
哎,這讓人摳腦殼的 LFU。
這是why哥的第 83 篇原創文章
讓人摳腦殼的 LFU
前幾天在某APP看到了這樣的一個討論:

看到一個有點意思的評論:
LFU 是真的難,腦殼都給我摳疼了。
如果說 LRU 是 Easy 模式的話,那麼把中間的字母從 R(Recently) 變成 F(Frequently),即 LFU ,那就是 hard 模式了。
你不認識 Frequently 沒關係,畢竟這是一個英語專八的詞彙,我這個英語八級半的選手教你:
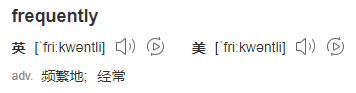
所以 LFU 的全稱是Least Frequently Used,最不經常使用策略。
很明顯,強調的是使用頻率。
而 LRU 演算法的全稱是Least Recently Used。最近最少使用演算法。
強調的是時間。
當統計的維度從時間變成了頻率之後,在演算法實現上發生了什麼變化呢?
這個問題先按下不表,我先和之前寫過的 LRU 演算法進行一個對比。
LRU vs LFU
LRU 演算法的思想是如果一個數據在最近一段時間沒有被訪問到,那麼在將來它被訪問的可能性也很小。所以,當指定的空間已存滿資料時,應當把最久沒有被訪問到的資料淘汰。
也就是淘汰資料的時候,只看資料在快取裡面待的時間長短這個維度。
而 LFU 在快取滿了,需要淘汰資料的時候,看的是資料的訪問次數,被訪問次數越多的,就越不容易被淘汰。
但是呢,有的資料的訪問次數可能是相同的。
怎麼處理呢?
如果訪問次數相同,那麼再考慮資料在快取裡面待的時間長短這個維度。
也就是說 LFU 演算法,先看訪問次數,如果次數一致,再看快取時間。
給大家舉個具體的例子。
假設我們的快取容量為 3,按照下列資料順序進行訪問:

如果按照 LRU 演算法進行資料淘汰,那麼十次訪問的結果如下:
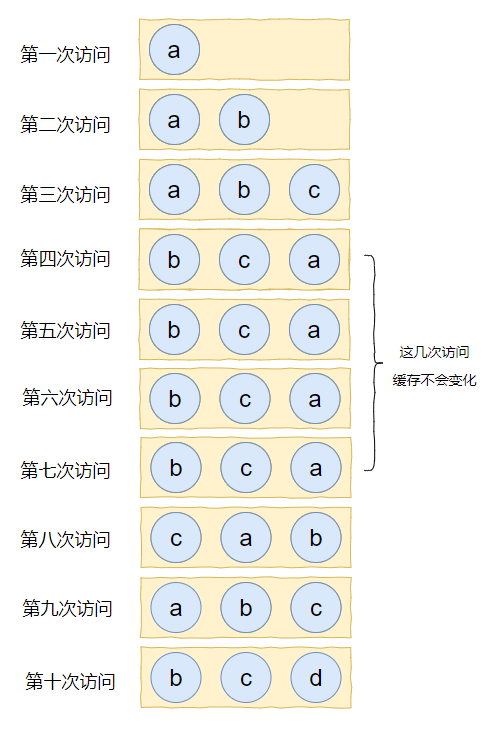
十次訪問結束後,快取中剩下的是 b,c,d 這三個元素。
你有沒有覺得有一絲絲不對勁?

十次訪問中元素 a 被訪問了 5 次,結果最後元素 a 被淘汰了?
如果按照 LFU 演算法,最後留在快取中的三個元素應該是 b,c,a。
這樣看來,LFU 比 LRU 更加合理,更加巴適。
假設,要我們實現一個 LFUCache:
class LFUCache {
public LFUCache(int capacity) {
}
public int get(int key) {
}
public void put(int key, int value) {
}
}
那麼思路應該是怎樣的呢?
帶你瞅一眼。
LFU 方案一 - 一個雙向連結串列
如果在完全沒有接觸過 LFU 演算法之前,讓我硬想,我能想到的方案也只能是下面這樣的:
因為既需要有頻次,又需要有時間順序。
我們就可以搞個連結串列,先按照頻次排序,頻次一樣的,再按照時間排序。
因為這個過程中我們需要刪除節點,所以為了效率,我們使用雙向連結串列。
還是假設我們的快取容量為 3,還是用剛剛那組資料進行演示。
我們把頻次定義為 freq,那麼前三次訪問結束後,即這三個請求訪問結束後:
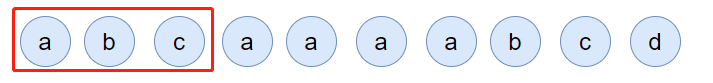
連結串列裡面應該是這樣的:

三個元素的訪問頻次都是 1。
對於前三個元素來說,value=a 是頻次相同的情況下,最久沒有被訪問到的元素,所以它就是 head 節點的下一個元素,隨時等著被淘汰。
接著過來了 1 個 value=a 的請求:

當這個請求過來的時候,連結串列中的 value=a 的節點的頻率(freq)就變成了2。
此時,它的頻率最高,最不應該被淘汰。
因此,連結串列變成了下面這個樣子:

接著連續來了 3 個 value=a 的請求:

此時的連結串列變化就集中在 value=a 這個節點的頻率(freq)上:
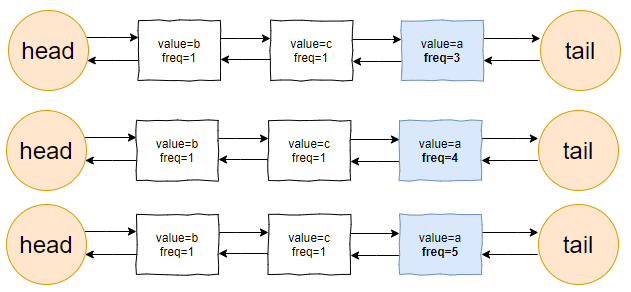
接著,這個 b 請求過來了:

b 節點的 freq 從 1 變成了 2,節點的位置也發生了變化:

然後,c 請求過來:
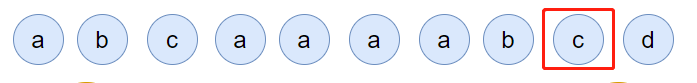
你說這個時候會發生什麼事情?
連結串列中的 c 當前的訪問頻率是 1,當這個 c 請求過來後,那麼連結串列中的 c 的頻率就會變成 2。
你說巧不巧,此時,value=b 節點的頻率也是 2。
撞車了,那麼你說,這個時候怎麼辦?
前面說了:頻率一樣的時候,看時間。
value=c 的節點是正在被訪問的,所以要淘汰也應該淘汰之前被訪問的 value=b 的節點。
此時的連結串列,就應該是這樣的:

然後,最後一個請求過來了:

d 元素,之前沒有在連結串列裡面出現過,而此時連結串列的容量也滿了。
該進行淘汰了。
於是把 head 的下一個節點(value=b)淘汰,並把 value=d 的節點插入:

最終,所有請求完畢。
留在快取中的是 d,c,a 這三個元素。
整體的流程就是這樣的:
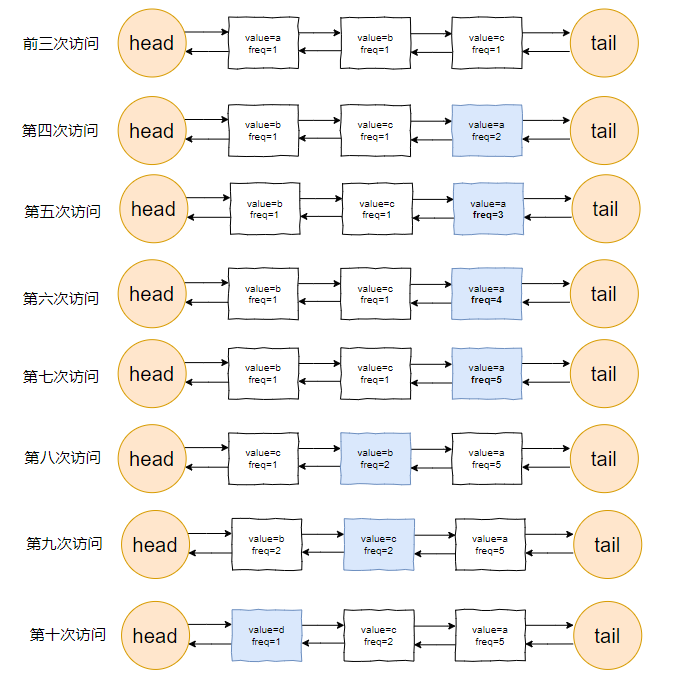
當然,這裡只是展示了連結串列的變化。
其實我們放的是 key-value 鍵值對。
所以應該還有一個 HashMap 來儲存 key 和連結串列節點的對映關係。
這個簡單,用腳趾頭都能想到,我也就不展開來說了。
按照上面這個思路,你慢慢的寫程式碼,應該是能寫出來的。
上面這個雙鏈表的方案,就是扣著腦殼硬想,大部分人能直接想到的方案。
面試官要的肯定是時間複雜度為 O(1) 的解決方案。
現在的這個解決方案時間複雜度為 O(N)。

