
flink1.10版local模式提交job流程分析
阿新 • • 發佈:2020-11-19
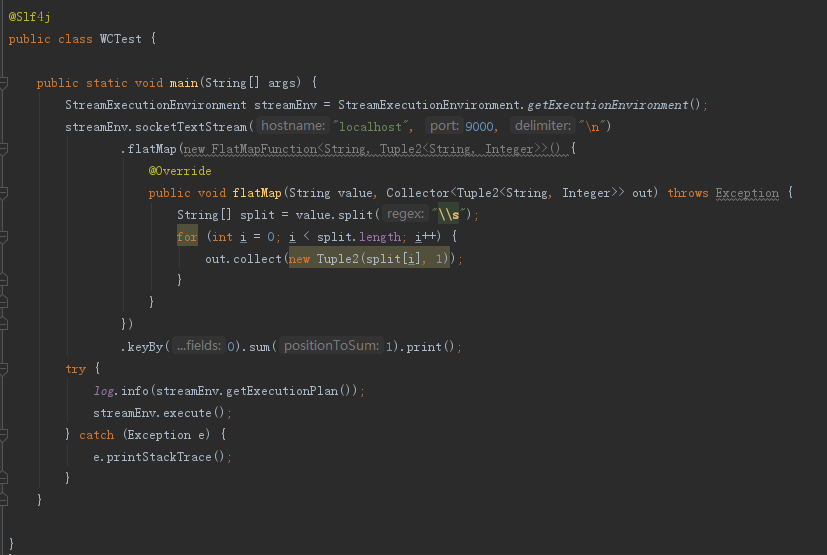
1、WordCount程式例項
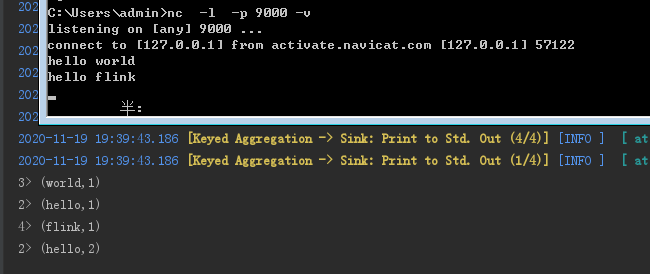
2、本地監聽9000埠後測試結果
3、job提交流程
4、local模式執行StreamGraph任務
5、流程分析
flink job提交流程個人理解可以大致分為定義和提交兩個環節:以下以WordCount程式為例進行分析
5.1 定義流程
流程定義包含執行環境構建和演算法流程定義:
5.1.1 執行環境構建
執行環境是整個flink程式執行的上下文,記錄其相關配置,並提供一系列方法,如讀取輸入流等,同時提供execute真正開啟提交計算的入口。

