
Redis 用的很溜,瞭解過它用的什麼協議嗎?
阿新 • • 發佈:2020-11-24
> 我是風箏,公眾號「古時的風箏」,一個兼具深度與廣度的程式設計師鼓勵師,一個本打算寫詩卻寫起了程式碼的田園碼農!
文章會收錄在 [JavaNewBee](https://github.com/huzhicheng/JavaNewBee) 中,更有 Java 後端知識圖譜,從小白到大牛要走的路都在裡面。
有個小夥伴面試回來說面試官問了他一些 Redis 問題,但是他好像沒有回答上來。
我說,你 Redis 不是用的很溜嗎,什麼問題難住你了。
他說,事情是這樣的,剛開始,問了一些基礎的問題,比如 Redis 的幾種基本資料型別和使用場景,以及主從複製和叢集的一些問題,這些都還好。
然後問 Redis 的兩種持久化方式,我說與 RDB 和 AOF 兩種方式,RDB 資料檔案小,恢復速度快,但是對效能有影響,而且不適合實時儲存。而 AOF 是現在最常用的持久化方式,它的一大優點就是實時性,並且對 Redis 半身效能影響最小。
那面試又問了,你知道 AOF 持久化之後的檔案是什麼格式嗎?
答:好像就是文字檔案吧?
好,文字檔案,那你知道它有什麼規則嗎?或者說,它和 Redis 的協議有什麼關係嗎?
答:啊,這個,恩,不太清楚呢。
**現在就來看一下 AOF 和 RESP 協議的關係**
1. 從兩種持久化方式說起。
2. RESP 協議是什麼
3. 動手實現一個簡單的協議解析命令列工具
先從持久化說起,雖然一提到 Redis,首先想到的就是快取,但是 Redis 不僅僅是快取這麼簡單,它的定位是記憶體型資料庫,可以儲存多種型別的資料結構,還可以當做簡單訊息佇列使用。既然是資料庫,持久化功能是必不可少的。
## Redis 的兩種持久化方式
Redis 提供了兩種持久化方式,一種是 RDB 方式,另外一種是 AOF 方式,AOF 是目前比較流行的持久化方案。
