
Javaer 進階必看的 RocketMQ ,就這篇了
阿新 • • 發佈:2020-11-20
> 每個時代,都不會虧待會學習的人。
大家好,我是 yes。
繼上一篇 [頭條終面:寫個訊息中介軟體](https://mp.weixin.qq.com/s/rsy1Tl-E2Jl8l8hwqW62zQ) ,我提到實現訊息中介軟體的一些關鍵點,今天就和大家一起深入生產級別訊息中介軟體 - RocketMQ 的核心實現,來看看真正落地能支撐萬億級訊息容量、低延遲的訊息佇列到底是如何設計的。
這篇文章我會先介紹整體的架構設計,然後再深入各核心模組的詳細設計、核心流程的剖析。
還會提及使用的一些注意點和最佳實踐。
對於訊息佇列的用處和一些概念不太清楚的同學強烈建議先看[訊息佇列面試連環問](https://mp.weixin.qq.com/s/nHKok3sG0ueg5EgVHwWnLg),這篇文章介紹了訊息佇列的使用場景、基本概念和常見面試題。
話不多說,上車。
## RocketMQ 整體架構設計
整體的架構設計主要分為四大部分,分別是:Producer、Consumer、Broker、NameServer。
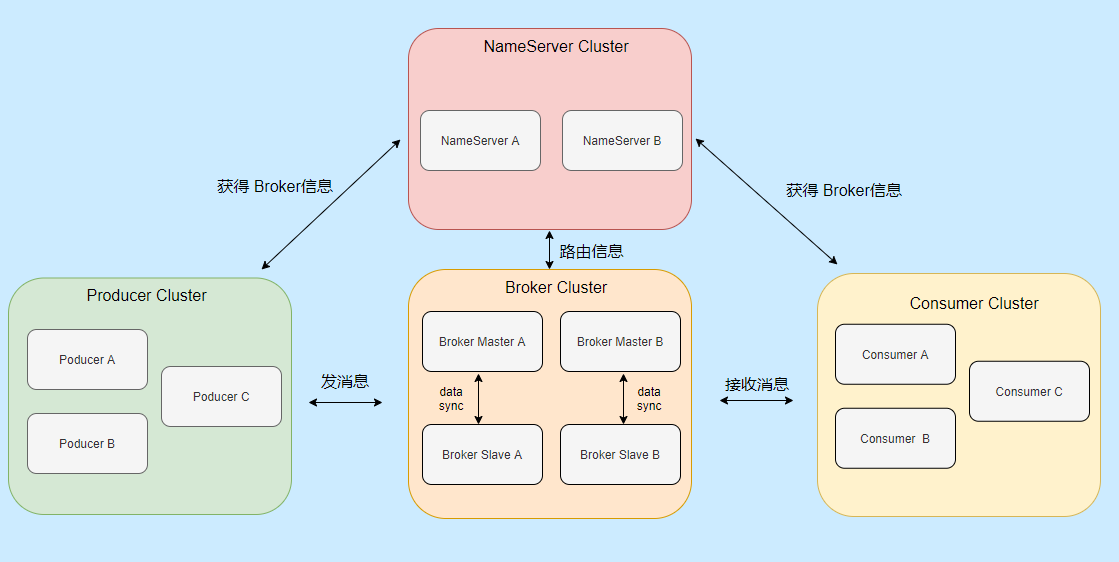
為了更貼合實際,我畫的都是叢集部署,像 Broker 我還畫了主從。
- Producer:就是訊息生產者,可以叢集部署。它會先和 NameServer 叢集中的隨機一臺建立長連線,得知當前要傳送的 Topic 存在哪臺 Broker Master上,然後再與其建立長連線,支援多種負載平衡模式傳送訊息。
- Consumer:訊息消費者,也可以叢集部署。它也會先和 NameServer 叢集中的隨機一臺建立長連線,得知當前要訊息的 Topic 存在哪臺 Broker Master、Slave上,然後它們建立長連線,支援叢集消費和廣播消費訊息。
- Broker:主要負責訊息的儲存、查詢消費,支援主從部署,一個 Master 可以對應多個 Slave,Master 支援讀寫,Slave 只支援讀。**Broker 會向叢集中的每一臺 NameServer 註冊自己的路由資訊。**
- NameServer:是一個很簡單的 Topic 路由註冊中心,支援 Broker 的動態註冊和發現,儲存 Topic 和 Borker 之間的關係。通常也是叢集部署,但是**各 NameServer 之間不會互相通訊, 各 NameServer 都有完整的路由資訊**,即無狀態。
我再用一段話來概括它們之間的互動:

先啟動 NameServer 叢集,各 NameServer 之間無任何資料互動,Broker 啟動之後會向所有 NameServer 定期(每 30s)傳送心跳包,包括:IP、Port、TopicInfo,NameServer 會定期掃描 Broker 存活列表,如果超過 120s 沒有心跳則移除此 Broker 相關資訊,代表下線。
這樣每個 NameServer 就知道叢集所有 Broker 的相關資訊,此時 Producer 上線從 NameServer 就可以得知它要傳送的某 Topic 訊息在哪個 Broker 上,和對應的 Broker (Master 角色的)建立長連線,傳送訊息。
Consumer 上線也可以從 NameServer 得知它所要接收的 Topic 是哪個 Broker ,和對應的 Master、Slave 建立連線,接收訊息。
簡單的工作流程如上所述,相信大家對整體資料流轉已經有點印象了,我們再來看看每個部分的詳細情況。
## NameServer
它的特點就是輕量級,無狀態。角色類似於 Zookeeper 的情況,從上面描述知道其主要的兩個功能就是:Broker 管理、路由資訊管理。
總體而言比較簡單,我再貼一些欄位,讓大家有更直觀的印象知道它儲存了些什麼。

## Producer
Producer 無非就是訊息生產者,那首先它得知道訊息要發往哪個 Broker ,於是每 30s 會從某臺 NameServer 獲取 Topic 和 Broker 的對映關係存在本地記憶體中,如果發現新的 Broker 就會和其建立長連線,每 30s 會發送心跳至 Broker 維護連線。
並且會**輪詢當前可以傳送的 Broker 來發送訊息**,達到負載均衡的目的,在**同步傳送情況**下如果傳送失敗會預設重投兩次(retryTimesWhenSendFailed = 2),並且不會選擇上次失敗的 broker,會向其他 broker 投遞。
在**非同步傳送**失敗的情況下也會重試,預設也是兩次 (retryTimesWhenSendAsyncFailed = 2),但是僅在同一個 Broker 上重試。
### Producer 啟動流程
然後我們再來看看 Producer 的啟動流程看看都幹了些啥。
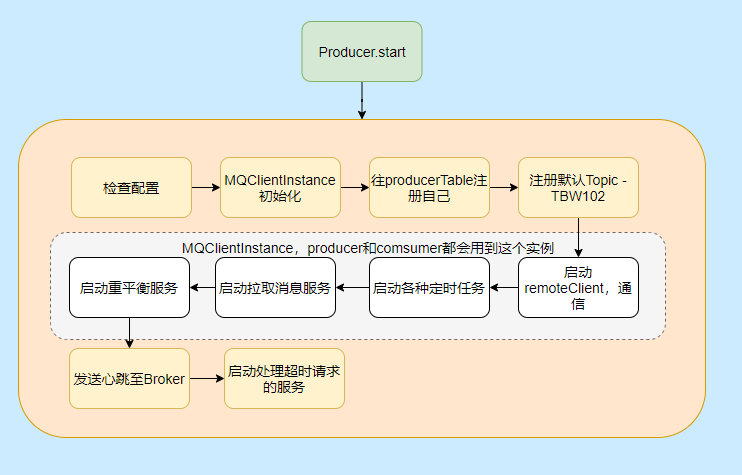
大致啟動流程圖中已經表明的很清晰的,但是有些細節可能還不清楚,比如重平衡啊,TBW102 啥玩意啊,有哪些定時任務啊,別急都會提到的。
有人可能會問這生產者為什麼要啟拉取服務、重平衡?
