
Spark架構與原理這一篇就夠了
一、基本介紹
是什麼?
快速,通用,可擴充套件的分散式計算引擎。
彈性分散式資料集RDD
RDD(Resilient Distributed Dataset)彈性分散式資料集,是Spark中最基本的資料(邏輯)抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。 RDD具有資料流模型的特點:自動容錯、位置感知性排程和可伸縮性。RDD允許使用者在執行多個查詢時顯式地將工作集快取在記憶體中,後續的查詢能夠重用工作集,這極大地提升了查詢速度。
基本概念

基本流程
二、Hadoop和Spark的區別
Spark 是類Hadoop MapReduce的通用並行框架, 專門用於大資料量下的迭代式計算.是為了跟 Hadoop 配合而開發出來的,不是為了取代 Hadoop, Spark 運算比 Hadoop 的 MapReduce 框架快的原因是因為 Hadoop 在一次 MapReduce 運算之後,會將資料的運算結果從記憶體寫入到磁碟中,第二次 Mapredue 運算時在從磁碟中讀取資料,所以其瓶頸在2次運算間的多餘 IO 消耗. Spark 則是將資料一直快取在記憶體中,直到計算得到最後的結果,再將結果寫入到磁碟,所以多次運算的情況下, Spark 是比較快的. 其優化了迭代式工作負載。
| Hadoop的侷限 | Spark的改進 |
|---|---|
| 抽象層次低,編碼難以上手。 | 通過使用RDD的統一抽象,實現資料處理邏輯的程式碼非常簡潔。 |
| 只提供Map和Reduce兩個操作,欠缺表達力。 | 通過RDD提供了許多轉換和動作,實現了很多基本操作,如sort、join等。 |
| 一個job只有map和reduce兩個階段,複雜的程式需要大量的job來完成。且job之間的依賴關係需要應用開發者自行管理。 | 一個job可以包含多個RDD的轉換操作,只需要在排程時生成多個stage。一個stage中也可以包含多個map操作,只需要map操作所使用的RDD分割槽保持不變。 |
| 處理邏輯隱藏在程式碼細節中,缺少整體邏輯檢視。 | RDD的轉換支援流式API,提供處理邏輯的整體檢視。 |
| 對迭代式資料的處理效能比較差,reduce與下一步map的中間結果只能存放在HDFS的檔案系統中。 | 通過記憶體快取資料,可大大提高迭代式計算的效能,記憶體不足時可溢寫到磁碟上。 |
| reduce task需要等所有的map task全部執行完畢才能開始執行。 | 分割槽相同的轉換可以在一個task中以流水線的形式執行。只有分割槽不同的轉換需要shuffle操作。 |
| 時延高,只適合批資料處理,對互動式資料處理和實時資料處理支援不夠。 | 將流拆成小的batch,提供discretized stream處理流資料 |
三、RDD操作
兩種型別: transformation和action
Transformation
主要做的是就是將一個已有的RDD生成另外一個RDD。Transformation具有lazy特性(延遲載入)。
Transformation運算元的程式碼不會真正被執行。只有當我們的程式裡面遇到一個action運算元的時候,程式碼才會真正的被執行。這種設計讓Spark更加有效率地執行。
常用的Transformation:
| 動作 | 說明 | 示例 |
|---|---|---|
| map(func) | 返回一個新的RDD,該RDD由每一個輸入元素經過func函式轉換後組成 (每一個輸入元素只能被對映為一個) | var rdd = sc.parallelize(List(“hello world”, “hello spark”, “hello hdfs”)) var rdd2 = rdd.map(x => x + “_1”) rdd2.foreach(println) |
| filter(func) | 返回一個新的RDD,該RDD由經過func函式計算後返回值為true的輸入元素組成 | var rdd3 = rdd2.filter(x => x.contains(“world”)) rdd3.foreach(println) |
| flatMap(func) | 類似於map,但是每一個輸入元素可以被對映為0或多個輸出元素(所以func應該返回一個序列,而不是單一元素) | var rdd4 = rdd2.flatMap(x => x.split(" ")) rdd4.foreach(println) |
| sample(withReplacement, fraction, seed) | 根據fraction指定的比例對資料進行取樣,可以選擇是否使用隨機數進行替換,seed用於指定隨機數生成器種子 | |
| groupByKey([numTasks]) | 在一個(K,V)的RDD上呼叫,返回一個(K, Iterator[V])的RDD | var rdd5 = rdd4.map(x => (x, 1)) var rdd6 = rdd5.groupByKey() rdd6.foreach(println) |
| sample(withReplacement, fraction, seed) | 根據fraction指定的比例對資料進行取樣,可以選擇是否使用隨機數進行替換,seed用於指定隨機數生成器種子 | var rdd = sc.parallelize(1 to 10)rdd.sample(false,0.4).collect() rdd.sample(false,0.4, 9).collect() |
| combineByKey | 合併相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) | jake 80.0 jake 90.0 jake 85.0 mike 86.0 mike 90 求分數的平均值 |