### RDB 方式
RDB持久化是通過快照的方式,在指定的時間間隔內將記憶體中的資料集快照寫入磁碟。它以一種緊湊壓縮的二進位制檔案的形式出現。可以將快照複製到其他伺服器以建立相同資料的伺服器副本,或者在重啟伺服器後恢復資料。RDB是Redis預設的持久化方式,也是早期版本的必須方案。
RDB 由下面幾個引數控制。
```shell
# 設定 dump 的檔名
dbfilename dump.rdb
# 持久化檔案的儲存目錄
dir ./
# 900秒內,如果至少有1個key發生變化,就會自動觸發bgsave命令建立快照
save 900 1
# 300秒內,如果至少有10個key發生變化,就會自動觸發bgsave命令建立快照
save 300 10
# 60秒內,如果至少有10000個key發生變化,就會自動觸發bgsave命令建立快照
save 60 10000
```
#### 持久化流程
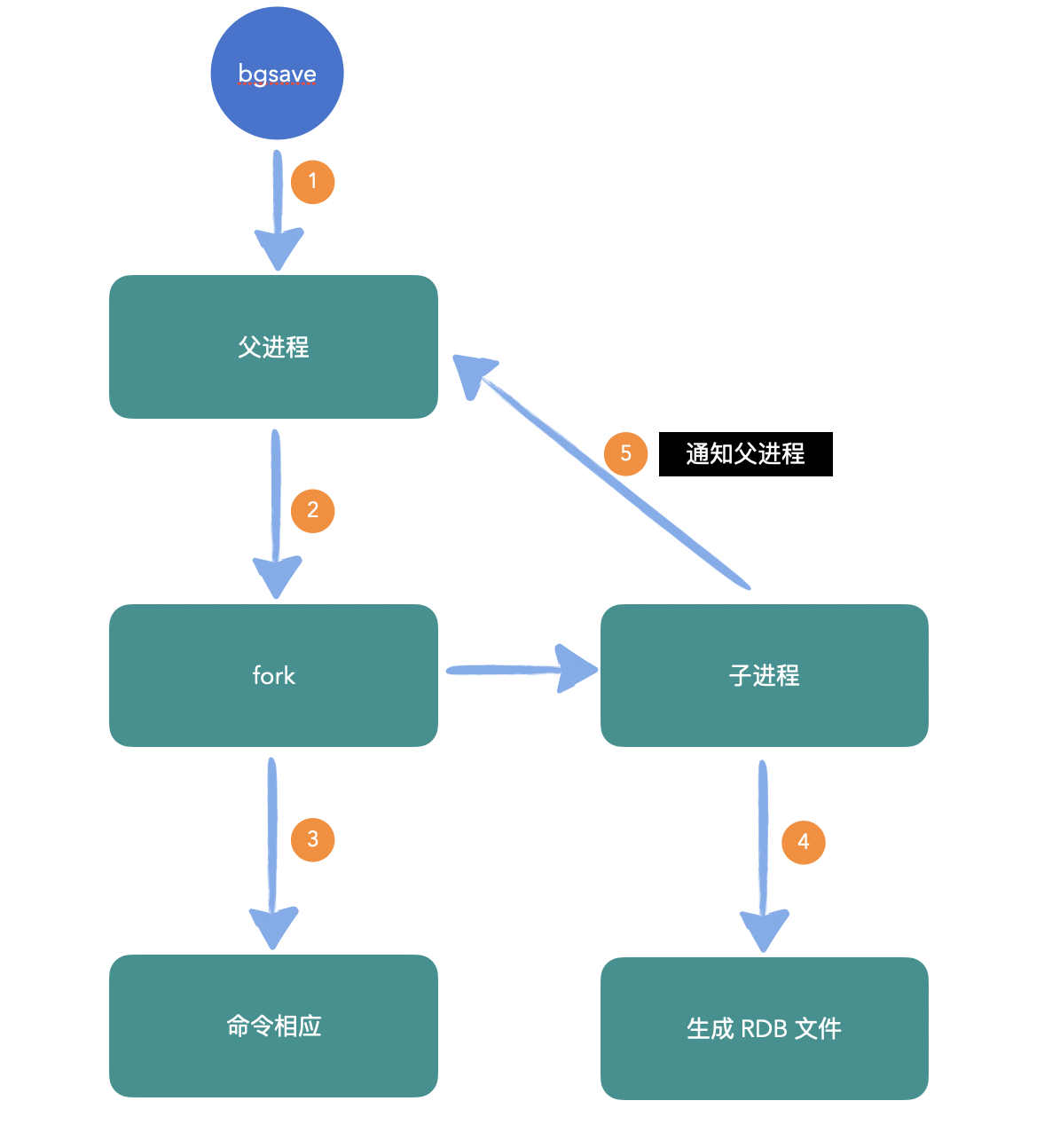
上面說到了配置檔案中的幾個觸發持久化的機制,比如 900 秒、300秒、60秒,當然也可以手動執行命令 `save`或`bgsave`進行觸發。`bgsave`是非阻塞版本,通過 fork 出子程序的方式來進行快照生成,而 `save`會阻塞主程序,不建議使用。
1、首先 `bgsave`命令觸發;
2、父程序 fork 出一個子程序,這一步是比較重量級的操作,也是 RDB 方式效能不及 AOF 的一個重要原因;
3、父程序 fork 出子程序後就可以正常的相應客戶端發來的其他命令了;
4、子程序開始進行持久化工作,對現有資料進行完整的快照儲存;
5、子程序完成操作後,通知父程序;
