
如何使用 K8s 兩大利器"審計"和"事件"幫你擺脫運維困境?
阿新 • • 發佈:2020-12-07
## 概述
下面幾個問題,相信廣大 K8s 使用者在日常叢集運維中都曾經遇到過:
- 叢集中的某個應用被刪除了,誰幹的?
- Apiserver 的負載突然變高,大量訪問失敗,叢集中到底發生了什麼?
- 叢集節點 NotReady,是什麼原因導致的?
- 叢集的節點發生了自動擴容,是什麼觸發的?什麼時間觸發的?
以前,排查這些問題,對客戶來說並不容易。生產環境中的 Kubernetes 叢集通常是一個相當複雜的系統,底層是各種異構的主機、網路、儲存等雲基礎設施,上層承載著大量的應用負載,中間執行著各種原生(例如:Scheduler、Kubelet)和第三方(例如:各種 Operator)的元件,負責對基礎設施和應用進行管理和排程; 此外不同角色的人員頻繁地在叢集上進行部署應用、新增節點等各種操作。在叢集執行的過程中,為了對叢集中發生的狀況能夠儘可能的瞭如指掌,我們通常會從多個維度對叢集進行觀測。
日誌,作為實現軟體可觀測性的三大支柱之一,為了解系統執行狀況,排查系統故障提供了關鍵的線索,在運維管理中起著至關重要的作用。Kubernetes 提供了兩種原生的日誌形式——審計(Audit)和事件(Event),它們分別記錄了對於叢集資源的訪問以及叢集中發生的事件資訊。從騰訊雲容器團隊長期運維 K8s 叢集的經驗來看,審計和事件並不是可有可無的東西,善用它們可以極大的提高叢集的可觀測性,為運維帶來巨大的便利。下面讓我們先來簡單認識一下它們。
## 什麼是 Kubernetes 審計?
Kubernetes 審計日誌是 Kube-apiserver 產生的可配置策略的結構化日誌,記錄了對 Apiserver 的訪問事件。審計日誌提供 Metrics 之外的另一種叢集觀測維度,通過檢視、分析審計日誌,可以追溯對叢集狀態的變更;瞭解叢集的執行狀況;排查異常;發現叢集潛在的安全、效能風險等等。
