
樸素貝葉斯分類-實戰篇-如何進行文字分類
阿新 • • 發佈:2020-11-25
> **微信公眾號:碼農充電站pro**
> **個人主頁:**
上篇介紹了[樸素貝葉斯的原理](https://www.cnblogs.com/codeshell/p/13999440.html),本篇來介紹如何用樸素貝葉斯解決實際問題。
樸素貝葉斯最擅長的領域是文字分析,包括:
- 文字分類
- 情感分析
- 垃圾郵件處理
要對文字進行分類,首先要做的是如何提取文字的主要資訊,如何衡量哪些資訊是文字中的主要資訊呢?
### 1,對文件分詞
我們知道,一篇文件是由若干**詞彙**組成的,也就是文件的主要資訊是詞彙。從這個角度來看,我們就可以用一些**關鍵詞**來描述文件。
這種處理文字的方法叫做**詞袋**(bag of words)模型,該模型會忽略文字中的詞語出現的順序以及相應的語法,將文件看做是由若干單片語成的,且單詞之間互相獨立,沒有關聯。
要想提取文件中的關鍵詞,就得先對文件進行分詞。分詞方法一般有兩種:
- 第一種是基於字串匹配。就是掃描字串。如果發現字串的子串和詞相同,就算匹配成功。
- 匹配規則一般有“正向最大匹配”,“逆向最大匹配”,“長詞優先”等。
- 該類演算法的優點是隻需基於字典匹配,演算法簡單;缺點是沒有考慮詞義,處理歧義詞效果不佳。
- 第二種是基於統計和機器學習。需要人工標註詞性和統計特徵,對中文進行建模。
- 先要訓練分詞模型,然後基於模型進行計算概率,取概率最大的分詞作為匹配結果。
- 常見的序列標註模型有**隱馬爾科夫模型**和**條件隨機場**。
**停用詞**是一些非常普遍使用的詞語,對文件分析作用不大,在文件分析之前需要將這些詞去掉。比如:
- 中文停用詞:“你,我,他,它,的,了” 等。
- 英文停用詞:“is,a,the,this,that” 等。
- 停用詞檔案:停用詞一般儲存在檔案中,需要自行讀取。
另外分詞階段,還需要處理**同義詞**,很多時候一件東西有多個不同的名字。比如“番茄”和“西紅柿”,“鳳梨”和“菠蘿”等。
中文分詞與英文分詞是不同的,我們分別介紹一個著名的分詞包:
- 中文分詞:[jieba](https://github.com/fxsjy/jieba/) 分詞比較常用,其中包含了中文的停用詞等。
- 英文分詞:[NTLK](http://www.nltk.org/) 比較常用,其中包含了英文的停用詞等。
### 2,計算單詞權重
哪些關鍵詞對一個文件才是重要的?比如可以通過單詞出現的**次數**,次數越多就表示越重要。
更合理的方法是計算單詞的`TF-IDF` 值。
#### 2.1,單詞的 TF-IDF 值
單詞的`TF-IDF` 值可以描述一個單詞對文件的重要性,`TF-IDF` 值越大,則越重要。
- **TF**:全稱是`Term Frequency`,即詞頻(單詞出現的頻率),也就是一個單詞在文件中出現的**次數**,次數越多越重要。
- 計算公式:`一個單詞的詞頻TF = 單詞出現的次數 / 文件中的總單詞數`
- **IDF**:全稱是`Inverse Document Frequency`,即逆向文件詞頻,是指一個單詞在文件中的區分度。它認為一個**單詞**出現在的**文件數**越少,這個單詞對該文件就越重要,就越能通過這個單詞把該文件和其他文件區分開。
- 計算公式:` 一個單詞的逆向文件頻率 IDF = log(文件總數 / 該單詞出現的文件數 + 1) `
- 為了避免分母為0(有些單詞可能不在文件中出現),所以在分母上加1
---

---
> ,
norm='l2',
use_idf=True,
smooth_idf=True,
sublinear_tf=False)
```
常用的引數有:
- `input`:有三種取值:
- filename
- file
- content:預設值為`content`。
- `analyzer`:有三種取值,分別是:
- word:預設值為`word`。
- char
- char_wb
- `stop_words`:表示停用詞,有三種取值:
- `english`:會載入[自帶英文停用詞](http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words)。
- `None`:沒有停用詞,預設為`None`。
- `List`型別的物件:需要使用者自行載入停用詞。
- 只有當引數 `analyzer == 'word'` 時才起作用。
- `token_pattern`:表示過濾規則,是一個正則表示式,不符合正則表示式的單詞將會被過濾掉。
- 注意預設的 `token_pattern` 值為 `r'(?u)\b\w\w+\b'`,匹配兩個以上的字元,如果是一個字元則匹配不上。
- 只有引數 `analyzer == 'word'` 時,正則才起作用。
- `max_df`:用於描述單詞在文件中的最高出現率,取值範圍為 `[0.0~1.0]`。
- 比如 `max_df=0.6`,表示一個單詞在 60% 的文件中都出現過,那麼認為它只攜帶了非常少的資訊,因此就不作為分詞統計。
- `mid_df`:單詞在文件中的最低出現率,一般不用設定。
常用的**方法**有:
- `t.fit(raw_docs)`:用`raw_docs` 擬合模型。
- `t.transform(raw_docs)`:將 `raw_docs` 轉成矩陣並返回,其中包含了每個單詞在每個文件中的 TF-IDF 值。
- `t.fit_transform(raw_docs)`:可理解為先 `fit` 再 `transform`。
在上面三個方法中:
- `t` 表示 `TfidfVectorizer` 物件。
- `raw_docs` 引數是一個可遍歷物件,其中的每個元素表示一個文件。
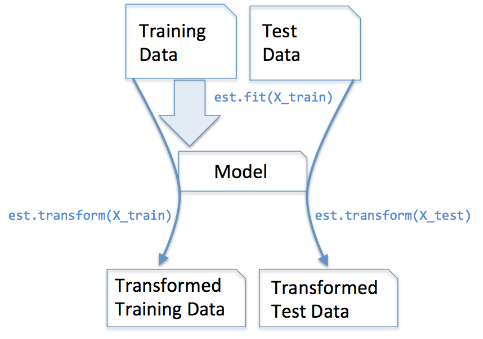
***`fit_transform` 與 `transform` 的用法***
- 一般在擬合轉換資料時,先處理**訓練集**資料,再處理**測試集**資料。
- 訓練集資料會用於擬合模型,而測試集資料不會用於擬合模型。所以:
- `fit_transform` 用於訓練集資料。
- `transform` 用於測試集資料,且 `transform` 必須在 `fit_transform` 之後。
- 如果測試集資料也用 `fit_transform` 方法,則會造成過擬合。
下圖表達的很清晰明瞭:
所以一般的使用步驟是:
```python
# x 為 DictVectorizer,DictVectorizer 等類的物件
# 用於特徵提取
x = XXX()
train_features = x.fit_transform(train_datas)
test_features = x.transform(test_datas)
```
#### 2.3,一個例子
比如我們有如下3 個文件(`docs` 的每個元素表示一個文件):
```python
docs = [
'I am a student.',
'I live in Beijing.',
'I love China.',
]
```
我們用 `TfidfVectorizer` 類來計算TF-IDF 值:
```python
from sklearn.feature_extraction.text import TfidfVectorizer
t = TfidfVectorizer() # 使用預設引數
```
用 `fit_transform()` 方法擬合模型,反回矩陣:
```python
t_matrix = t.fit_transform(docs)
```
用 `get_feature_names()` 方法獲取所有不重複的特徵詞:
```python
>>> t.get_feature_names()
['am', 'beijing', 'china', 'in', 'live', 'love', 'student']
```
> 不知道你有沒有發現,這些特徵詞中不包含`i` 和 `a` ?你能解釋一下是為什麼嗎?