#### RDB的優點:
- RDB是一個緊湊壓縮的二進位制檔案,代表Redis在某個時間點上的資料 快照。非常適用於備份,全量複製等場景。比如每6小時執行bgsave備份, 並把RDB檔案拷貝到遠端機器或者檔案系統中(如hdfs),用於災難恢復。
- Redis載入RDB恢復資料遠遠快於AOF的方式。
#### RDB的缺點:
- RDB方式資料沒辦法做到實時持久化/秒級持久化。因為bgsave每次運 行都要執行fork操作建立子程序,屬於重量級操作,頻繁執行成本過高。
- RDB檔案使用特定二進位制格式儲存,Redis版本演進過程中有多個格式 的RDB版本,存在老版本Redis服務無法相容新版RDB格式的問題。
### AOF 方式
AOF 由下面幾個引數控制。
```shell
# appendonly引數開啟AOF持久化
appendonly yes
# AOF持久化的檔名,預設是appendonly.aof
appendfilename "appendonly.aof"
# AOF檔案的儲存位置和RDB檔案的位置相同,都是通過dir引數設定的
dir ./
# 同步策略
# appendfsync always
appendfsync everysec
# appendfsync no
# aof重寫期間是否同步
no-appendfsync-on-rewrite no
# 重寫觸發配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 載入aof出錯如何處理
aof-load-truncated yes
# 檔案重寫策略
aof-rewrite-incremental-fsync yes
```
針對RDB不適合實時持久化的問題,Redis提供了AOF 持久化方式來解決,AOF 也是目前最流程的持久化方式。
AOF(append only file),以獨立日誌的方式記錄每次寫命令, 重啟時再重新執行AOF檔案中的命令達到恢復資料的目的。