## 審計來源
在 Kubernetes 中,所有對叢集狀態的查詢和修改都是通過向 Apiserver 傳送請求,對 Apiserver 的請求來源可以分為4類
- 控制面元件,例如 Scheduler,各種 Controller,Apiserver 自身
- 節點上的各種 Agent,例如 Kubelet、Kube-proxy 等
- 叢集的其它服務,例如 Coredns、Ingress-controller、各種第三方的 Operator 等
- 外部使用者,例如運維人員通過 Kubectl
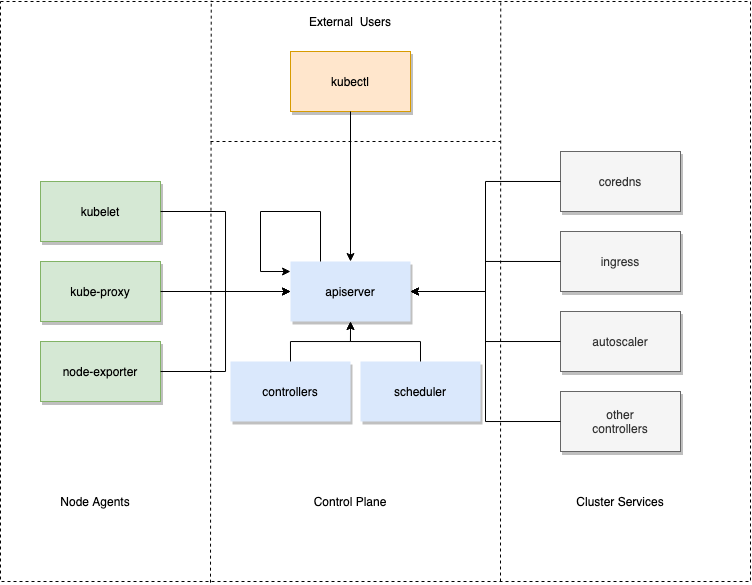
### 審計中都記錄了些什麼?
每一條審計日誌都是一個 JSON 格式的結構化記錄,包括元資料(metadata)、請求內容(requestObject)和響應內容(responseObject)3個部分。其中元資料一定會存在,請求和響應內容是否存在取決於審計級別。元資料包含了請求的上下文資訊,例如誰發起的請求,從哪裡發起的,訪問的 URI 等等;
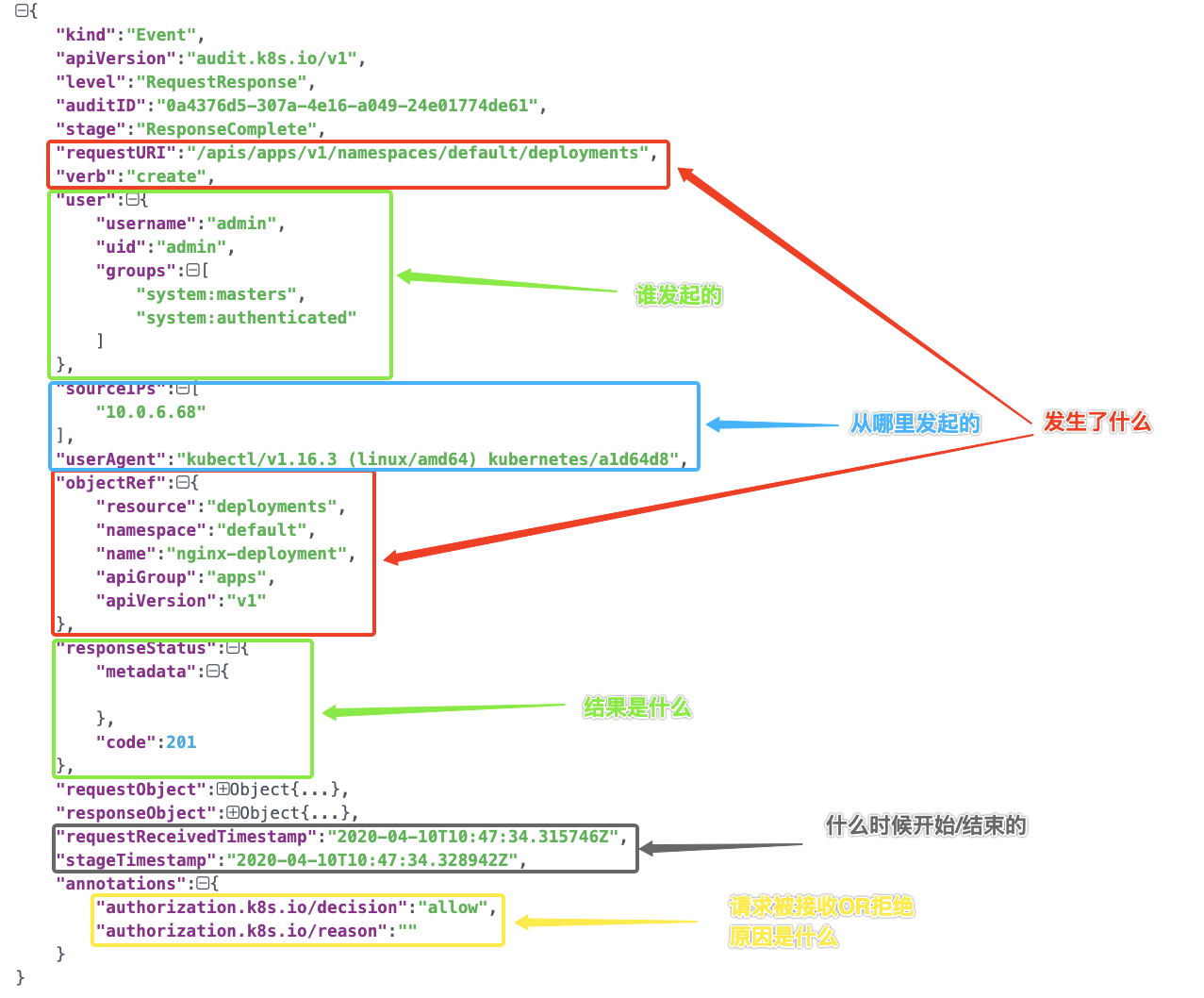
### 審計有什麼用?
Apiserver 做為 Kubernetes 叢集唯一的資源查詢、變更入口,審計日誌可以說記錄了所有對於叢集訪問的流水, 通過它可以從巨集觀和微觀瞭解整個叢集的執行狀況,比如:
- 資源被刪掉了,什麼時候刪掉的,被“誰”刪掉的?
- 服務出現問題,什麼時候做過版本變更?
- Apiserver 的響應延時變長,或者出現大量 5XX 響應 Status Code,Apiserver 負載變高,是什麼導致的?
- Apiserver 返回 401/403 請求,究竟是證書過期,非法訪問,還是 RBAC 配置錯誤等。
- Apiserver 收到大量來自外網 IP 對敏感資源的訪問請求,這種請求是否合理,是否存在安全風險;
## 什麼是Kubernetes事件?
事件(Event)是 Kubernetes 中眾多資源物件中的一員,通常用來記錄叢集內發生的狀態變更,大到叢集節點異常,小到 Pod 啟動、排程成功等等。我們常用的`kubectl describe`命令就可以檢視相關資源的事件資訊。
### 事件中記錄了什麼?