O(1) 解法
如果我們要拿出時間複雜度為 O(1) 的解法,我們就得細細的分析了,不能扣著腦殼硬想了。
先分析一下需求。
第一點:我們需要根據 key 查詢其對應的 value。
用腳趾頭都能想到,用 HashMap 儲存 key-value 鍵值對。
查詢時間複雜度為 O(1),滿足。
第二點:每當我們操作一個 key 的時候,不論是查詢還是新增,都需要維護這個 key 的頻次,記作 freq。
因為我們需要頻繁的操作 key 對應的 freq,也就是得在時間複雜度為 O(1) 的情況下,獲取到指定 key 的 freq。
來,請你大聲的告訴我,用什麼資料結構?
是不是還得再來一個 HashMap 儲存 key 和 freq 的對應關係?
第三點:如果快取裡面放不下了,需要淘汰資料的時候,把 freq 最小的 key 刪除掉。
注意啊,上面這句話:[把 freq 最小的 key 刪除掉]。
freq 最小?
我們怎麼知道哪個 key 的 freq 最小呢?
前面說了,有一個 HashMap 儲存 key 和 freq 的對應關係。
當然我們可以遍歷這個 HashMap,來獲取到 freq 最小的 key。
但是啊,朋友們,遍歷出現了,那麼時間複雜度還會是 O(1) 嗎?
那怎麼辦呢?
注意啊,高潮來了,一學就廢,一點就破。
我們可以搞個變數來記錄這個最小的 freq 啊,記為 minFreq,不就行了?