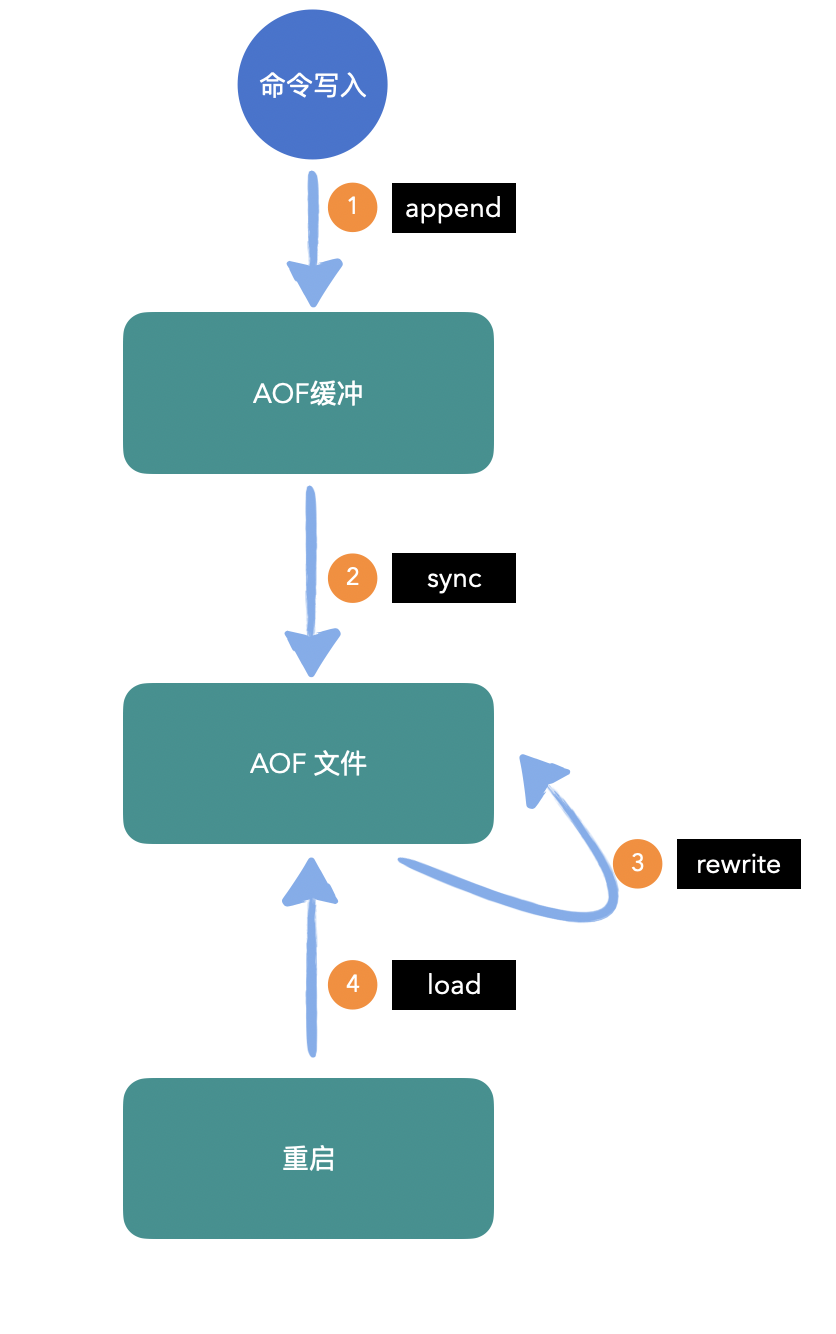
1、所有的寫入命令會追加到aof_buf(緩衝區)中;
2、AOF緩衝區根據對應的策略向硬碟做同步操作;
3、隨著AOF檔案越來越大,需要定期對AOF檔案進行重寫,達到壓縮的目的;
4、當Redis伺服器重啟時,可以載入AOF檔案進行資料恢復;
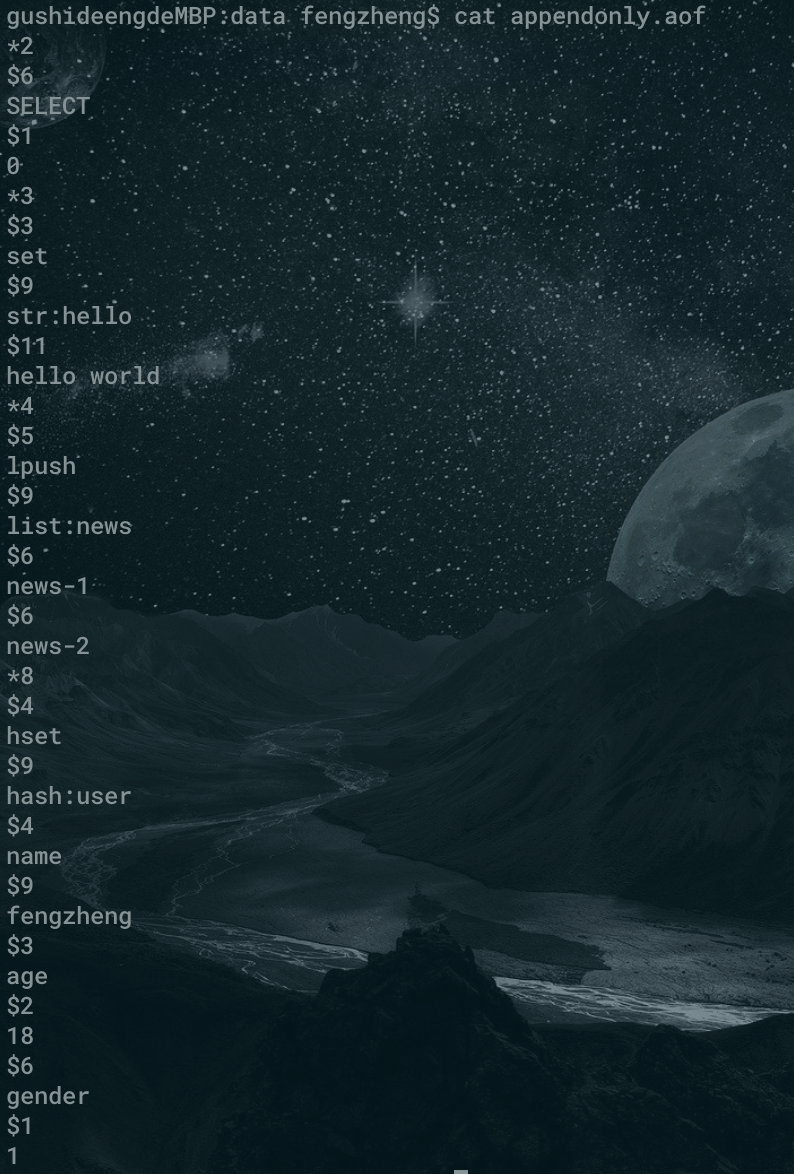
#### AOF 檔案裡存的是什麼
我在本地的測試 redis 環境中隨便刷了幾條命令,然後開啟 appendonly.aof 檔案檢視,發現裡面的內容像下面這樣子。
## RESP 協議
Redis客戶端與服務端通訊,使用 RESP 協議通訊,該協議是專門為 Redis 設計的通訊協議,但也可以用於其它客戶端-伺服器通訊的場景。
RESP 協議有如下幾個特點:
- 實現簡單;
- 快速解析;
- 可閱讀;
客戶端傳送命令給服務端,服務端拿到命令後進行解析,然後執行對應的邏輯,之後返回給客戶端,當然了,這一發一回復都是用的 RESP 協議特點的格式。
一般情況下我們會使用 `redis-cli`或者一些客戶端工具連線 Redis 服務端。
```shell
./redis-cli
```
然後整個互動過程的命令傳送和返回結果像下面這樣,綠色部分為傳送的命令,紅色部分為返回的結果。

這就是我們再熟悉不過的部分了。但是,這並不能看出 RESP 協議的真實面貌。
### 用 telnet 試試
RESP 是基於 TCP 協議實現的,所以除了用各種客戶端工具以及 Redis 提供的 `redis-cli`工具,還可以用 telnet 檢視,用 telnet 就可以看出 RESP 返回的原始資料格式了。