- 級別(Type): 目前僅有“Normal”和“Warning”,但是如果需要,可以使用自定義型別。
- 資源型別/物件(Involved Object):事件所涉及的物件,例如 Pod,Deployment,Node 等。
- 事件源(Source):報告此事件的元件;如 Scheduler、Kubelet 等。
- 內容(Reason):當前發生事件的簡短描述,一般為列舉值,主要在程式內部使用。
- 詳細描述(Message):當前發生事件的詳細描述資訊。
- 出現次數(Count):事件發生的次數。
### 事件有什麼用?
叢集內已經翻江倒海,叢集外卻風平浪靜,這可能是我們日常叢集運維中常常遇到的情況,叢集內的狀況如果無法透過事件來感知,很可能會錯過最佳的問題處理時間,待問題擴大,影響到業務時才發現往往已經為時已晚;除了早早發現問題,Event 也是排查問題的最佳幫手,由於 Event 記錄了全面的叢集狀態變更資訊,所以大部分的叢集問題都可通過 Event 來排查。總結一下 Event 在叢集中扮演兩大重要角色:
- “吹哨人”:當叢集發生異常情況時,使用者可通過事件第一時間感知;
- “目擊者”:叢集中的大小事件都會通過 Event 記錄,如果叢集中發生意外情況,如:節點狀態異常,Pod 重啟,都可以通過事件查詢發生的時間點及原因;
## TKE 如何發掘審計/事件的價值
傳統的通過輸入查詢語句檢索日誌的方式來使用審計和事件,固然可以提供很高的靈活性,但也有著較高的使用門檻,不僅要求使用者對於日誌的資料結構非常瞭解,還要熟悉 Lucene、SQL 語法。這往往導致使用效率偏低,也無法充分發掘資料的價值。
騰訊雲容器服務 TKE 聯合騰訊雲[日誌服務CLS](https://cloud.tencent.com/product/cls),打造出針對 Kubernetes 審計/事件採集、儲存、檢索、分析的一站式產品級服務, 不僅提供了一鍵開啟/關閉功能,免去一切繁瑣的配置;而且容器團隊還從長期運維海量叢集的經驗中,總結出對於 Kubernetes 審計/事件的最佳使用實踐,通過視覺化的圖表,以多個維度對[審計日誌](https://cloud.tencent.com/document/product/457/50510)和[叢集事件](https://cloud.tencent.com/document/product/457/50512)進行呈現,使用者只需瞭解 K8s 的基本概念,就能很“直覺”地在 TKE 控制檯上進行各種檢索和分析操作,足以涵蓋絕大多數常見叢集運維場景, 讓無論是發現問題還是定位問題都事半功倍,提升運維效率,真正將審計和事件資料的價值最大化 。