單Value型別運算元補充:
1. mapPartitions: 將待處理的資料以分割槽為單位傳送到計算節點進行處理;
2. mapPartintions: 將待處理的資料以分割槽為單位傳送到計算節點進行處理 ;
3. glom: 將同一個分割槽的資料直接轉換為相同型別的記憶體陣列進行處理,分割槽不變 ;
4. groupBy: 將資料根據指定的規則進行分組, 分割槽預設不變,但是資料會被打亂重新組合 ;
5. distinct: 將資料集中重複的資料去重 ;
6. coalesce: 根據資料量縮減分割槽,用於大資料集過濾後,提高小資料集的執行效率
當 spark 程式中,存在過多的小任務的時候,可以通過 coalesce 方法,收縮合並分割槽,減少
分割槽的個數,減小任務排程成本 ;
7. repartition: 該操作內部其實執行的是 coalesce 操作,引數 shuffle 的預設值為 true。
8. sortBy: 該操作用於排序資料。在排序之前,可以將資料通過 f 函式進行處理,之後按照 f 函式處理
的結果進行排序,預設為升序排列
雙Value型別運算元補充:
1. intersection: 對源 RDD 和引數 RDD 求交集後返回一個新的 RDD
2. union: 對源 RDD 和引數 RDD 求並集後返回一個新的 RDD
3. subtract: 以一個 RDD 元素為主, 去除兩個 RDD 中重複元素,將其他元素保留下來
Action
觸發程式碼的執行,我們一段spark程式碼裡面至少需要有一個action操作。
常用的Action:
| 動作 | 含義 | 示例 |
|---|---|---|
| reduce(func) | 通過func函式聚集RDD中的所有元素,可以實現,RDD中元素的累加,計數和其他型別的聚集操作 | var rdd = sc.parallelize(1 to 10) rdd.reduce((x, y) => x+y) |
| reduceByKey(func) | 按key進行reduce,讓key合併 | wordcount示例: var rdd = sc.parallelize(List(“hello world”, “hello spark”, “hello hdfs”)) rdd.flatMap(x => x.split(" ")).map(x => (x,1)).reduceByKey((x,y) => x+y).collect() |
| collect() | 在驅動程式中,以陣列的形式返回資料集的所有元素 | |
| count() | 返回RDD的元素個數 | |
| first() | 返回RDD的第一個元素(類似於take(1)) | |
| take(n) | 返回一個由資料集的前n個元素組成的陣列 | |
| saveAsTextFile(path) | 將資料集的元素以textfile的形式儲存到HDFS檔案系統或者其他支援的檔案系統,對於每個元素,Spark將會呼叫toString方法,將它裝換為檔案中的文字 | rdd.saveAsTextFile("/user/jd_ad/ads_platform/outergd/0124/demo2.csv") |
| foreach(func) | 在資料集的每一個元素上,執行函式func進行更新。 | |
| takeSample | 抽樣返回一個dateset中的num個元素 | var rdd = sc.parallelize(1 to 10) rdd.takeSample(false,10) |
四、Block與RDD生成過程
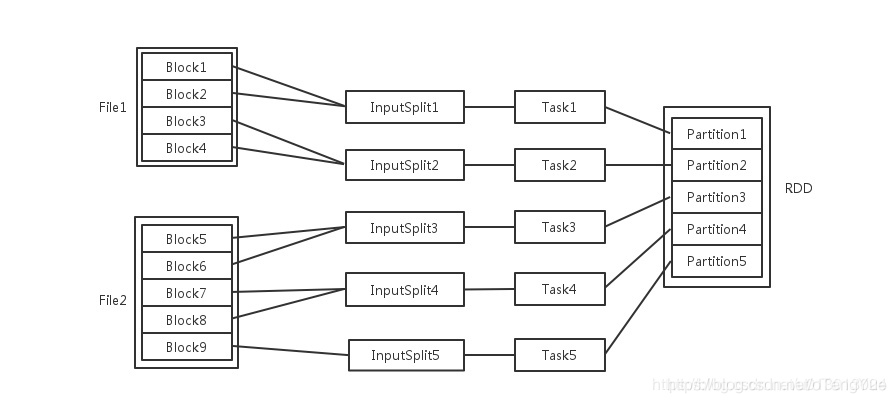
輸入可能以多個檔案的形式儲存在HDFS上,每個File都包含了很多塊,稱為Block。
當Spark讀取這些檔案作為輸入時,會根據具體資料格式對應的InputFormat進行解析,一般是將若干個Block合併成一個輸入分片,稱為InputSplit,注意InputSplit不能跨越檔案。
隨後將為這些輸入分片生成具體的Task。InputSplit與Task是一一對應的關係。
隨後這些具體的Task每個都會被分配到叢集上的某個節點的某個Executor去執行。
- 每個節點可以起一個或多個Executor。
- 每個Executor由若干core組成,每個Executor的每個core一次只能執行一個Task。
- 每個Task執行的結果就是生成了目標RDD的一個partiton。
注意: 這裡的core是虛擬的core而不是機器的物理CPU核,可以理解為就是Executor的一個工作執行緒。
而 Task被執行的併發度 = Executor數目 * 每個Executor核數。
至於partition的數目:
- 對於資料讀入階段,例如sc.textFile,輸入檔案被劃分為多少InputSplit就會需要多少初始Task。
- 在Map階段partition數目保持不變。
- 在Reduce階段,RDD的聚合會觸發shuffle操作,聚合後的RDD的partition數目跟具體操作有關,例如repartition操作會聚合成指定分割槽數,還有一些運算元是可配置的。
五、依賴關係與Stage劃分
RDD之間有一系列的依賴關係,依賴關係又分為窄依賴和寬依賴。簡單的區分發,可以看一下父RDD中的資料是否進入不同的子RDD,如果只進入到一個子RDD則是窄依賴,否則就是寬依賴。如下圖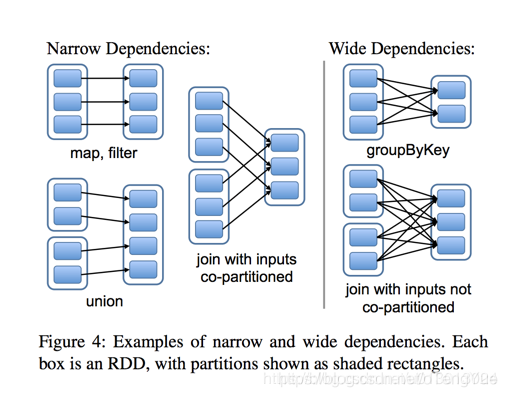
窄依賴( narrow dependencies )
- 子RDD 的每個分割槽依賴於常數個父分割槽(即與資料規模無關)