因為 Producer 和 Consumer 都需要用 MQClientInstance,而同一個 clientId 是共用一個 MQClientInstance 的, clientId 是通過本機 IP 和 instanceName(預設值 default)拼起來的,所以多個 Producer 、Consumer 實際用的是一個MQClientInstance。
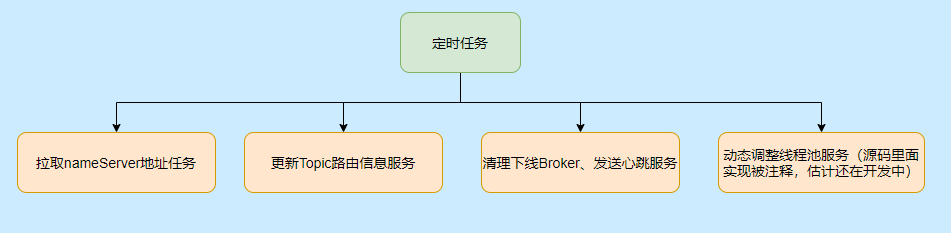
至於有哪些定時任務,請看下圖:
### Producer 發訊息流程
我們再來看看發訊息的流程,大致也不是很複雜,無非就是找到要傳送訊息的 Topic 在哪個 Broker 上,然後傳送訊息。
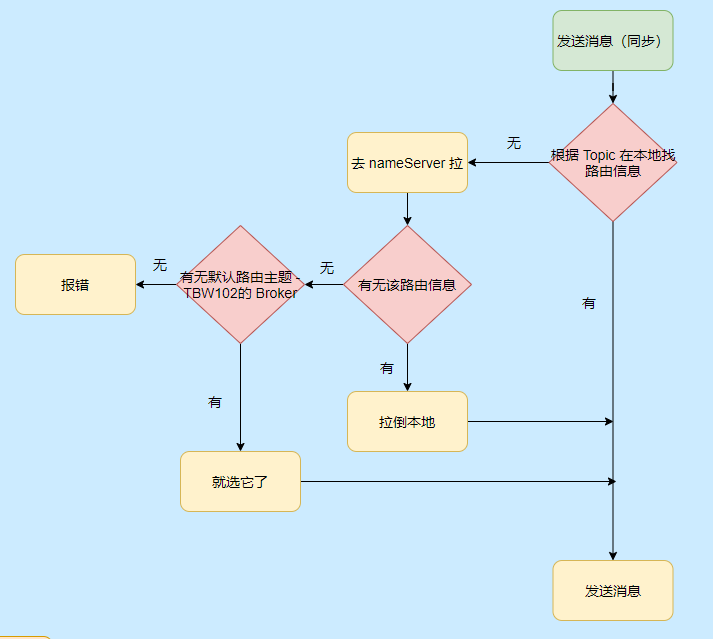
現在就知道 TBW102 是啥用的,就是接受自動建立主題的 Broker 啟動會把這個預設主題登記到 NameServer,這樣當 Producer 傳送新 Topic 的訊息時候就得知哪個 Broker 可以自動建立主題,然後發往那個 Broker。
而 Broker 接受到這個訊息的時候發現沒找到對應的主題,但是它接受建立新主題,這樣就會建立對應的 Topic 路由資訊。
## 自動建立主題的弊端
自動建立主題那麼有可能該主題的訊息都只會發往一臺 Broker,起不到負載均衡的作用。
因為建立新 Topic 的請求到達 Broker 之後,Broker 建立對應的路由資訊,但是心跳是每 30s 傳送一次,所以說 NameServer 最長需要 30s 才能得知這個新 Topic 的路由資訊。
**假設此時傳送方還在連續快速的傳送訊息**,那 NameServer 上其實還沒有關於這個 Topic 的路由資訊,所以**有機會**讓別的允許自動建立的 Broker 也建立對應的 Topic 路由資訊,這樣叢集裡的 Broker 就能接受這個 Topic 的資訊,達到負載均衡的目的,但也有個別 Broker 可能,沒收到。
如果傳送方這一次發了之後 30s 內一個都不發,之前的那個 Broker 隨著心跳把這個路由資訊更新到 NameServer 了,那麼之後傳送該 Topic 訊息的 Producer 從 NameServer 只能得知該 Topic 訊息只能發往之前的那臺 Broker ,這就不均衡了,如果這個新主題訊息很多,那臺 Broker 負載就很高了。
**所以不建議線上開啟允許自動建立主題,即 autoCreateTopicEnable 引數。**
## 傳送訊息故障延遲機制
有一個引數是 sendLatencyFaultEnable,預設不開啟。這個引數的作用是對於之前傳送超時的 Broker 進行一段時間的退避。
傳送訊息會記錄此時傳送訊息的時間,如果超過一定時間,那麼此 Broker 就在一段時間內不允許傳送。

比如傳送時間超過 15000ms 則在 600000 ms 內無法向該 Broker 傳送訊息。
