
資料庫倉庫系列:(一)什麼是資料倉庫,為什麼要資料倉庫
**八哥**
羅拉,工作很忙嗎?加班這麼晚?還悶悶不樂的?
|
**羅拉**
哎,工作的事情,煩死了...| | |**八哥**
啥工作,說出來開心...額,說出來我看看能不能幫你
|
**羅拉**
最近公司搞了一個營銷月活動,領導想看最近一個月每個使用者消費情況,
包括按照年齡、性別、地址之類的分佈。| | |
**八哥**
這個不是很常規的需求嗎?應該不難吧?
|**羅拉**
需求看起來很簡單,但是當我實際想統計的時候就一臉懵逼了| | |**八哥**
嗯,你說說看,難的點在哪裡?
|
**羅拉**
這個需求中我們至少需要==全量使用者資訊、使用者消費記錄、產品清單==如果這三玩意在一個數據庫中我們容易就做到這個需求,
可是這些分別在==mysql,mongoDB、hdfs檔案==中
我想關聯得經過重重轉換,想想都頭大...| | |
**八哥**
等等,聽你這麼說,
你們公司現在的資料來源很多,然後就這麼堆著?
每次都拿原始資料來做分析?
|
**羅拉**
對啊,不然捏,其實一開始還好,但是現在隨著公司發展,業務越來越多,越來越難搞了
每次弄個數據就怕遇到不同儲存介質的,需要轉來轉去
還有經常做重複的東西。浪費時間| | |
**八哥**
不是,你們這情況就沒想過弄個數據倉庫嗎?
|
**羅拉**
資料倉庫?沒有,但好像聽過,那是什麼玩意兒?給我說說| | |**八哥**
額,好吧,給你說說
os:完蛋,好像給自己挖坑了...
| --- ### 舉個栗子 說到資料倉庫,和資料庫一字之差。那就不得不說一下他們之間的關係了。 首先我們先舉個栗子,先初步認識一下兩者的關係。 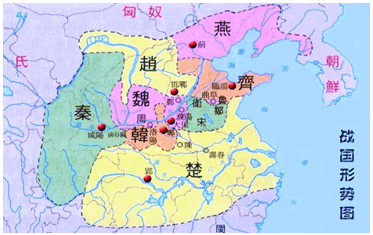 上圖是我們戰國時期的形勢圖。 我們耳熟能詳的戰國七雄:齊、楚、秦、燕、趙、魏、韓。 戰國時期,能人輩出,各國都實行不同的方案發展自身,七個國家基本都有過一段時間興盛時期。 但是這個時候東周還沒有滅亡,明面上,周天子才是天才正統,七國還是屬於分封國家。 分封國管理自己內部的事務,比如賦稅、練兵、教育等,周天子一般不會干涉(好像後面也沒啥能力干涉),但是周天子有需求,比如勤王,那麼諸侯國理論上就要接受周天子的調遣。 在這個例子中,周王朝可以類比資料倉庫,諸侯國可以類比資料庫。(當然,這個類比不太準確,但是大家可以有個統籌的概念)。 --- 那麼,回到羅拉工作的問題,公司的資料來源很多,導致我們每進行一個數據統計都需要很多複雜的操作。 比如,羅拉公司中資料來源有以下幾種  而我們需要統計的資訊涉及到上面的所有資料來源,我們必須把上面的資料都集中到一個儲存介質中才能進行關聯。 然而,即使我們這次需求做完了,如果我們需求有一點變化,我們可能都得重頭來一遍。 比如這次我要計算最近七天消費分佈,下次我要計算最近30天甚至最近半年、一年的指標。 由於我們之前只計算了近七天的指標,那對於其他的指標我們只能重新計算, 甚至可能出現數據源過大,如果儲存介質選擇不當,導致計算效率低下的問題。 為了解決這個問題,我們可以借鑑上面戰國七雄的例子,設計一個數據倉庫。 其結構圖如下: 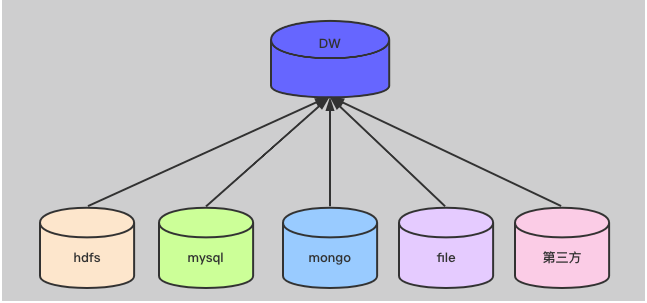 而我們要做的就是的目標就是搗鼓出一個DW。讓我們的資料更加規範。 接下來我們就開始資料倉庫方面的一些介紹。 --- ### 什麼是資料倉庫 #### 資料倉庫的定義 資料倉庫(Data Warehouse)是一個面向主題的(Subject Oriented)、整合的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化的(Time Variant)資料集合。用於支援管理決策(Decision Making Support)。 > 具體的含義後續介紹 #### 資料庫與資料倉庫的區別 **從邏輯、概念層面來看** 資料倉庫和資料庫其實是一樣的,它們都是通過某種資料庫軟體,基於某種資料模型來組織管理資料。 但是他們的側重點不同: 通常資料庫更關注業務交易處理(OLTP)層面; 而資料倉庫關注資料分析(OLAP)層面。 這導致二者之間在一些方面有明顯的區別: 資料庫(DataBase) | 資料倉庫(Data Warehouse) ---|--- 表結構相對複雜| 表結構相對簡單 儲存結構相對緊湊| 儲存結構相對鬆散 較少資料冗餘 |較多資料冗餘 一般讀、寫都有優化 | 一般只有讀優化 相對簡單的讀、寫查詢|相對複雜的讀查詢 單次操作資料量較少|單次操作涉及資料量相對較大 通過上面的對比,結合實際使用,我們可知,資料庫一般都會追求響應速度、資料的一致性等特點。 所以我們在設計資料庫模型上一般都會遵循一些正規化,比如``1NF、2NF、3NF``等。 目的都是為了減少資料的冗餘和相應速度等。 而資料倉庫強調的是資料分析的效率,複雜查詢的響應速度和資料之間的相關性之類的分析。 所以,資料倉庫一般都是多維模型,有較多的資料冗餘,但是同時查詢的效率也會提高。 > 這裡的複雜查詢不是指一個複雜的sql,而是資料倉庫建好後,通過完善的資料指標簡化原本複雜查詢的需求。 所以,從某種意義上來說,資料倉庫就是==反正規化設計==的資料庫 ---- ### 為什麼要資料倉庫 通過上看的對資料庫和資料倉庫的對比,羅拉還是有點似懂非懂。 好像懂了,但是就是不太明白,資料倉庫和資料庫的實際分工。 就是為什麼要資料倉庫? 我如果把所有資料來源都放到一個庫裡面的是不是就是資料倉庫? 也對,上面的文字太過空泛,就好像在上思修課,聽了都想睡覺。 那下面八哥就結合圖文和羅拉公司的案例,給大家扯一扯資料倉庫的作用吧。 --- #### 一般公司的三個階段與架構演變 以羅拉的公司為例,公司主要的業務是生產化妝品,主要通過線上銷售,也就是我們說的電商。 一般來說,電商公司會有三個階段。(當然,掛得早也許就沒有第二、第三階段了) ##### 第一階段 幾個人,甚至一個人,找個地方,弄個伺服器,做個下單的頁面,搞個mysql。 放個鞭炮就可以開門營業了,這個時候屬於初創階段。 我們的資料很簡單,並且數量也比較少,可能就只有簡單的銷售記錄。 此時的架構如下: 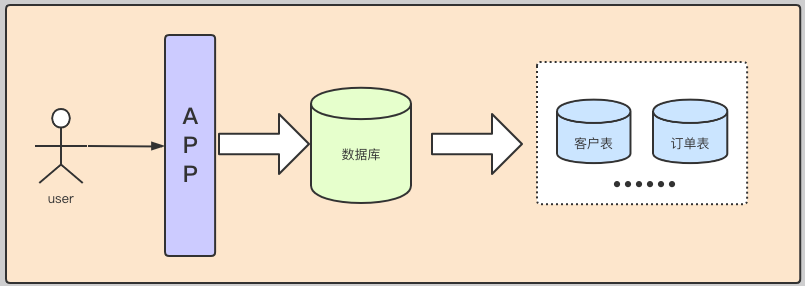 基本我們的統計需求都可以通過簡單的查詢實現,並且伺服器也沒啥壓力,速度槓槓滴。 ##### 第二階段 由於經營有方,我們獲得訂單越來越多,招聘了一些員工,產生的資料量也越來越多, 並且有了一些運營推廣的需求,我們儲存的資料型別也越來越多。 單庫,單伺服器已經撐不住了。 於是我們升級了架構:變成了多伺服器和多業務庫(即分庫分表)。 此時的架構如下: 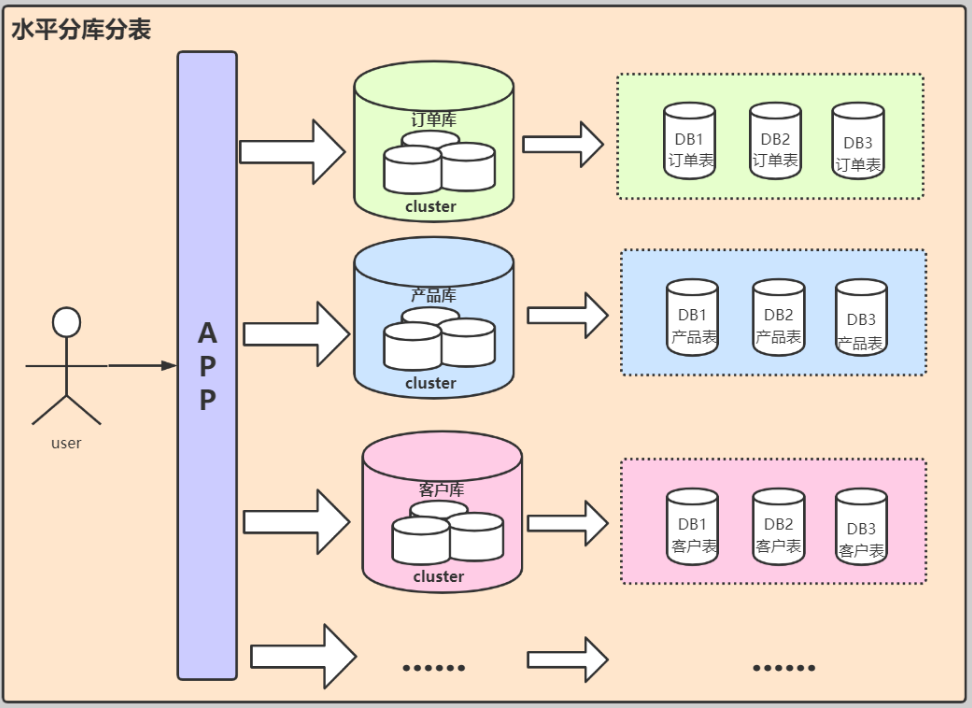 這個時候我們還能通過複雜的語句從業務庫查詢我們需要的指標。 ##### 第三階段 隨著口碑越來越好,我們獲得客戶和訂單指數級別增加,招的員工越來越多。 分工也從大家都是領導到有ceo、cto、cfo、cio等。辦公地方也換到更加高大上的地方。 隨著團隊越來越專業,營銷手段、經營策略也會越來越專業。 而這一些都需要資料的支撐。 但是我們現在需要的資料非常專業或非常全面。 比如以前我們只關心“日營收、月營收、營收同比、環比等”。 但是我們現在為了精準營銷,我們更關注“客戶性別比例、年齡分層、消費分級、地域差異、消費組成、回購率”等更加細分的資料。 這個時候我們關注的都是一些非常精細化和使用者叢集分析。這些一般都能對公司的決策起到關鍵性作用。 那麼這個時候,之前的業務庫基本無法支撐我們的資料需求了,我們就需要建立一個數據倉庫來支援管理決策。 看來羅拉公司發展不錯,公司正處於第二到第三階段的時候。也就是需要建立資料倉庫的時候。 這個時候的架構一般都是以下面的結構為藍圖: 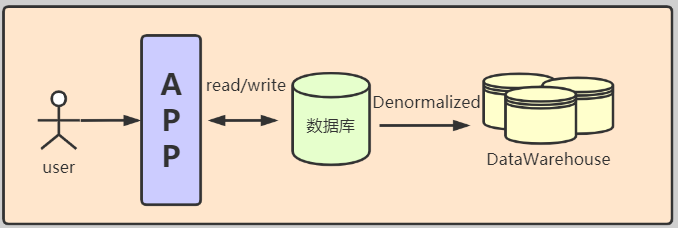 如果需要分不同的組或資料隔離、以免相互影響,除了配置許可權,也可能會通過配置資料目錄(Data Catalog)來實現目的。 此時架構會變成下面的樣子: 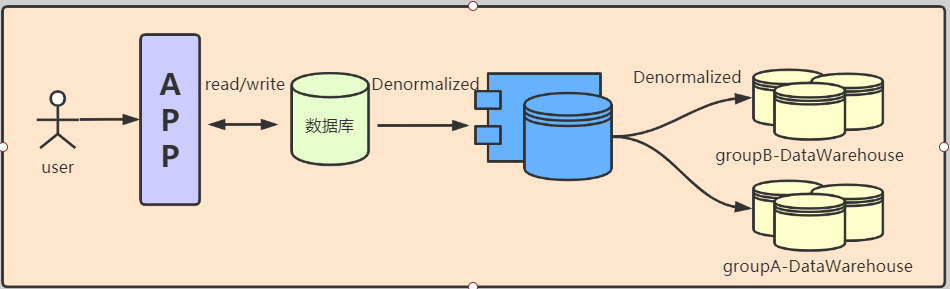 > 實際中的架構,無論哪個階段都會比圖中的複雜,但是基本以此為藍圖進行拓展。 ---- #### 為什麼要資料倉庫? 通過對上面三個階段的分析,我們其實很容易得出一個結論,我們建立資料倉庫最懂得目的就是要把**事務處理與資料分析解耦合**,增加系統的可拓展性。 解不解耦合其實就是業務庫與資料倉庫的關係,之前我們簡單介紹了資料庫與資料倉庫的區別。 這裡我們稍微嘮嗑深一點。如果我們解耦合與不解耦合會有什麼差別 --- #### 不解耦合 如果我們不解耦合,也就是我們的資料分析直接來自業務庫,導致幾個問題資料分析的時候。 ##### 結構複雜、大規模查詢慢 業務庫一般是針對業務專門設計的,為了減少資料冗餘,會遵循3NF正規化。 這就導致表之間的關係其實是一張網,通過外來鍵、主鍵之類的進行關聯。 我們很多的業務表資訊都是一堆編碼,通過編碼去關聯詳情。 如下: 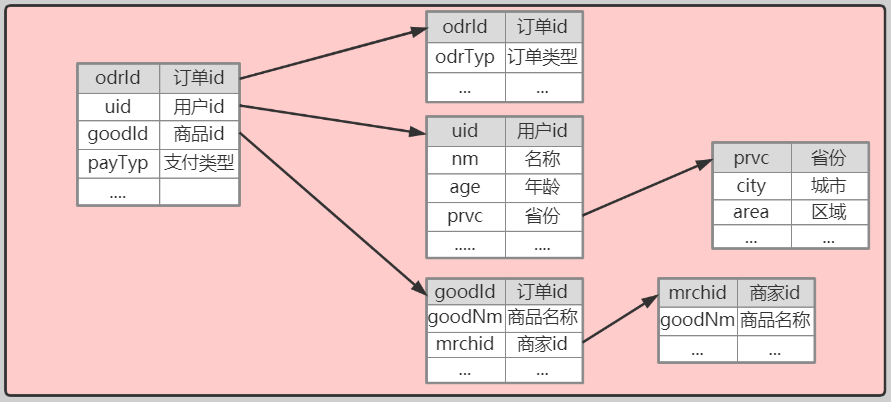 此時如果對於一些資料分析涉及到具體詳情資訊,我們可能需要通過多層關聯才能得到,這就給分析資料增加很大的複雜度。 此時如果每個表都是大表,資料量都很大,那麼我們就可以帶薪蹲坑了(編碼一分鐘,執行九分鐘)。 如果在同一個資料庫還能勉強做,如果想羅拉那樣,資料滿天星,mysql、mongo、hdfs哪裡都有的話,老實說這個時候做關聯操作實在是有心無力。 ##### 髒資料亂入 業務庫一般儲存了所有的業務資料,與此同時,在業務過程中可能猶豫各種原因比如網路、宕機、資料校驗不完善等原因,會產生一些列髒資料。 髒資料包括但不限於一下情況: 髒資料情況 | 案例 :---:|:---: 核心資料為空 | uid、odrId為null 資料不合法 | 手機號碼、身份證、日期之類的不符合規範 資料錯誤 | 比如線上時長、登陸時長超過合理值 資料重複 | 資料重複上報 如果我們在做資料分析的時候還得對於所有的髒資料再處理一次,那這效率,像羅拉這樣加班就算了。 如果拿資料支援管理決策,一不小心因為處理髒資料不完善,搞個錯誤資料,誤了公司決策,這個鍋你背得動嗎? ##### 無法反應歷史 業務庫一般的不會儲存很長曆史的資料以保證響應速度,這樣對於我們需要做一個歷史衍變、趨勢之類的資料分析,單靠業務庫就已經很難實現了。 而歷史趨勢對於我們後續的決策是很有借鑑意義。 比如營收,銷量之類的做個歷史分析  如果我們的資料分析,都和業務庫扯在一起,至少上面的問題基本都會有。 如果我們把資料分析部分拆出來呢? 當然就是通過解耦合啦 ---- #### 解耦合 業務庫服務業務,我們通過建立資料倉庫達到業務處理與資料分析分離的目的。 如果我們的資料倉庫設計的合理,那麼會極大提高我們資料分析人員資料分析的效率和質量。 究其主要是基於以下幾點。 --- ##### 表結構清晰 我們資料倉庫一般都是通過etl一天更新一次,對於每天的資料量我們都是心裡有數的,並且為了分析方便,我們會刻意冗餘資料。 在資料倉庫中,我們資料的設計模型(詳細的模型分類後面再說)一般採用星型結構。 主要有兩部分組成:事實表、維度表 - 事實表 處於星星結構的中心,儲存某種業務各個維度的資料,其中各個維度一般都是對應編碼。 比如訂單表: 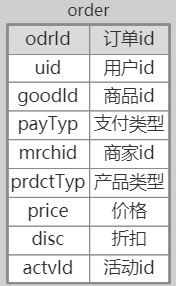 - 維度表 維度表可以看作是事實表的發散表,對應著事實表裡面的每一個維度。根據我們的需要,我們可以選擇我們需要的維度進行分析關聯。 比如下面的表: 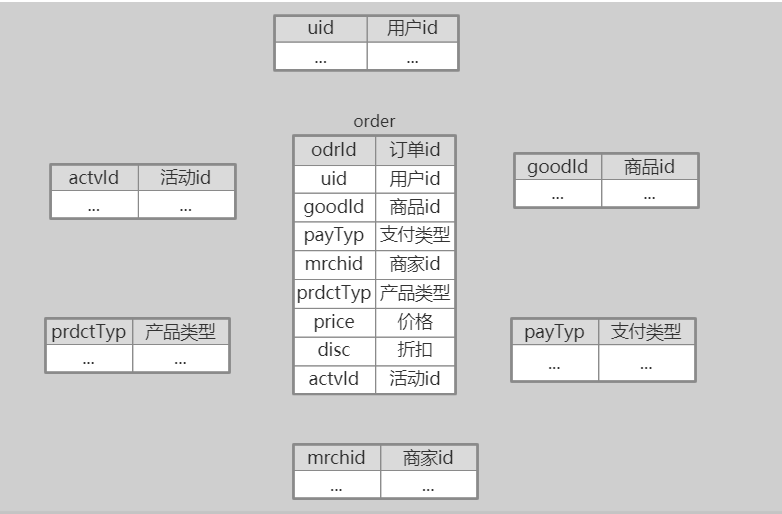 這個時候我們分析資料的步驟就變成了下面模式化的步驟: 1. 選擇分析主題(營收、登陸、時長等) 2. 找相關業務表(即營收事實表、登陸事實表、時間事實表等) 3. 根據分析資料需求確定維度(即確定事實表需要關聯的維度表) 4. 計算結果(關聯需要的維度後計算結果) 通過以上設計,表結構簡單清晰,資料分析的步驟規範、易於理解。 ##### 無髒資料 之前我們直接用業務庫的資料,可能存在各種各樣的髒資料。 在資料倉庫中,我們對於模型在設計方面最基本的要求有幾點: 1. 資料欄位型別統一:同一個含義的欄位要型別一致(比如,登陸、消費都有使用者id,要麼都是``int``、要麼都是``string``)。 2. 命名要規範:採用駝峰或分隔要統一,切勿混用,不要出現``usrId,musr_id``同時出現的情況 3. 相同含義的欄位保持一致:比如手機號碼,決定用``msdn`` 就不要在出現``phoneNumber`` 之類的 4. 預設值處理:對於預設值或異常錯誤的資料要有預設值。方便分析的時候刪選過濾。 5. 欄位命名可理解:不要亂七八糟亂取名字,便於理解的名字,最好維護一個英文縮寫表。 為了達到上面的需求,我們每天都會通過etl對業務資料進行處理。 髒資料對我們資料分析的影響很大,所以對於每一個業務,我們在etl的資料清洗過程中就對髒資料進行處理,同時把業務資料按照我們資料模型設計的規範匯入到資料倉庫。 這樣我們在資料分析的過程中就不需要要費勁處理髒資料了,頂多就一個過濾。 ##### 反應歷史 資料倉庫一般都是採用分散式儲存,典型的就是基於hive的資料倉庫。我們可以儲存大量的歷史資料。 可以支撐我們做歷史分析。 ##### 快速複雜查詢 正如八哥前面說過的,快速複雜查詢不是說執行一個複雜的sql能夠很快返回結果。 而是我們通過建立合理、規範的資料倉庫,似的原本在業務苦衷需要通過各種關聯才得到的結果在資料倉庫中可以用過簡單關聯和計算舊的到結果。 單靠倉庫本身的比如hive查詢可能需要花費較長的時間,因為基於mapreduce,是硬傷,但是我們可以通過將構建多維查詢比如通過kylin、druid、clickhouse等將所有的查詢可能儲存下來,達到秒級查詢效率也是可以。 ---- ### 總結 通過上面的介紹,我們可以對資料倉庫做一句話總結: **資料倉庫就是為了業務處理和資料分析解耦的**。 至於如何設計一個數據倉庫,我們後面繼續再繼續。 歡迎關注【兔八哥雜談】,會持續分享更多內