- 輸入輸出一對一的運算元,且結果RDD 的分割槽結構不變,主要是map 、flatMap
- 輸入輸出一對一,但結果RDD 的分割槽結構發生了變化,如union 、coalesce
- 從輸入中選擇部分元素的運算元,如filter 、distinct 、subtract 、sample
寬依賴( wide dependencies )
- 子RDD 的每個分割槽依賴於所有父RDD 分割槽
- 對單個RDD 基於key 進行重組和reduce ,如groupByKey 、reduceByKey ;
- 對兩個RDD 基於key 進行join 和重組,如join
Spark任務會根據RDD之間的依賴關係,形成一個DAG有向無環圖,DAG會提交給DAGScheduler,DAGScheduler會把DAG劃分相互依賴的多個stage,劃分stage的依據就是RDD之間的寬窄依賴。遇到寬依賴就劃分stage,每個stage包含一個或多個task任務。然後將這些task以taskSet的形式提交給TaskScheduler執行。 stage是由一組並行的task組成。切割規則:從後往前,遇到寬依賴就切割stage,遇到窄依賴就將這個RDD加入該stage中。 如下圖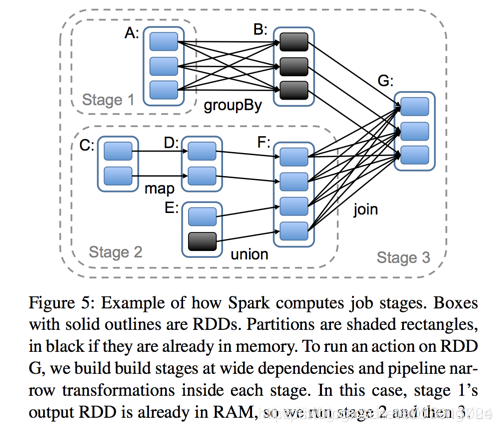
六、Spark流程
排程流程(粗粒度圖解)
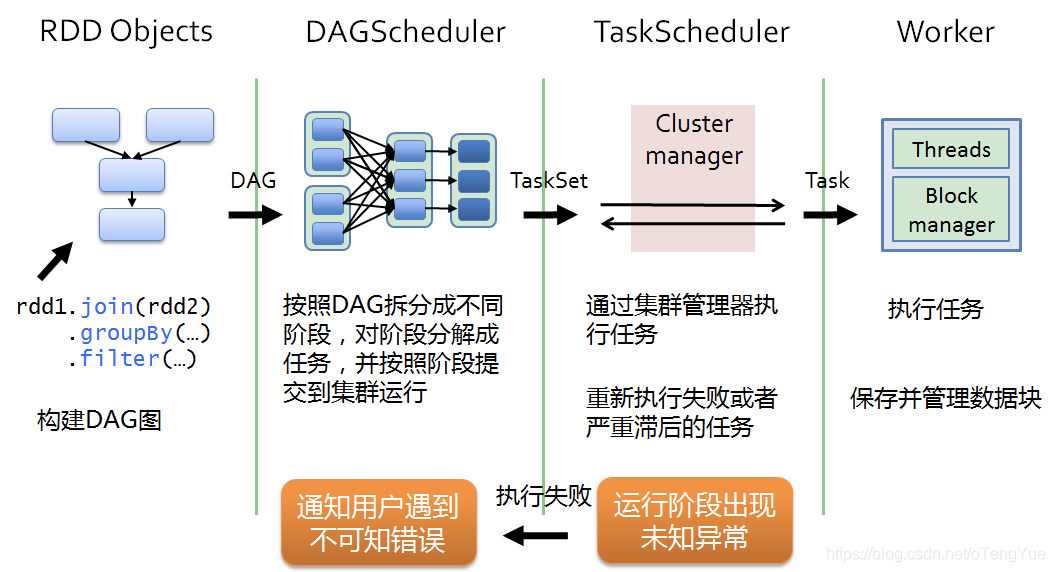
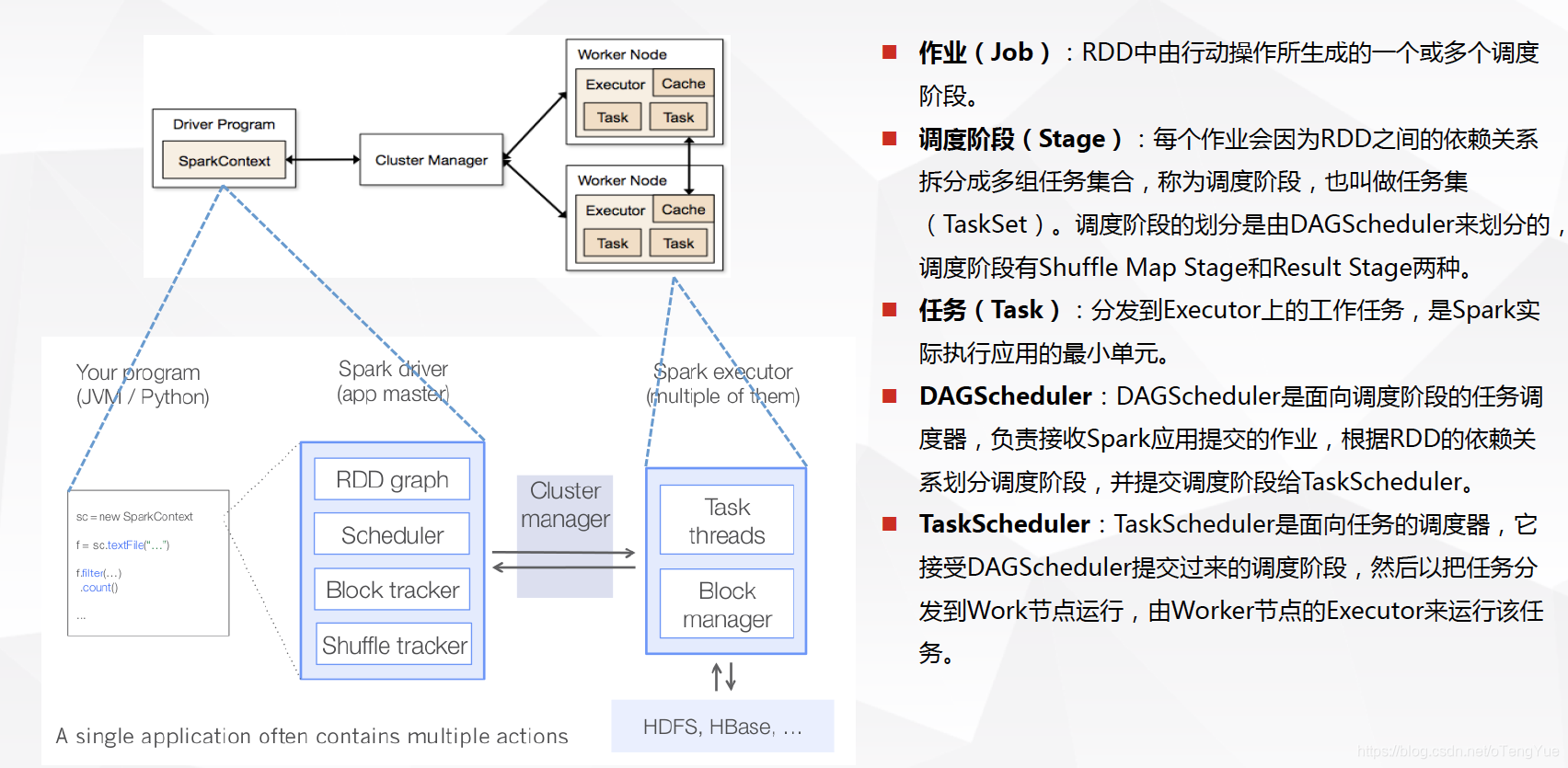
- 1、DriverProgram即使用者提交的程式定義並建立了SparkContext的例項,SparkContext會根據RDD物件構建DAG圖,然後將作業(job)提交(runJob)給DAGScheduler。
- 2、DAGScheduler對作業的DAG圖進行切分成不同的stage[stage是根據shuffle為單位進行劃分],每個stage都是任務的集合(taskset)並以taskset為單位提交(submitTasks)給TaskScheduler。
- 3、TaskScheduler通過TaskSetManager管理任務(task)並通過叢集中的資源管理器(Cluster Manager)[standalone模式下是Master,yarn模式下是ResourceManager]把任務(task)發給叢集中的Worker的Executor, 期間如果某個任務(task)失敗, TaskScheduler會重試,TaskScheduler發現某個任務(task)一直未執行完成,有可能在不同機器啟動一個推測執行任務(與原任務一樣),哪個任務(task)先執行完就用哪個任務(task)的結果。無論任務(task)執行成功或者失敗,TaskScheduler都會向DAGScheduler彙報當前狀態,如果某個stage執行失敗,TaskScheduler會通知DAGScheduler可能會重新提交任務。
- 4、Worker接收到的是任務(task),執行任務(task)的是程序中的執行緒,一個程序中可以有多個執行緒工作進而可以處理多個數據分片,執行任務(task)、讀取或儲存資料。
執行流程(細粒度圖解)
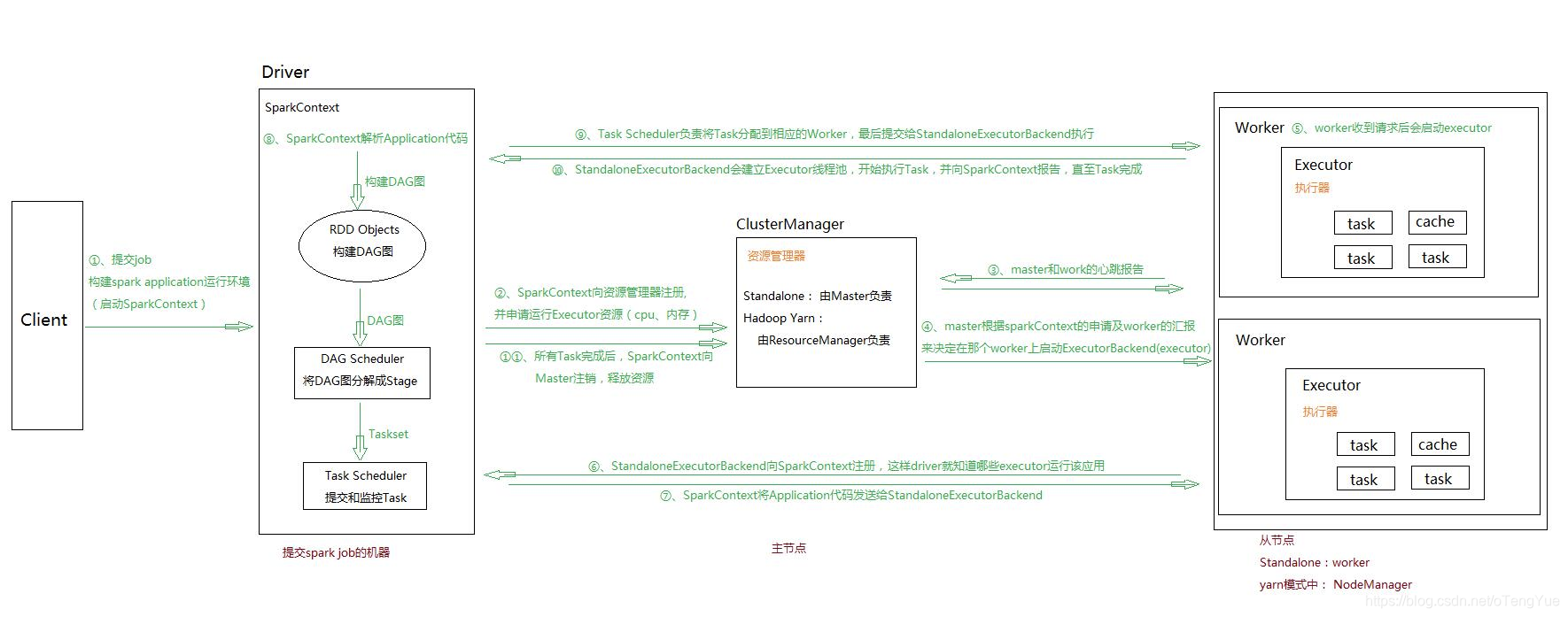
- 1、通過SparkSubmit提交job後,Client就開始構建 spark context,即 application 的執行環境(使用本地的Client類的main函式來建立spark context並初始化它)
- 2、yarn client提交任務,Driver在客戶端本地執行;yarn cluster提交任務的時候,Driver是執行在叢集上
- 3、SparkContext連線到ClusterManager(Master),向資源管理器註冊並申請執行Executor的資源(核心和記憶體)
- 4、Master根據SparkContext提出的申請,根據worker的心跳報告,來決定到底在那個worker上啟動executor
- 5、Worker節點收到請求後會啟動executor
- 6、executor向SparkContext註冊,這樣driver就知道哪些executor執行該應用
- 7、SparkContext將Application程式碼傳送給executor(如果是standalone模式就是StandaloneExecutorBackend)
- 8、同時SparkContext解析Application程式碼,構建DAG圖,提交給DAGScheduler進行分解成stage,stage被髮送到TaskScheduler。
- 9、TaskScheduler負責將Task分配到相應的worker上,最後提交給executor執行
- 10、executor會建立Executor執行緒池,開始執行Task,並向SparkContext彙報,直到所有的task執行完成
- 11、所有Task完成後,SparkContext向Master登出
七、spark在yarn上的兩種執行模式(yarn-client和yarn-cluster)
1、Yarn-Client
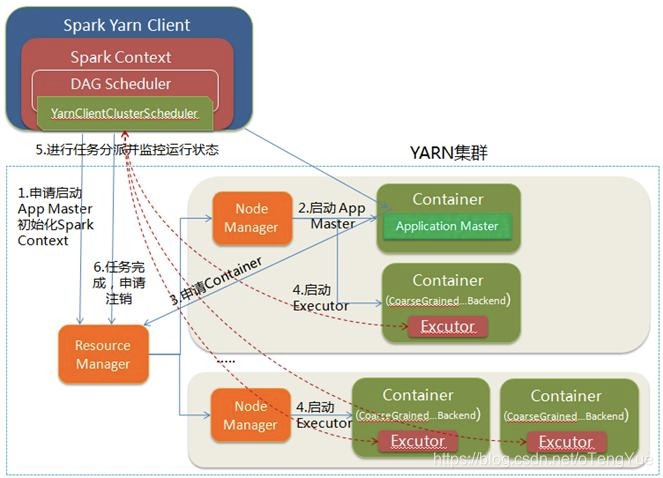
- 1.Spark Yarn Client向YARN的ResourceManager申請啟動Application Master。同時在SparkContent初始化中將建立DAGScheduler和TASKScheduler等,由於我們選擇的是Yarn-Client模式,程式會選擇YarnClientClusterScheduler和YarnClientSchedulerBackend;
