
股指期貨高頻資料機器學習預測

更多精彩內容,歡迎關注公眾號:數量技術宅。想要獲取本期分享的完整策略程式碼,請加技術宅微信:sljsz01
問題描述
通過對交易委託賬本(訂單簿)中資料的學習,給定特定一隻股票10個時間點股票的訂單簿資訊,預測下20個時間點中間價的均值。
評價標準為均方根誤差。
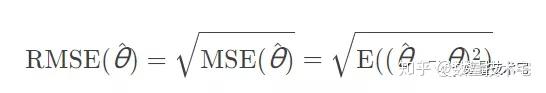
交易時間為工作日9:30-11:30,13:00-15:00,快照頻率3秒。
股價的形成分為集合競價和連續競價– 集合競價:9:15-9:25,開盤集合競價,確定開盤價
– 連續競價:9:30之後,根據買賣雙方的委託形成的價格
競價原則:價格優先,時間優先。
交易委託賬本具體資訊:– Date - 日期– Time - 時間– MidPrice - 中間價(買入價與賣出價的平均值)– LastPirce - 最新成交價– Volume - 當日累計成交數量– BidPrice1 - 申買最高價– BidVolume1 - 申買最高價對應的量– AskPrice1 - 申賣最高價
– AskVolume1 - 申賣最高價對應的量
問題分析
在這個問題中,我們利用10個時間點股票的訂單簿資訊,預測特定一隻股票下20個時間點中間價的均值,來判斷其在一分鐘內的價格變化特徵,以便於高頻交易。高頻交易的意義在於,對於人類來說,很難在一分鐘之內判斷出股價變化情況,並完成交易。因此,只能利用計算機進行自動化交易。對於無資訊無模型預測,即利用訂單簿中最後一個價格“預測”,得到的均方根誤差為0.00155。試圖通過分析資料、建立模型,做出高於此誤差的預測。
資料分析
資料集
訓練集(raw training data,train_data.csv):430039條訂單簿資訊測試集(test data, test_data.csv):1000條(100組)訂單簿資訊為了避免概念的混淆,下文中如果特別說明,“測試集”均指public board所依賴的資料。此外,這裡的“訓練集”下文中包含經過資料清理和預處理的訓練集(training data)和驗證集(development data)。
資料清洗
為了將訓練集轉換為測試集的格式,即通過10個間隔3秒的訂單簿記錄,來預測後20個間隔3秒的訂單簿記錄中中間價的均值,必須對資料清洗。將訓練集集中連續的nGiven+(nPredict平方)條資料作為一組資料。
檢查每一組資料,去掉含有時間差不為3秒的連續兩條資料的組。這樣可以跳過跨天的以及不規整的資料。
資料預處理
歸一化
給定的資料特徵(日期、時間、價格、成交量等)的量綱不同,並且資料絕對值差的較大。如測試集第一條資料:

MidPrice和Volume差6個數量級。首先,資料歸一化後,最優解的尋優過程明顯會變得平緩,更容易正確地收斂到最優解。其次,在支援向量機(SVM)等不具有伸縮不變性的模型中,大數量級的資料會掩蓋小數量級的資料。這是因為隨機進行初始化後,各個資料擁有同樣的或近似的縮放比例,相加之後小數量級的資料便被大數量級的資料“吃掉了”。此外,對於具有伸縮不變性的模型,如邏輯迴歸,進行歸一化也有助於模型更快地收斂。綜上所述,對模型進行歸一化是十分有必要的。
Prices
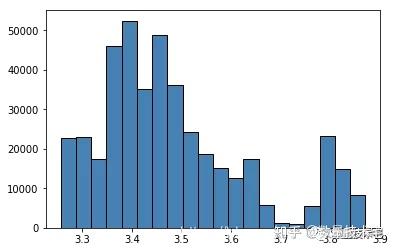
訓練集MidPrice分佈:
測試集MidPrice分佈:
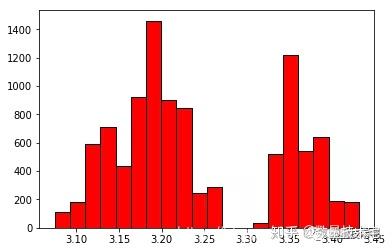
從上面兩張圖片中可以看出,訓練集和測試集中最重要的特徵以及待遇測量——中間價只有約三分之一重合。這意味著如果按照數值直接進行歸一化,可能會有較差的結果。
我採取的第一種方式是預測差值——+即每組資料待預測量——下20條陣列中MidPrice的均值與最後一個MidPrice的差值,並將各個價格減去最後一個MidPriced的值,這樣可以使訓練集和驗證集分佈更為接近,但是這樣造成的問題是,在量綱存在的情況下,最後一個MidPriced的值仍是有價值的,將它直接消去不合適。
第二種方式是完全消除量綱,將預測任務變為變化率的預測。即將所有與Price相關的變數都減去併除以最後一條陣列的中間價。這樣就可以將量綱完全消除。
last_mp = x_cur[nGiven-1,0]
for axis in [0,1,3,5]: # MidPrice, LastPrice, BidPrice1, AskPrice1
x_cur[:,axis] -= last_mp
x_cur[:,axis] /= last_mp
...
y.append((sum(mid_price[k+nGiven:k+nGiven+nPredict])/
nPredict-mid_price[k+nGiven-1])/mid_price[k+nGiven-1])Volume
Volume是指當日累計成交數量。在每組資料中,Volume的大小差別很大,這主要是因為每組資料開始的時間不同。開始,我試圖保留時間資訊和Volume,來更好地利用Volume資訊。事實上,雖然一天中的Volume是相關的,但是幾乎不可能通過時間資訊來估計Volume,何況高頻交易簿的精度很高。因此,通過加入時間資訊避免對Volume的歸一化是不可行的。
第二個嘗試是利用類似於對Prices的處理,將每組資料中的Volume減去該組資料中第一條資料的Volume。但這樣效果並不好,這是因為Volume在一組中是遞增的,將它們進行如上處理後仍是遞增的,利用普通的歸一化手段無法將它們對映在同一尺度上。
第三種嘗試是利用變化量。將每一組Volume資料減去上一條資訊的Volume,將這個特徵轉化為:3秒內累計成交數量。至此,每組/條資料的Volume便為同一分佈了。此外,對於第一條資料,沒有辦法得知它與上一條資料(沒有給出)的差值,只能用均值填充。具體方法是利用迄“今”(這條資料)為止得到的Volume插值的均值。
for i in range(9,0,-1):
x_cur[i,2]-=x_cur[i-1,2]
volume_sum+=x_cur[i,2]
volume_len+=1
x_cur[0,2]=volume_sum/volume_len時間資訊
由於時間是遞增的,可以通過將它們對映在每一天(即,刪除日期,保留時間),然後進行預測。但是由於資料只有約120天,將它們對映在每一個時間點會導致這部分資料過於稀疏。因此,在保證每組資料中,每連續兩條資料的時間差值為3秒的情況下,可以直接將時間資訊刪除。
此外,我發現在多種模型的實驗中,是否將時間資訊加入並不會有太大的改變。
對於預測值的處理
在前文中提到過,將預測數值任務改變為預測變化率的任務。這樣做除了為了消除量綱,更主要的原因是加快收斂。若果不進行這樣的處理,對於CNN/DNN/RNN等基於神經網路的模型,需要大約20epoch才能收斂到baseline RMSE=0.00155,但是如果採取變化率預測,只需要一個epoch就可以收斂到RMSE=0.00149.4
因此,如果不進行這樣的處理,將會極度增加訓練的時間,對調參和模型分析造成很大困難。
噪聲
加入噪聲。對於某些資料而言——尤其是Price相關的資料,由於有很多組相同或相似的陣列以及線性對映的不變性,導致處理後結果是離散的。因此,我在每個值中加入±1%的噪聲,以提高模型的泛化能力。
降低噪聲。在固定模型的情況下,我發現改變任務為預測下15條資料的中間價均值,亦或是下10條資料的中間價均值,得到的leaderboard成績要優於預測下20條的資料的中間價均值。我想這是因為通過跨度為30秒的10條資料可能無法預測到更遠的時間點,如跨度為60秒的20條資料中的後幾條資料。在沒有更多資訊的情況下,很可能之後的數值對於預測來說是噪聲。在實驗中也證明了這一點,後文將會詳細說明。在下文中將這個nPredict“超引數”視為MN(Magic Number)。
模型探索
基於LSTM的RNN模型
這個模型是我所實現最優的模型,採取這個模型的主要原因是基於LSTM的RNN模型具有很好的處理時間序列的能力。
遞迴神經網路(RNN)
迴圈神經網路(Recurrent Neural Network,RNN)是一類具有短期記憶能力的神經網路。在迴圈神經網路中,神經元不但可以接受其它神經元的資訊,也可以接受自身的資訊,形成具有環路的網路結構。和前饋神經網路相比,迴圈神經網路更加符合生物神經網路的結構。迴圈神經網路已經被廣泛應用在語音識別、語言模型以及自然語言生成等任務上。迴圈神經網路的引數學習可以通過隨時間反向傳播演算法 [Werbos, 1990] 來學習。隨時間反向傳播演算法即按照時間的逆序將錯誤資訊一步步地往前傳遞。當輸入序列比較長時,會存在梯度爆炸和消失問題[Bengio et al., 1994, Hochreiter and Schmidhuber, 1997, Hochreiteret al., 2001],也稱為長期依賴問題。為了解決這個問題,人們對迴圈神經網路進行了很多的改進,其中最有效的改進方式引入門控機制。
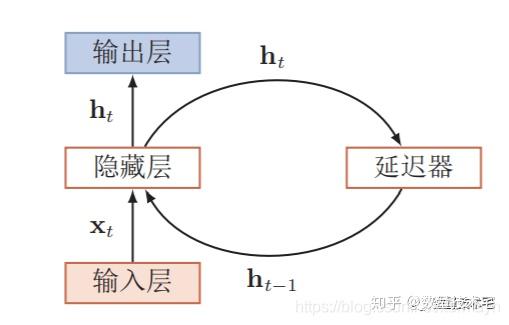
長短期記憶(LSTM)網路
長短期記憶(long short-term memory,LSTM)網路 [Gers et al., 2000, Hochreiter and Schmidhuber, 1997]是迴圈神經網路的一個變體,可以有效地解 決簡單迴圈神經網路的梯度爆炸或消失問題。在公式(6.48)的基礎上,LSTM網路主要改進在以下兩個方面:新的內部狀態 LSTM網路引入一個新的內部狀態(internal state)ct專門進行線性的迴圈資訊傳遞,同時(非線性)輸出資訊給隱藏層的外部狀態ht。
在每個時刻t,LSTM網路的內部狀態ct記錄了到當前時刻為止的歷史資訊。
迴圈神經網路中的隱狀態h儲存了歷史資訊,可以看作是一種記憶(memory)。在簡單迴圈網路中,隱狀態每個時刻都會被重寫,因此可以看作是一種短期記憶(short-term memory)。在神經網路中,長期記憶(long-term memory)可以看作是網路引數,隱含了從訓練資料中學到的經驗,並更新週期要遠遠慢於短期記憶。而在LSTM網路中,記憶單元c可以在某個時刻捕捉到某個關鍵資訊,並有能力將此關鍵資訊儲存一定的時間間隔。記憶單元c中儲存資訊的生命週期要長於短期記憶h,但又遠遠短於長期記憶,因此稱為長的短期記憶(long short-term memory)
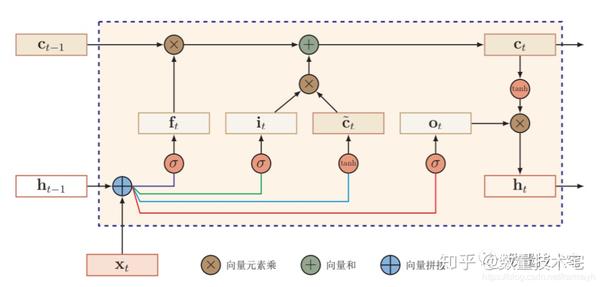
模型實現
利用Keras框架,實現基於LSTM的RNN模型。具體結構為兩層LSTM網路和兩層Dense層網路。試圖利用LSTM網路提取時間序列中的特徵資訊,並利用Dense層將提取出的特徵資訊進行迴歸。
model = Sequential()
model.add(LSTM(input_shape=(None, nFeature),activation='softsign',dropout=0.5, units=256, return_sequences=True))
model.add(LSTM(units=256,activation='softsign',dropout=0.5, return_sequences=False))
model.add(Dense(64,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,kernel_initializer="uniform",activation='linear'))
model.compile(loss='mean_squared_error', optimizer='Adam')在這個較大的模型中,為了防止過擬合訓練集和驗證集,我採取了以下的措施:
在全連線(Dense)層和LSTM層中,加入Dropout。在訓練中,dropout掉近似50%的引數,可以將網路模型減小至一半。在實驗發現,減小至該網路一半的網路更不容易出現過擬合的情況(下文中會詳細說明)。
提前結束訓練(Early-stopping)。在兩個相同的網路中,改變MN(即nPredict)的值,得到如下的測試集RMSE~epochs。由此可見,Early-stopping是非常有必要的。
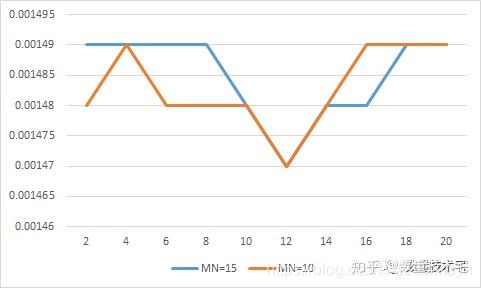
注:MN=20的同樣模型RMSE最好達到0.00148。
引數調整