我本地的 Redis 是用的預設 6379 埠,並且沒有設定 requirepass ,我們來試一下用 telnet 連線。
```shell
telnet 127.0.0.1 6379
```
然後執行與前面相同的幾條命令,傳送和返回的結果如下,綠色部分為傳送的命令,紅色為返回的結果。

怎麼樣,有些命令的返回還好,但是像`get str:hello`這條,返回的結果除了 `world`值本身,上面還多了一行 `$5`,是不是有點迷糊了。
### 協議規則
#### 請求命令
一條客戶端發往伺服器的命令的規則如下:
```shell
*<引數數量> CR LF
$<引數 1 的位元組數量> CR LF
<引數 1 的資料> CR LF
...
$<引數 N 的位元組數量> CR LF
<引數 N 的資料> CR LF
```
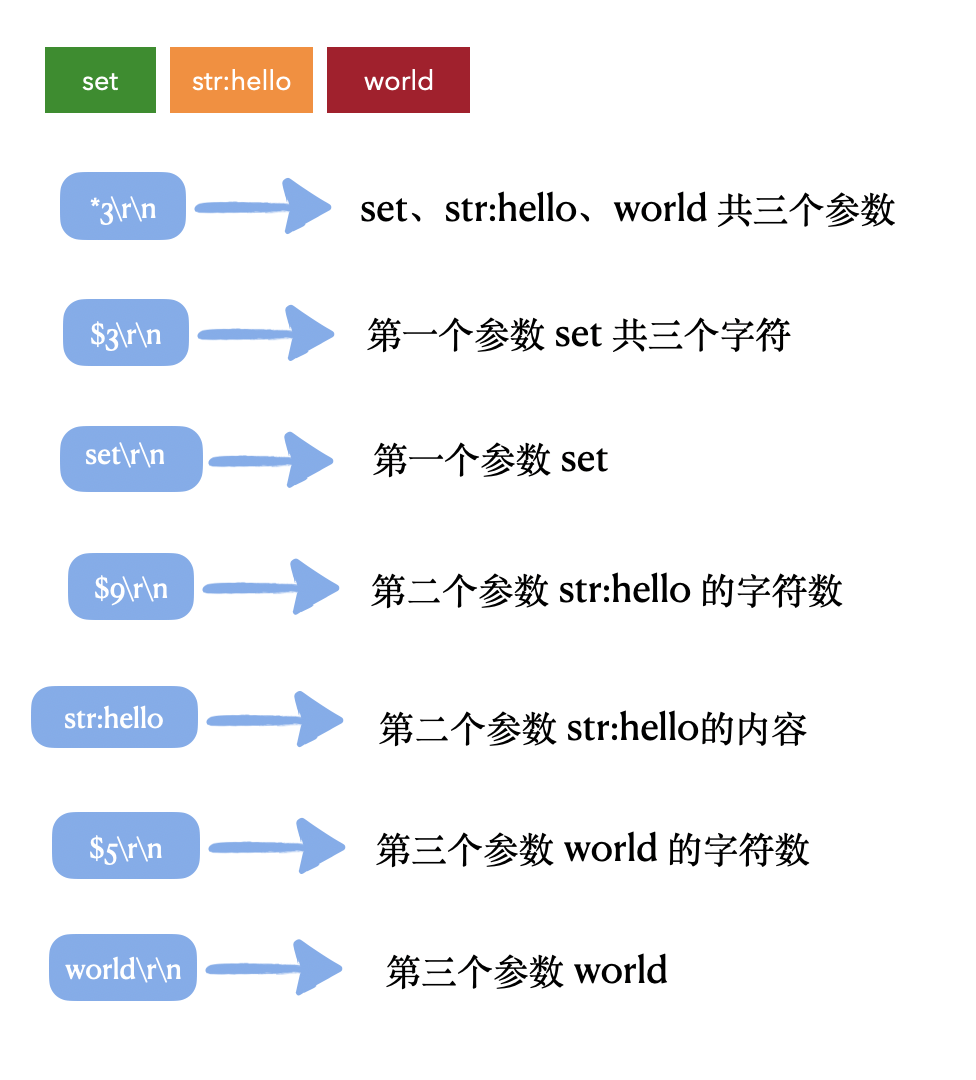
RESP 用`\r\n`作為分隔符,會表明此條命令的具體引數個數,在命令上看來,空格分隔的都表示一個引數,例如 `set str:hello world` 這條命令就是3個引數,會表明每個引數的字元數和具體內容。
用這條命令舉例,對應到 RESP 協議規則上就會變成下面這個樣子:
```
*3\r\n$3\r\nset\r\n$9str:hello\r\n$5world\r\n
```
#### 服務端回覆
Redis 命令會返回多種不同型別的回覆。
通過檢查伺服器發回資料的第一個位元組, 可以確定這個回覆是什麼型別:
1、狀態回覆(status reply)的第一個位元組是 `"+"`
比如 `ping`命令的回覆,`+PONG\r\n`
2、錯誤回覆(error reply)的第一個位元組是 `"-"`
比如輸入一個 redis 中不存在的命令,或者給某些命令設定錯誤的引數,例如輸入 `auth`,auth 命令後面需要有一個密碼引數的,如果不輸入就會返回錯誤回覆型別。