- 2.ResourceManager收到請求後,在叢集中選擇一個NodeManager,為該應用程式分配第一個Container,要求它在這個Container中啟動應用程式的ApplicationMaster,與YARN-Cluster區別的是在該ApplicationMaster不執行SparkContext,只與SparkContext進行聯絡進行資源的分派;
- 3.Client中的SparkContext初始化完畢後,與ApplicationMaster建立通訊,向ResourceManager註冊,根據任務資訊向ResourceManager申請資源(Container);
- 4.一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通訊,要求它在獲得的Container中啟動啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向Client中的SparkContext註冊並申請Task;
- 5.Client中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend執行Task並向Driver彙報執行的狀態和進度,以讓Client隨時掌握各個任務的執行狀態,從而可以在任務失敗時重新啟動任務;
- 6.應用程式執行完成後,Client的SparkContext向ResourceManager申請登出並關閉自己。
2、Yarn-Cluster(企業中主要使用)
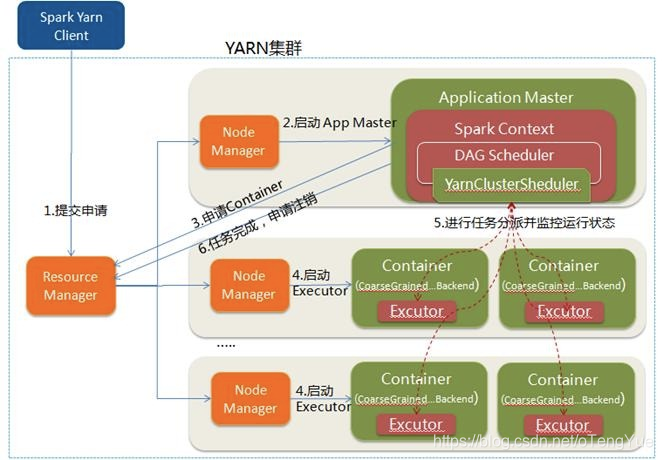
- 1.Spark Yarn Client向YARN中提交應用程式,包括ApplicationMaster程式、啟動ApplicationMaster的命令、需要在Executor中執行的程式等;
- 2.ResourceManager收到請求後,在叢集中選擇一個NodeManager,為該應用程式分配第一個Container,要求它在這個Container中啟動應用程式的ApplicationMaster,其中ApplicationMaster進行SparkContext等的初始化;
- 3.ApplicationMaster向ResourceManager註冊,這樣使用者可以直接通過ResourceManage檢視應用程式的執行狀態,然後它將採用輪詢的方式通過RPC協議為各個任務申請資源,並監控它們的執行狀態直到執行結束;
- 4.一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通訊,要求它在獲得的Container中啟動啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向ApplicationMaster中的SparkContext註冊並申請Task。這一點和Standalone模式一樣,只不過SparkContext在Spark Application中初始化時,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler進行任務的排程,其中YarnClusterScheduler只是對TaskSchedulerImpl的一個簡單包裝,增加了對Executor的等待邏輯等;
- 5.ApplicationMaster中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend執行Task並向ApplicationMaster彙報執行的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的執行狀態,從而可以在任務失敗時重新啟動任務;
- 6.應用程式執行完成後,ApplicationMaster向ResourceManager申請登出並關閉自己。
3、兩種模式區別
理解YARN-Client和YARN-Cluster深層次的區別之前先清楚一個概念:Application Master。在YARN中,每個Application例項都有一個ApplicationMaster程序,它是Application啟動的第一個容器。它負責和ResourceManager打交道並請求資源,獲取資源之後告訴NodeManager為其啟動Container。從深層次的含義講YARN-Cluster和YARN-Client模式的區別其實就是ApplicationMaster程序的區別
YARN-Cluster模式下,Driver執行在AM(Application Master)中,它負責向YARN申請資源,並監督作業的執行狀況。當用戶提交了作業之後,就可以關掉Client,作業會繼續在YARN上執行,因而YARN-Cluster模式不適合執行互動型別的作業
YARN-Client模式下,Application Master僅僅向YARN請求Executor,Client會和請求的Container通訊來排程他們工作,也就是說Client不能離開
下圖是幾種模式下的比較:
八、MapReduce的Shuffle和Spark中的Shuffle區別和聯絡
Spark在DAG排程階段會將一個Job劃分為多個Stage,上游Stage做map工作,下游Stage做reduce工作,其本質上還是MapReduce計算框架。Shuffle是連線map和reduce之間的橋樑,它將map的輸出對應到reduce輸入中,這期間涉及到序列化反序列化、跨節點網路IO以及磁碟讀寫IO等,所以說Shuffle是整個應用程式執行過程中非常昂貴的一個階段,理解Spark Shuffle原理有助於優化Spark應用程式。
注:
1.什麼是大資料處理的Shuffle?