這個機制其實很關鍵,傳送超時大概率表明此 Broker 負載高,所以先避讓一會兒,讓它緩一緩,這也是實現訊息傳送高可用的關鍵。
## 小結一下
Producer 每 30s 會向 NameSrv 拉取路由資訊更新本地路由表,有新的 Broker 就和其建立長連線,每隔 30s 傳送心跳給 Broker 。
不要在生產環境開啟 autoCreateTopicEnable。
Producer 會通過重試和延遲機制提升訊息傳送的高可用。
## Broker
Broker 就比較複雜一些了,但是非常重要。大致分為以下五大模組,我們來看一下官網的圖。
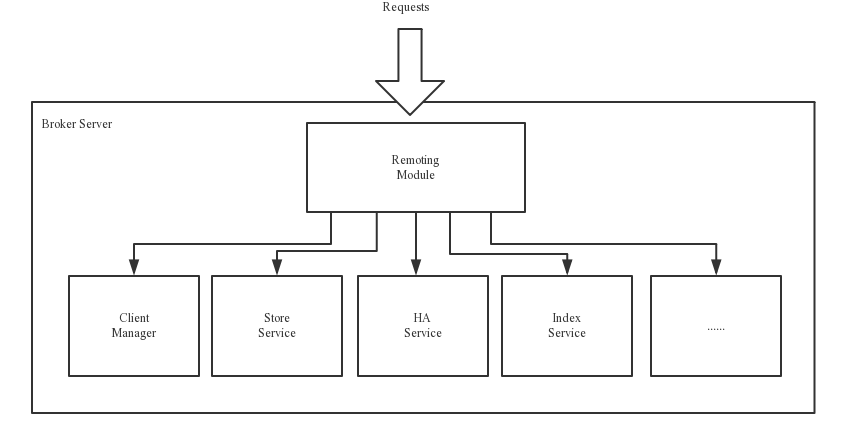
- Remoting 遠端模組,處理客戶請求。
- Client Manager 管理客戶端,維護訂閱的主題。
- Store Service 提供訊息儲存查詢服務。
- HA Serivce,主從同步高可用。
- Index Serivce,通過指定key 建立索引,便於查詢。
有幾個模組沒啥可說的就不分析了,先看看儲存的。
## Broker 的儲存
RocketMQ 儲存用的是本地檔案儲存系統,效率高也可靠。
主要涉及到三種類型的檔案,分別是 CommitLog、ConsumeQueue、IndexFile。
### CommitLog
RocketMQ 的所有主題的訊息都存在 CommitLog 中,單個 CommitLog 預設 1G,並且檔名以起始偏移量命名,固定 20 位,不足則前面補 0,比如 00000000000000000000 代表了第一個檔案,第二個檔名就是 00000000001073741824,表明起始偏移量為 1073741824,以這樣的方式命名用偏移量就能找到對應的檔案。
所有訊息都是順序寫入的,超過檔案大小則開啟下一個檔案。
### ConsumeQueue
ConsumeQueue 訊息消費佇列,可以認為是 CommitLog 中訊息的索引,因為 CommitLog 是糅合了所有主題的訊息,所以通過索引才能更加高效的查詢訊息。
ConsumeQueue 儲存的條目是固定大小,只會儲存 8 位元組的 commitlog 物理偏移量,4 位元組的訊息長度和 8 位元組 Tag 的雜湊值,固定 20 位元組。
在實際儲存中,ConsumeQueue 對應的是一個Topic 下的某個 Queue,每個檔案約 5.72M,由 30w 條資料組成。
消費者是先從 ConsumeQueue 來得到訊息真實的實體地址,然後再去 CommitLog 獲取訊息。
### IndexFile
IndexFile 就是索引檔案,是額外提供查詢訊息的手段,不影響主流程。
通過 Key 或者時間區間來查詢對應的訊息,檔名以建立時間戳命名,固定的單個 IndexFile 檔案大小約為400M,一個 IndexFile 儲存 2000W個索引。
我們再來看看以上三種檔案的內容是如何生成的:
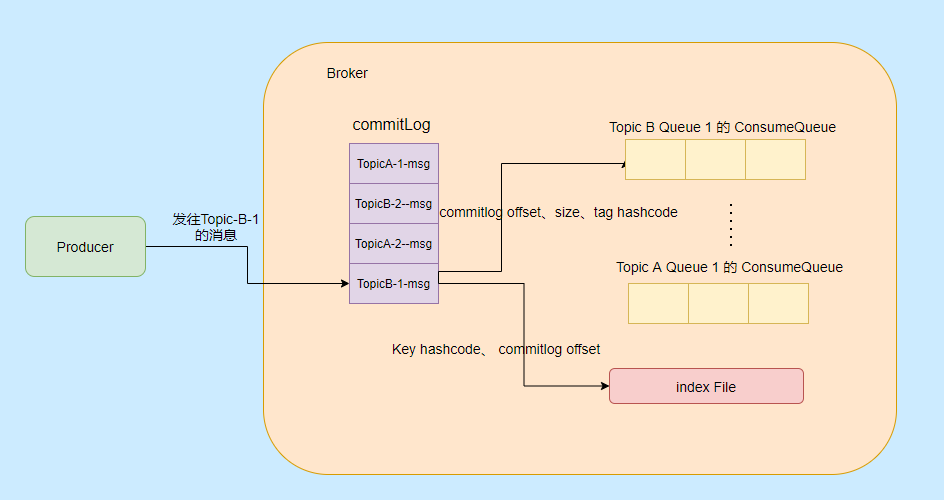