現在我們有最小頻次(minFreq)了,需要獲取到這個最小頻次對應的 key,時間複雜度得為 O(1)。
來,朋友,請你大聲的告訴我,你又想起了什麼資料結構?
是不是又想到了 HashMap?
好了,我們現在有三個 HashMap 了,給大家介紹一下:
一個儲存 key 和 value 的 HashMap,即HashMap<key,value>。 一個儲存 key 和 freq 的 HashMap,即HashMap<key,freq>。 一個儲存 freq 和 key 的 HashMap,即HashMap<freq,key>。
它們每個都是各司其職,目的都是為了時間複雜度為 O(1)。
但是我們可以把前兩個 HashMap 合併一下。
我們弄一個物件,物件裡面包含兩個屬性分別是value、freq。
假設這個物件叫做 Node,它就是這樣的,頻次預設為 1:
class Node {
int value;
int freq = 1;
//建構函式省略
}
那麼現在我們就可以把前面兩個 HashMap ,替換為一個了,即 HashMap<key,Node>。
同理,我們可以在 Node 裡面再加入一個 key 屬性:
class Node {
int key;
int value;
int freq = 1;
//建構函式省略
}
因為 Node 裡面包含了 key,所以可以把第三個 HashMap<freq,key> 替換為 HashMap<freq,Node>。
到這一步,我們還差了一個非常關鍵的資訊沒有補全,就是下面這一個點。
第四點:可能有多個 key 具有相同的最小的 freq,此時移除這一批資料在快取中待的時間最長的那個元素。
這個需求,我們需要通過 freq 查詢 Node,那麼操作的就是 HashMap<freq,Node> 這個雜湊表。
上面說[多個 key 具有相同的最小的 freq],也就是說通過 minFreq ,是可以查詢到多個 Node 的。
所以HashMap<freq,Node> 這個雜湊表,應該是這樣的:
HashMap<freq,集合
此時的問題就變成了:我們應該用什麼集合來裝這個 Node 物件呢?
不慌,我們先理一下這個集合需要滿足什麼條件。
首先,需要刪除 Node 的時候。
因為這個集合裡面裝的是訪問頻次一樣的資料,那麼希望這批資料能有時序,這樣可以快速的刪除待的時間最久的 Node。
有時序,能快速查詢刪除待的時間最久的 key,你能想到什麼資料結構?
這不就是雙向連結串列嗎?
然後,需要訪問 Node 的時候。
一個 Node 被訪問,那麼它的頻次必然就會加一。
比如下面這個例子:
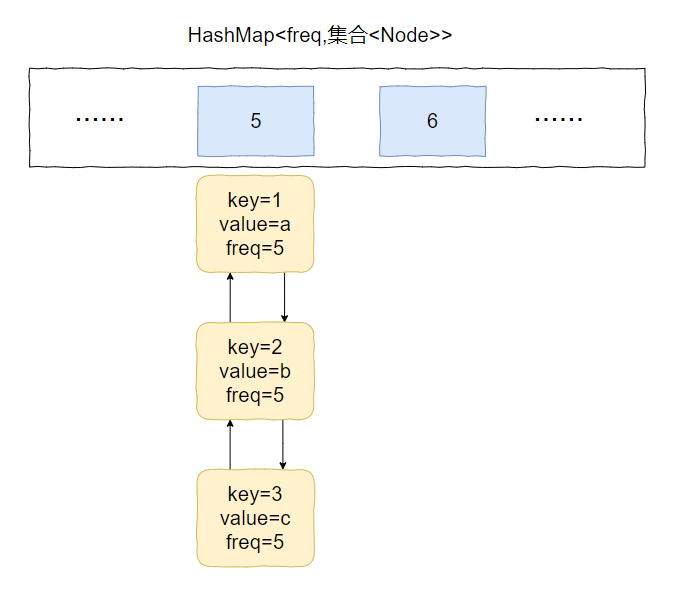
假設最小訪問頻次就是 5,而 5 對應了 3 個 Node 物件。
此時,我要訪問 value=b 的物件,那麼該物件就會從 key=5 的 value 中移走。
然後頻次加一,即 5+1=6。
加入到 key=6 的 value 集合中,變成下面這個樣子:
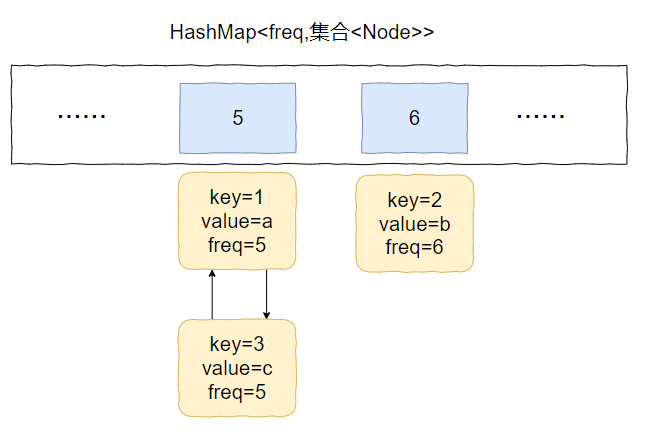
也就是說我們得支援任意 node 的快速刪除。
我們可以針對上面的需求,自定義一個雙向連結串列。
但是在 Java 集合類中,有一個滿足上面說的有序且支援快速刪除的條件的集合。
那就是 LinkedHashSet。
所以,HashMap<freq,集合
總結一下。
我們需要兩個 HashMap,分別是 HashMap<key,Node> 和 HashMap<freq,LinkedHashSet
然後還需要維護一個最小訪問頻次,minFreq。
哦,對了,還得來一個引數記錄快取支援的最大容量,capacity。
沒了。
有的小夥伴肯定要問了:你倒是給我一份程式碼啊?

