
Java記憶體模型精講
阿新 • • 發佈:2021-01-06
## 1.JAVA 的併發模型
***共享記憶體模型***
在共享記憶體的併發模型裡面,**執行緒之間共享程式的公共狀態**,執行緒之間通過讀寫記憶體中公共狀態來進行隱式通訊
該記憶體指的是**主記憶體**,實際上是實體記憶體的一小部分
## 2.JAVA 記憶體模型的抽象
### 2.1 java記憶體中哪些資料是執行緒安全的,哪些是非安全的
1. 非執行緒安全 : 在 java 中所有的例項域、靜態域、和陣列元素都存放在**堆記憶體**中,並且這些資料是**執行緒共享**的,所以會存在記憶體可見性問題
2. 執行緒安全 : 區域性變數、方法定義的引數、異常處理器引數是**當前執行緒**的**虛擬機器棧**中的資料,並且不會進行**執行緒共享**,所以不會存在記憶體可見性問題
### 2.2 執行緒間通訊的本質
1. 執行緒間通訊的本質是 :**JMM**即 JAVA 記憶體模型進行控制,JMM決定了一個執行緒對共享變數的寫入何時對其他執行緒可見。
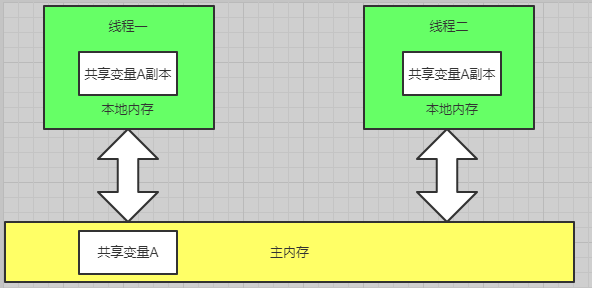
由上圖能看出來執行緒間的通訊都是通過主記憶體來進行傳遞訊息的, 每個執行緒在進行共享資料處理的時候都是將共享的資料**複製**到當前執行緒本地(每個執行緒自己都有一個記憶體)來進行操作。
2. **訊息通訊過程**(不考慮資料安全性的問題) :
* 執行緒一將主記憶體中的共享變數 A 載入到自己的本地記憶體中進行處理。比如 A = 1;
* 此時將修改的共享變數 A 刷入到主記憶體中, 之後執行緒二再將主記憶體中的共享變數 A 讀取到本地記憶體進行操作;
**整個資料互動的過程是JMM控制的,主要控制主記憶體與每個執行緒的本地記憶體如何進行互動來提供共享資料的可見性**
## 3.重排序
程式在執行的時候為了提高效率會將程式指令進行重新排序
### 3.1 重排序分類
* 編譯器優化重排序
編譯器在不改變單執行緒程式語義的情況下進行語句執行順序的優化
* 指令集並行重排序
如果不存在資料的依賴性的話,處理器可以改變語句對應機器指令的執行順序
* 記憶體系統重排序
由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行
### 3.2 重排序過程
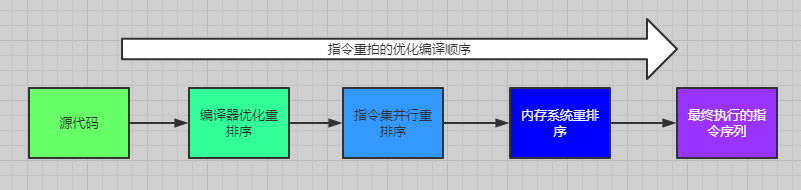
以上三種重排序都會導致我們在寫併發程式的時候出現記憶體可見性的問題。
JMM的編譯器重排序規則會禁止特定型別的編譯器重排序;
JMM的處理器重排序規則會要求java編譯器在生成指令序列的時候插入特定的**記憶體屏障指令**,通過記憶體屏障指令來禁止特定型別的處理器進行重排序
### 3.3 處理器重排序
由於為了避免處理器等待向記憶體中寫入資料的延時,在處理器和記憶體中間加了一個**緩衝區**,這樣處理器可以一直向緩衝區中寫入資料,等到一定時間將緩衝區的資料一次性的刷入到記憶體中。
優點 :
1. 處理器不同停頓,提高了處理器的執行效率
2. 減少在向記憶體寫入資料時的記憶體匯流排的佔用
缺點 :
1. 每個處理器上的寫緩衝區只對當前處理器可見,所以就會造成記憶體操作的執行順序和實際情況不符合
例如以下場景 :
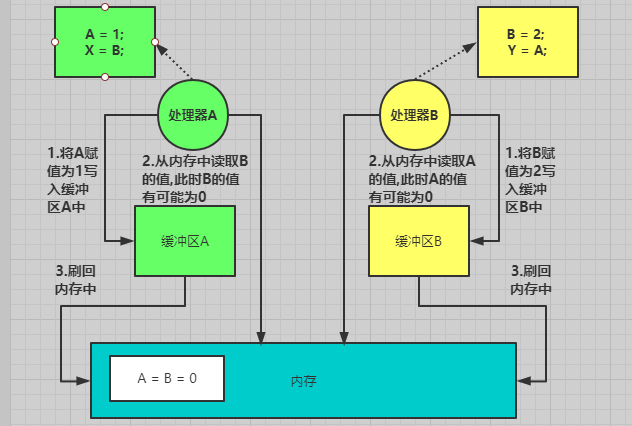
在當前場景中就可能出現在處理器 A 和處理器 B 沒有將它們各自的寫緩衝區中的資料刷回記憶體中, 將記憶體中讀取的A = 0、B = 0 進行給X和Y賦值,此時將緩衝區的資料刷入記憶體,導致了最後結果和實際想要的結果不一致。**因為只有將緩衝區的資料刷入到了記憶體中才叫真正的執行**
以上主記憶體與工作記憶體之間的具體**互動協議**,即一個變數如何從**主記憶體拷貝到工作記憶體**,如何從**工作記憶體同步到主記憶體**之間的實現細節,JMM定義了以下8種操作來完成
|操作|語義解析|
|:----|:----|
|lock(鎖定)|作用於主記憶體的變數,把一個變數標記為一條執行緒獨佔狀態|
|unlock(解鎖)|作用於主記憶體的變數,把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定|
|read(讀取)|作用於主記憶體的變數,把一個變數值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的load動作使用|
|load(載入)|作用於工作記憶體的變數,它把read操作從主記憶體中得到的變數值放入工作記憶體的變數副本中|
|use(使用)|作用於工作記憶體的變數,把工作記憶體中的一個變數值傳遞給執行引擎|
|assign(賦值)|作用於工作記憶體的變數,它把一個從執行引擎接收到的值賦給工作記憶體的變數|
|store(儲存)|作用於工作記憶體的變數,把工作記憶體中的一個變數的值傳送到主記憶體中,
以便隨後的write的操作| |write(寫入)|作用於工作記憶體的變數,它把store操作從工作記憶體中的一個變數的值傳送
到主記憶體的變數中| 如果要把一個變數從主記憶體中複製到工作記憶體中,就需要按順序地執行read和load操作,如果把變數從工作記憶體中同步到主記憶體中,就需要按順序地執行store和write操作。**但Java記憶體模型只要求上述操作必須按順序執行,而沒有保證必須是連續執行** **操作執行流程圖解:** 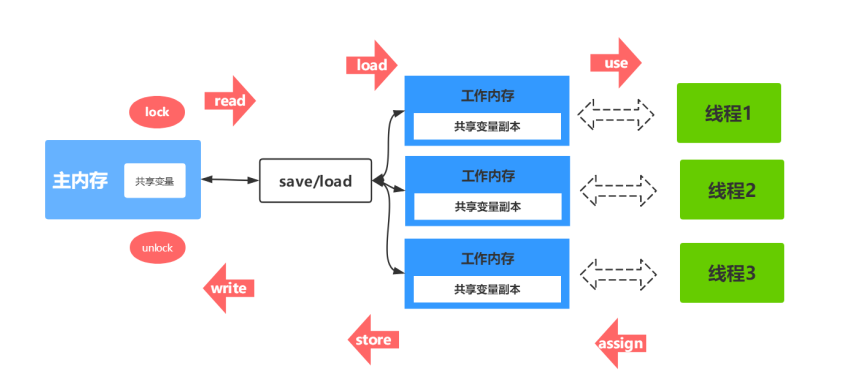 **同步規則分析** 1. 不允許一個執行緒無原因地(沒有發生過任何assign操作)把資料從工作記憶體同步回主記憶體中 2. 一個新的變數只能在主記憶體中誕生,不允許在工作記憶體中直接使用一個未被初始化(load或者assign)的變數。即就是對一個變數實施use和store操作之前,必須先自行assign和load操作。 3. 一個變數在同一時刻只允許一條執行緒對其進行lock操作,但lock操作可以被同一執行緒重複執行多次,多次執行lock後,只有執行相同次數的unlock操作,變數才會被解鎖。lock和unlock必須成對出現。 4. 如果對一個變數執行lock操作,將會清空工作記憶體中此變數的值,在執行引擎使用這個變數之前需要重新執行load或assign操作初始化變數的值。 5. 如果一個變數事先沒有被lock操作鎖定,則不允許對它執行unlock操作;也不允許去unlock一個被其他執行緒鎖定的變數。 6. 對一個變數執行unlock操作之前,必須先把此變數同步到主記憶體中(執行store和write操作) ### 3.4 記憶體屏障指令 為了解決處理器重排序導致的記憶體錯誤,java編譯器在生成指令序列的適當位置插入**記憶體屏障指令**,來禁止特定型別的處理器重排序 **記憶體屏障指令** |屏障型別|指令示例|說明| |:----|:----|:----| |LoadLoadBarriers|Load1;LoadLoad;Load2|Load1資料裝載發生在Load2及其所有後續資料裝載之前| |StoreStoreBarriers|Store1;StoreStore;Store2|Store1資料刷回主存要發生在Store2及其後續所有資料刷回主存之前| |LoadStoreBarriers|Load1;LoadStore;Store2|Load1資料裝載要發生在Store2及其後續所有資料刷回主存之前| |StoreLoadBarriers|Store1;StoreLoad;Load2|Store1資料刷回記憶體要發生在Load2及其後續所有資料裝載之前| ### 3.5 happens-before(先行規則) happens-before 原則來輔助保證程式執行的原子性、可見性以及有序性的問題,它是判斷資料是否存在競爭、執行緒是否安全的依據 在JMM中如果一個操作中的結果需要對另一個操作**可見**,那麼這兩個操作之前必須要存在**happens-before**關係 (兩個操作可以是同一個執行緒也可以不是一個執行緒) **規則內容**: * 程式順序規則 : 指的是在一個執行緒內控制程式碼順序,比如分支、迴圈等,即在一個執行緒內必須保證語義序列性,也就是說按照程式碼順序執行 * 加鎖規則 : 一個解鎖(unlock)操作一定要發生於一個加鎖(lock)操作之前,也就是說,如果對於一個鎖解鎖後,再加鎖,那麼加鎖的動作必須在解鎖動作之後(同一個鎖) * volatile變數規則 : 對一個volatile的變數的寫操作要發生在對這個變數的讀操作之前,這保證了volatile變數的可見性,簡單的理解就是,volatile變數在每次被執行緒訪問時,都強迫從主記憶體中讀該變數的值,而當該變數發生變化時,又會強迫將最新的值重新整理到主記憶體,任何時刻,不同的執行緒總是能夠看到該變數的最新值 * 執行緒啟動規則 : 執行緒的啟動方法 start() 要發生在當前執行緒所有操作之前 * 執行緒終止規則 : 執行緒中所有的操作都要發生線上程終止之前,Thread.join()方法的作用是等待當前執行的執行緒終止。假設線上程B終止之前,修改了共享變數,執行緒A從執行緒B的join方法成功返回後,執行緒B對共享變數的修改將對執行緒A可見 * 執行緒中斷規則 : 執行緒呼叫interrupt()方法要發生在被中斷執行緒的程式碼檢查出中斷事件之前 * 物件終結規則 : 物件的初始化完成要發生在物件被回收之前 * 傳遞性規則 : 如果操作 A 發生在操作 B 之前,操作 B 又發生在操作 C 之前,那麼操作A一定發生於操作 C 之前 **注意**: 兩個操作之間具有 happens-before 關係,並不意味著前一個操作必須要在後一個操作之前執行,只需要前一個操作的結果對後一個操作可見,並且前一個操作按順序要排在後一個操作之前。 ### 3.6 資料依賴性 就是前一個操作的結果對後一個操作的結果產生影響,此時編譯器和處理器在處理當前有資料依賴性的操作時不會改變存在**資料依賴**的兩個操作的執行順序 **注意**: 此時所說的資料依賴僅僅針對**單個處理器**中執行的指令序列或者**單個執行緒**中執行的操作。*不同處理器和不同執行緒的情況編譯器和處理器是不會考慮的* ### 3.7 as-if-serial 在**單執行緒**情況下不管怎麼重排序程式的執行結果不能被改變,所以如果在單處理器或者單執行緒的情況下,編譯器和處理器對於**有資料依賴性**的操作是不會進行重排序的。反之如果**沒有資料依賴性**的操作就有可能發生指令重排。 ## 5.資料競爭與順序一致性 **在多執行緒情況下才會出現資料競爭** ### **5.1 資料競爭** 在一個執行緒中寫了一個變數,在另一個執行緒中讀一個變數,而且寫和讀並**沒有進行同步** ### **5.2 順序一致性** 如果在多執行緒條件下,程式能夠正確的使用同步機制,那麼程式的執行將具有順序一致性(就像在單執行緒條件下執行一樣) 程式最終執行的結果與你預期的結果一樣 ### **5.3 順序一致性記憶體模型** 5.3.1**特性**: * 一個執行緒中的所有操作必須按照程式的順序來執行 * 所有的操作都必須是原子性的操作,並且對其他執行緒可見的 5.3.2**概念:** 在概念上,順序一致性有一個單一的全域性記憶體,在任意時間點最多隻有一個執行緒可以連線到記憶體,當在多執行緒的場景下,會把所有記憶體的讀寫操作變成序列化 5.3.3**案例:** 例如有多個併發執行緒 A B C, A 執行緒有兩個操作 A1 A2, 他們的執行的順序是 A1 -> A2 。B 執行緒有三個操作 B1 B2 B3, 他們的執行的順序是 B1 -> B2 ->B3 。C 執行緒有兩個操作 C1 C2 那麼他們在程式中執行的順序是 C1 -> C2 。 **場景分析 :** 場景一 : 併發安全(同步)執行順序 A1 -> A2 -> B1 -> B2 ->B3 -> C1 -> C2 場景二: 併發不安全(非同步)執行順序 A1 -> B1 -> A2 -> C1 -> B2 ->B3 -> C2 **結論 :** 在非同步的場景下,即使三個執行緒中的每一個操作亂序執行,但是在每個執行緒中的各自操作還是保持有序的。並且所有執行緒都只能看到一個一致的整體執行順序,也就是說三個執行緒看到的都是該順序 : A1 -> B1 -> A2 -> C1 -> B2 ->B3 -> C2 ,因為順序一致性記憶體模型中的每個操作必須立即對任意執行緒可見。 **以上案例場景在JMM中不是這樣的,未同步的程式在JMM中不僅整體的執行順序變了,就連每個執行緒的看到的操作執行順序也是不一樣的**。 例如前面所說的如果執行緒A將變數的值 a = 2 寫入到了自己的本地記憶體中,**還沒有刷入到主存中,線上程 A 來看值是變了,但是其他執行緒 B 執行緒 C 根本看不到值的改變,就認為執行緒A 的操作還沒有發生,只有執行緒 A 將工作記憶體中的值刷回主記憶體執行緒 B和執行緒C 才能的到。但是如果是同步的情況下,順序一致性模型和JMM模型執行的結果是一致的,但是程式的執行順序不一定,因為在JMM中,會發生指令重排現象所以執行順序會不一
以便隨後的write的操作| |write(寫入)|作用於工作記憶體的變數,它把store操作從工作記憶體中的一個變數的值傳送
到主記憶體的變數中| 如果要把一個變數從主記憶體中複製到工作記憶體中,就需要按順序地執行read和load操作,如果把變數從工作記憶體中同步到主記憶體中,就需要按順序地執行store和write操作。**但Java記憶體模型只要求上述操作必須按順序執行,而沒有保證必須是連續執行** **操作執行流程圖解:**  **同步規則分析** 1. 不允許一個執行緒無原因地(沒有發生過任何assign操作)把資料從工作記憶體同步回主記憶體中 2. 一個新的變數只能在主記憶體中誕生,不允許在工作記憶體中直接使用一個未被初始化(load或者assign)的變數。即就是對一個變數實施use和store操作之前,必須先自行assign和load操作。 3. 一個變數在同一時刻只允許一條執行緒對其進行lock操作,但lock操作可以被同一執行緒重複執行多次,多次執行lock後,只有執行相同次數的unlock操作,變數才會被解鎖。lock和unlock必須成對出現。 4. 如果對一個變數執行lock操作,將會清空工作記憶體中此變數的值,在執行引擎使用這個變數之前需要重新執行load或assign操作初始化變數的值。 5. 如果一個變數事先沒有被lock操作鎖定,則不允許對它執行unlock操作;也不允許去unlock一個被其他執行緒鎖定的變數。 6. 對一個變數執行unlock操作之前,必須先把此變數同步到主記憶體中(執行store和write操作) ### 3.4 記憶體屏障指令 為了解決處理器重排序導致的記憶體錯誤,java編譯器在生成指令序列的適當位置插入**記憶體屏障指令**,來禁止特定型別的處理器重排序 **記憶體屏障指令** |屏障型別|指令示例|說明| |:----|:----|:----| |LoadLoadBarriers|Load1;LoadLoad;Load2|Load1資料裝載發生在Load2及其所有後續資料裝載之前| |StoreStoreBarriers|Store1;StoreStore;Store2|Store1資料刷回主存要發生在Store2及其後續所有資料刷回主存之前| |LoadStoreBarriers|Load1;LoadStore;Store2|Load1資料裝載要發生在Store2及其後續所有資料刷回主存之前| |StoreLoadBarriers|Store1;StoreLoad;Load2|Store1資料刷回記憶體要發生在Load2及其後續所有資料裝載之前| ### 3.5 happens-before(先行規則) happens-before 原則來輔助保證程式執行的原子性、可見性以及有序性的問題,它是判斷資料是否存在競爭、執行緒是否安全的依據 在JMM中如果一個操作中的結果需要對另一個操作**可見**,那麼這兩個操作之前必須要存在**happens-before**關係 (兩個操作可以是同一個執行緒也可以不是一個執行緒) **規則內容**: * 程式順序規則 : 指的是在一個執行緒內控制程式碼順序,比如分支、迴圈等,即在一個執行緒內必須保證語義序列性,也就是說按照程式碼順序執行 * 加鎖規則 : 一個解鎖(unlock)操作一定要發生於一個加鎖(lock)操作之前,也就是說,如果對於一個鎖解鎖後,再加鎖,那麼加鎖的動作必須在解鎖動作之後(同一個鎖) * volatile變數規則 : 對一個volatile的變數的寫操作要發生在對這個變數的讀操作之前,這保證了volatile變數的可見性,簡單的理解就是,volatile變數在每次被執行緒訪問時,都強迫從主記憶體中讀該變數的值,而當該變數發生變化時,又會強迫將最新的值重新整理到主記憶體,任何時刻,不同的執行緒總是能夠看到該變數的最新值 * 執行緒啟動規則 : 執行緒的啟動方法 start() 要發生在當前執行緒所有操作之前 * 執行緒終止規則 : 執行緒中所有的操作都要發生線上程終止之前,Thread.join()方法的作用是等待當前執行的執行緒終止。假設線上程B終止之前,修改了共享變數,執行緒A從執行緒B的join方法成功返回後,執行緒B對共享變數的修改將對執行緒A可見 * 執行緒中斷規則 : 執行緒呼叫interrupt()方法要發生在被中斷執行緒的程式碼檢查出中斷事件之前 * 物件終結規則 : 物件的初始化完成要發生在物件被回收之前 * 傳遞性規則 : 如果操作 A 發生在操作 B 之前,操作 B 又發生在操作 C 之前,那麼操作A一定發生於操作 C 之前 **注意**: 兩個操作之間具有 happens-before 關係,並不意味著前一個操作必須要在後一個操作之前執行,只需要前一個操作的結果對後一個操作可見,並且前一個操作按順序要排在後一個操作之前。 ### 3.6 資料依賴性 就是前一個操作的結果對後一個操作的結果產生影響,此時編譯器和處理器在處理當前有資料依賴性的操作時不會改變存在**資料依賴**的兩個操作的執行順序 **注意**: 此時所說的資料依賴僅僅針對**單個處理器**中執行的指令序列或者**單個執行緒**中執行的操作。*不同處理器和不同執行緒的情況編譯器和處理器是不會考慮的* ### 3.7 as-if-serial 在**單執行緒**情況下不管怎麼重排序程式的執行結果不能被改變,所以如果在單處理器或者單執行緒的情況下,編譯器和處理器對於**有資料依賴性**的操作是不會進行重排序的。反之如果**沒有資料依賴性**的操作就有可能發生指令重排。 ## 5.資料競爭與順序一致性 **在多執行緒情況下才會出現資料競爭** ### **5.1 資料競爭** 在一個執行緒中寫了一個變數,在另一個執行緒中讀一個變數,而且寫和讀並**沒有進行同步** ### **5.2 順序一致性** 如果在多執行緒條件下,程式能夠正確的使用同步機制,那麼程式的執行將具有順序一致性(就像在單執行緒條件下執行一樣) 程式最終執行的結果與你預期的結果一樣 ### **5.3 順序一致性記憶體模型** 5.3.1**特性**: * 一個執行緒中的所有操作必須按照程式的順序來執行 * 所有的操作都必須是原子性的操作,並且對其他執行緒可見的 5.3.2**概念:** 在概念上,順序一致性有一個單一的全域性記憶體,在任意時間點最多隻有一個執行緒可以連線到記憶體,當在多執行緒的場景下,會把所有記憶體的讀寫操作變成序列化 5.3.3**案例:** 例如有多個併發執行緒 A B C, A 執行緒有兩個操作 A1 A2, 他們的執行的順序是 A1 -> A2 。B 執行緒有三個操作 B1 B2 B3, 他們的執行的順序是 B1 -> B2 ->B3 。C 執行緒有兩個操作 C1 C2 那麼他們在程式中執行的順序是 C1 -> C2 。 **場景分析 :** 場景一 : 併發安全(同步)執行順序 A1 -> A2 -> B1 -> B2 ->B3 -> C1 -> C2 場景二: 併發不安全(非同步)執行順序 A1 -> B1 -> A2 -> C1 -> B2 ->B3 -> C2 **結論 :** 在非同步的場景下,即使三個執行緒中的每一個操作亂序執行,但是在每個執行緒中的各自操作還是保持有序的。並且所有執行緒都只能看到一個一致的整體執行順序,也就是說三個執行緒看到的都是該順序 : A1 -> B1 -> A2 -> C1 -> B2 ->B3 -> C2 ,因為順序一致性記憶體模型中的每個操作必須立即對任意執行緒可見。 **以上案例場景在JMM中不是這樣的,未同步的程式在JMM中不僅整體的執行順序變了,就連每個執行緒的看到的操作執行順序也是不一樣的**。 例如前面所說的如果執行緒A將變數的值 a = 2 寫入到了自己的本地記憶體中,**還沒有刷入到主存中,線上程 A 來看值是變了,但是其他執行緒 B 執行緒 C 根本看不到值的改變,就認為執行緒A 的操作還沒有發生,只有執行緒 A 將工作記憶體中的值刷回主記憶體執行緒 B和執行緒C 才能的到。但是如果是同步的情況下,順序一致性模型和JMM模型執行的結果是一致的,但是程式的執行順序不一定,因為在JMM中,會發生指令重排現象所以執行順序會不一