`-ERR wrong number of arguments for 'auth' command\r\n`
3、整數回覆(integer reply)的第一個位元組是 `":"`
例如 `INCR`、`DECR` 自增自減命令,返回的結果是這樣的 `:2\r\n`
4、批量回復(bulk reply)的第一個位元組是 `"$"`
例如對 string 型別執行 get 操作,`$5\r\nworld\r\n`,`$`後面的數字 5 表示返回的結果有 5 個字元,後面是返回結果的實際內容。
5、多條批量回復(multi bulk reply)的第一個位元組是 `"*"`
例如 `LRANGE key start stop`或者 `hgetall`等返回多條結果的命令,比如 `lrange`命令返回的結果:
```
*2\r\n$6\r\nnews-2\r\n$6\r\nnews-1\r\n
```
多條批量回復和前面說的客戶端傳送命令的格式是一致的。
## 實現一個簡單的 Redis 互動工具
瞭解了 Redis 的協議規則,我們就可以自己寫一個簡單的客戶端了。當然,通過官網我們可以看到已經有各種語言,而且每種語言有不止一個客戶端工具了。

比如 Java 語言的客戶端就有這麼多種,其中 Jedis 應該是用的最多了,既然已經有這麼好用的輪子了,當然沒必要重複造輪子,主要還是為了加深印象。
RESP 協議基於 TCP 協議,可以使用 socket 方式進行連線。
```java
public Socket createSocket() throws IOException {
Socket socket = null;
try {
socket = new Socket();
socket.setReuseAddress(true);
