
資料變換-歸一化與標準化
阿新 • • 發佈:2020-11-30
> **公號:碼農充電站pro**
> **主頁:**
一般在機器學習的**模型訓練**之前,有一個比較重要的步驟是**資料變換**。
因為,一般情況下,原始資料的各個特徵的值並不在一個統一的範圍內,這樣資料之間就沒有**可比性**。
資料變換的目的是**將不同渠道,不同量級的資料轉化到統一的範圍之內,方便後續的分析處理**。
資料變換的方法有很多,比如**資料平滑,資料聚集,資料概化,資料規範化**和**屬性構造**等。
本篇文章主要介紹資料規範化,這是一種比較常用,也比較簡單的方法。
資料規範化是**使屬性資料按比例縮放,這樣就將原來的數值對映到一個新的特定區域中**,包括**歸一化,標準化**等。
### 1,資料歸一化
歸一化就是獲取原始資料的最大值和最小值,然後把原始值線性變換到 **[0,1]** 範圍之內,變換公式為:
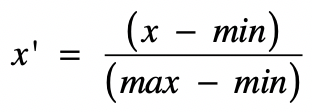
其中:
- `x` 是當前要變換的原始值。
- `min` 是當前特徵中的最小值。
- `max` 是當前特徵中的最大值。
- `x'` 是變換完之後的新值。
>