下面具體來看getExecutionEnvironment方法

本地執行時,其實執行的是createStreamExecutionEnvironment方法
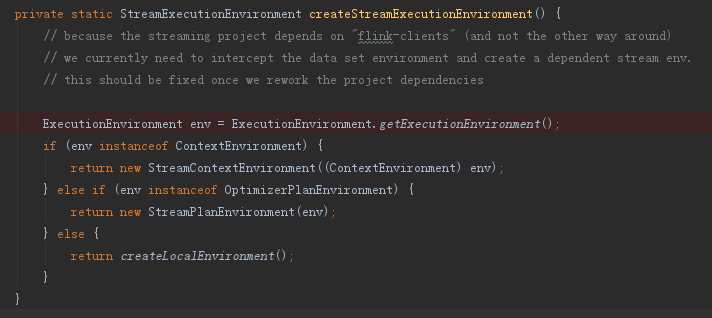
繼續往下看發現不斷過載createLocalEnvironment方法,最終new了一個LocalStreamEnvironment物件,並設定其並行度等於當前機器的CPU核心數

至此執行環境構建完畢,返回一個LocalStreamEnvironment物件
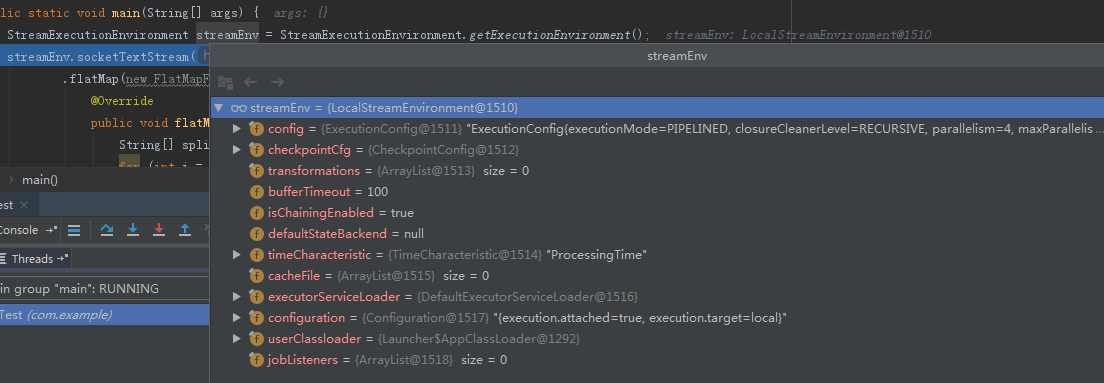
5.1.2 演算法流程定義
