
計算機組成-無鎖程式設計追求極致效能
阿新 • • 發佈:2020-12-04
## 前言
現代計算機通常由`CPU`,以及主機板、記憶體、硬碟等主要硬體結構組成,而決定計算機效能的最核心部件是`CPU`+記憶體,`CPU`負責處理程式指令,記憶體負責儲存指令執行結果。在這個工作機制當中`CPU`的讀寫效率其實是遠遠高於記憶體的,為提升執行效率減少`CPU`與記憶體的互動,一般在`CPU`上設計了快取結構,常見的為三級快取結構:
- L1 Cache,分為資料快取和指令快取,邏輯核獨佔
- L2 Cache,物理核獨佔,邏輯核共享
- L3 Cache,所有物理核共享
下圖為`CPU-Core(TM)I7-10510U`型號快取結構
儲存器儲存空間大小:記憶體>L3>L2>L1>暫存器。
儲存器速度快慢排序:暫存器>L1>L2>L3>記憶體。
### 快取行大小
---
```shell
[root@192 ~]# getconf -a|grep CACHE
LEVEL1_ICACHE_SIZE 32768 #L1快取大小
LEVEL1_ICACHE_ASSOC 8 #L1快取行大小
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_ASSOC 8
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144 #L2快取大小
LEVEL2_CACHE_ASSOC 4
LEVEL2_CACHE_LINESIZE 64 #L2快取行大小
LEVEL3_CACHE_SIZE 8388608 #L3快取大小
LEVEL3_CACHE_ASSOC 16
LEVEL3_CACHE_LINESIZE 64 #L3快取行大小
LEVEL4_CACHE_SIZE 0
LEVEL4_CACHE_ASSOC 0
LEVEL4_CACHE_LINESIZE 0
[root@192 ~]# cat /proc/cpuinfo |grep -i cache
cache size : 8192 KB
cache_alignment : 64
cache size : 8192 KB
cache_alignment : 64
```
JAVA程式毫無疑問也必須是執行在硬體機器之上,如何利用底層硬體工作原理,提升效能也必然是我們需要考慮的,筆者今天以無鎖併發高效能框架`Disruptor`為例分析如何高效的利用CPU快取。
## Who is Disruptor?
Disruptor是一個開源框架,研發的初衷是為了解決高併發下**佇列**鎖的問題,最早由LMAX(一種新型零售金融交易平臺)提出並使用,能夠在**無鎖**的情況下實現佇列的併發操作,並號稱能夠在一個執行緒裡每秒處理6百萬筆訂單。