我沒有進行大規模的網格搜尋以確定最好的超引數,我主要調整了網路的規模。基本想法是先選擇一個較大的網路,訓練至過擬合,判斷其有足夠擬合數據的能力,然後減小網路規模或進行正則化,消除過擬合以保留足夠的泛化能力。
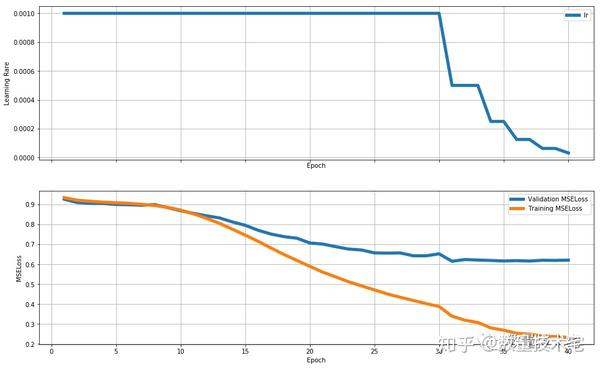
大網路(units = 256):
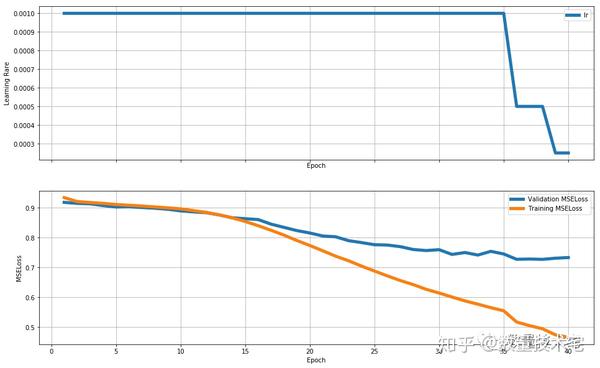
中網路(units = 128):
小網路(units = 64):
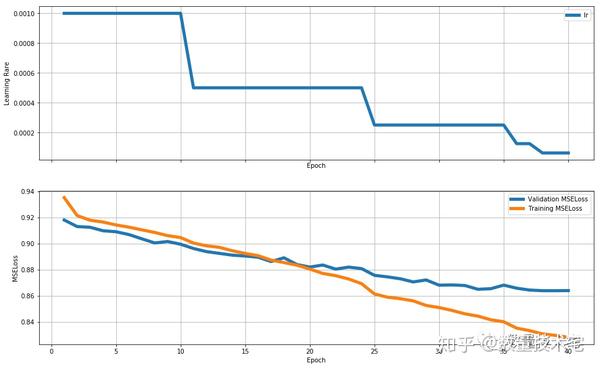
在實驗中發現,三個網路均會產生過擬合的問題。但是很明顯小網路的擬合能力不足(在更大的RSME開始出現過擬合),而大網路的擬合能力極其嚴重。於是我選擇了中網路規模的網路——大網路+50%dropout。
卷積神經網路
採取這個模型的主要原因是卷積神經網路模型可以通過共享(1,nFeature)卷積核減少引數,並將一組中每條資料進行同樣地處理。
卷積神經網路由一個或多個卷積層和頂端的全連通層(對應經典的神經網路)組成,同時也包括關聯權重和池化層(pooling layer)。這一結構使得卷積神經網路能夠利用輸入資料的二維結構。與其他深度學習結構相比,卷積神經網路在影象和語音識別方面能夠給出更好的結果。這一模型也可以使用反向傳播演算法進行訓練。相比較其他深度、前饋神經網路,卷積神經網路需要考量的引數更少,使之成為一種頗具吸引力的深度學習結構。
模型實現
利用Keras框架,實現卷積神經網路模型。具體結構為兩層卷積網路和三層Dense層網路。其中兩層卷積網路分別為1 ∗ 7卷積核和10 ∗ 1卷積核。
model = Sequential()
model.add(Conv2D(input_shape=(10,7,1),filters = 256, kernel_size = (1,7), strides=(1, 1), padding='valid',activation='relu'))
model.add(Dropout(0.5))
model.add(Conv2D(filters = 256, kernel_size = (10,1), strides=(1, 1), padding='valid',activation='relu'))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,kernel_initializer="uniform",activation='linear'))
model.compile(loss='mean_squared_error', optimizer='Adam')全連結的神經網路模型
神經網路模型的主要優點是具有極強的近似能力:模型可以以任意精度擬合一切連續函式。同時,進行這個模型的嘗試,也可以判斷卷積神經網路是否比樸素的全連結神經網路模型更好。
人工神經網路(英語:Artificial Neural Network,ANN),簡稱神經網路(Neural Network,NN)或類神經網路,在機器學習和認知科學領域,是一種模仿生物神經網路(動物的中樞神經系統,特別是大腦)的結構和功能的數學模型或計算模型,用於對函式進行估計或近似。神經網路由大量的人工神經元聯結進行計算。大多數情況下人工神經網路能在外界資訊的基礎上改變內部結構,是一種自適應系統,通俗的講就是具備學習功能。現代神經網路是一種非線性統計性資料建模工具。
模型實現
利用Keras框架,實現卷積神經網路模型。具體結構為兩層卷積網路和三層Dense層網路。其中兩層卷積網路分別為1 ∗ 7卷積核和10 ∗ 1卷積核。
model = Sequential()
model.add(Flatten(input_shape=(10,7,1)))
model.add(Dense(1024,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(512,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256,kernel_initializer="glorot_normal",activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,kernel_initializer="uniform",activation='linear'))
model.compile(loss='mean_squared_error', optimizer='Adam')利用XGBoost建立的模型
XGBoost介紹
XGBoost代表“Extreme Gradient Boosting”,其中術語“Gradient Boosting”源於弗裡德曼的貪婪函式逼近:梯度增強機。
XGBoost實質上是Gradient boosting Decision Tree(GBDT)的高效實現,如果使用最常用gbtree作為學習器,那麼它基本相當於CART分類樹。CART分類迴歸樹是一種典型的二叉決策樹,可以做分類或者回歸。如果待預測結果是離散型資料,則CART生成分類決策樹;如果待預測結果是連續型資料,則CART生成迴歸決策樹。資料物件的屬性特徵為離散型或連續型,並不是區別分類樹與迴歸樹的標準,例如表1中,資料物件xixi的屬性A、B為離散型或連續型,並是不區別分類樹與迴歸樹的標準。作為分類決策樹時,待預測樣本落至某一葉子節點,則輸出該葉子節點中所有樣本所屬類別最多的那一類(即葉子節點中的樣本可能不是屬於同一個類別,則多數為主);作為迴歸決策樹時,待預測樣本落至某一葉子節點,則輸出該葉子節點中所有樣本的均值。
模型實現
利用xgboost庫,實現XGB模型。
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV
cv_params = {'n_estimators': [600,800,1000,1200,1400,1600]}
other_params = {'learning_rate': 0.1, 'n_estimators': 100, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.6, 'colsample_bytree': 0.9, 'gamma': 0.4, 'reg_alpha': 0, 'reg_lambda': 1}
model = XGBRegressor(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params,
scoring='neg_mean_squared_error', cv=3, verbose=3, n_jobs=5)
optimized_GBM.fit(X_train_70, y_train)引數調整
利用上述GridSearchCV函式以及類似於Gibbs取樣演算法的思想,逐步調整引數。具體方法為:首先設定每個引數的取值區間。然後選取某個引數,將其設定為取值區間中等間距的幾個點,進行訓練模型進行驗證,將最好的點設定為這個引數的值,然後選取其他引數,重複這一步,直到引數穩定。但實驗中,由於過擬合情況嚴重,n_estimators越大會導致近似情況更好,但同時會導致模型的泛化能力降低。於是我通過提交結果,選定了n_estimator=200。然後調整其他引數。
隨機迴歸森林模型
簡單來說,隨機森林就是多個迴歸樹的融合。隨機森林的優勢在於
1.在沒有驗證資料集的時候,可以計算袋外預測誤差(生成樹時沒有用到的樣本點所對應的類別可由生成的樹估計,與其真實類別比較即可得到袋外預測)。
2.隨機森林可以計算變數的重要性。
3.計算不同資料點之間的距離,從而進行非監督分類。
模型實現
利用sklearn庫提供的RandomForestRegressor。
from sklearn.ensemble import RandomForestRegressor
clf = RandomForestRegressor(
oob_score = True,
max_depth = 20,
min_samples_split=20,
min_samples_leaf=10,
n_estimators=20,
random_state=0,
verbose=3)
clf.fit(X_train.reshape(-1,70),y_train.reshape((-1,)))結果與討論
| model | public leader board score |
|---|
*private leader board = 0.00140
討論:模型CNN vs DNN。利用卷積沒有取得更好的結果,這很大原因是資料特徵只有7維,沒有必要進行降維,因此CNN模型中的池化層(Pooling Layer)無法使用,降低了卷積模型能力。DNN vs RNN。RNN在epoch = 20開始lb = 0.00149,而DNN在較長區間[4,30+] epoches 中一直保持lb = 0.00148,這說明了RNN有更好的擬合時間序列的能力,但同樣有著更差的擬合能力,因此必須進行early-stopping防止過擬合。XGB。XGB有著很好的資料擬合能力,但由於調參需要較多的時間(每個模型擬合需要約40分鐘),而我沒有足夠的計算資源,只能放棄更細粒度的調參。
Random Forest。和XGB類似,它們對於多維資料的處理可能會比神經網路模型更好,但是在7維的資料中,表現並不如神經網路模型。
討論:模型之外特徵工程的重要性遠遠超過模型的選取以及調參。在最初的嘗試中,我只是簡單的進行了資料歸一化,得到的結果並不理想,很多次訓練的RNN模型有RMSE>0.00155的情況。在認真探索每個資料特徵的意義並根據它們的意義進行資料處理後,採取的模型幾乎全部RMSE<0.00150。我想,思考特徵的特點並思考如何利用是十分關鍵的。畢竟說白了,這些模型只是泛用函式擬合器。未來的工作豐富訂單簿資訊。可以獲得AskPrice2, AskPrice3,… 以及AskVolumn2,AskVolumn3等豐富資訊。採取更多的輸入時間點。畢竟過去的資料是“免費”的,我們可以採用如過去一分鐘的資料進行預測。但可能結果和MN的情況一樣——再多的資料只是噪聲。豐富資料集。用更多股票和更長時間的資料。RNN模型的泛化能力沒有被完全利用,我想通過更多的資料可以達到更好的效果。嘗試XGboost的精細調參。
模型融合。如XGBoost+LightGBM+LSTM。
如果你想要本次分享Pine語言策略的文字程式碼,歡迎加小編微信,與我交流。


往期乾貨分享推薦閱讀
如何使用TradingView(TV)回測數字貨幣交易策略
如何投資股票型基金?什麼時間買?買什麼?
【數量技術宅|量化投資策略系列分享】基於指數移動平均的股指期貨交易策略
AMA指標原作者Perry Kaufman 100+套交易策略原始碼分享
【 數量技術宅 | 期權系列分享】期權策略的“獨孤九劍”
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
【數量技術宅|量化投資策略系列分享】成熟交易者期貨持倉跟隨策略
如何獲取免費的數字貨幣歷史資料
【數量技術宅|量化投資策略系列分享】多週期共振交易策略
【數量技術宅|金融資料分析系列分享】為什麼中證500(IC)是最適合長期做多的指數
商品現貨資料不好拿?商品季節性難跟蹤?一鍵解決沒煩惱的Python爬蟲分享
【數量技術宅|金融資料分析系列分享】如何正確抄底商品期貨、大宗商品
【數量技術宅|量化投資策略系列分享】股指期貨IF分鐘波動率統計策略
【數量技術宅 | Python爬蟲系列分享】實時監控股市重大公告的Python爬蟲
&n