演算法流程簡單來說通常包含三個部分:定義source、operator和sink,對應到示例程式為socketTextStream、(flatMap、keyBy、sum)和print三部分
首先:socketTextStream其本質是向執行環境中添加了SocketTextStreamFunction作為source


其次:faltMap、keyBy和sum其本質是向執行環境中新增FlatMapFunction、KeySelector和AggregationFunction三種運算元
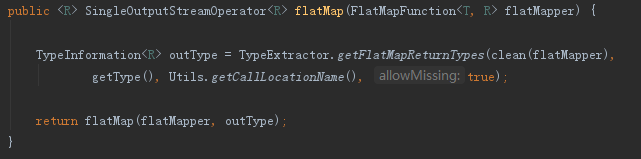

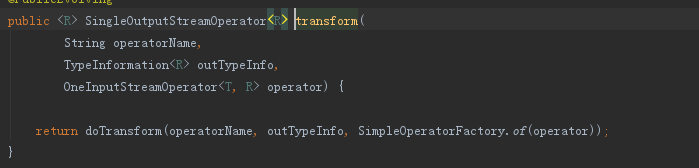
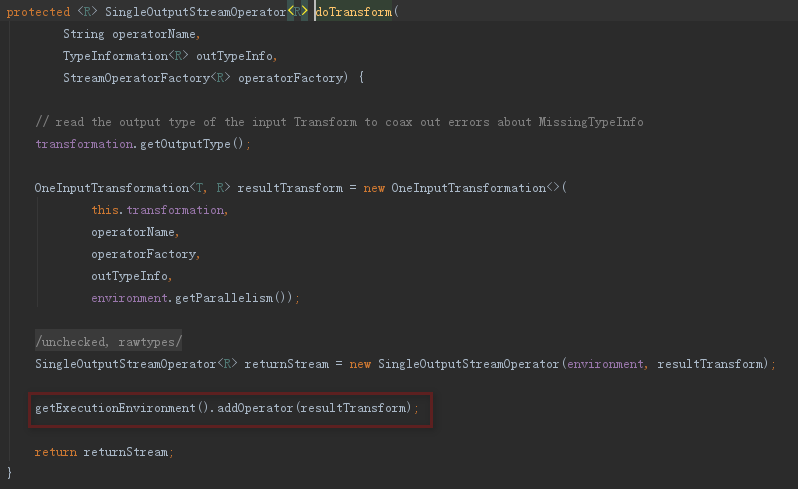
下面分別為keyBy和sum的關鍵細節