socket.setKeepAlive(true);
socket.setTcpNoDelay(true);
socket.setSoLinger(true, 0);
socket.connect(new InetSocketAddress(host, port), DEFAULT_TIMEOUT);
socket.setSoTimeout(DEFAULT_TIMEOUT);
outputStream = socket.getOutputStream();
inputStream = socket.getInputStream();
return socket;
} catch (Exception ex) {
if (socket != null) {
socket.close();
}
throw ex;
}
}
```
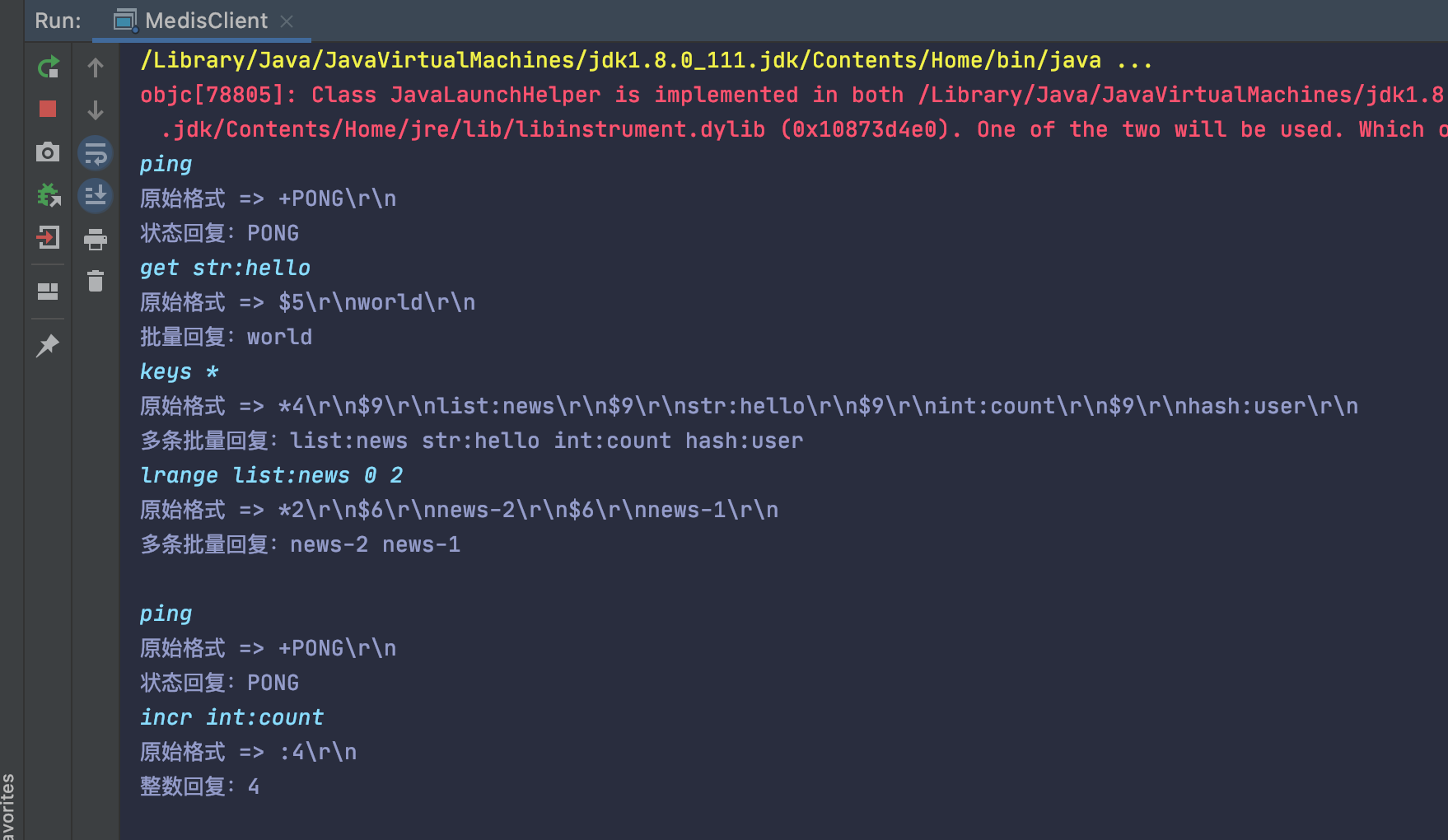
然後剩下的就是對返回的結果進行字串的解析了,我做的工具就到簡陋的到這一步了,下面是一些簡單命令的返回輸出。
> 程式碼已放到 github 上,有興趣的可以 clone 下來看一下。
>
> https://github.com/huzhicheng/medis
***
**這位英俊瀟灑的少年,如果覺得還不錯的話,給個推薦可好!**
公眾號「古時的風箏」,Java 開發者,全棧工程師,bug 殺手,擅長解決問題。
一個兼具深度與廣度的程式設計師鼓勵師,本打算寫詩卻寫起了程式碼的田園碼農!堅持原創乾貨輸出,你可選擇現在就關注我,或者看看歷史文章再關注也不遲。長按二維碼關注,跟我一起變優秀!
![](https://img2020.cnblogs.com/blog/273364/202008/273364-20200807093211558-1258890