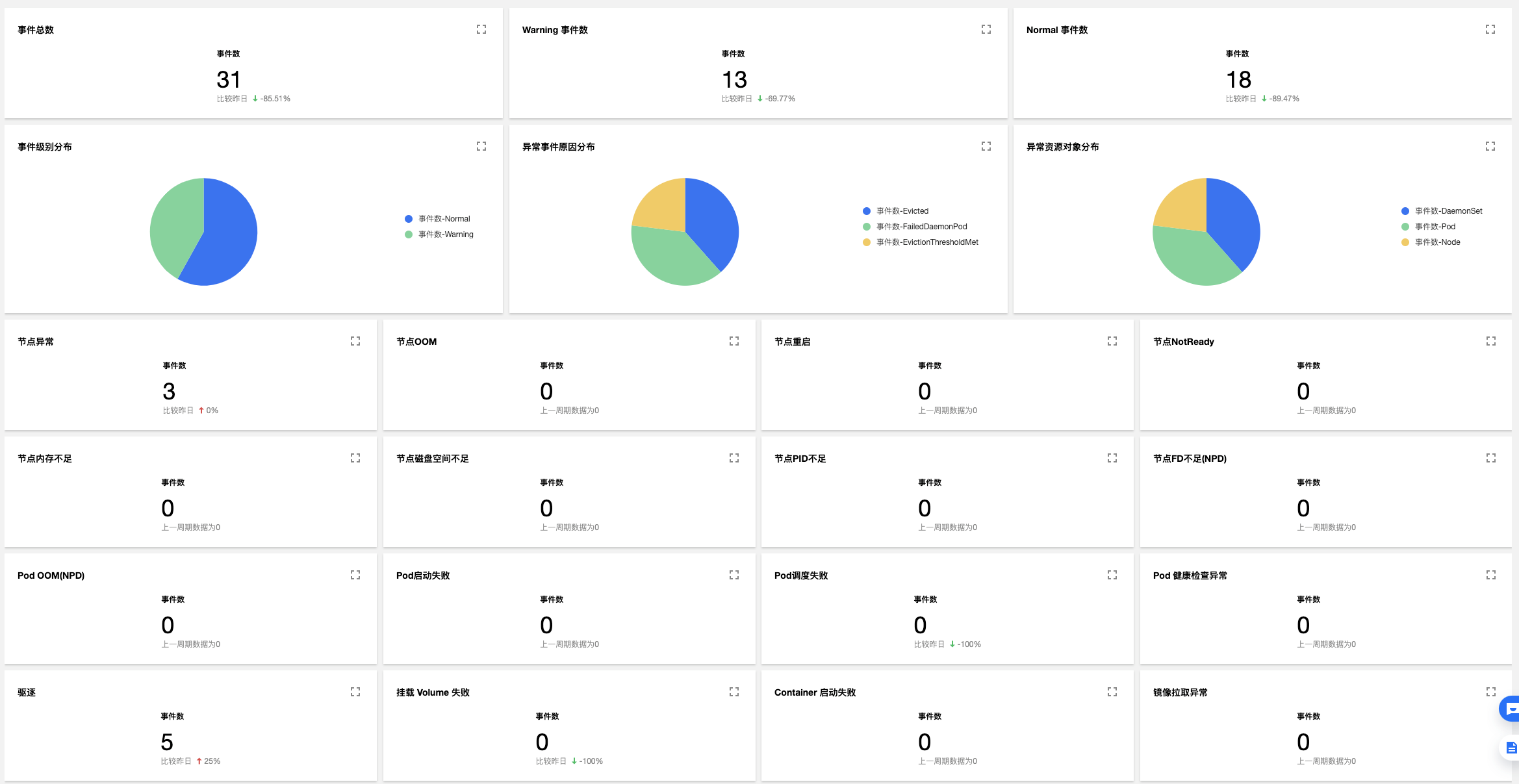
## 如何使用 TKE 審計/事件服務去排查問題?
> 關於 TKE 的叢集審計/事件簡介與基礎操作,請參考[叢集審計](https://cloud.tencent.com/document/product/457/48346)、[事件儲存](https://cloud.tencent.com/document/product/457/32091)的官方文件。
### 場景示例:
下面我們看幾個現實中的典型場景
#### 示例1: 排查一個工作負載消失的問題
在`審計檢索`頁面中,單擊【K8s 物件操作概覽】標籤,指定操作型別和資源物件
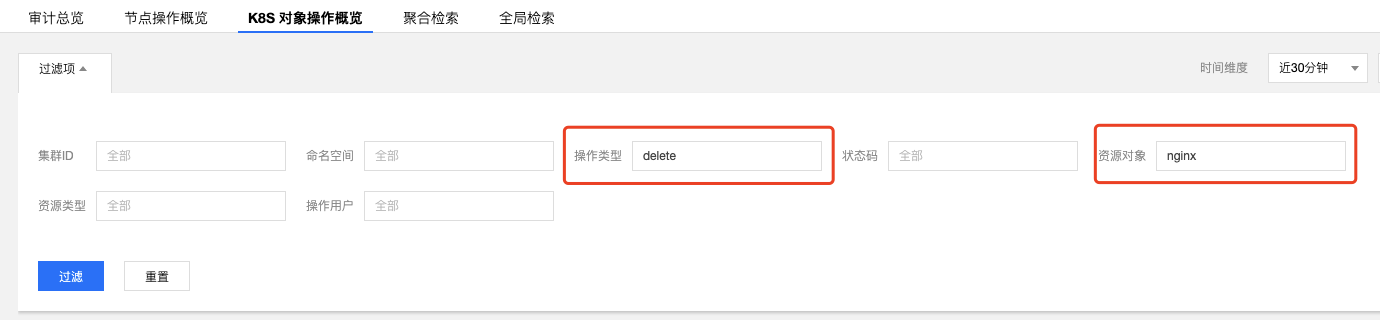
查詢結果如下圖所示:

由圖可見,是 `10001****7138` 這個帳號,對應用「nginx」進行了刪除。可根據帳號ID在【訪問管理】>【使用者列表】中找到關於此賬號的詳細資訊。
#### 示例2: 排查一個節點被封鎖的問題
在`審計檢索`頁面中,單擊【節點操作概覽】標籤,填寫被封鎖的節點名

查詢結果如下圖所示:
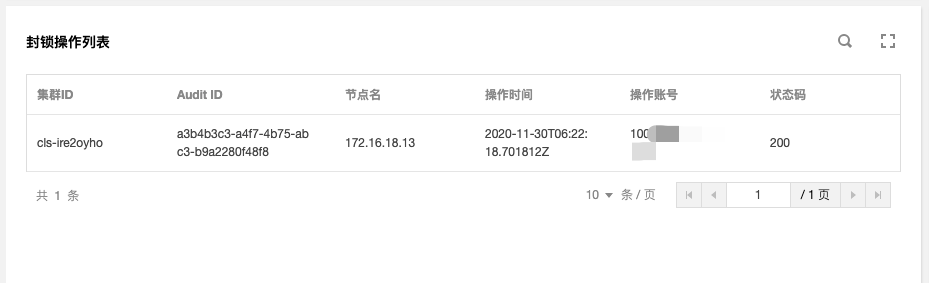
