
池化技術總結
本文來源於公眾號《CV技術指南》的技術總結部分,更多相關技術總結請掃描文末二維碼關注公眾號。
導言:
池化是一個幾乎所有做深度學習的人都瞭解的一個技術,大家對池化如何進行前向傳播也都瞭解,池化的作用也瞭解一二。然而,池化如何回傳梯度呢,池化回傳梯度的原則是什麼呢,最大池化與平均池化的區別是什麼呢,什麼時候選擇最大池化、什麼時候選擇平均池化呢。
主要用的池化操作有平均池化、最大池化、全域性平均池化,全域性自適應池化。此外還有很多,如RoI池化、金字塔池化、重疊池化、隨機池化、雙線性池化等。
在本文中將會對這些內容一一總結。
池化的作用
1. 抑制噪聲,降低資訊冗餘。
2. 提升模型的尺度不變性、旋轉不變性。
3. 降低模型計算量。
4. 防止過擬合。
此外,最大池化作用:保留主要特徵,突出前景,提取特徵的紋理資訊。平均池化作用:保留背景資訊,突出背景。這兩者具體後面會介紹,這裡只介紹它們的作用。
池化回傳梯度
池化回傳梯度的原則是保證傳遞的loss(或者說梯度)總和不變。根據這條原則很容易理解最大池化和平均池化回傳梯度方式的不同。
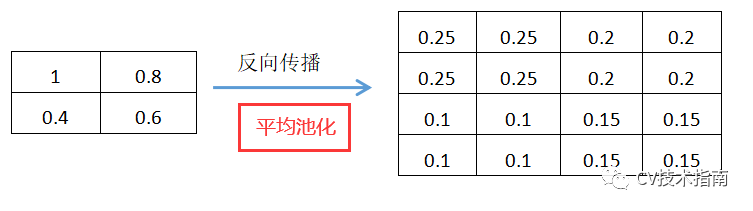
平均池化的操作是取每個塊( 如2x2 )的平均值,作為下一層的一個元素值,因此在回傳時,下一層的每一元素的loss(或者說梯度)要除以塊的大小( 如2x2 = 4),再分配到塊的每個元素上,這是因為該loss來源於塊的每個元素。
注意:如果塊的每個元素直接使用下一層的那個梯度,將會造成Loss之和變為原來的N倍。具體如下圖。
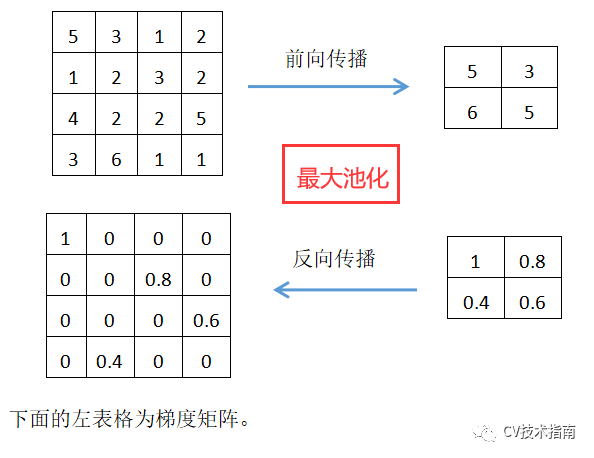
最大池化的操作是取每個塊的最大值作為下一層的一個元素值,因此下一個元素的Loss只來源於這個最大值,因此梯度更新也只更新這個最大值,其他值梯度為0。因此,最大池化需要在前向傳播中記錄最大值所在的位置,即max_id。這也是最大池化與平均池化的區別之一。具體如下圖所示:
最大池化與平均池化的使用場景
根據最大池化的操作,取每個塊中的最大值,而其他元素將不會進入下一層。眾所周知,CNN卷積核可以理解為在提取特徵,對於最大池化取最大值,可以理解為提取特徵圖中響應最強烈的部分進入下一層,而其他特徵進入待定狀態(之所以說待定,是因為當回傳梯度更新一次引數和權重後,最大元素可能就不是在原來的位置取到了)。
一般而言,前景的亮度會高於背景,因此,正如前面提到最大池化具有提取主要特徵、突出前景的作用。但在個別場合,前景暗於背景時,最大池化就不具備突出前景的作用了。
因此,當特徵中只有部分資訊比較有用時,使用最大池化。如網路前面的層,影象存在噪聲和很多無用的背景資訊,常使用最大池化。
同理,平均池化取每個塊的平均值,提取特徵圖中所有特徵的資訊進入下一層。因此當特徵中所有資訊都比較有用時,使用平均池化。如網路最後幾層,最常見的是進入分類部分的全連線層前,常常都使用平均池化。這是因為最後幾層都包含了比較豐富的語義資訊,使用最大池化會丟失很多重要資訊。
空間金字塔池化
首先嚐試一下用幾句話介紹一下空間金字塔池化的背景,空間金字塔池化出自目標檢測的SPPNet中,在目標檢測中需要生成很多區域候選框,但這些候選框的大小都不一樣,這些候選框最後都需要進入分類網路對候選框中的目標進行分類,因此需要將候選框所在區域變成一個固定大小的向量,空間金字塔池化就是解決這麼一個問題。