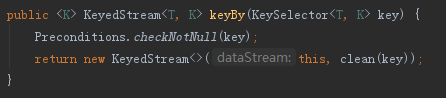


最後:print其本質是向執行環境中新增PrintSinkFunction作為sink

5.2 提交任務
提交任務個人理解又包含client提交作業和Executor提交作業兩部分
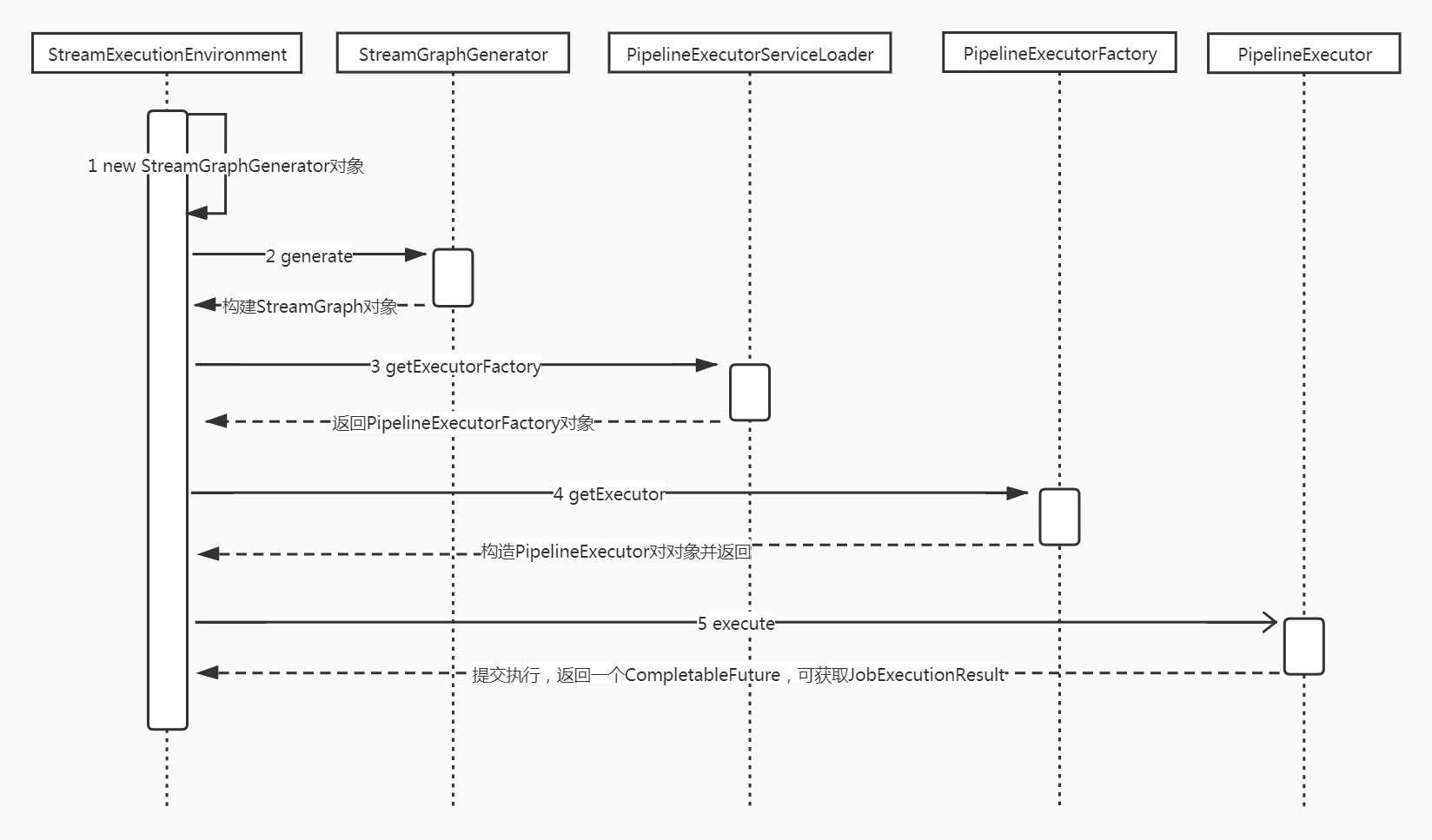
5.2.1 第一個環節client根據流程定義提交作業如job提交流程圖所示
這個過程其實又可以可以分為兩部分:生成StreamGraph和executeAsync兩部分:
首先看生成StreamGraph部分,這一部分比較簡單,將執行環境中定義好的流程引數構建出StreamGraph即可,核心細節如下:
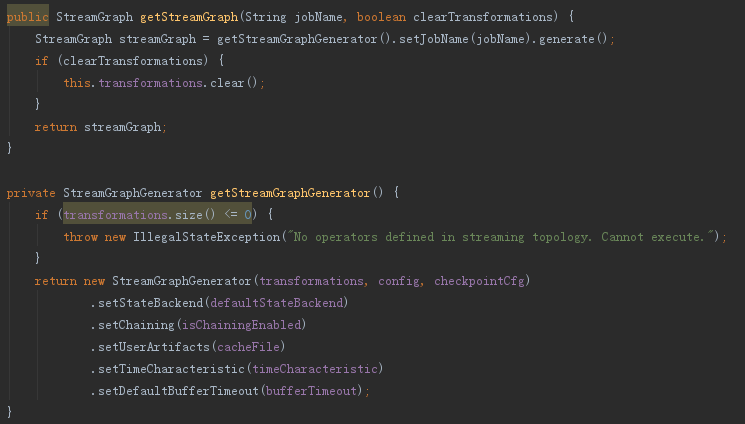