由圖可見,是`10001****7138`這個帳號在`2020-1-30T06:22:18`時對`172.16.18.13`這臺節點進行了封鎖操作。
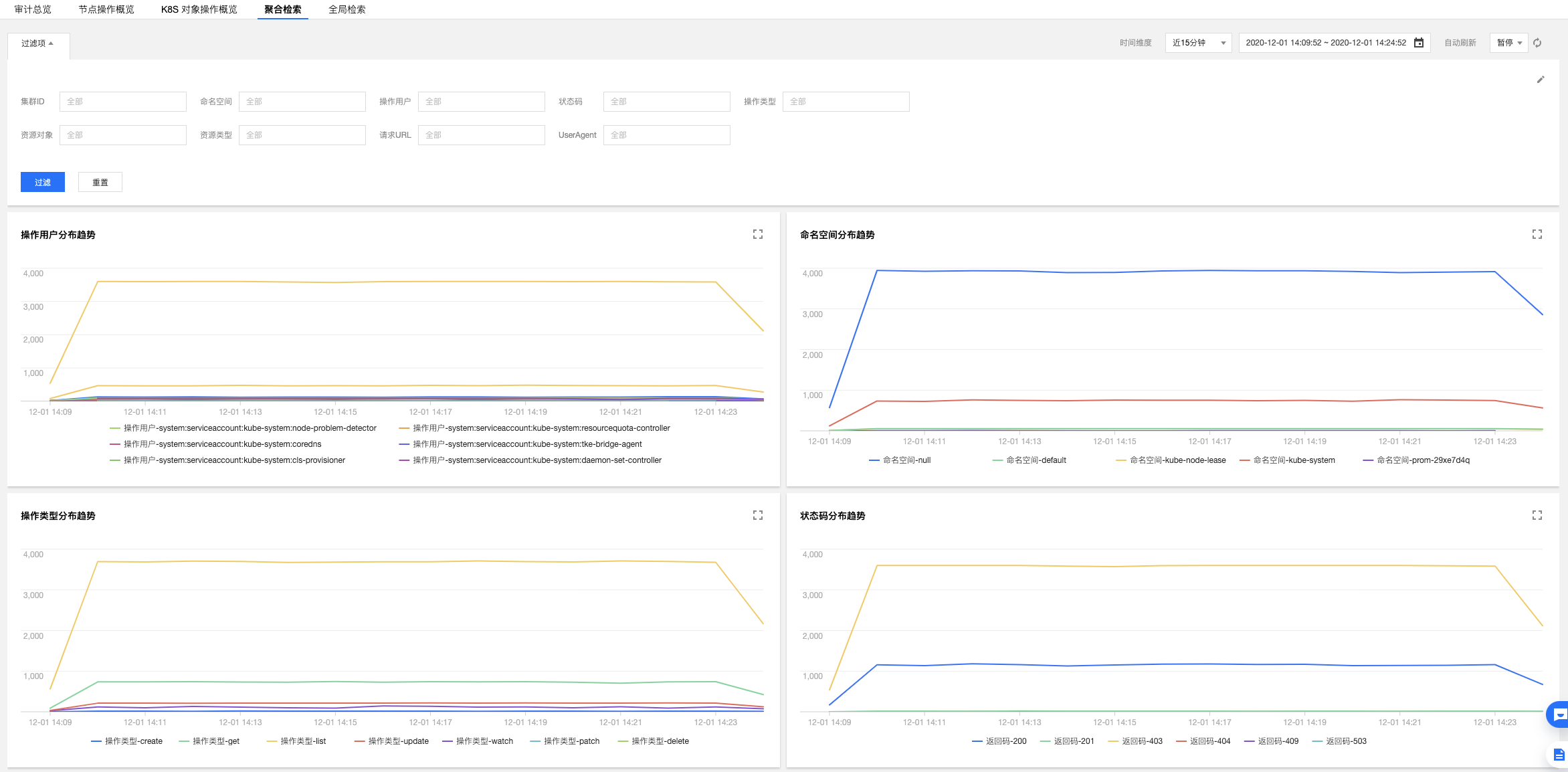
#### 示例3: 排查 Apiserver 響應變慢的問題
在`審計檢索`的【聚合檢索】標籤頁中,提供了從使用者、操作型別、返回狀態碼等多個維度對於 Apiserver 訪問聚合趨勢圖。
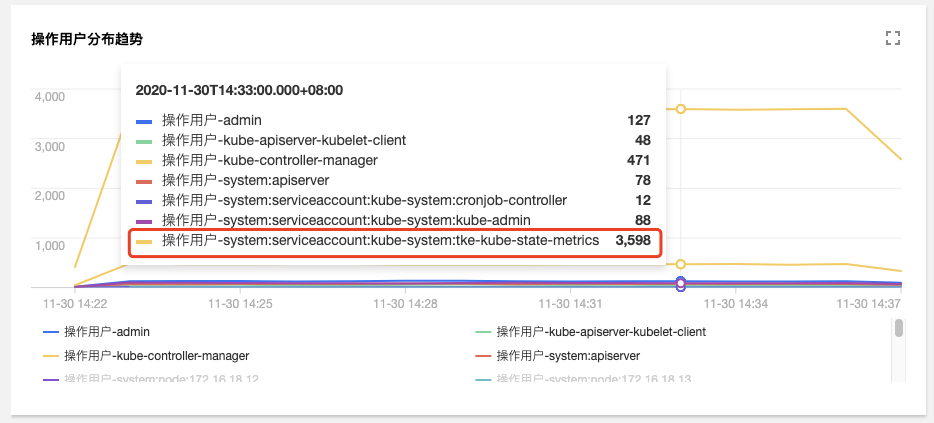
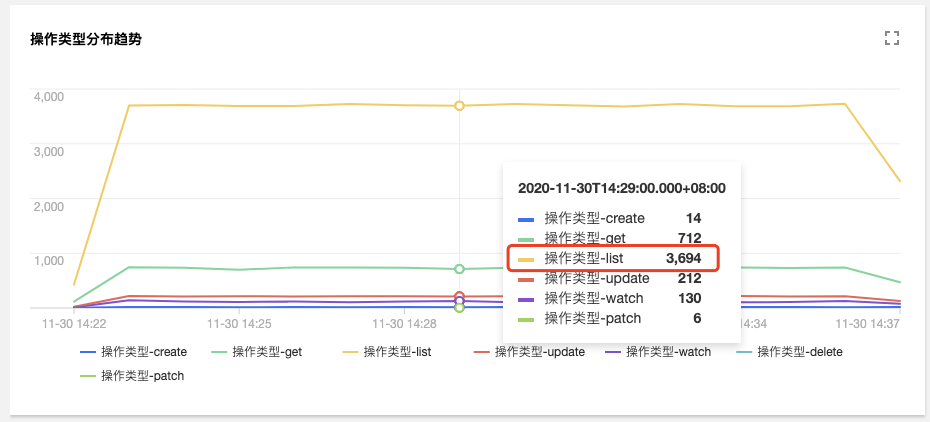
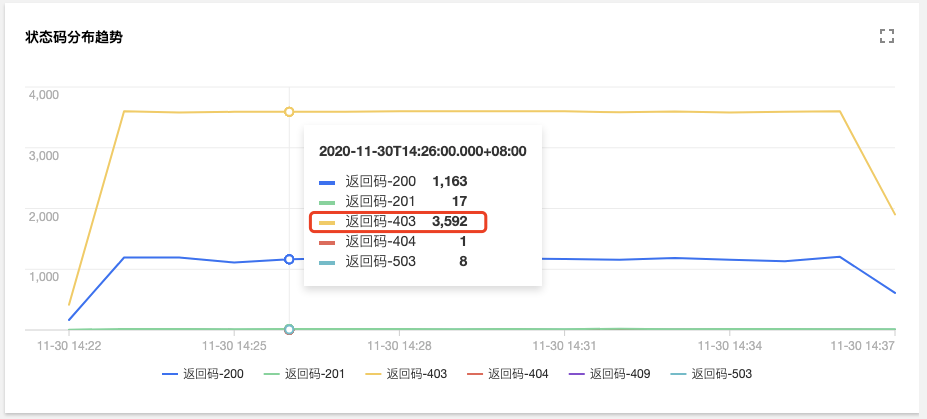
由圖可見,使用者`tke-kube-state-metrics`的訪問量遠高於其他使用者,並且在“操作型別分佈趨勢”圖中可以看出大多數都是 list 操作,在“狀態碼分佈趨勢”圖中可以看出,狀態
碼大多數為 403,結合業務日誌可知,由於 RBAC 鑑權問題導致`tke-kube-state-metrics`元件不停的請求Apiserver重試,導致 Apiserver 訪問劇增。日誌如下所示:
```
