
輪廓檢測論文解讀 | 整體巢狀邊緣檢測HED | CVPR | 2015
阿新 • • 發佈:2020-12-08
---
# 主題列表:juejin, github, smartblue, cyanosis, channing-cyan, fancy, hydrogen, condensed-night-purple, greenwillow, v-green, vue-pro, healer-readable
# 貢獻主題:https://github.com/xitu/juejin-markdown-themes
theme: juejin
highlight:
---
## 0 輪廓檢測
**輪廓檢測**,對我這樣的初學者而言,與**語義分割**類似。分割任務是什麼我就不再贅述了,輪廓檢測則是完成這樣的一個任務:

瞭解傳統影象處理或者opencv的朋友應該都不難看出(想到),“Canny”輪廓提取運算元,這個運算元簡單的說就是對影象的畫素值的變化(梯度)進行檢測,然後梯度變化大的地方認定為輪廓(上圖就是用Canny運算元提取的效果)。當然,最近也是用深度學習的方法來做這種輪廓提取,本問介紹的HED就是這樣的一個**深度學習提取邊框的辦法**,下圖是HED提取小狗輪廓的結果圖。

## 1 論文概述
- 相關論文:《Holistically-Nested Edge Detection》
- 論文連結:https://arxiv.org/abs/1504.06375
- 論文年份:2015
今天解讀一篇論文,網上已經有一些的解讀了,不過講解的並不細緻,讓我難以理解,直到看了官方程式碼才理理順,所以這篇文章**部分搬運,再加上個人補充**。
**整體來說,這個HED邊緣檢測模型,與Unet分割模型類似,再加上年份較老,所以復現價值不大,大家當擴充套件知識看看就得了。**
Unet我們直接已經講解過了,用簡單的文字來簡單的回顧一下:**字母U的左半邊,是不斷卷積池化層進行特徵抽取,然後得到不同尺度的特徵圖,然後U的右半邊,通過轉置卷積進行上取樣,然後與下采樣過程中的同尺度拼接做特徵融合,然後最終模型輸出一個與輸入影象相同大小的預測結果。**
**HED,Holistically-Nested Edge Detection**這個模型,其中的亮點在我看來,是對Deep supervision的一種應用。Deep supervision這個概念相比讀者應該不陌生,在上上上一篇文章《Unet++》那個文章中我已經提到了,簡單的說就是一個模型有多個輸出的結構。
## 2 HED結構
來看下論文中給出的HED的結構圖:
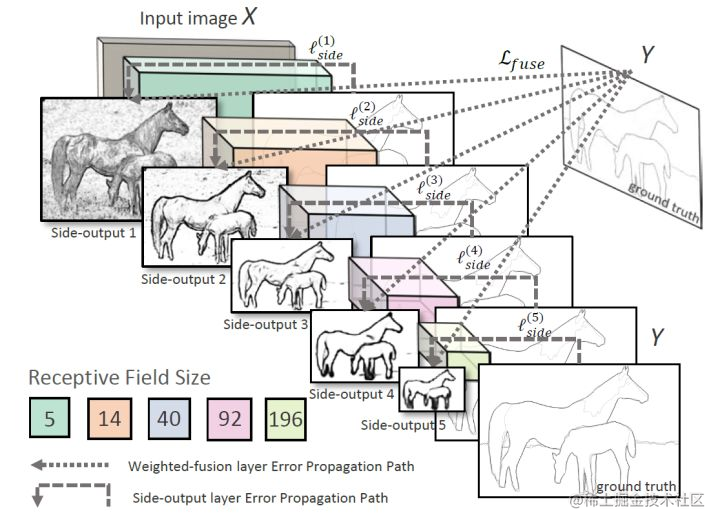
這個圖可能比較抽象,我來大概講解一下:
- 可以看到的是整個過程只有一個**卷積+池化的過程**,Unet還有上取樣的過程,這是不同點;
- 圖中的有5個馬的圖片,從大到小,從淺到深,紋理越來越少,這分別是經過了maxpool和卷積得到的不同尺寸的輸出。從圖中可以看到,這些輸出叫做side-output 1到side-output 5。
- 圖中這五個特徵圖經過虛線,得到了一個Y,這個Y是經過“weighted-fusion”得到了,簡單的說就是,五個圖經過一個可以訓練的權重引數,融合成了最終的輸出
結構不難理解,但是到這裡讀者肯定心中仍有疑惑,看完下面的損失函式的構成就通透了。
## 3 損失函式
這個損失函式算是deep supervision比較常見的損失函數了,就是**每一個side-output輸出都是損失函式的一部分**。
整體來說,這個損失函式是有兩個部分:
- side-output:這個就是上圖中五個不同尺度的預測結果,通過上取樣成原圖大小,然後和mask做交叉熵。因為有5個圖,所以損失是五個的和;
- fusion:五個圖fusion出得Y,這個Y與ground truth的交叉熵;
所以論文中有這樣的損失函式:
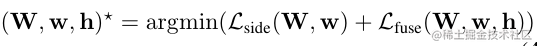
我也沒注意W,w,h的含義,但是看起來確實是side和fusion兩部分損失函式。
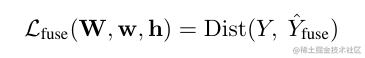
這裡的Dist其實使用的就是交叉熵
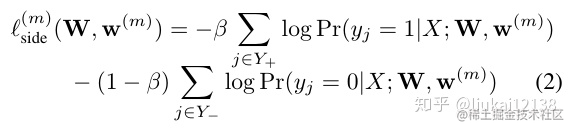
這個side中,除去這個$\beta$不管,剩下的內容就是二值交叉熵,也許和你常見的那種形式不太一樣,但是是一樣的。**給個提示:看這裡的$\Sigma$的下標**