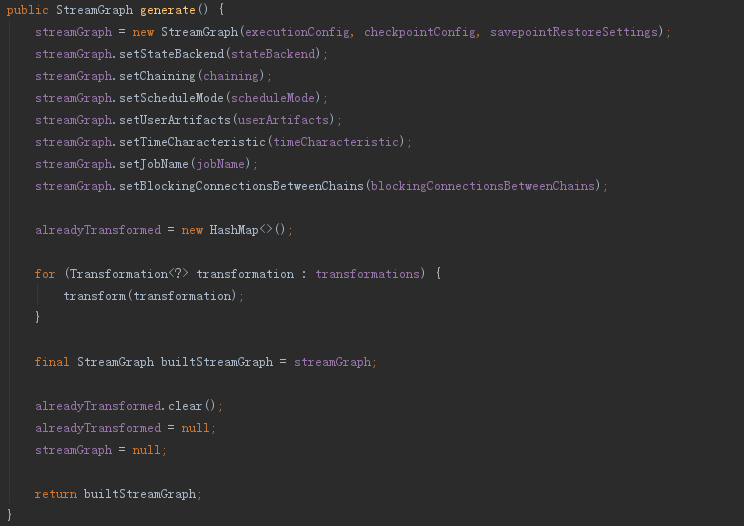
executeAsync部分其實就是載入一個PipelineExecutor提交StreamGraph,細節如下:
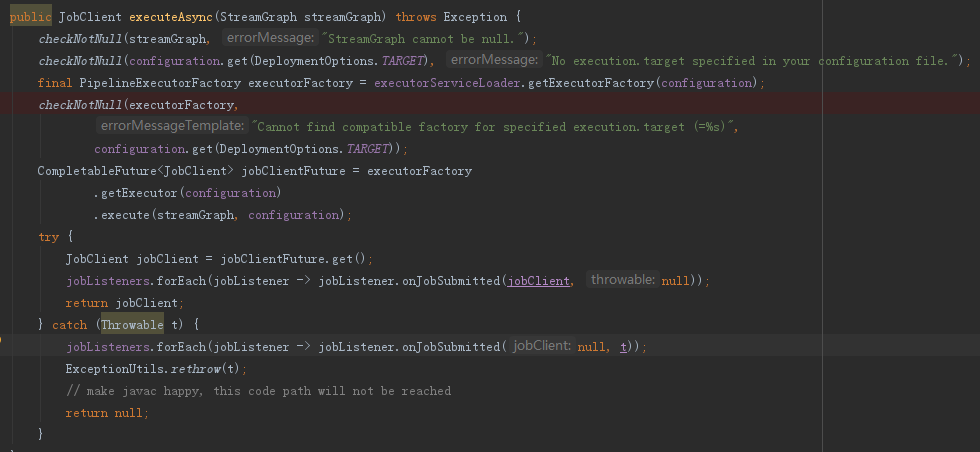

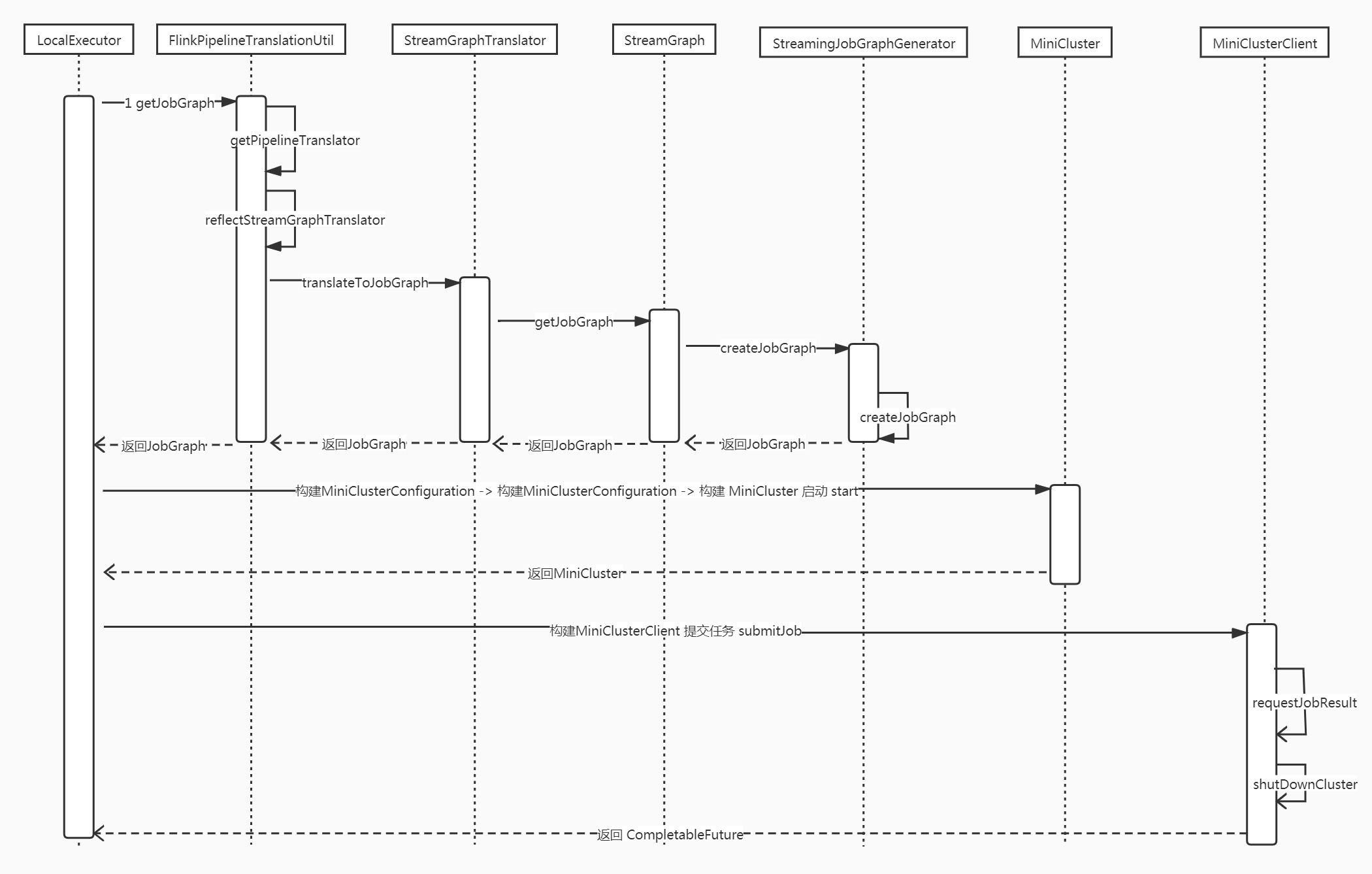
5.2.2 第二個環節Executor提交作業部分原始碼如下:
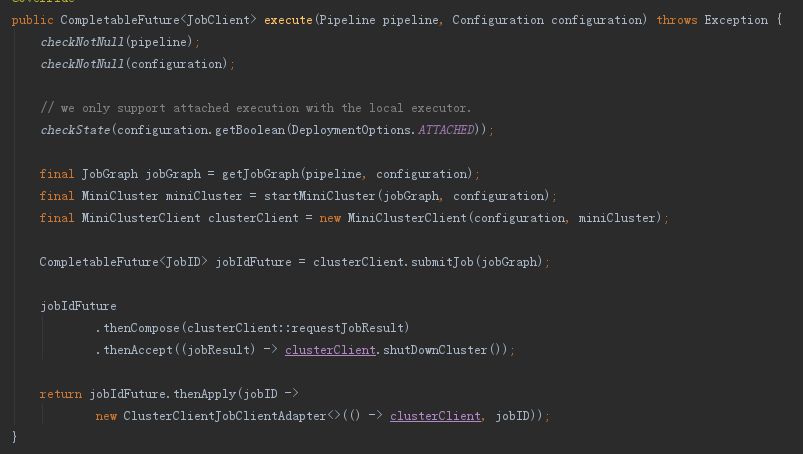
本地模式主要包含了以下環節:
1> 由StreamGraph生成JobGraph
2> 建立啟動miniCluster叢集,啟動JobMaster等等
3> 提交任務到Jo