E1130 06:19:37.368981 1 reflector.go:156] pkg/mod/k8s.io/[email protected]/tools/cache/reflector.go:108: Failed to list *v1.VolumeAttachment: volumeattachments.storage.k8s.io is forbidden: User "system:serviceaccount:kube-system:tke-kube-state-metrics" cannot list resource "volumeattachments" in API group "storage.k8s.io" at the cluster scope
```
#### 示例4:排查節點異常的問題
一臺 Node 節點出現異常,在`事件檢索`頁面,點選【事件總覽】,在過濾項中輸入異常節點名稱
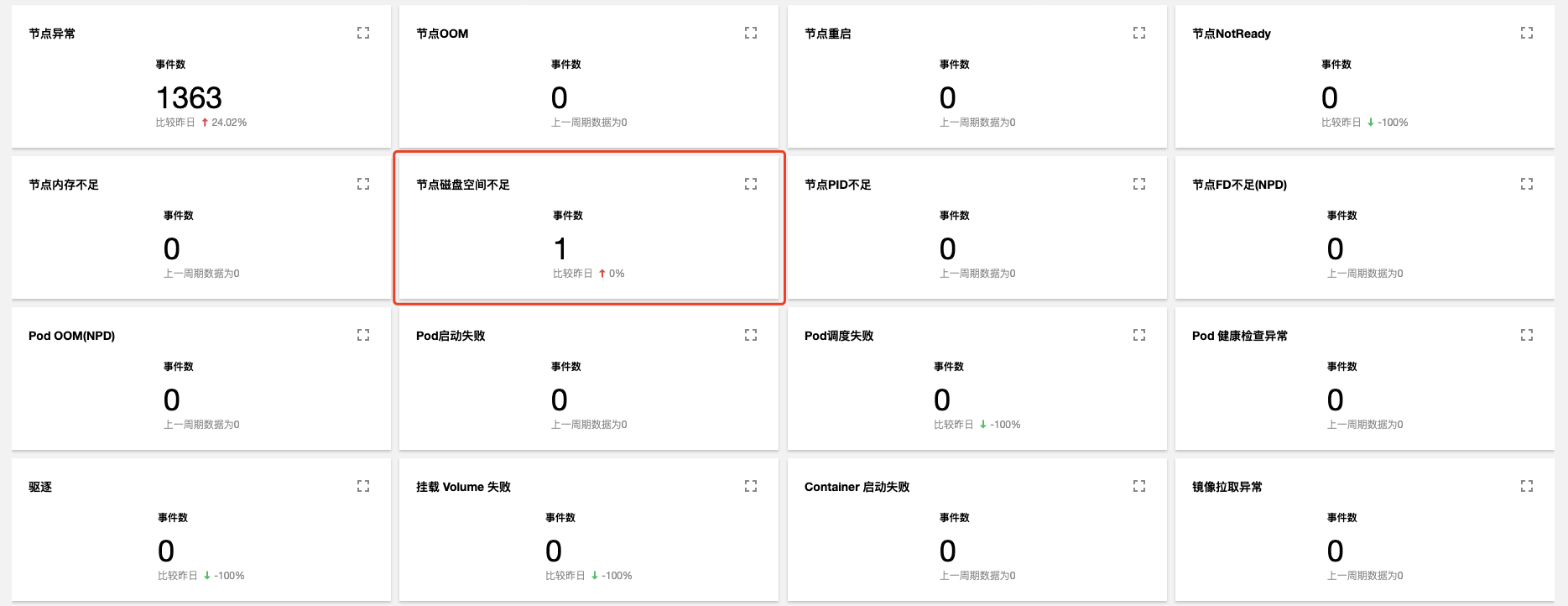
查詢結果顯示,有一條`節點磁碟空間不足`的事件記錄查詢結果如下圖:
進一步檢視異常事件趨勢
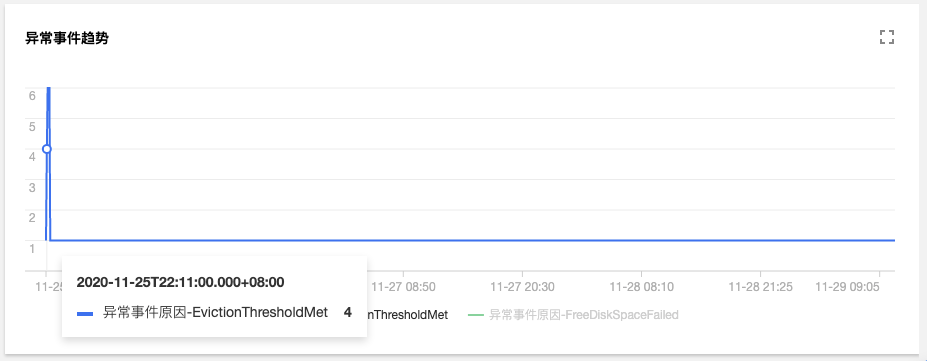
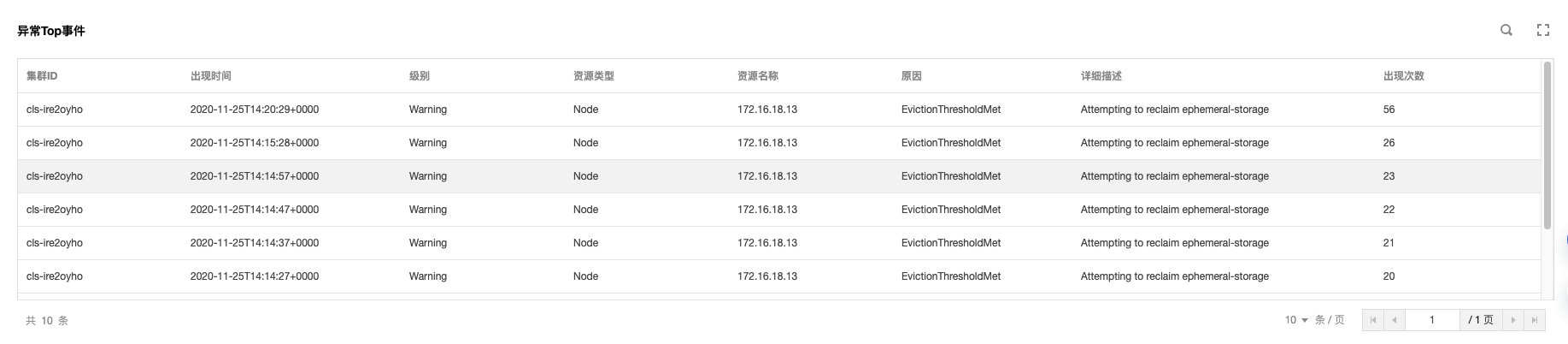