訊息到了先儲存到 Commitlog,然後會有一個 ReputMessageService 執行緒接近實時地將訊息轉發給訊息消費佇列檔案與索引檔案,也就是說是非同步生成的。
## 訊息刷盤機制
RocketMQ 提供訊息同步刷盤和非同步刷盤兩個選擇,關於刷盤我們都知道效率比較低,單純存入記憶體中的話效率是最高的,但是可靠性不高,影響訊息可靠性的情況大致有以下幾種:
1. Broker 被暴力關閉,比如 kill -9
2. Broker 掛了
3. 作業系統掛了
4. 機器斷電
5. 機器壞了,開不了機
6. 磁碟壞了
如果都是 1-4 的情況,同步刷盤肯定沒問題,非同步的話就有可能丟失部分訊息,5 和 6就得依靠副本機制了,如果同步雙寫肯定是穩的,但是效能太差,如果非同步則有可能丟失部分訊息。
所以需要看場景來使用同步、非同步刷盤和副本雙寫機制。
## 頁快取與記憶體對映
Commitlog 是混合儲存的,所以所有訊息的寫入就是順序寫入,對檔案的順序寫入和記憶體的寫入速度基本上沒什麼差別。
並且 RocketMQ 的檔案都利用了記憶體對映即 Mmap,將程式虛擬頁面直接對映到頁快取上,無需有核心態再往使用者態的拷貝,來看一下我之前文章畫的圖。
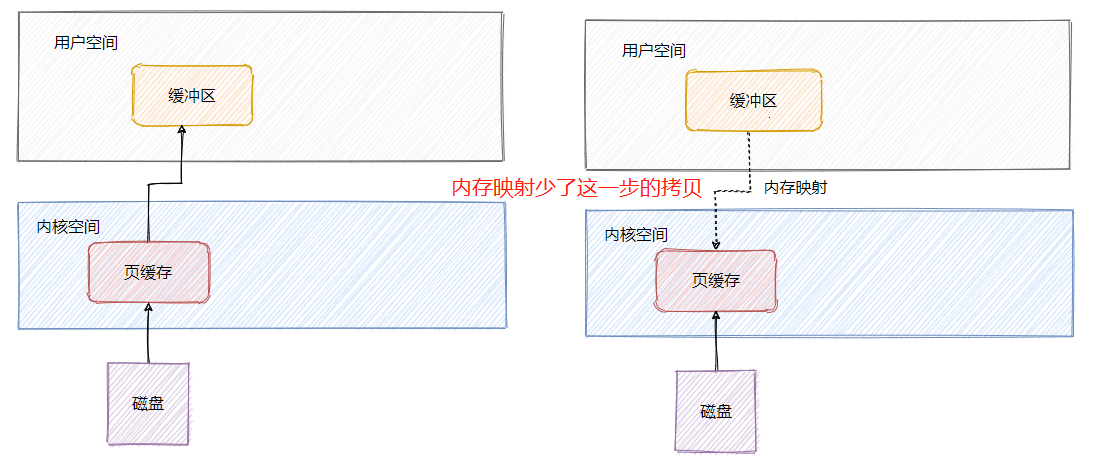
頁快取其實就是作業系統對檔案的快取,用來加速檔案的讀寫,也就是說對檔案的寫入先寫到頁快取中,作業系統會不定期刷盤(時間不可控),對檔案的讀會先載入到頁快取中,並且根據區域性性原理還會預讀臨近塊的內容。
其實也是因為使用記憶體對映機制,所以 RocketMQ 的檔案儲存都使用定長結構來儲存,方便一次將整個檔案對映至記憶體中。
## 檔案預分配和檔案預熱
而記憶體對映也只是做了對映,只有當真正讀取頁面的時候產生缺頁中斷,才會將資料真正載入到記憶體中,所以 RocketMQ 做了一些優化,防止執行時的效能抖動。
### 檔案預分配
CommitLog 的大小預設是1G,當超過大小限制的時候需要準備新的檔案,而 RocketMQ 就起了一個後臺執行緒 AllocateMappedFileService,不斷的處理 AllocateRequest,AllocateRequest 其實就是預分配的請求,會提前準備好下一個檔案的分配,防止在訊息寫入的過程中分配檔案,產生抖動。
### 檔案預熱
有一個 warmMappedFile 方法,它會把當前對映的檔案,每一頁遍歷多去,寫入一個0位元組,然後再呼叫mlock 和 madvise(MADV_WILLNEED)。
mlock:可以將程序使用的部分或者全部的地址空間鎖定在實體記憶體中,防止其被交換到 swap 空間。
madvise:給作業系統建議,說這檔案在不久的將來要訪問的,因此,提前讀幾頁可能是個好主意。
## 小結一下
CommitLog 採用混合型儲存,也就是所有 Topic 都存在一起,順序追加寫入,檔名用起始偏移量命名。
訊息先寫入 CommitLog 再通過後臺執行緒分發到 ConsumerQueue 和 IndexFile 中。
