
被 Pandas read_csv 坑了
阿新 • • 發佈:2020-12-20
## 被 Pandas read_csv 坑了
-- 不怕前路坎坷,只怕從一開始就走錯了方向
**Pandas** 是python的一個數據分析包,納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具。Pandas 就是為解決資料分析任務生的,無論是資料分析還是機器學習專案資料預處理中, Pandas 無處不在。
最近掉進一坑,差點鑄成大錯。實在沒想到居然栽在pandas.read_csv上了,這裡分享一下,希望大家注意。
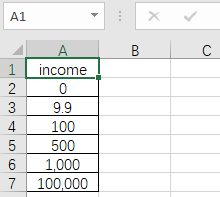
另:業務資料不方便拿出來演示,為儘可能復現,這裡我手造了一份,另存為 income.csv 檔案。
## 翻船記
讀取csv檔案小菜一碟
```
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:\...\income.csv',encoding='utf-8')
```
讀好了看看資料資訊吧:
```
df.info()
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 6 non-null object
dtypes: object(1)
memory usage: 176.0+ bytes
```
誒,怎麼資料成了object?不應該是float嗎?
不管他,硬轉一發
```
df=pd.DataFrame(df,dtype=np.float)
```
居然報錯了,1000被讀成了字串。
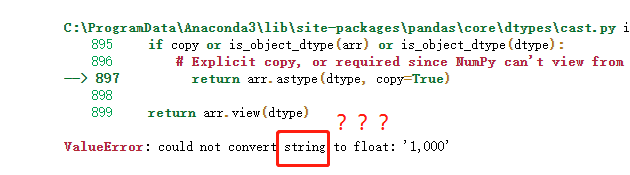
其實這裡我還掉進了另一個坑,使用了一個已被棄用的 .convert_objects 方法。這種方法更硬,直接把string轉成了NaN,所以後面各種操作流暢且錯誤地進行著....這都是 pandas 沒升級的鍋,定期檢查升級包太有必要了([pip 的高階玩法](https://mp.weixin.qq.com/s?__biz=MzA4MjYwMTc5Nw==&mid=2648944700&idx=1&sn=c9d663a96bbd72a67e6946e24494ad9d&chksm=87942216b0e3ab001e185612eb465dcc8b192b3bf06ba191889cd7d00c03b1d6149500870e8e&token=1454358884&lang=zh_CN#rd))
說回剛才的問題,1,000被讀成了字串是因為csv檔案中它使用了千位分隔符。問題其實非常簡單,設定一下 **thousands** 引數就行了
```
df2 = pd.read_csv(r'C:\...\income.csv',encoding='utf-8',thousands =',')
```
看一下info
```
df2.