無論是Hadoop還是Spark,都要實現Shuffle。Shuffle描述資料從map tasks的輸出到reduce tasks輸入的這段過程。
2.為什麼需要進行Shuffle呢?
map tasks的output向著reduce tasks的輸入input對映的時候,並非節點一一對應的,在節點A上做map任務的輸出結果,可能要分散跑到reduce節點A、B、C、D ,就好像shuffle的字面意思“洗牌”一樣,這些map的輸出資料要打散然後根據新的路由演算法(比如對key進行某種hash演算法),傳送到不同的reduce節點上去。
MapReduce的Shuffle
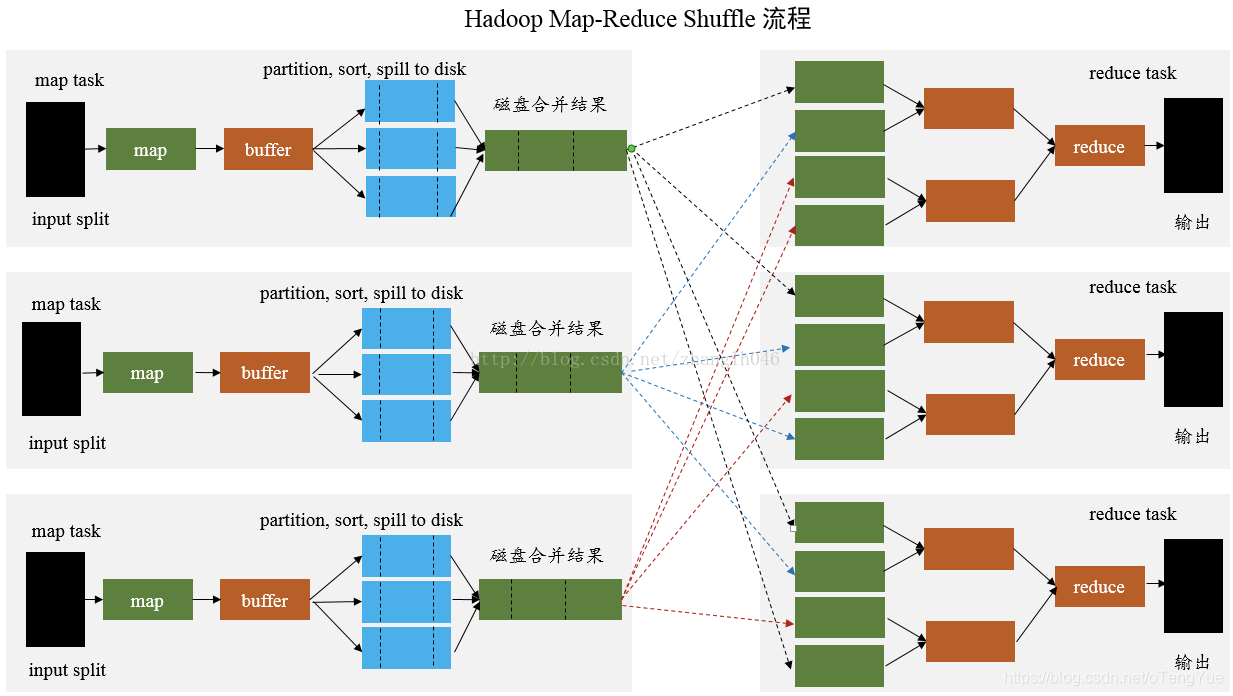
MapReduce 是 sort-based,進入 combine() 和 reduce() 的 records 必須先partition、key對中間結果進行排序合併。這樣的好處在於 combine/reduce() 可以處理大規模的資料,因為其輸入資料可以通過外排得到(mapper 對每段資料先做排序,reducer 的 shuffle 對排好序的每段資料做歸併)。
Spark中的Shuffle
前面已經提到,在DAG排程的過程中,Stage階段的劃分是根據是否有shuffle過程,也就是存在ShuffleDependency寬依賴的時候,需要進行shuffle,這時候會將作業job劃分成多個Stage;
Spark的Shuffle實現大致如下圖所示,在DAG階段以shuffle為界,劃分stage,上游stage做map task,每個map task將計算結果資料分成多份,每一份對應到下游stage的每個partition中,並將其臨時寫到磁碟,該過程叫做shuffle write;下游stage做reduce task,每個reduce task通過網路拉取上游stage中所有map task的指定分割槽結果資料,該過程叫做shuffle read,最後完成reduce的業務邏輯。