現在我們對損失函式應該有了一個大致的感覺了,但是仍然有兩個疑問:
1. $loss_{side}$中的$\beta$是什麼?怎麼算?
2. $loss_{fuse}$中的$\hat{Y}_{fuse}$怎麼得到,換言之,如何融合5個side-output?
**對於第一個問題**,$\beta$是一個平衡係數,
$$\beta = \frac{|Y^-|}{|Y|}$$
其中$|Y|$表示影象的畫素的數量,也就是widthxheight;$|Y^-|$表示這個圖片中,ground truth的畫素的數量,類似與解決預測畫素不平衡的一個手段。
**假設一張圖片中ground truth的畫素量少,那麼意味著,$\beta$的值小,那麼公式(2)中的第一項的權重輕,而第一項的sigma的下標是$Y^+$,說明這個是計算非目標,也就是groud truth=0的損失,也就是背景的損失,數量很多,所以權重輕損失少。** 這一點實在不好講明白,希望大家沒理解的多讀兩遍。
**對於第二個問題**,論文中給出了公式:
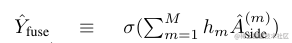
這個h應該是一個可以訓練的引數,然後加和之後用sigma歸一化。
## 4 損失函式 TF
現在萬事俱備,官方提供了程式碼,來看一下這個損失函式的TF版本:
```python
def class_balance_sigmoid_cross_entropy(logits,label,name='cross_entropy_loss'):
y = tf.cast(label,tf.float32)
count_neg = tf.reduce_sum(1.-y)
count_pos = tf.reduce_sum(y)
beta = count_neg/(count_neg+count_pos)
pos_weight = beta/(1-beta)
cost = tf.nn.weighted_cross_entropy_with_logits(logits,y,pos_weight)
cost = tf.reduce_mean(cost*(1-beta),name=name)
return cost
cost = class_balanced_sigmoid_cross_entropy(dsn_fuse, annotation_tensor) + \
class_balanced_sigmoid_cross_entropy(dsn1, annotation_tensor) + \
class_balanced_sigmoid_cross_entropy(dsn2, annotation_tensor) + \
class_balanced_sigmoid_cross_entropy(dsn3, annotation_tensor) + \
class_balanced_sigmoid_cross_entropy(dsn4, annotation_tensor) + \
class_balanced_sigmoid_cross_entropy(dsn5, annotation_tensor)
```
可能有的朋友看不懂TF的寫法,不過大概能看懂把,細節不懂但是英文單詞總是沒問題的,整體來看,跟我們上面講解的差不多把。
## 5 總結
這裡談一談我看了這個2015年的老前輩模型的收穫把:
1. HED是一個邊緣檢測模型,但是使用的和Unet的框架有些類似。HED使用了deep supervision的方法,而Unet並沒有,這裡我突然想到**Unet++** 的結構,Unet++的思想完全可以沿著Unet+HED這條線路誕生。
2. 我們學到了一個deep supervision的損失函式的寫法;
3. 我們學到了一個單詞Holistically-nested。**holistically 整體地,nest 巢狀**。
參考文章:
1. https://zhuanlan.zhihu.com/p/35694372
2. https://zhuanlan.zhihu.com/p/36660932
3. https://www.zhihu.com/question/31864895
4. https://arxiv.org/abs/1504.06375
5. https://blog.csdn.net/u014779538/article/details/