可以發現,`2020-11-25`號開始,節點`172.16.18.13`由於磁碟空間不足導致節點異常,此後 kubelet 開始嘗試驅逐節點上的 pod 以回收節點磁碟空間;
#### 示例5: 查詢觸發節點擴容的原因
開啟了[節點池](https://cloud.tencent.com/document/product/457/43719)「彈性伸縮」的叢集,CA(cluster-autoscler)元件會根據負載狀況自動對叢集中節點數量進行增減。如果叢集中的節點發生了自動擴(縮)容,使用者可通過事件檢索對整個擴(縮)容過程進行回溯。
在`事件檢索`頁面,點選【全域性檢索】,輸入以下檢索命令:
```
event.source.component : "cluster-autoscaler"
```
在左側隱藏欄位中選擇`event.reason`、`event.message`、`event.involvedObject.name`、`event.involvedObject.name`進行顯示,將查詢結果按照`日誌時間`倒序排列,結果如下圖所示:
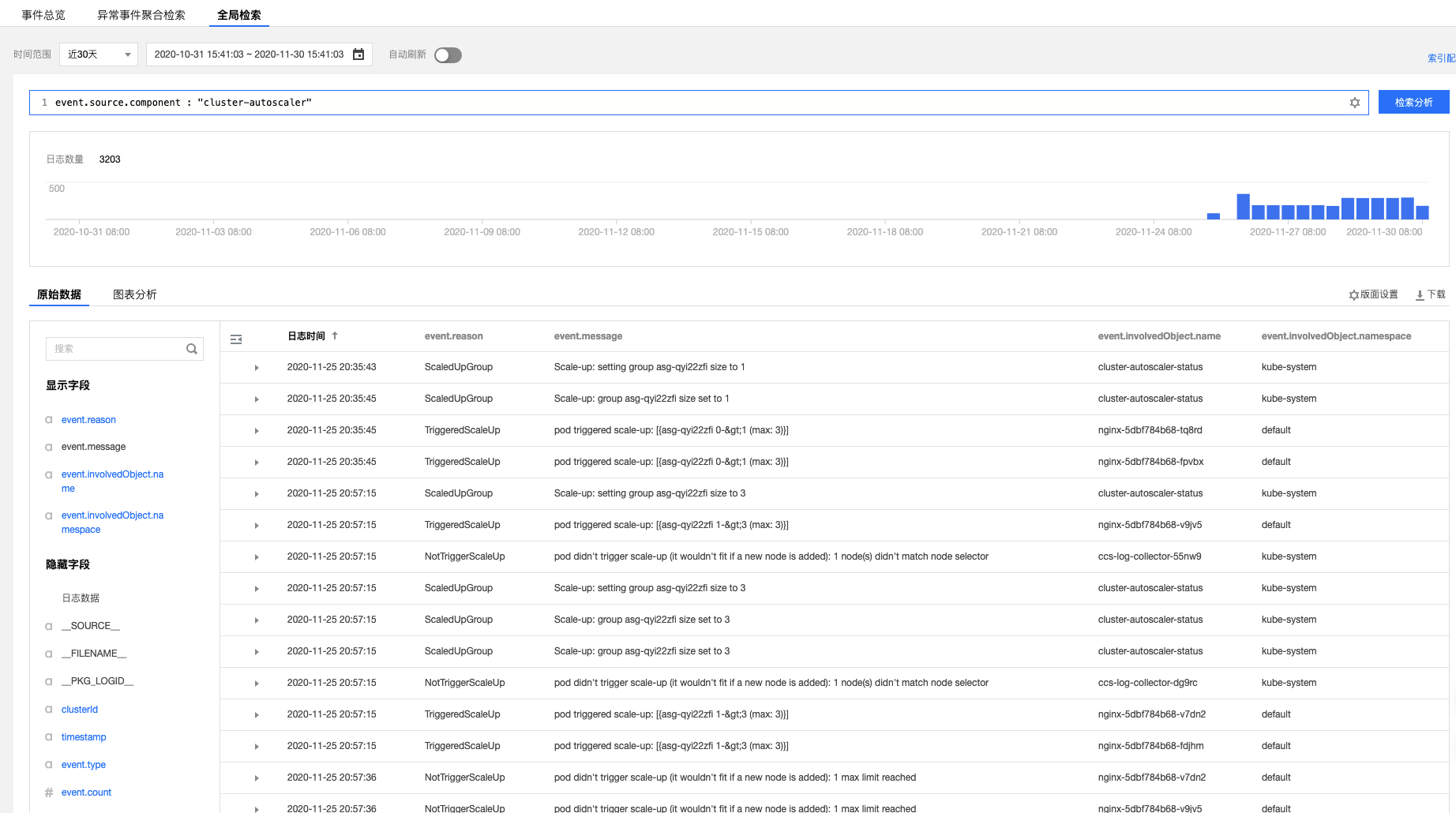