下圖是spark shuffle實現的一個版本演進。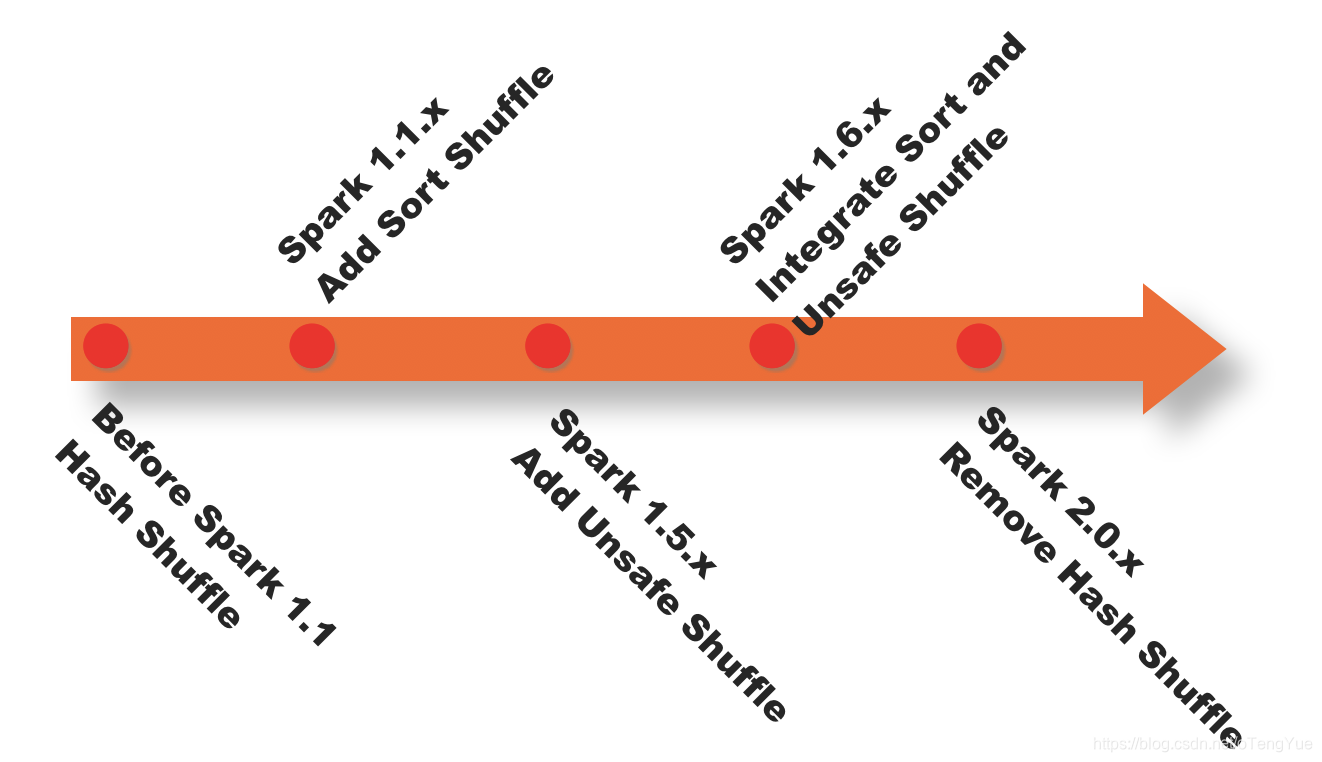
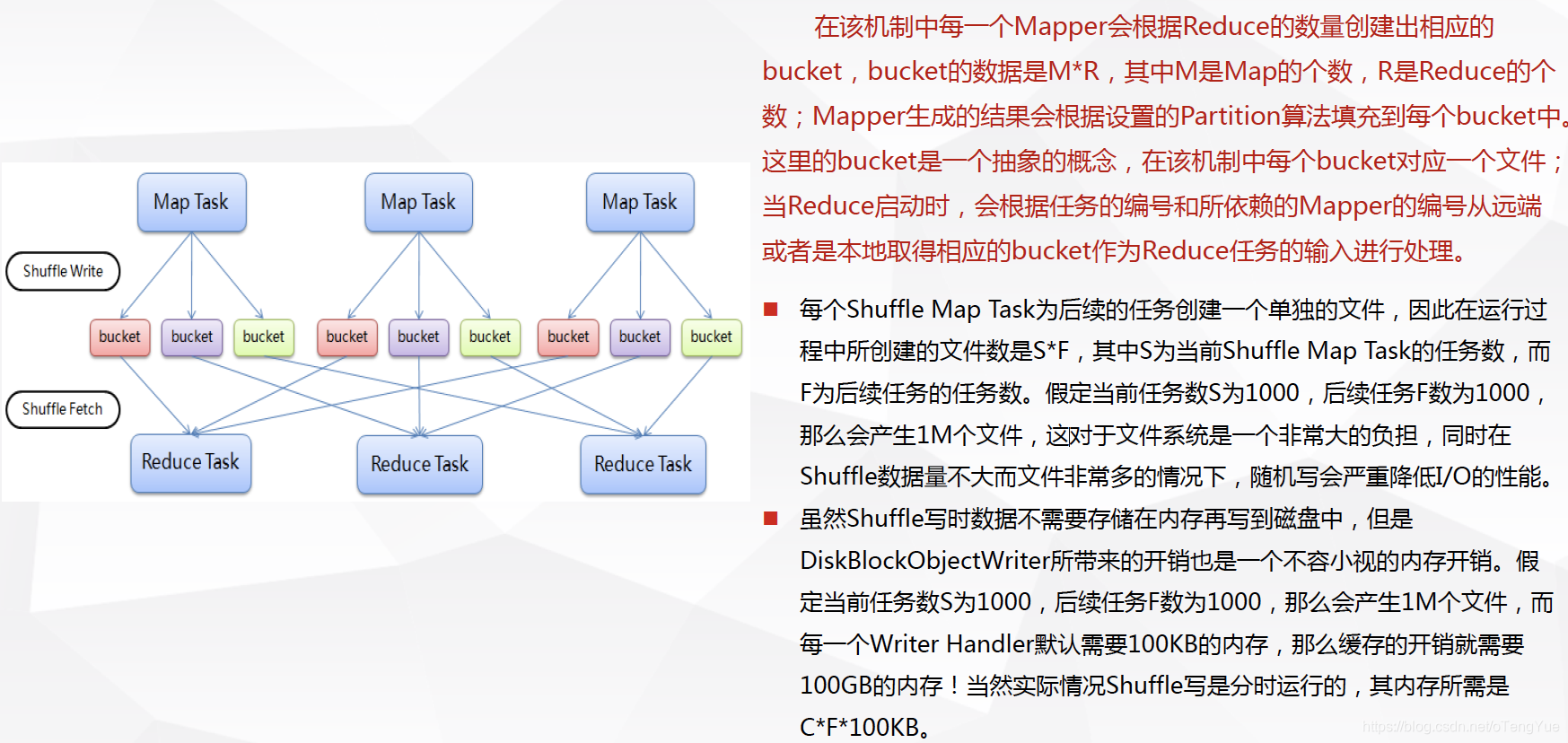
基於Hash的Shuffle實現
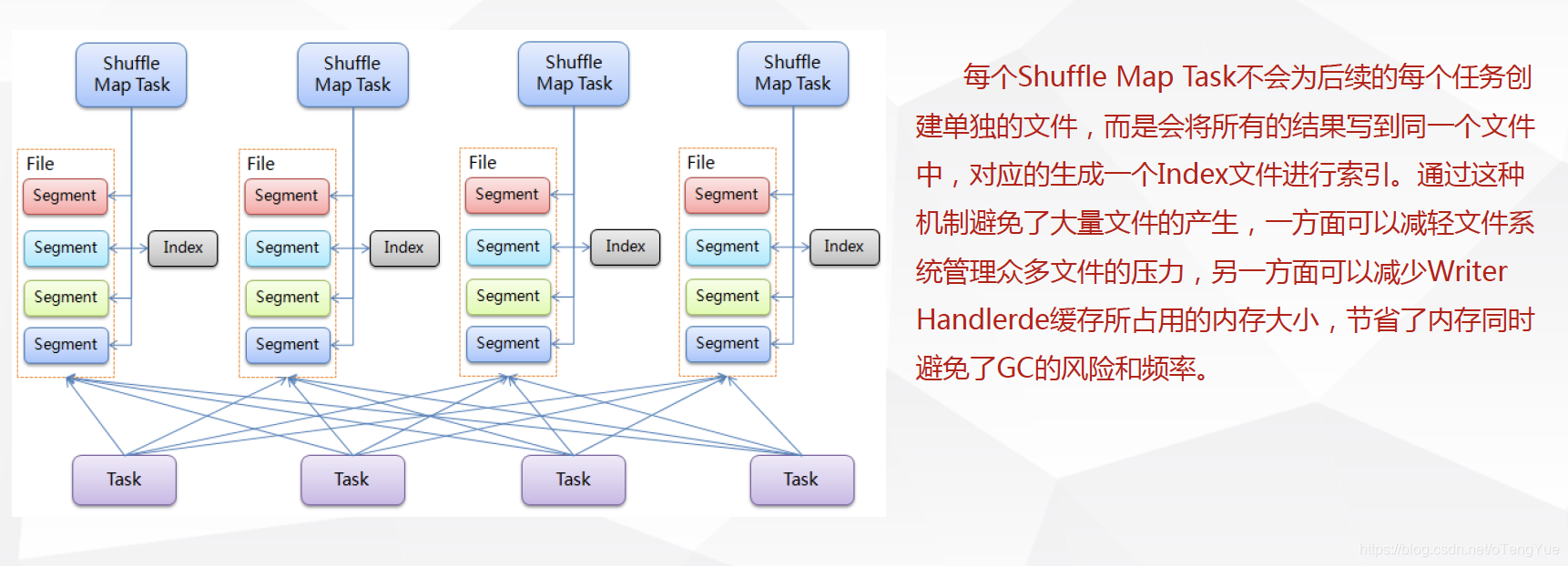
基於Sort的Shuffle實現(現在採用的機制)
九、spark中的持久化(cache()、persist()、checkpoint())
RDD持久化級別
| 持久化級別 | 含義解釋 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java物件格式,將資料儲存在記憶體中。如果記憶體不夠存放所有的資料,則資料可能就不會進行持久化。那麼下次對這個RDD執行運算元操作時,那些沒有被持久化的資料,需要從源頭處重新計算一遍。這是預設的持久化策略,使用cache()方法時,實際就是使用的這種持久化策略。 |
| DISK_ONLY | 使用未序列化的Java物件格式,將資料全部寫入磁碟檔案中。 |
| MEMORY_ONLY_SER | 基本含義同MEMORY_ONLY。唯一的區別是,會將RDD中的資料進行序列化,RDD的每個partition會被序列化成一個位元組陣列。這種方式更加節省記憶體,從而可以避免持久化的資料佔用過多記憶體導致頻繁GC。 |
| MEMORY_AND_DISK | 使用未序列化的Java物件格式,優先嚐試將資料儲存在記憶體中。如果記憶體不夠存放所有的資料,會將資料寫入磁碟檔案中,下次對這個RDD執行運算元時,持久化在磁碟檔案中的資料會被讀取出來使用。 |
