
刪庫後除了跑路還能幹什麼?
### 前言 Hi,歡迎訂閱白日夢的MySQL專題! 這篇文章我們一起閒聊,如果你不小心把MySQL中的資料刪了,除了跑路還能幹啥? 看完本篇你將瞭解:常見的資料庫備份方式、mysqldump實戰、一條binlog長啥樣、什麼是gtid?什麼是binlog位點?mysqlbinlog資料恢復實戰。
### 資料備份有哪些種? MySQL中資料備份的方式還是蠻多的,常見的有冷備份、邏輯備份、熱備份、快照備份。
什麼是冷備份? 所謂的冷備份,說白了就是在資料庫停止執行的情況下,直接備份磁碟中MySQL用來儲存資料的那些資料檔案。 在前面的文章中,白日夢跟大家分享過MySQL的表空間。看過那篇文章的同學都是知道,MySQL中的資料最終都儲存在表空間中的。`表空間 == 表空間檔案`。其實而所謂的空間,本質上對應著存在於作業系統磁碟上的肉眼能看到的物理檔案。 下面你可以看一下我的MySQL的表空間檔案都是怎麼配置的,以及它們都在哪裡。 MySQL版本:5.7 ,並且我在 my.cnf 配置檔案中添加了如下的配置。 ```bash # 表示每一個數據庫單獨使用一個表空間 innodb_file_per_table=on ``` 然後我建立資料庫:stusy。 建立資料表:test_backup。 進入到如下的目錄中,你可以看到MySQL為我們建立的資料庫表創建出了單獨的目錄,而目錄中的有 .frm、.idb檔案就是冷備份需要備份的檔案。 
什麼是邏輯備份? 邏輯備份指的是使用 mysqldump 工具去備份資料。使用mysqldump進行資料庫的邏輯備份也是在做的各位RD需要掌握的技能。日常開發中難免會有將線上的資料備份到測試環境使用的場景。 為啥說mysqldump是邏輯備份?原因大概是:你使用mysqldump去備份最終得到的引數其實是一堆sql,再通過回放sql的形式完成資料的恢復。白日夢之前的文章中跟大家分享過(可自行檢視歷史文章哈)。在MySQL中資料表、資料行其實是邏輯存上的概念。像資料頁這中概念是物理真實存在的。所以你用mysqldump得到一堆sql,自然稱得上是邏輯備份嘍。 下文中具體說,mysqldump實戰。
什麼是熱備份? 所謂熱備份其實是指:直接對執行中的資料庫進行備份。相對於冷備份,熱備份還是比較複雜的。你想啊,對處於執行過程中的資料庫進行備份,肯定就得將一些增量的資料也備份進去。 通常人們會使用一款叫:xtraback 的工具完成資料庫的熱備份。 除此之外,我瞭解有一款Golang寫的開源工具 ghost,在github上還是挺火的。它是一款支援做無損DDL的工具(後面會專門有一篇文章講這個工具的原理)。這款工具在實現支援無損DDL功能時,有一部分邏輯本質上也是在支援增量資料的備份。 ghost的實現手段是:新增binlog監聽事件,監聽到binlog event後去解析binlog得到sql,再回放這個SQL。就像是從庫使用主庫對binlog進行資料恢復一樣。
什麼是快照備份?
再瞭解一下什麼是快照備份:
快照備份不是資料庫本身提供的能力,本質上它是藉助於檔案系統的快照功能來實現的對資料庫的備份。
我們知道的Linux伺服器本質上也是電腦的,它會有自己的磁碟,無論是固態硬碟,還是機械磁碟。反正會有這種固態儲存。還需要進一步對磁碟進行分割槽。然後才有將Linux檔案系統中的目錄都會掛載在不同的分割槽上。這麼做的目的,簡單來說就像你的window有C盤、D盤、E盤。D盤中的出問題後不會影響E盤一樣。
快照備份要求:資料庫的所有資料檔案都要放在一個數據分割槽中。
常見的支援快照工具的檔案系統和裝置有:FreeBSD、UFS檔案系統、Solaris的ZFS檔案系統。GNU/Linux的LVM(Logical Volume Manager)
### 實用的mysqldump備份方式
本小節看幾個實戰mysqldump備份case。
測試環境:建立如下表
```bash
CREATE TABLE `test_backup2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
資料表中寫入3條資料
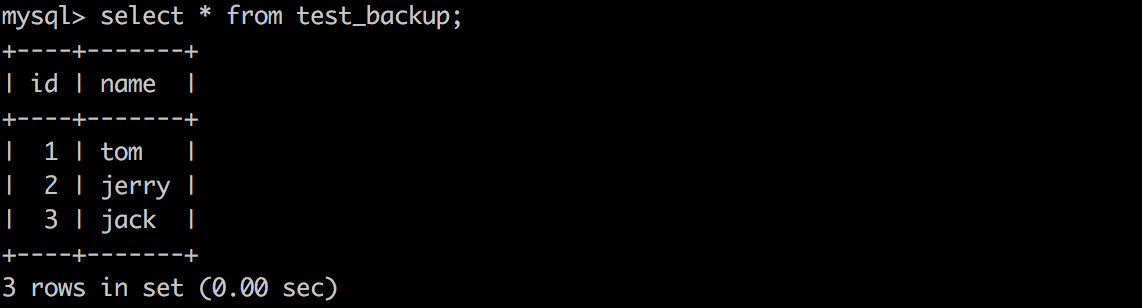
mysqldump語法
```bash
mysqldump [arguments] > file_name;
```
1、備份指定的資料庫 通過引數`--databases` 指定你要備份的資料庫 ```bash # mysqldump -uroot -p --databases db1 db2 db3 > 自定義名.sql; ./mysqldump -uroot -p --databases stusy > test_backup.sql; ```  因為我開啟了GTID,所以直接執行如上的命令列有報錯提示說:如果我只想完成資料的dump,需要在命令列中新增上它提示的那些引數。 ```bash # 如果你沒有開啟GTID選項,它提示我加的這些引數你都沒有必要新增的。 # --triggers 備份觸發器 # --routines 備份儲存過程和函式 # --events 備份事件排程器 ./mysqldump --set-gtid-purged=OFF --databases stusy --triggers --routines --events -uroot -p > test_backup.sql; ``` 檢視產出的SQL檔案:
注意點:使用引數 --databases 引數。最終產出的SQL中為你建立資料庫了。 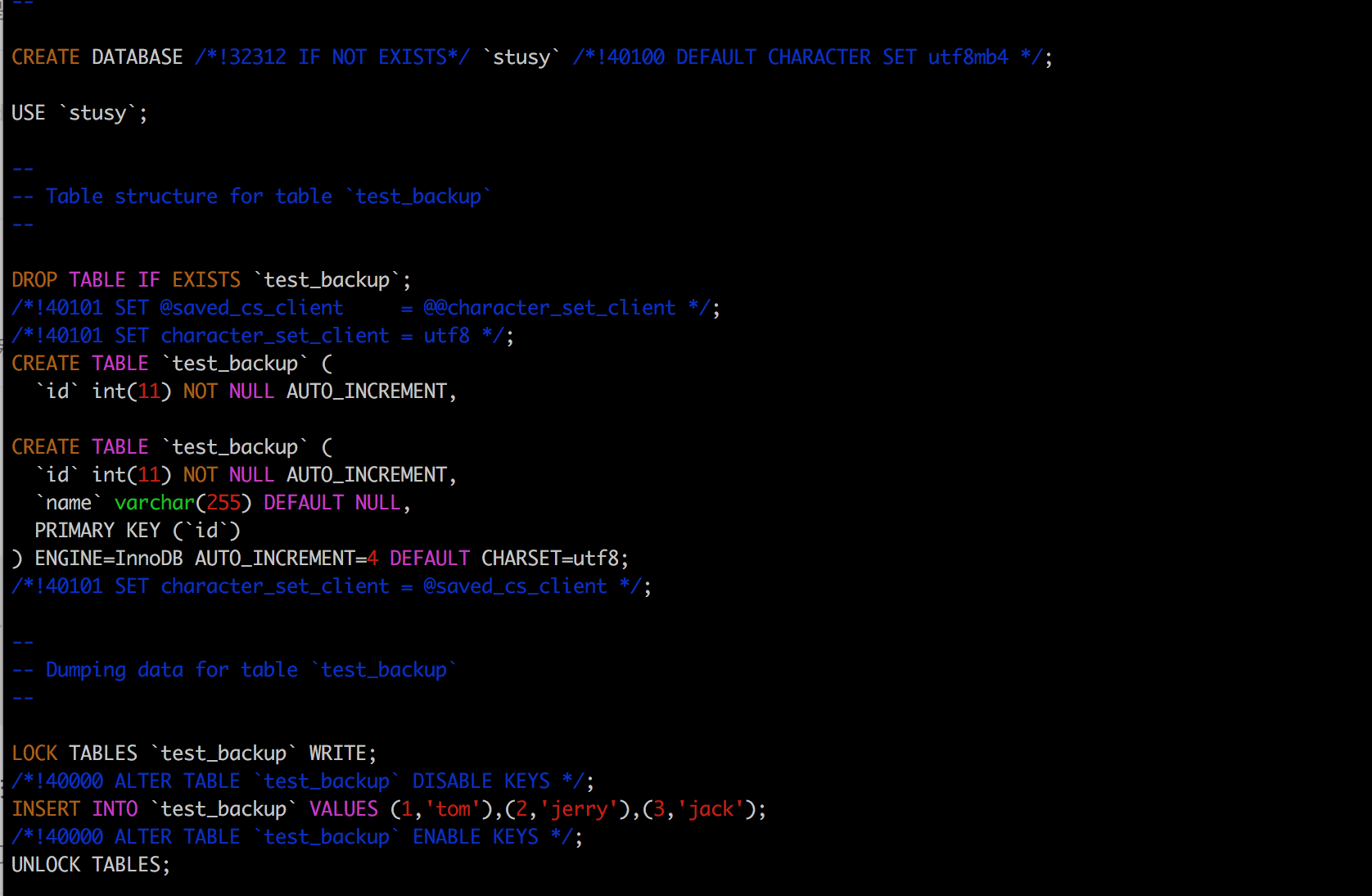 > 檔案開始和結束的部分有很多註釋,這些註釋可以用來設定MYSQL資料的各項引數。一般用來保證還原資料時可以更加有效準確的工作。
2、備份指定資料庫中的指定資料表: 通過引數 `--tables` 指定你要備份的資料表。 ``` bash # mysqldump -uroot -p --databases db1 db2 db3 --tables t1 t2 > 自定義名.sql; ./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events -uroot -p > test_backup.sql; ```
3、對一個架構進行備份 不使用`--databases`,直接寫資料庫名。對整庫架構進行備份 ```bash ./mysqldump --set-gtid-purged=OFF --triggers --routines --events -uroot -p mysql> mysql_backup.sql; ``` 檢視備份的結果
注意點:相對於使用 --databases 引數來說。最終產出的SQL中!!沒有!!為你建立資料庫。 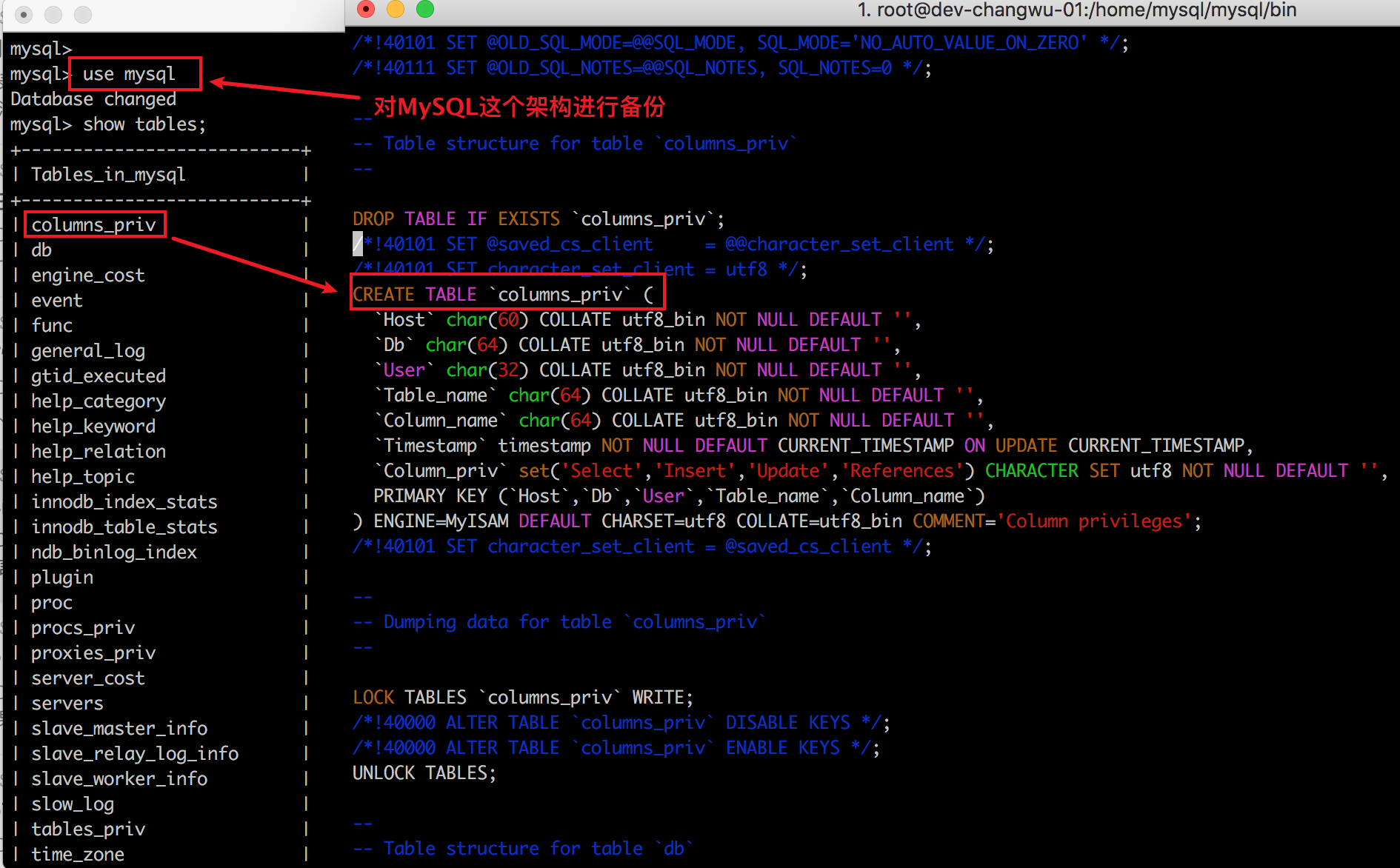
4、重點理解引數:--single-transaction 如果你想獲得一份“一致性備份”可以使用該引數。那什麼是一致性備份呢? todo 下面的:我勸!這位年輕人不講MVCC,耗子尾汁! 貼上鍊接。 新增`--single-transaction`引數後,mysqldump會自動幫你執行 `start transaction` 開啟事務的SQL。如果你看過白日夢之前寫的 “我勸!這位年輕人不講MVCC,耗子尾汁!”,想必你一定了解,MVCC的實現原理,回到現在的這個問題中,也就是說,只要你執行開啟事務的語句就會得到一個一致性可重複讀的檢視(read view)。說白了:此次執行mysqldump得到的SQL檔案中的資料,就是你執行的該命令的那個瞬間,打下的快照的資料。 注意:如果你不使用`--single-transaction`引數,會自動新增上`--lock-all-tables`。此外,還需要知道當我們使用引數`--single-transaction`獲取到的那個一致性實圖並不能隔離DDL(表級別的操作,比如新增列)。所以你要確保在備份時沒有其他的DDL語句執行。
5、重點理解引數:--master-data
```bash
# 當值為1時,轉存檔案中會有change master 語句。
--master-data = 1
# 當值為2時,轉存檔案中當 change master 語句會被註釋。
--master-data = 2
```
下面分別讓 `--master-data` 為不同的值。檢視產出。
```bash
./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events --master-data=2 -uroot -p > test_backup.sql;
```
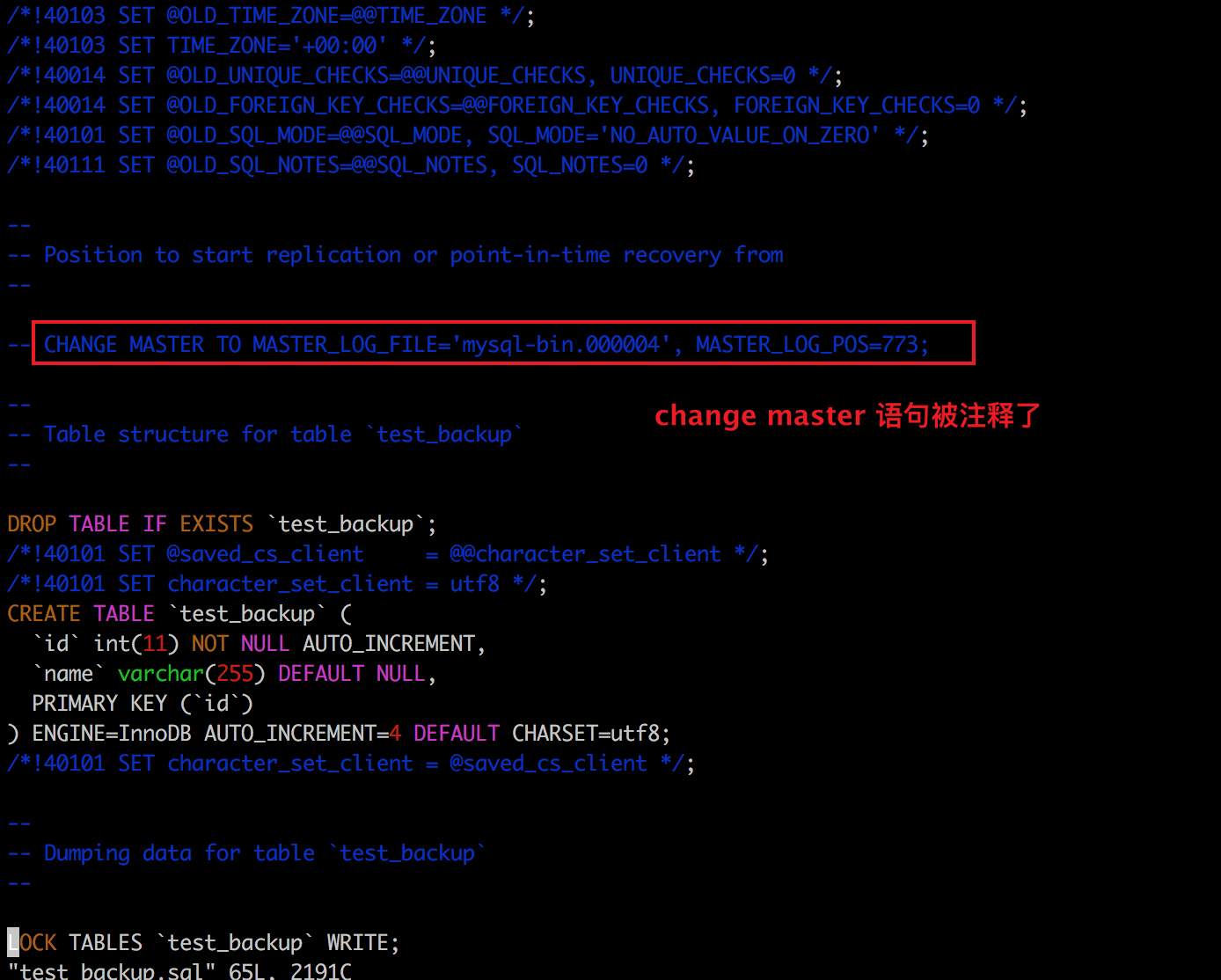
```bash
./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events --master-data=1 -uroot -p > test_backup.sql;
```
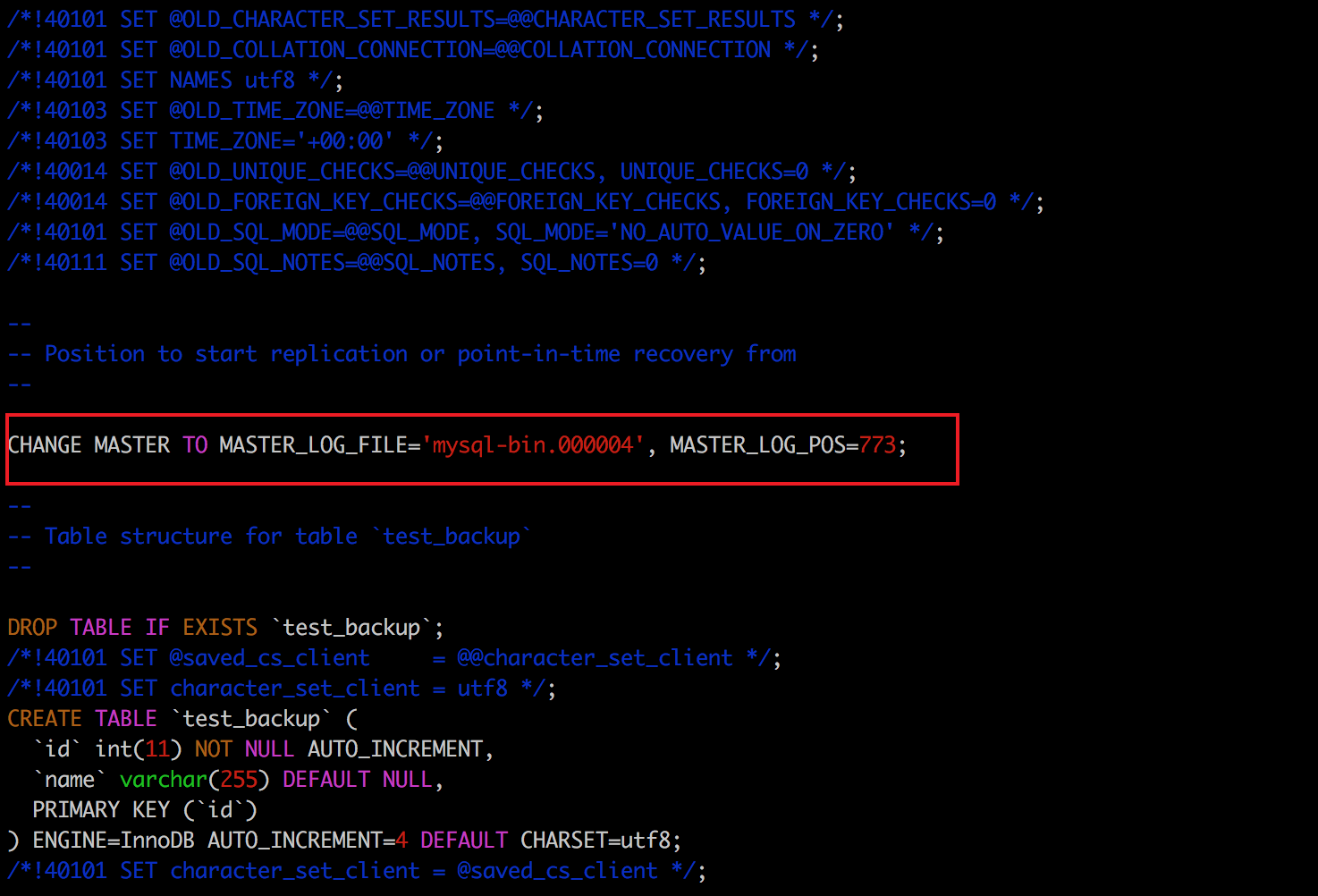
一般搭建過mysql叢集的同學都知道這條change master sql語句的作用是: 從庫認主庫的命令。
是的,使用引數`--master-data=1`得到的備份檔案通常主要做用是建立一個replication(從庫)。
> 上面介紹了工作中常用的幾種用法和注意點。
>
> 其實mysqldump支援的引數多達幾十個。你可以使用 --help檢視它們。
>
> 如果上面的引數不能滿足你的需求。你可去官網查閱:https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
### 得先知道什麼是GTID
GTID (global transcation identifier)它是MySQL5.6版本中新增進來的新特性 ,使用GTID可以唯一的標識一個事物。
我用大白話描述一下GTID常見的作用:
比如一條update有語句進入MySQL之後經歷如下過程:
```bash
1. 寫undolog
2. 寫redolog(prepare)
3. 寫binlog
4. 寫redolog(commit)
# 這也是所謂的兩階段提交
```
不管你有沒有自己搭建過MySQL叢集,你一定聽說過MySQL叢集!主庫將自己成功執行過的事物都寫在binlog,然後叢集中的從庫會dump主庫記錄的binlog回放出資料,完成資料同步。當我們將GTID相關的配置開啟後,update語句經歷如下過程:
```bash
1. 寫undolog # 回滾
2. 寫redolog(prepare)# 保證提交的不會丟失
3. 寫一個特殊的Binlog Event,型別為GTID_Event,指定下一個事務的GTID
4. 寫binlog # 主從同步事物使用
5. 寫redolog(commit)
```
也就是說mysql會在binlog中多為我們記錄一行gtid。這個gtid和當前事物唯一對應。不會重複。
這時當從庫向主庫傳送同步資料當請求時:bin-log和gtid都會傳送到slave端,從庫在回放日誌同步資料時,同樣會使用gtid寫bin-log,這樣主庫和從庫之間的資料,就通過GTID強制性的關聯並且保持同步了。
下圖擷取自binlog一條事務,你可以看到裡面會記錄gtid。
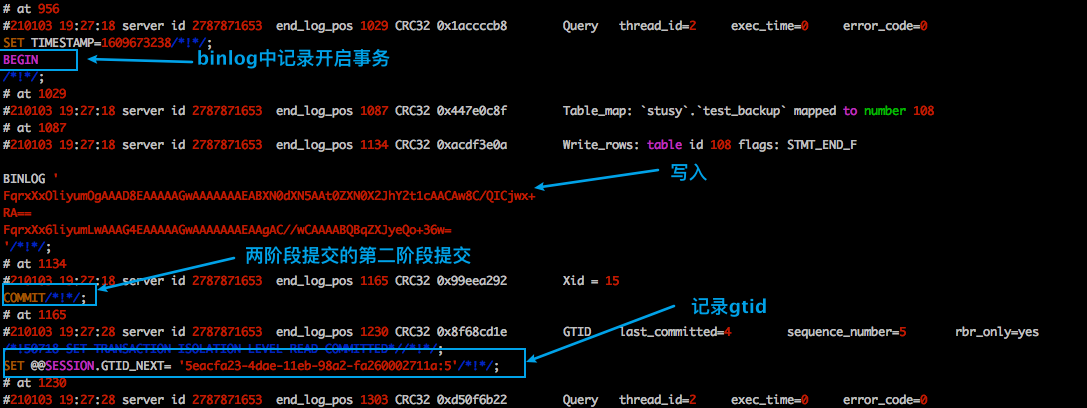
這時如果從庫想在主庫同步資料,只需要告訴主庫自己有哪些gtid就好了,主庫會把從庫沒有的gtid對應的事務日誌給從庫讓它去同步資料。
而在這種方式出現之前,主從之間同步資料時,從庫需要告訴主庫自己已經同步到binlog.0000x,position=yyy的地方了。這個binlog.0000x,position=yyy需要人為的去檢視一下。不能說檢視這兩個資訊比較麻煩,但是肯定不如GTID來的方便。
### 看一條binlog長啥樣
為了對小白友好一點,再看一下這張圖:
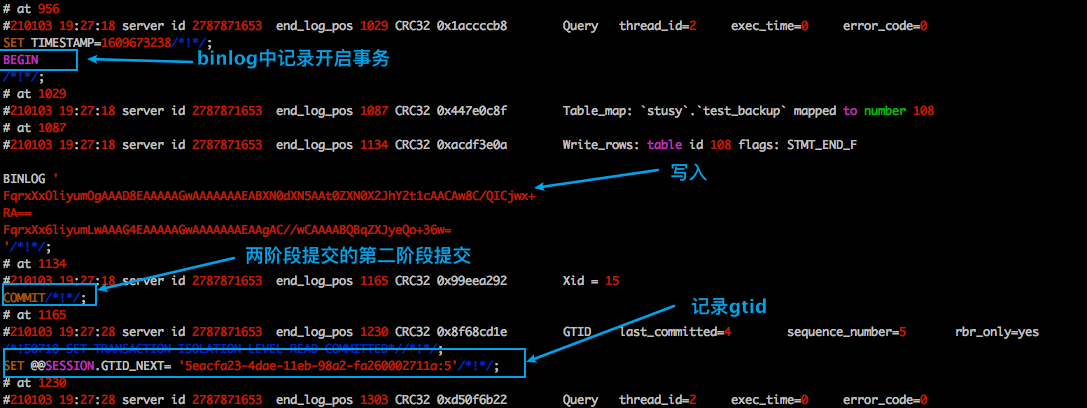
首先你得知道,像select這種查詢型別的sql,是不會被記錄進binlog中的,binlog中只會記錄對資料庫作出修改的寫入或者更新的sq。就像上圖中,你可以看我圖中begin、xxx、commit。
另外binlog中是有位點的,人們一般把稱它叫:position。其實所謂的位點就是上圖中的`at xxx`中的xxx。
每一個事物都有自己的開啟、結束位點,換句話說我們可以通過開始和結束的位點找到一個或者是好多和事物。就上圖來說,這個事物的start-positon=956,stop-position=1230。
這個位點有啥用呢?
作用1:搭建主從叢集時,通過下面的命令告訴從庫,應該從主庫的哪個binlog的哪個位點開始同步資料
```sql
CHANGE MASTER TO
MASTER_HOST='10.157.23.158',
MASTER_USER='mysqlsync',
MASTER_PASSWORD='mysqlsync123',
MASTER_PORT=8882,
MASTER_LOG_FILE='mysql-bin.000008',
MASTER_LOG_POS=1013; # 這就是位點
```
作用2:資料恢復時,指定從哪個位點恢復到哪個位點。或者跳過哪個位點,下面我們一起看下基於binlog的資料恢復。
> 如果你不曾搭建過叢集,沒關係,歡迎關注白日夢,我後面會分享基於 binlog+position、基於gtid、基於docker+gtid搭建MySQL叢集的方法。
### 資料恢復
不知道你有沒有誤刪過資料庫中的資料,之前我就誤刪過。不過還好是測試環境的。
其實誤刪資料後是可以通過binlog將資料恢復出來的。既然是使用binlog恢復資料,前提是你的MySQL開啟了binlog(預設情況下mysql不會幫你記錄binlog,如果你還不知道什麼是binlog也沒關係,白日夢前面的文章有分享,你可以去看下)。
大部分情況下,DBA同學會將你使用的MySQL binlog開啟。你可以像下面這樣驗證一下自己使用的資料庫binlog是否打開了。如果沒有開啟binlog,資料可能真的沒辦法恢復。
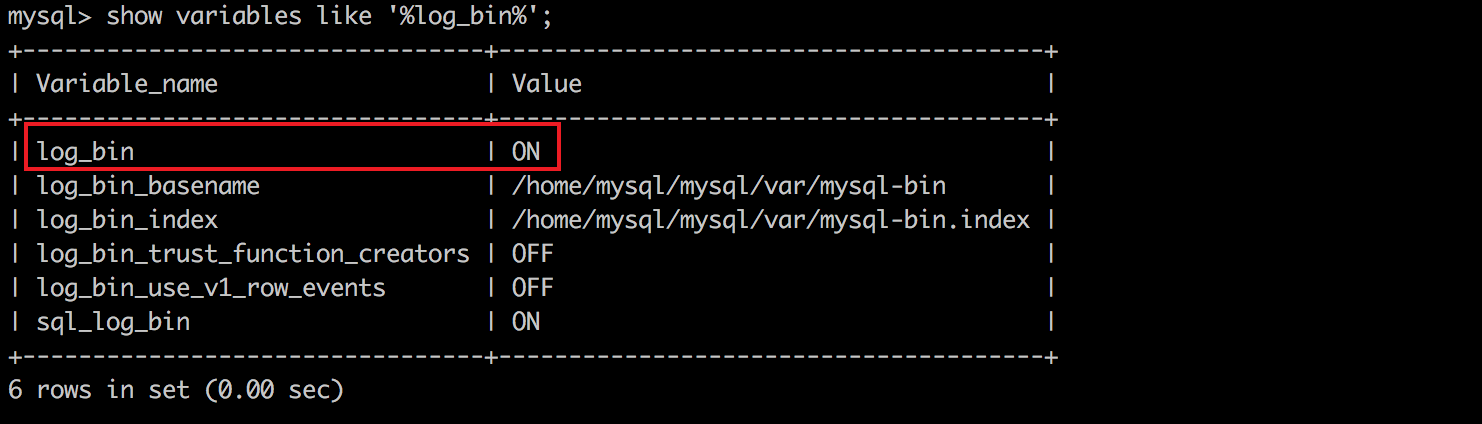
> 線上的資料庫不斷承接流量,binlog會不斷滾動變大,你要趕在binlog被清理之前去恢復資料。
下面一起看看如何使用binlog恢復資料,下面看我的實驗步驟:
先檢視我的所有的binlog:
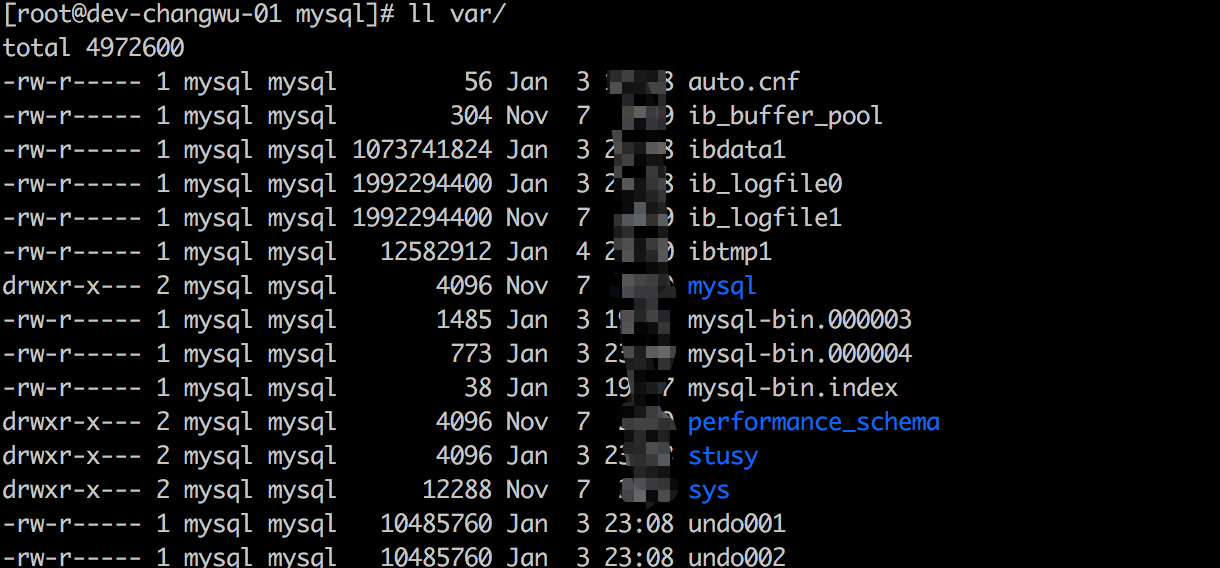
然後我把資料庫中的資料全部刪除。

情況一:沒有開啟GITD 如果你的MySQL沒有開啟GTID。直接使用下面的命令,就能把你指定的binlog中指定範圍的positon的資料回放出來。 ```bash ./mysqlbinlog start-positon=956,stop-position=1230 ../var/mysql-bin.000003 | ./mysql-uroot -p ``` > 除了用位點縮小範圍,還可以指定開始時間和結束時間來縮小範圍。
思考這樣的情況: 假設你沒有趕在binlog被清理之前去恢復資料,當你去恢復資料時上圖中delete sql之前的binlog已經被刪除了。那怎麼辦? 這時你可以通過最近的全量備份把delete之前的資料恢復出來,然後delete之後的增量資料,通過mysqlbinlog工具恢復出來,注意別忘了通過positon跳過這個delete,不然一執行會放出來delete語句,資料又全被刪除了。 如果你沒有全量備份,binlog也不全了。那估計就懸了!
情況二:開啟GITD
開啟GTID的MySQL,同樣執行這行命令恢復資料會遇到下面的錯誤。
```sql
./mysqlbinlog start-positon=956,stop-position=1230 ../var/mysql-bin.000003 | ./mysql-uroot -p
```

如果你看了前面白日夢跟你介紹的什麼是GTID,想必你已經知道為啥報錯了。因為你用binlog回放資料,其實就是讓mysql重新執行一下binlog中記錄的邏輯,問題就出在binlog中記錄了set next_gtid=xxx,因為gtid唯一的,是不能重複的。
所以需要新增引數`--skip-gtids=true`
```bash
[root@dev-changwu-01 bin]# ./mysqlbinlog --skip-gtids=true --start-position=684 --stop-position=1485 ../var/mysql-bin.000003 | ./mysql -uroot -p
Enter password:
```
### 推薦閱讀-白日夢的MySQL專題
1. [MySQL的修仙之路,圖文談談如何學MySQL、如何進階!(已釋出)](https://mp.weixin.qq.com/s/c7KLGRNd5FT4xVoeJ4tvag)
2. [面前突擊!33道資料庫高頻面試題,你值得擁有!(已釋出)](https://mp.weixin.qq.com/s/c7KLGRNd5FT4xVoeJ4tvag)
3. [大家常說的基數是什麼?(已釋出)](https://mp.weixin.qq.com/s/FgxwAFQbEjv5i-TxjvLK6Q)
4. [講講什麼是慢查!如何監控?如何排查?(已釋出)](https://mp.weixin.qq.com/s/tXTLMCiVpEnnmhUclYR19Q)
5. [對NotNull欄位插入Null值有啥現象?(已釋出)](https://mp.weixin.qq.com/s/b30fKiQJTZARZazQdv6WKw)
6. [能談談 date、datetime、time、timestamp、year的區別嗎?(已釋出)](https://mp.weixin.qq.com/s/9zKX86P4kzlKla6-NyS3EA)
7. [瞭解資料庫的查詢快取和BufferPool嗎?談談看!(已釋出)](https://mp.weixin.qq.com/s/GB1OVQc8Cwv5Qpy329PIaA)
8. [你知道資料庫緩衝池中的LRU-List嗎?(已釋出)](https://mp.weixin.qq.com/s/OXAvtiZd9GA4Zx_rUJ6Wzw)
9. [談談資料庫緩衝池中的Free-List?(已釋出)](https://mp.weixin.qq.com/s/D3piti1Z-b7z1-Es5iEEpg)
10. [談談資料庫緩衝池中的Flush-List?(已釋出)]( https://mp.weixin.qq.com/s/56-DE61mEte6glmJ3lFvOg)
11. [瞭解髒頁刷回磁碟的時機嗎?(已釋出)]( https://mp.weixin.qq.com/s/56-DE61mEte6glmJ3lFvOg)
12. [用十一張圖講清楚,當你CRUD時BufferPool中發生了什麼!以及BufferPool的優化!(已釋出)](https://mp.weixin.qq.com/s/p5BgyX2Qg-UayPQAxslArw)
13. [聽說過表空間沒?什麼是表空間?什麼是資料表?(已釋出)](https://mp.weixin.qq.com/s/CwxRjGI843UerF89G_WJ-Q)
14. [談談MySQL的:資料區、資料段、資料頁、資料頁究竟長什麼樣?瞭解資料頁分裂嗎?談談看!(已釋出)](https://mp.weixin.qq.com/s/yPTO_QgkaNrU-gNoddjl-Q)
15. [談談MySQL的行記錄是什麼?長啥樣?(已釋出)](https://mp.weixin.qq.com/s/-Q_sqyUU60sF-H-XFv4Pdg)
16. [瞭解MySQL的行溢位機制嗎?(已釋出)](https://mp.weixin.qq.com/s/-Q_sqyUU60sF-H-XFv4Pdg)
17. [說說fsync這個系統呼叫吧! (已釋出)](https://mp.weixin.qq.com/s/tyxd64gGa_SmR6c9vrwf1w)
18. [簡述undo log、truncate、以及undo log如何幫你回滾事物! (已釋出)](https://mp.weixin.qq.com/s/zDiuK1wTIdwK4U3W3mrIlg)
19. [我勸!這位年輕人不講MVCC,耗子尾汁! (已釋出)](https://mp.weixin.qq.com/s/YiurAKs4gISp-RZNG_1JEQ)
20. [MySQL的崩潰恢復到底是怎麼回事? (已釋出)](https://mp.weixin.qq.com/s/6dQnlvjqOo6A0e_h8vST3w)
21. [MySQL的binlog有啥用?誰寫的?在哪裡?怎麼配置 (已釋出)](https://mp.weixin.qq.com/s/DN1shuyxPJ6BkE_RLezAnA)
22. [MySQL的bin log的寫入機制 (已釋出)](https://mp.weixin.qq.com/s/MtWzoiJtupso5M8z1KUaQQ)
23. [刪庫後!除了跑路還能幹什麼?(已釋出)](https://mp.weixin.qq.com/s/uVRtjKEaWRonwo_wWZGdxQ)
### 推薦閱讀-二本應屆生的大學生活,已上岸百度
[二本應屆生的大學生活,已上岸百度(已釋出)](https://mp.weixin.qq.com/s/ZLudOWM8Z4rOKbfvNYA1XA)
歡迎關注白日夢,走進白日夢的圈子~
### 下一篇:兩階段提交和分散式事務
一、事務的提交
二、簡單看下兩階段提交的流程
三、兩階段寫日誌用意?
四、加餐:sync_binlog = 1 問題
五、兩階段提交設計的初衷 - 分散式事務
六、MySQL兩階段寫日誌
七、再留一個彩蛋
參考:
https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
https://www.cnblogs.com/paul8339/p/9353