通過上圖的事件流水,可以看到節點擴容操作在`2020-11-25 20:35:45`左右,分別由三個 nginx Pod(nginx-5dbf784b68-tq8rd、nginx-5dbf784b68-fpvbx、nginx-5dbf784b68-v9jv5) 觸發,最終擴增了3個節點,後續的擴容由於達到節點池的最大節點數沒有再次觸發。
## 總結
本文介紹了在 Kubernetes 中兩個經常被忽略的元素--「審計日誌」和「叢集事件」,並討論了它們在賦能叢集運維和提升系統可觀測性方面的價值。騰訊雲容器團隊在長期運維海量 Kubernetes 叢集經驗總結的基礎上,在 TKE 中釋出了基於審計和事件的產品服務,幫助使用者能夠快速高效解決日常叢集運維中遇到的問題,將使用者從繁雜的叢集問題中解放出來。
最後我們從實戰角度出發,通過幾個經典問題來演示通過 TKE 審計/事件服務來定位排查問題。由於篇幅有限,我們的演示只是產品功能的冰山一角,更多的功能需要使用者去探索使用,最後歡迎使用者體驗 。(騰訊雲日誌服務 CLS 對於 TKE 產生的所有審計/事件資料提供免費服務至 2021年6月1日。)
>【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
![](https://img2020.cnblogs.com/other/2041406/202012/2041406-20201207155625806-1601715