| MEMORY_AND_DISK_SER | 基本含義同MEMORY_AND_DISK。唯一的區別是,會將RDD中的資料進行序列化,RDD的每個partition會被序列化成一個位元組陣列。這種方式更加節省記憶體,從而可以避免持久化的資料佔用過多記憶體導致頻繁GC。 |
- cache和persist都是用於將一個RDD進行快取,這樣在之後使用的過程中就不需要重新計算,可以大大節省程式執行時間。
- cache和persist的區別:cache只有一個預設的快取級別
MEMORY_ONLY,而persist可以根據情況設定其它的快取級別。 - checkpoint介面是將RDD持久化到HDFS中,與persist的區別是checkpoint會切斷此RDD之前的依賴關係,而persist會保留依賴關係。
checkpoint的兩大作用:
一是spark程式長期駐留,過長的依賴會佔用很多的系統資源,定期checkpoint可以有效的節省資源;
二是維護過長的依賴關係可能會出現問題,一旦spark程式執行失敗,RDD的容錯成本會很高。
(注:checkpoint執行前要先進行cache,避免兩次計算。)
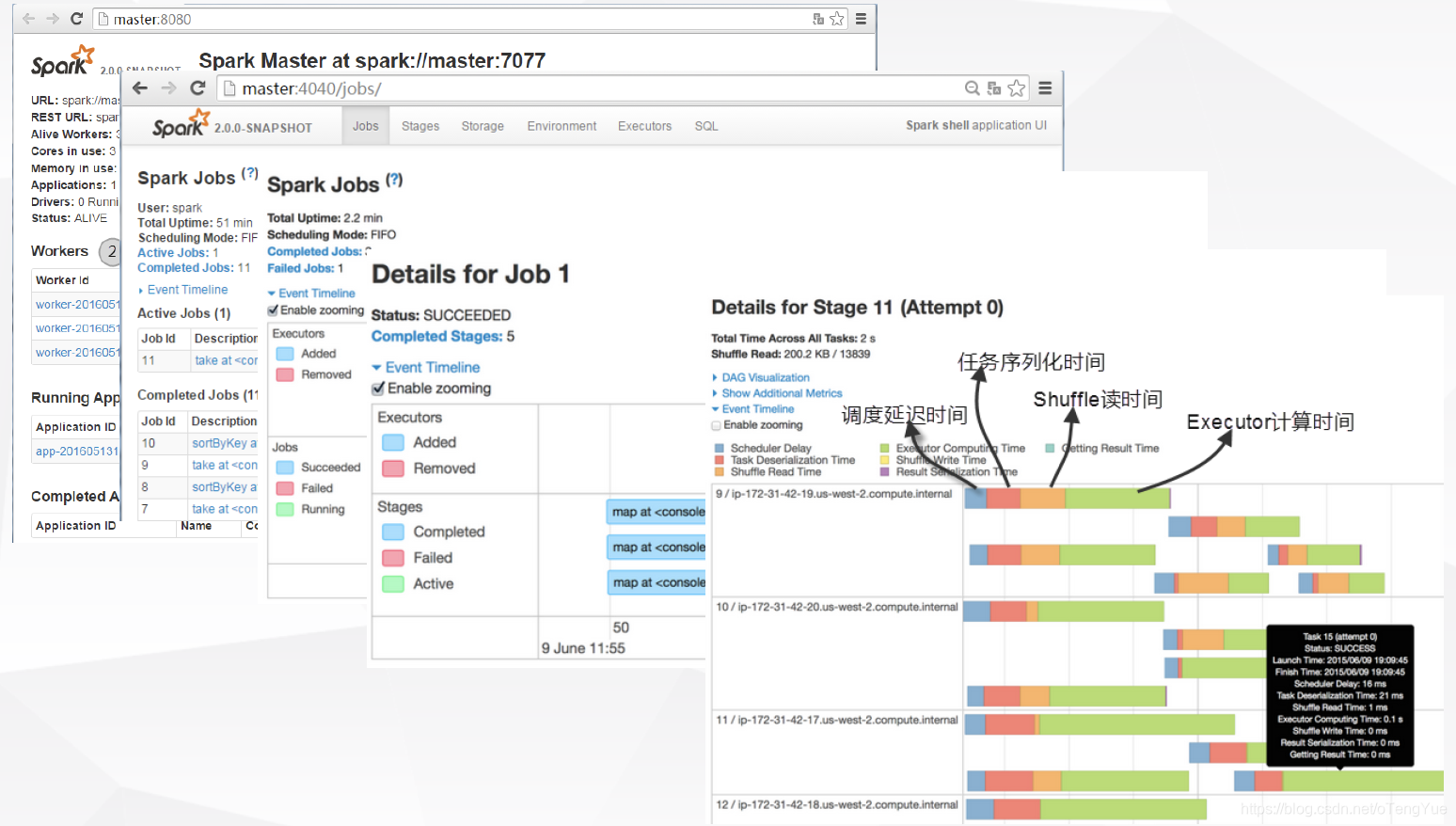
十、監控介面

相關推薦
Spark架構與原理這一篇就夠了
一、基本介紹 是什麼? 快速,通用,可擴充套件的分散式計算引擎。 彈性分散式資料集RDD RDD(Resilient Distributed Dataset)彈性分散式資料集,是Spark中最基本的資料(邏輯)抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。 RDD具有資料流模型的特點
萬字總結:學習MySQL優化原理,這一篇就夠了!
ade min() 全表掃描 搜索 財務 兼容 嵌套循環 很大的 完成 前言 說起MySQL的查詢優化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用NULL字段、合理創建索引、為字段選擇合適的數據類型..... 你是否真的理解這些優化技巧?是否理解其背後的工
EJB的解謎(EJB原理看這一篇就夠了)
EJB到底是什麼? 1. 我們不禁要問,什麼是"服務叢集"?什麼是"企業級開發"? 既然說了EJB 是為了"服務叢集"和"企業級開發",那麼,總得說說什麼是所謂的"服務叢集"和"企業級開發"吧!這個問題其實挺關鍵的,因為J2EE 中並沒有說明白,也沒有具體的指標或者事
理解Sharding jdbc原理,看這一篇就夠了
相比於Spring基於AbstractRoutingDataSource實現的分庫分表功能,Sharding jdbc在單庫單表擴充套件到多庫多表時,相容性方面表現的更好一點。例如,spring實現的分庫分表sql寫法如下: select id, name, price,
深度學習與計算機視覺 看這一篇就夠了
來源:http://www.leiphone.com/news/201605/zZqsZiVpcBBPqcGG.html#rd 人工智慧是人類一個非常美好的夢想,跟星際漫遊和長生不老一樣。我們想製造出一種機器,使得它跟人一樣具有一定的對外界事物感知能力,比如看見世界。
真的,關於深度學習與計算機視覺,看這一篇就夠了 | 硬創公開課
今年夏天,雷鋒網將在深圳舉辦“全球人工智慧與機器人創新大會”(GAIR),在本次大會上,我們將釋出“人工智慧與機器人Top25創新企業榜“,慧眼科技是我們重點關注的公司之一。今天,我們邀請到慧眼科技研發總監李漢曦,為我們帶來深度學習與計算機視覺方面的內容分享。 嘉賓
Docker基礎與實戰,看這一篇就夠了
docker 基礎 什麼是Docker Docker 使用 Google 公司推出的 Go 語言 進行開發實現,基於 Linux 核心的 cgroup,namespace,以及 AUFS 類的 Union FS 等技術,對程序進行封裝隔離,屬於 作業系統層面的虛擬化技術。由於隔離的程序獨立於宿主和其它的隔離的
Docker-Compose基礎與實戰,看這一篇就夠了
what & why Compose 專案是 Docker 官方的開源專案,負責實現對 Docker 容器叢集的快速編排。使用前面介紹的Dockerfile我們很容易定義一個單獨的應用容器。然而在日常開發工作中,經常會碰到需要多個容器相互配合來完成某項任務的情況。例如要實現一個 Web 專案,除了
File流與IO流 看這一篇就夠了
主要內容 File類 遞迴 IO流 位元組流 字元流 異常處理 Properties 緩衝流 轉換流 序列化流 列印流 學習目標 [ ] 能夠說出File物件的建立方式 [ ] 能夠說出File類獲取名稱的方法名稱 [ ] 能夠說出File類獲取絕對路徑的方法名稱 [ ] 能夠說出File類獲取檔案大小
spark中的pair rdd,看這一篇就夠了
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天是spark專題的第四篇文章,我們一起來看下Pair RDD。 定義 在之前的文章當中,我們已經熟悉了RDD的相關概念,也瞭解了RDD基本的轉化操作和行動操作。今天我們來看一下RDD當中非常常見的PairRDD,也叫做鍵值對RDD
【FastDFS】FastDFS 分散式檔案系統的安裝與使用,看這一篇就夠了!!
## 寫在前面 > 有不少小夥伴在實際工作中,對於如何儲存檔案(圖片、視訊、音訊等)沒有一個很好的解決思路。都明白不能將檔案儲存在單臺伺服器的磁碟上,也知道需要將檔案進行副本備份。如果自己手動寫檔案的副本機制,那就太麻煩了,這會涉及冗餘副本機制、伺服器的排程、副本檢測、伺服器節點檢測、檔案副本存放策略
Spring中的BeanFactory與FactoryBean看這一篇就夠了
前言 理解FactoryBean是非常非常有必要的,因為在Spring中FactoryBean最為典型的一個應用就是用來建立AOP的代理物件,不僅如此,而且對理解Mybatis核心原始碼也非常有幫助!如果甘願crud,做個快樂的碼農,那我就哦豁豁豁豁豁豁豁豁豁豁豁豁豁豁...... @[toc] BeanF
spark記憶體管理這一篇就夠了
1. 堆內和堆外記憶體規劃 1.1 堆內記憶體 堆內記憶體的大小,由 Spark 應用程式啟動時的 –executor-memory 或 spark.executor.memory 引數配置。Executor 內執行的併發任務共享 JVM 堆內記憶體,這些任務在快取 RDD 資料和廣播(Broadcast)資
【轉】【修真院“善良”系列之十八】WEB程序員從零開始到就業的全資料V1.0——只看這一篇就夠了!
absolute feed 自己 session rem 好的 ans 一個 css樣式 這是兩年以來,修真院收集整理的學習資料順序。以CSS15個任務,JS15個任務為基礎,分別依據要完成任務的不同的技能點,我們整理出來了這麽一篇在學習的時候需要看到的資料。這是Versi
Java中的多線程你只要看這一篇就夠了
== 討論 cin 線程池。 locking nth lis dset tro 引 如果對什麽是線程、什麽是進程仍存有疑惑,請先Google之,因為這兩個概念不在本文的範圍之內。 用多線程只有一個目的,那就是更好的利用cpu的資源,因為所有的多線程代碼都可以用單線程來實現。
Azure IOT 設備固件更新技巧,看這一篇就夠了
trigger 物聯網平臺 搭建 href ice 有效 面板 調用 創建 嫌長不看版 今天為大家準備的硬菜是:在 Azure IoT 中心創建 Node.js 控制臺應用,進行端到端模擬固件更新,為基於 Intel Edison 的設備安裝新版固件的流程。通過創建模擬設備
轉:Java中的多線程你只要看這一篇就夠了
無法 線程不安全 str his ace oat 情況下 containe live 如果對什麽是線程、什麽是進程仍存有疑惑,請先Google之,因為這兩個概念不在本文的範圍之內。 用多線程只有一個目的,那就是更好的利用cpu的資源,因為所有的多線程代碼都可以用單線程來實現
想做好PPT折線圖,看這一篇就夠了!
12月 image 菊花 -c 強調 spa any border 線圖 配圖主題無關今天鄭少跟大家聊聊折線圖的使用方法,或者你有疑問,折線圖很簡單,插入修改數據不就好了嗎?如果你要是這樣想的,恭喜你,有可能你會做出下面這樣的效果。如果你要是稍微懂一點折線圖的使用方法,你就
JSON入門看這一篇就夠了
jsb cart 開發包 fonts 數據 長度 gmv lock 在哪裏 什麽是JSON JSON:JavaScript Object Notation 【JavaScript 對象表示法】 JSON 是存儲和交換文本信息的語法。類似 XML。 JSON采用完全獨立於任何
Struts2入門這一篇就夠了
and win ioe 了解 指正 屬性 內容 servlet 優雅 前言 這是Strtus的開山篇,主要是引入struts框架...為什麽要引入struts,引入struts的好處是什麽,以及對Struts2一個簡單的入門.... 為什麽要引入struts? 既然Serv