消費者先讀取 ConsumerQueue 得到真正訊息的實體地址,然後訪問 CommitLog 得到真正的訊息。
利用了 mmap 機制減少一次拷貝,利用檔案預分配和檔案預熱提高效能。
提供同步和非同步刷盤,根據場景選擇合適的機制。
## Broker 的 HA
從 Broker 會和主 Broker 建立長連線,然後獲取主 Broker commitlog 最大偏移量,開始向主 Broker 拉取訊息,主 Broker 會返回一定數量的訊息,迴圈進行,達到主從資料同步。
消費者消費訊息會先請求主 Broker ,如果主 Broker 覺得現在壓力有點大,則會返回從 Broker 拉取訊息的建議,然後消費者就去從伺服器拉取訊息。
## Consumer
消費有兩種模式,分別是廣播模式和叢集模式。
廣播模式:一個分組下的每個消費者都會消費完整的Topic 訊息。
叢集模式:一個分組下的消費者瓜分消費Topic 訊息。
一般我們用的都是叢集模式。
而消費者消費訊息又分為推和拉模式,詳細看我這篇文章[訊息佇列推拉模式](https://mp.weixin.qq.com/s/Afeg3EyvGI3KjSpjKEncZQ),分別從原始碼級別分析了 RokcetMQ 和 Kafka 的訊息推拉,以及推拉模式的優缺點。
## Consumer 端的負載均衡機制
Consumer 會定期的獲取 Topic 下的佇列數,然後再去查詢訂閱了該 Topic 的同一消費組的所有消費者資訊,預設的分配策略是類似分頁排序分配。
將佇列排好序,然後消費者排好序,比如佇列有 9 個,消費者有 3 個,那消費者-1 消費佇列 0、1、2 的訊息,消費者-2 消費佇列 3、4、5,以此類推。
所以如果負載太大,那麼就加佇列,加消費者,通過負載均衡機制就可以感知到重平衡,均勻負載。
## Consumer 訊息消費的重試
難免會遇到訊息消費失敗的情況,所以需要提供消費失敗的重試,而一般的消費失敗要麼就是訊息結構有誤,要麼就是一些暫時無法處理的狀態,所以立即重試不太合適。
RocketMQ 會給**每個消費組**都設定一個重試佇列,Topic 是 `%RETRY%+consumerGroup`,並且設定了很多重試級別來延遲重試的時間。
為了利用 RocketMQ 的延時佇列功能,重試的訊息會先儲存在 Topic 名稱為“SCHEDULE_TOPIC_XXXX”的延遲佇列,在訊息的擴充套件欄位裡面會儲存原來所屬的 Topic 資訊。
delay 一段時間後再恢復到重試佇列中,然後 Consumer 就會消費這個重試佇列主題,得到之前的訊息。
如果超過一定的重試次數都消費失敗,則會移入到死信佇列,即 Topic `%DLQ%" + ConsumerGroup` 中,儲存死信佇列即認為消費成功,因為實在沒轍了,暫時放過。
然後我們可以通過人工來處理死信佇列的這些訊息。
## 訊息的全域性順序和區域性順序
全域性順序就是消除一切併發,一個 Topic 一個佇列,Producer 和 Consuemr 的併發都為一。
區域性順序其實就是指某個佇列順序,多佇列之間還是能並行的。
可以通過 MessageQueueSelector 指定 Producer 某個業務只發這一個佇列,然後 Comsuer 通過MessageListenerOrderly 接受訊息,其實就是加鎖消費。
在 Broker 會有一個 mqLockTable ,順序訊息在建立拉取訊息任務的時候需要在 Broker 鎖定該訊息佇列,之後加鎖成功的才能消費。
而嚴格的順序訊息其實很難,假設現在都好好的,如果有個 Broker 宕機了,然後發生了重平衡,佇列對應的消費者例項就變了,就會有可能會出現亂序的情況,如果要保持嚴格順序,那此時就只能讓整個叢集不可用了。
## 一些注意點
1、訂閱訊息是以 ConsumerGroup 為單位儲存的,所以ConsumerGroup 中的每個 Consumer 需要有相同的訂閱。
因為訂閱訊息是隨著心跳上傳的,如果一個 ConsumerGroup 中 Consumer 訂閱資訊不一樣,那麼就會出現互相覆蓋的情況。
比如消費者 A 訂閱 Topic a,消費者 B 訂閱 Topic b,此時消費者 A 去 Broker 拿訊息,然後 B 的心跳包發出了,Broker 更新了,然後接到 A 的請求,一臉懵逼,沒這訂閱關係啊。
2、RocketMQ 主從讀寫分離
從只能讀,不能寫,並且只有當前客戶端讀的 offset 和 當前 Broker 已接受的最大 offset 超過限制的實體記憶體大小時候才會去從讀,所以**正常情況下從分擔不了流量**
3、單單加機器提升不了消費速度,佇列的數量也需要跟上。
4、之前提到的,不要允許自動建立主題
## RocketMQ 的最佳實踐
這些最佳實踐部分參考自官網。
### Tags的使用
建議一個應用一個 Topic,利用 tages 來標記不同業務,因為 tages 設定比較靈活,且一個應用一個 Topic 很清晰,能直觀的辨別。
### Keys的使用
如果有訊息業務上的唯一標識,請填寫到 keys 欄位中,方便日後的定位查詢。
## 提高 Consumer 的消費能力
1、提高消費並行度:增加佇列數和消費者數量,提高單個消費者的並行消費執行緒,引數 consumeThreadMax。
2、批處理消費,設定 consumeMessageBatchMaxSize 引數,這樣一次能拿到多條訊息,然後比如一個 update語句之前要執行十次,現在一次就執行完。
3、跳過非核心的訊息,當負載很重的時候,為了保住那些核心的訊息,設定那些非核心的訊息,例如此時訊息堆積 1W 條了之後,就直接返回消費成功,跳過非核心訊息。
## NameServer 的定址
請使用 HTTP 靜態伺服器定址(預設),這樣 NameServer 就能動態發現。
## JVM選項
以下抄自官網:
如果不關心 RocketMQ Broker的啟動時間,通過“預觸控” Java 堆以確保在 JVM 初始化期間每個頁面都將被分配。
那些不關心啟動時間的人可以啟用它: -XX:+AlwaysPreTouch