## 快取行填充
下方示例為`Disruptor`框架的內部程式碼:
```java
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
```
*分析:*
1. 變數p1~p7本身沒有實際意義,只能用於**快取行填充**,為了儘可能地用上**CPU Cache**!
2. 訪問CPU裡的L1 Cache或者L2 Cache、L3 Cache,訪問延時是記憶體的1/15乃至1/100(記憶體的訪問速度,是遠遠慢於CPU Cache的)
- 因此,為了追求極限效能,需要儘可能地從**CPU Cache**裡面讀取資料
3. CPU Cache裝載記憶體裡面的資料,不是一個個欄位載入的,而是載入一整個快取行
- 64位的Intel CPU,快取行通常是**64 Bytes**,一個long型別的資料需要8 Bytes,因此會一下子載入8個long型別的資料
- 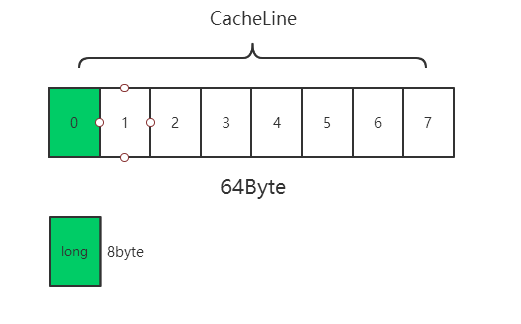
- 遍歷陣列元素速度很快,後面連續7次的資料訪問都會命中CPU Cache,不需要重新從記憶體裡面去讀取資料
### 快取行失效
**p1-p7僅用來填充快取行,我們跟本用不到它,但是我們為什麼要填充滿一個快取行呢?**
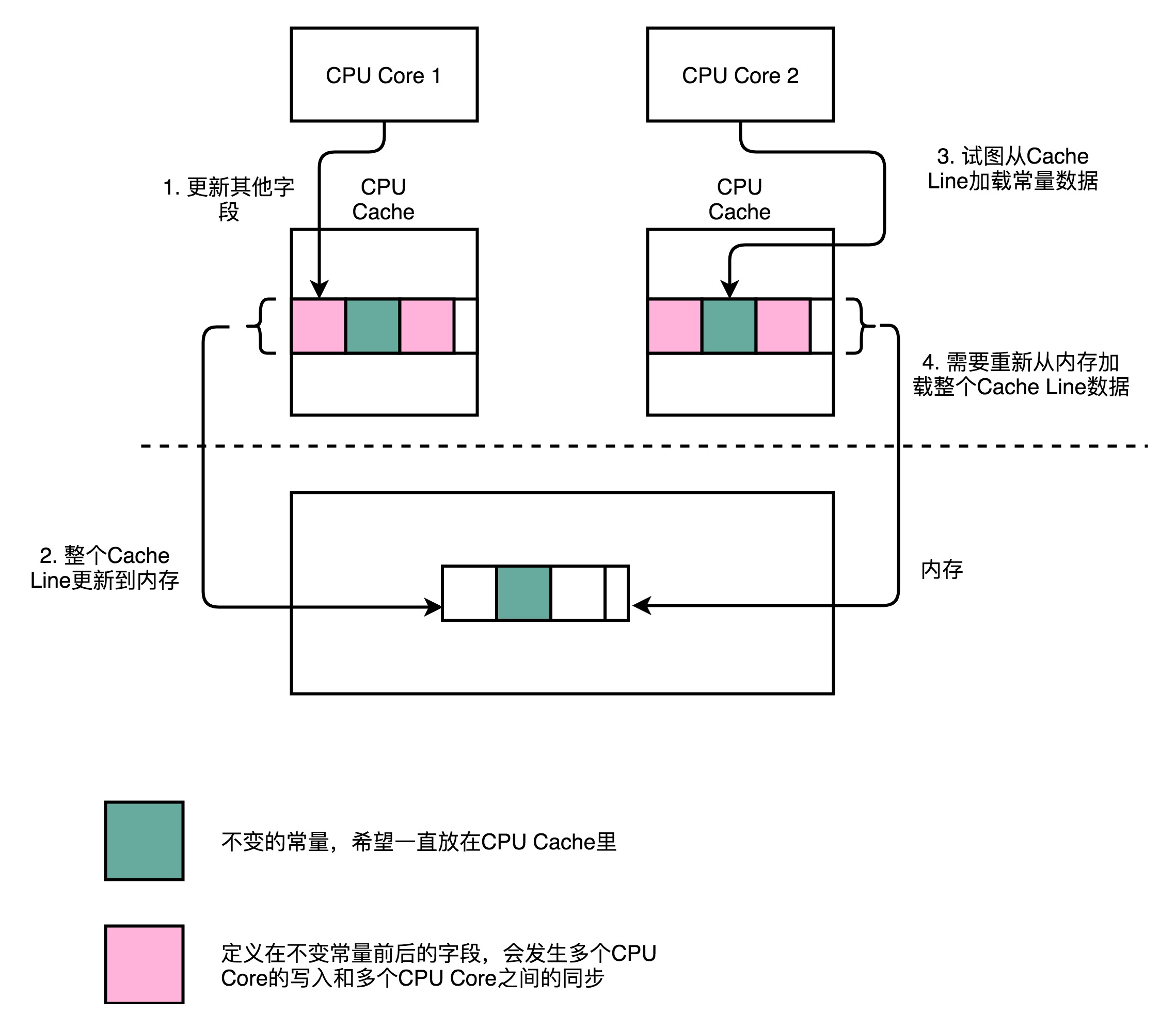
1. CPU在載入資料的時候,會把這個資料從**記憶體**載入到**CPU Cache**裡面
2. 此時,CPU Cache裡面除了這個資料,還會載入這個資料**前後定義**的其他變數
- 釋義:在高併發場景下,假定併發訪問變數p0,在p0後定義的其它變數也一併會被快取load
3. Disruptor是一個**多執行緒**的伺服器框架,在這個資料前後定義的其他變數,可能會被多個不同的執行緒去更新資料,讀取資料
- 這些寫入和讀取請求,可能會來自於**不同的CPU Core**
- 為了保證資料的**同步更新**,不得不把CPU Cache裡面的資料,**重新寫回**到記憶體裡面或者**重新**從記憶體裡面**載入**
- CPU Cache的**寫回**和**載入**,都是以整個**Cache Line**作為單位的
4. 如果常量的快取失效,當再次讀取這個值的時候,需要重新從**記憶體**讀取,讀取速度會大大**變慢**
### 快取行填充
```java
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBuff