
水庫抽樣演算法
阿新 • • 發佈:2020-12-19
整理自《大資料演算法》(王志巨集 哈爾濱工業大學)31頁
問題描述
給定一個數據流,從這個流中進行均勻取樣。
要求在接收到n個數據後,能夠等概率地輸出其中的k個數據。
已知n遠大於k,且現有的記憶體空間無法容納所有資料。
演算法描述
準備一個長度為k的陣列用於儲存樣本。
將接收到的前k個數據儲存在陣列中,
然後對於後續的第i個數據(i > k),擲出一個0~(i-1)之間的隨機數,
如果隨機數小於k/i,則用第i個數據替換陣列中的某個資料,替換位置通過擲出一個0~(k-1)之間的隨機數來決定。
如果隨機數不小於k/i,則捨棄第i個數據。
這樣在接收到多於k個數據後,陣列中保留的資料即為當前已接收資料的一個均勻抽樣。
演算法分析
按照常規的做法,保留n個數據然後從中均勻抽取k個樣本,每個資料被抽取的概率為
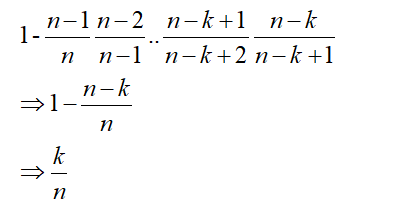
那麼當前這個問題的演算法也要保證每個資料被留在陣列中的概率為k/n。
假設已經獲得了前(n-1)個數據的k個均勻抽樣,現在再加入第n個數據,則第n個數據應該有k/n的概率被保留到陣列。
而陣列中原有的資料,被替換掉的概率為
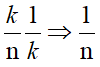
再算上它們之前被選取為樣本的概率k/(n-1),此時每個原有資料被保留下來的概率為
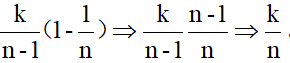
可見對於新資料和原有資料來說,它們被保留為樣本的概率都是相同的。
那麼前(n-1)個數據的k個均勻抽樣要如何獲得呢?這裡可以令n = k+1,此時n-1=k,k個樣本是唯一確定的。
藉助上述演算法就可以得到k+1個數據的均勻抽樣。迴圈利用上述演算法就能進一步得到前k+2、k+3、k+4個數據的均勻抽樣,由此可以推廣到任意n > k的情景。
演算法的有效性得以證