC Server,其對應的Handler數目分別由引數yarn.resourcemanager.resource-tracker.client.thread-count和dfs.namenode.service.handler.count指定,預設值分別為50和10,當叢集規模較大時,這兩個引數值會大大影響系統性能
- 客戶端最大重試次數。在分散式環境下,因網路故障或者其他原因迫使客戶端重試連線是很常見的,但嘗試次數過多可能不利於對實時性要求較高的應用。客戶端最大重試次數由引數ipc.client.connect.max.retries指定,預設值為10,也就是會連續嘗試10次(每兩次之間相隔1秒)
- 每個Handler執行緒對應的最大Call數目。由引數ipc.server.handler.queue.size指定,預設是100,也就是說,預設情況下,每個Handler執行緒對應的Call佇列長度為100。比如,如果Handler數目為10,則整個Call佇列(即共享佇列callQueue)最大長度為:100×10=1000
- ipc.server.listen.queue.size控制了服務端socket的監聽佇列長度,即backlog長度,預設值是128。而Linux的引數net.core.somaxconn預設值同樣為128。當服務端繁忙時,如NameNode,128是遠遠不夠的。這樣就需要增大backlog,例如3000臺叢集就將ipc.server.listen.queue.size設成了32768,為了使得整個引數達到預期效果,同樣需要將kernel引數net.core.somaxconn設成一個大於等於32768的值。
參考:《Hadoop 2.x HDFS原始碼剖析》《Hadoop技術內幕 :深入解析YARN架構與實現原理》
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://blog.csdn.net/lemon89/article/details/1735