下面是具體做法。
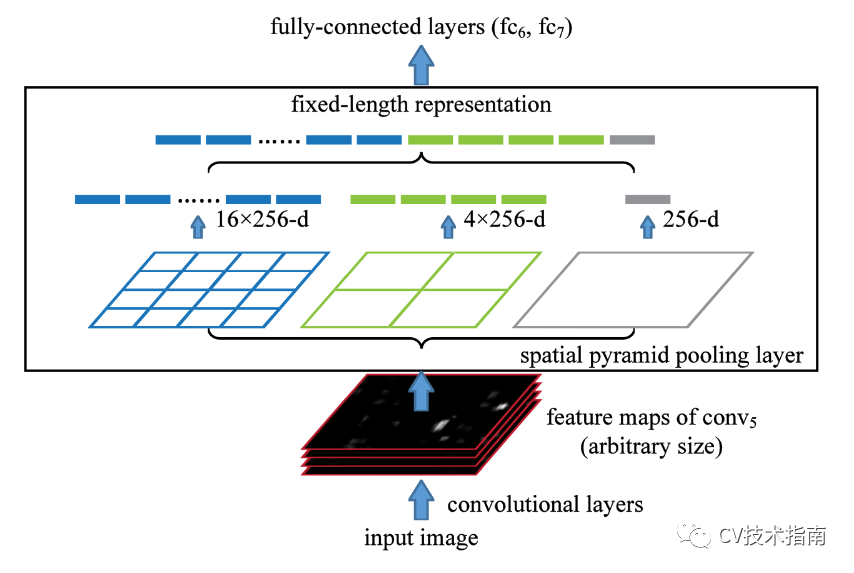
對於一個通道數為C的feature map,一取全域性最大值,得到一個1xC的張量,二將feature map分割成4塊,在每一塊上進行最大池化,得到一個4xC的張量,三將feature map分成16塊,在每塊上進行最大池化,得到一個16xC的張量,將這三個張量拼接起來,得到一個大小為21xC的張量。對於任意大小的feature map經過這些操作都可以得到固定大小的張量。
RoI池化
RoI即Region of Interest,RoI池化是空間金字塔池化的一種特殊形式。
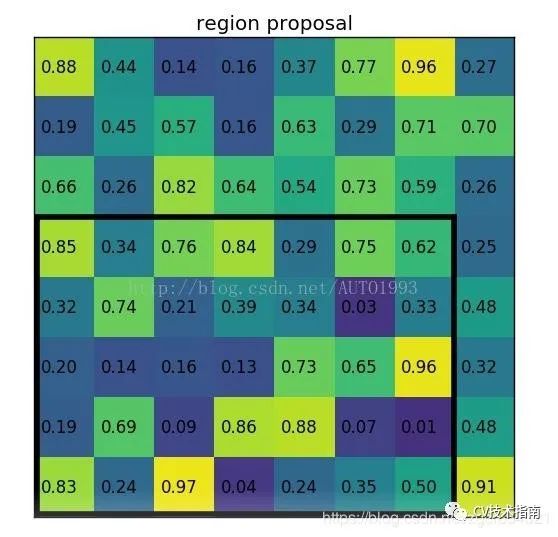
在目標檢測以前的方法中,使用selective search生成候選框,這些候選框是在特徵提取網路前就生成了,但經過特徵提取後該框的邊界不再是一個整數,例如,對於一個輸入為800x800的圖片,其中有一個665x665的框內框中一條狗,經過有五次池化的特徵提取網路後該框的區域變為了(665/32)*(665/32)=20.87*20.87的區域,因此RoI經過了第一次量化,對這個邊界進行取整為20,而分類網路的輸入固定大小為7x7。因此將20x20的區域分成7x7塊,由於20/7=2.86也不是整數,因此第二次量化,取2。然後在分塊上進行最大池化生成一個7x7的大小。具體如上圖所示。
這種方法經過兩次量化得到的RoI於原始的RoI有了一定的偏差,當候選框比較大時,這個偏差影響不會很大,但候選框本身比較小時,這個偏差相對來說比較大,嚴重影響結果。
本部分引用自部落格:https://blog.csdn.net/qq_33466954/article/details/106410410
其他型別的池化
重疊池化(Overlapping Pooling):一般而言,池化的視窗大小等於步長,因此池化作用區域不存在重合部分。所謂重疊池化,即池化視窗大小大於步長,池化作用區域存在重合部分,這種池化也許有一定的效果。
隨機池化(Stochastic Pooling):在一個池化視窗內對feature map的數值進行歸一化得到每個位置的概率值,然後按照此概率值進行隨機取樣選擇,即元素值大的被選中的概率也大。該池化的優點是確保了特徵圖中非最大響應值的神經元也有可能進入下一層被提取,隨機池化具有最大池化的優點,同時由於隨機性它能夠避免過擬合。
全域性自適應池化:其原理也是對於任意大小的feature map,都可以輸出指定的大小。這背後的原理不知是否與RoI池化類似,即對於輸入大小為HxW的feature map,指定輸出大小為7x7,我猜測其可能就是將HxW分成7x7塊再進行最大池化或平均池化。但真實情況需要閱讀原始碼方可知。若有知情讀者,可在公眾號中留言指出。
此外還有雙線性池化等不是很常用的池化,這裡不作過多介紹。
若有錯誤,歡迎留言指出。
本文來源於公眾號《CV技術指南》的技術總結部分,更多相關技術總結請掃描文末二維碼關注公眾號。