這些分析出來了,程式碼自己慢慢就擼出來了。
思路清晰後再去寫程式碼,就算面試的時候沒有寫出 bug free 的程式碼,也基本上八九不離十了。
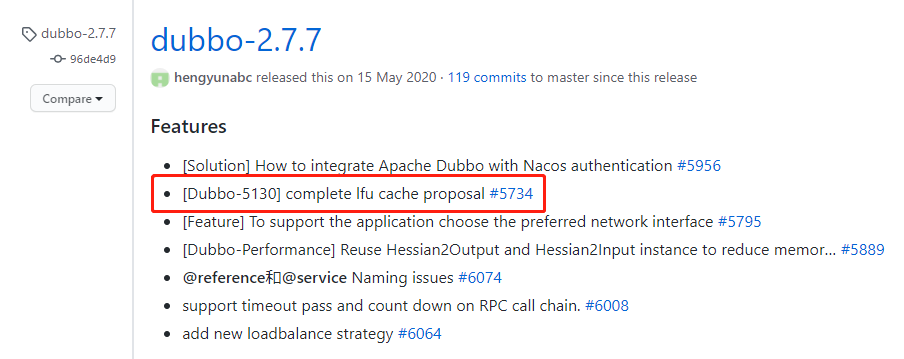
Dubbo 中的 LFU 演算法
Dubbo 在 2.7.7 版本之後支援了 LFU 演算法:
其原始碼的位置是:org.apache.dubbo.common.utils.LFUCache
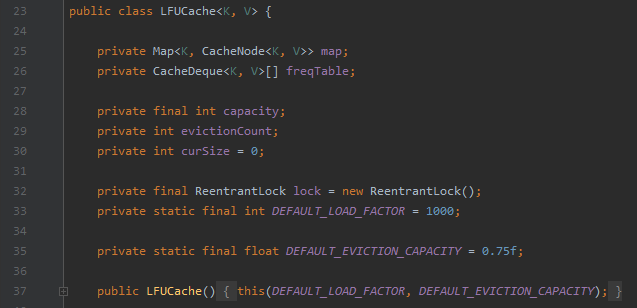
程式碼不長,總共就 200 多行,和我們上面說的 LFU 實現起來還有點不一樣。
你可以看到它甚至沒有維護 minFreq。
但是這些都不重要,打個斷點除錯一下很快就能分析出來作者的程式碼思路。
重要的是,我在看 Dubbo 的 LFU 演算法的時候發現了一個 bug。