用`vocabulary_` 屬性獲取特徵詞與`ID` 的對應關係:
```python
>>> t.vocabulary_
{'am': 0, 'student': 6, 'live': 4, 'in': 3, 'beijing': 1, 'love': 5, 'china': 2}
```
用 **矩陣物件**的`toarray()` 方法輸出 `TF-IDF` 值:
```python
>>> t_matrix.toarray()
array([
[0.70710678, 0. , 0. , 0. , 0. , 0. , 0.70710678],
[0. , 0.57735027, 0. , 0.57735027, 0.57735027, 0. , 0. ],
[0. , 0. , 0.70710678, 0. , 0. , 0.70710678, 0. ]
])
```
### 3,sklearn 樸素貝葉斯的實現
sklearn 庫中的 **naive_bayes** 模組實現了 5 種**樸素貝葉斯**演算法:
1. `naive_bayes.BernoulliNB` 類:**伯努利樸素貝葉斯**的實現。
- 適用於離散型資料,適合特徵變數是布林變數,符合 0/1 分佈,在文件分類中特徵是**單詞是否出現**。
- 該演算法**以檔案為粒度**,如果該單詞在某檔案中出現了即為 1,否則為 0。
2. `naive_bayes.CategoricalNB` 類:**分類樸素貝葉斯**的實現。
3. `naive_bayes.GaussianNB` 類:**高斯樸素貝葉斯**的實現。
- 適用於特徵變數是連續型資料,符合高斯分佈。比如說人的身高,物體的長度等,這種**自然界物體**。
4. `naive_bayes.MultinomialNB` 類:**多項式樸素貝葉斯**的實現。
- 適用於特徵變數是離散型資料,符合多項分佈。在文件分類中特徵變數體現在一個單詞出現的次數,或者是單詞的 TF-IDF 值等。
5. `naive_bayes.ComplementNB` 類:**補充樸素貝葉斯**的實現。
- 是多項式樸素貝葉斯演算法的一種改進。
> 每個類名中的**NB** 字尾是 **Naive Bayes** 的縮寫,即表示**樸素貝葉斯**。
各個類的原型如下:
```python
BernoulliNB(*, alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
CategoricalNB(*, alpha=1.0, fit_prior=True, class_prior=None)
GaussianNB(*, priors=None, var_smoothing=1e-09)
MultinomialNB(*, alpha=1.0, fit_prior=True, class_prior=None)
ComplementNB(*, alpha=1.0, fit_prior=True, class_prior=None, norm=False)
```
構造方法中的`alpha` 的含義為**平滑引數**:
- 如果一個單詞在訓練樣本中沒有出現,這個單詞的概率就會是 0。但訓練集樣本只是整體的抽樣情況,不能因為沒有觀察到,就認為整個事件的概率為 0。為了解決這個問題,需要做平滑處理。
- 當 alpha=1 時,使用的是 Laplace 平滑。Laplace 平滑就是採用加 1 的方式,來統計沒有出現過的單詞的概率。這樣當訓練樣本很大的時候,加 1 得到的概率變化可以忽略不計。
- 當 0>> joblib.dump(clf, 'nb.pkl')
['nb.pkl']
>>> joblib.dump(tf, 'tf.pkl')
['tf.pkl']
```
使用模型程式碼如下:
```python
import jieba
import warnings
from sklearn.externals import joblib
warnings.filterwarnings('ignore')
MODEL = None
TF = None
def load_model(model_path, tf_path):
global MODEL
global TF
MODEL = joblib.load(model_path)
TF = joblib.load(tf_path)
def nb_predict(title):
assert MODEL != None and TF != None
words = jieba.cut(title)
s = ' '.join(words)
test_features = TF.transform([s])
predicted_labels = MODEL.predict(test_features)
return predicted_labels[0]
if __name__ == '__main__':
# 載入模型
load_model('nb.pkl', 'tf.pkl')
# 測試
print nb_predict('東莞市場採購貿易聯網資訊平臺參加部委首批聯合驗收')
print nb_predict('留在中超了!踢進生死戰決勝一球,武漢卓爾保級成功')
print nb_predict('陳思誠全新系列電影《外太空的莫扎特》首曝海報 黃渤、榮梓杉演父子')
print nb_predict('紅薯的好處 常吃這種食物能夠幫你減肥')
```
其中:
- `load_model()` 函式用於載入模型。
- `nb_predict()` 函式用於對新聞標題進行預測,返回標題的型別。
### 6,總結
本篇文章介紹瞭如何利用**樸素貝葉斯**處理**文字分類**問題:
- 首先需要對文字進行分詞,常用的分詞包有:
- [jieba](https://github.com/fxsjy/jieba/) 用於中文分詞。
- [NTLK](http://www.nltk.org/) 用於英文分詞。
- 一些[中文停用詞](https://github.com/elephantnose/characters),供參考。
- 使用 `TfidfVectorizer` 計算單詞權重。
- 使用 `fit_transform` 方法提取**訓練集**特徵。
- 使用 `transform` 方法提取**測試集**特徵。
- 使用 `MultinomialNB` 類訓練模型,這裡給出了一個[實戰專案](https://github.com/codeshellme/codeshellme.github.io/tree/master/somecode/ml/naive_bayes/),供大家參考。
- 使用 [joblib](https://joblib.readthedocs.io) 儲存模型,方便模型的使用。
(本節完。)
---
**推薦閱讀:**
[***樸素貝葉斯分類-理論篇-如何通過概率解決分類問題***](https://www.cnblogs.com/codeshell/p/13999440.html)
[***決策樹演算法-理論篇-如何計算資訊純度***](https://www.cnblogs.com/codeshell/p/13948083.html)
[***決策樹演算法-實戰篇-鳶尾花及波士頓房價預測***](https://www.cnblogs.com/codeshell/p/13984334.html)
---
歡迎關注作者公眾號,獲取更多技術乾貨。
![碼農充電站pro](https://img-blog.csdnimg.cn/20200505082843773.png?#pic