禁用偏置鎖定可能會減少JVM暫停, -XX:-UseBiasedLocking
至於垃圾回收,建議使用帶JDK 1.8的G1收集器。
> -XX:+UseG1GC -XX:G1HeapRegionSize=16m
-XX:G1ReservePercent=25
-XX:InitiatingHeapOccupancyPercent=30
另外不要把-XX:MaxGCPauseMillis的值設定太小,否則JVM將使用一個小的年輕代來實現這個目標,這將導致非常頻繁的minor GC,所以建議使用rolling GC日誌檔案:
>-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=30m
## Linux核心引數
以下抄自官網:
* **vm.extra_free_kbytes**,告訴VM在後臺回收(kswapd)啟動的閾值與直接回收(通過分配程序)的閾值之間保留額外的可用記憶體。RocketMQ使用此引數來避免記憶體分配中的長延遲。(與具體核心版本相關)
* **vm.min_free_kbytes**,如果將其設定為低於1024KB,將會巧妙的將系統破壞,並且系統在高負載下容易出現死鎖。
* **vm.max_map_count**,限制一個程序可能具有的最大記憶體對映區域數。RocketMQ將使用mmap載入CommitLog和ConsumeQueue,因此建議將為此引數設定較大的值。(agressiveness --> aggressiveness)
* **vm.swappiness**,定義核心交換記憶體頁面的積極程度。較高的值會增加攻擊性,較低的值會減少交換量。建議將值設定為10來避免交換延遲。
* **File descriptor limits**,RocketMQ需要為檔案(CommitLog和ConsumeQueue)和網路連線開啟檔案描述符。我們建議設定檔案描述符的值為655350。
* [Disk scheduler](https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/ch06s04s02.html),RocketMQ建議使用I/O截止時間排程器,它試圖為請求提供有保證的延遲。
## 最後
其實還有很多沒講,比如流量控制、訊息的過濾、定時訊息的實現,包括底層通訊 1+N+M1+M2 的 Reactor 多執行緒設計等等。
主要是內容太多了,而且也不太影響主流程,所以還是剝離出來之後寫吧,大致的一些實現還是講了的。
包括元資訊的互動、訊息的傳送、儲存、消費等等。
關於事務訊息的那一塊我之前文章也分析過了,所以這個就不再貼了。
可以看到要實現一個生產級別的訊息佇列還是有很多很多東西需要考慮的,不過大致的架構和涉及到的模組差不多就這些了。
至於具體的細節深入,還是得靠大家自行研究了,我就起個拋磚引玉的作用。
最後個人能力有限,如果哪裡有紕漏請抓緊聯絡鞭撻我,可看網頁公告聯絡我。
---
**我是 yes,從一點點到億點點,我們下篇