不是指這個 LFU 演算法實現上的 bug,演算法實現我看了是沒有問題的。
bug 是 Dubbo 雖然加入了 LFU 快取演算法的實現,但是作為使用者,卻不能使用。
問題出在哪裡呢?
我帶你瞅一眼。
原始碼裡面告訴我這樣配置一下就可以使用 lfu 的快取策略:
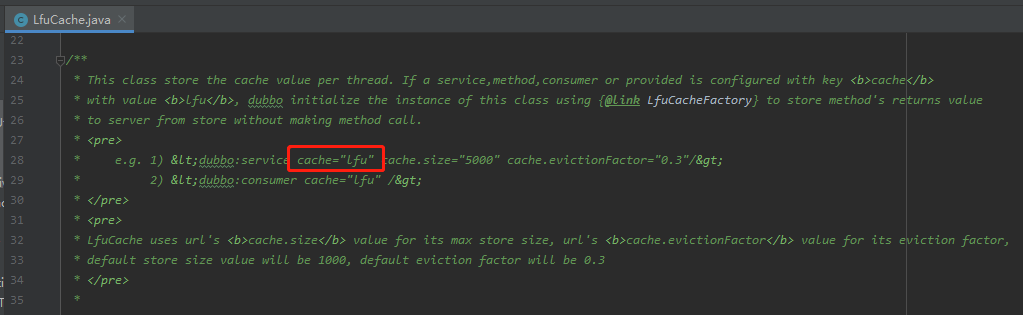
但是,當我這樣配置,發起呼叫之後,是這樣的:
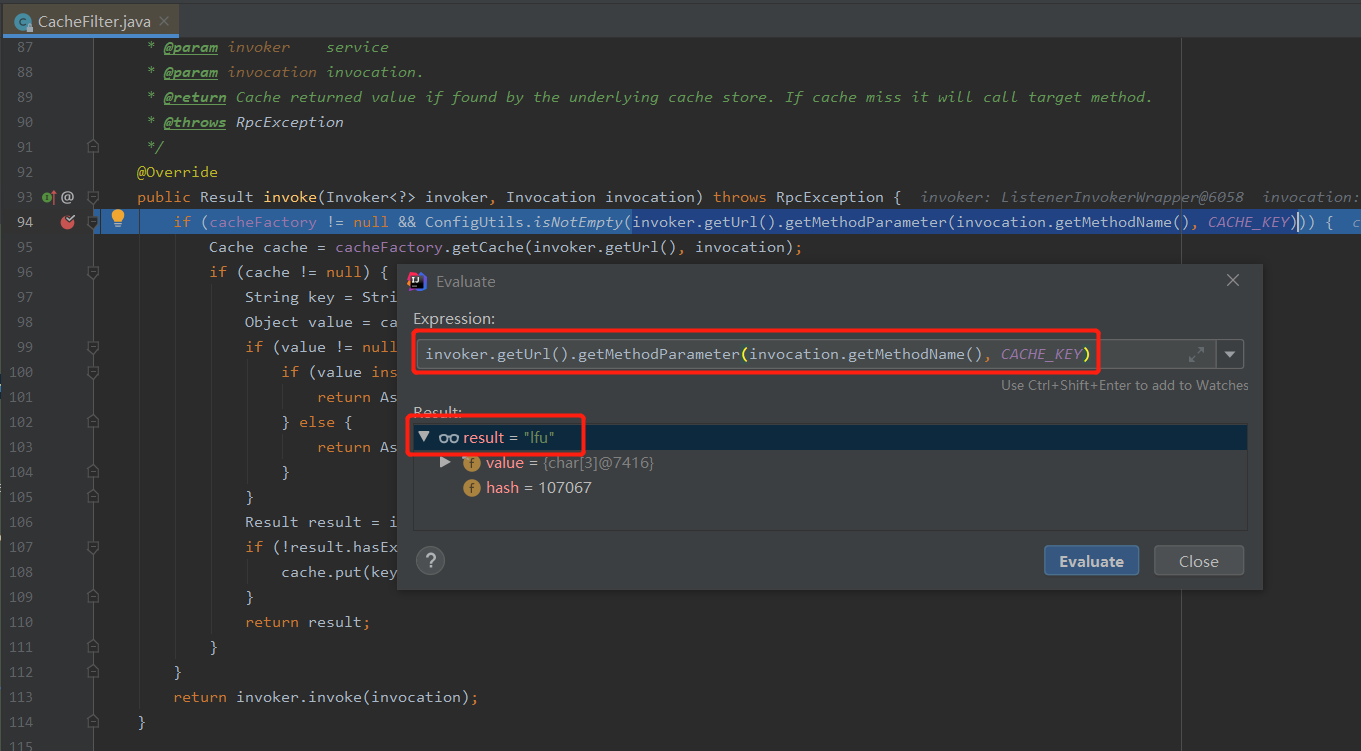
可以看到當前請求的快取策略確實是 lfu。
但是會丟擲一個錯誤:
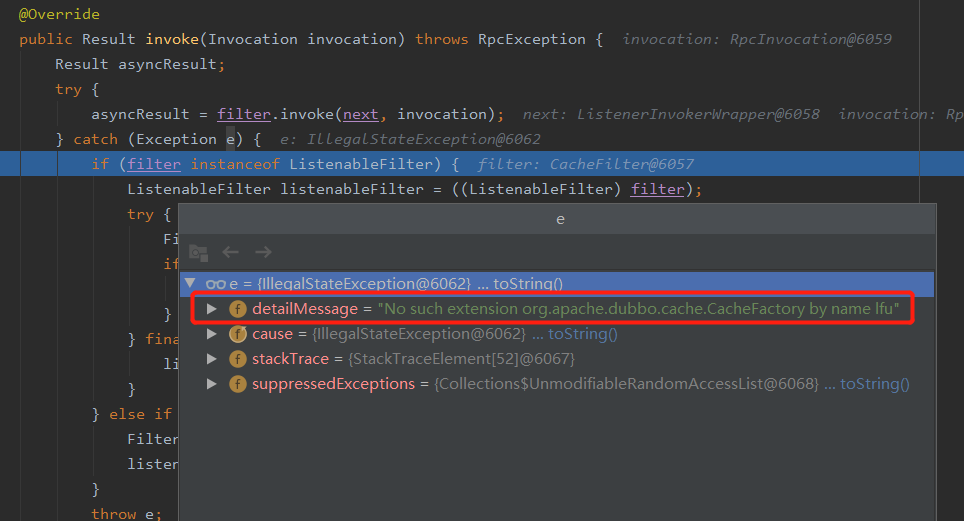
No such extension org.apache.dubbo.cache.CacheFactory by name lfu
沒有 lfu 這個策略。
這不是玩我嗎?

再看一下具體的原因。
在org.apache.dubbo.common.extension.ExtensionLoader#getExtensionClasses處只獲取到了 4 個快取策略,並沒有我們想要的 LFU:
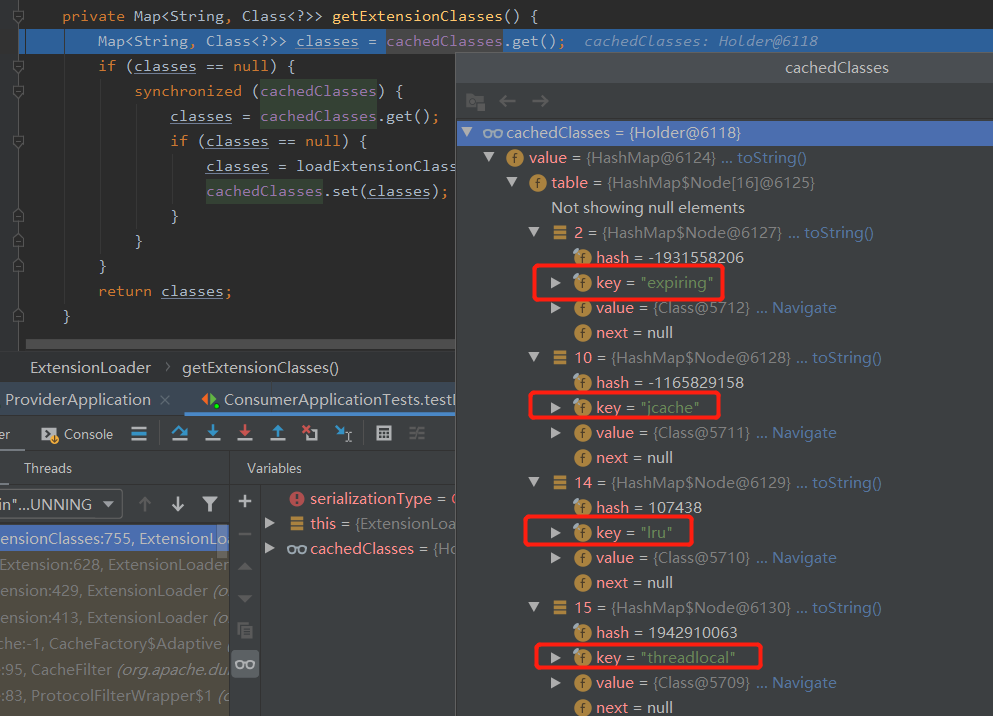
所以,在這裡丟擲了異常:
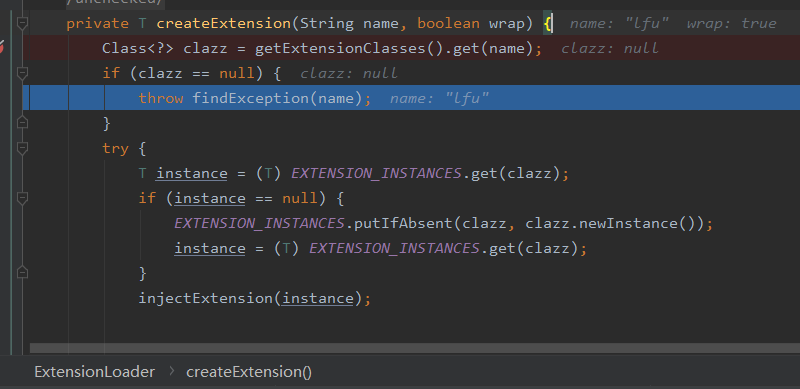
為什麼沒有找到我們想要的 LFU 呢?
那就的看你熟不熟悉 SPI 了。
在 SPI 檔案中,確實沒有 lfu 的配置:
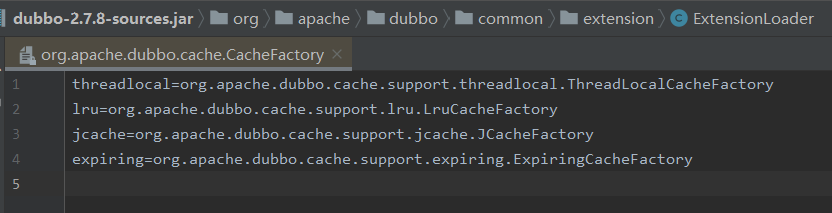
這就是 bug。
所以怎麼解決呢?
非常簡單,加上就完事了。
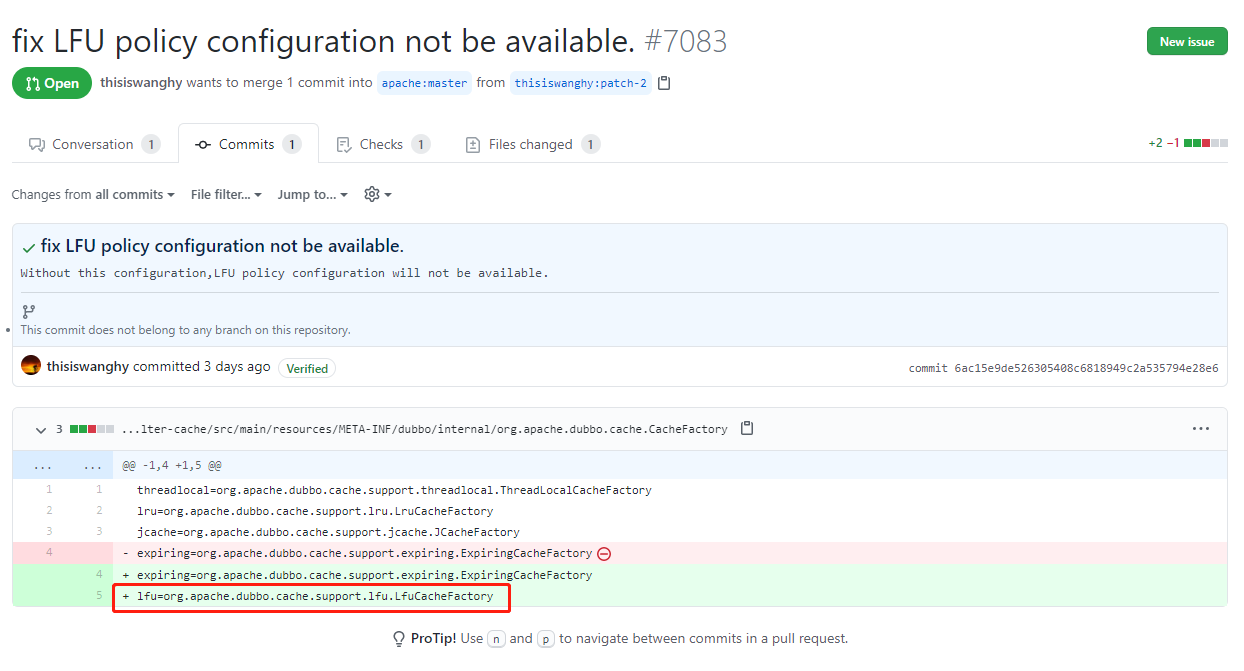
害,一不小心又給 Dubbo 貢獻了一行原始碼。

最後說一句(求關注)
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,可以在後臺提出來,我對其加以修改。
感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個主要寫程式碼,經常寫文章,偶爾拍視訊的程式猿。
