
機器學習(一):5分鐘理解機器學習並上手實踐
阿新 • • 發佈:2021-01-16
# 引言
現在市面上的機器學習教程大多先學習數學基礎,然後學機器學習的數學演算法,再建立機器學習的數學模型,再學習深度學習,再學習工程化,再考慮落地。這其中每個環節都在快速發展,唯獨落地特別困難。我們花費大量時間成本去學習以上內容,成本無疑是特別昂貴的。所以我們不如先“盲人摸象”、“不求甚解”地探索下機器學習,淺嘗輒止。如果想到自己的應用場景,再學以致用,深入探索。這無疑是使沉沒成本最低的決策。
本教程適合興趣廣泛的人士增加自己知識的廣度,從應用的角度謹“使用”機器學習這款工具,是典型的黑盒思維。這非常契合筆者的思維方式,當然也是我個人的格局侷限。
本教程會淺顯易懂,讓你走的很快。但如果你想走的更遠還請學習數學。當然我們也只是暫時放下數學,先構建自己的知識體系。
**先抬頭看路,找準適合自己的方向,再埋頭趕路,或深耕下去……**
# 把視角拉高
從手工到工業化再到人工智慧,這是把人類從生產活動中逐漸解放的過程。用機器來幫助人們工作,一直是人類的美好願望。讓機器智慧化,以此來代替人力做更智慧問題,這可以作為人工智慧的簡單解釋。
很多教程或者書籍把人工智慧、機器學習、深度學習的關係解釋為從屬關係,人工智慧 > 機器學習 > 深度學習。這種解釋不錯,但卻無法表示他們之間的更深層次的關係。
**機器學習是通過數學方法在資料中尋找解釋,以此來實現人工智慧的一種手段。而深度學習是參照神經系統在機器學習基礎上發展出的一種高階技巧。** 它們之間是存在一定的依託關係、進化趨勢的。
狹義地講,傳統的機器學習是通過數學模型不斷求導來找出資料規律的過程。這其中數學模型的選擇尤為重要。隨著GPU、TPU等算力的發展,演算法技術的進步,甚至出現了自動選模型、自動調參的技術。我們可以構建複雜的神經網路結構,只要有足夠的算力支援,足夠的時間我們可以用深度學習處理非常複雜的任務。所以在程式碼操作上,深度學習甚至比傳統的機器學習對程式設計師更友好、更易理解。我們先學習傳統機器學習而非直接學習深度學習的好處是,我們可以通過對“黑盒”的拆箱來理解機器學習過程,掌握機器學習的概念,我會對其中應用的數學模型進行解釋。
我們先來看一下人工智慧產業鏈的結構,如下圖:
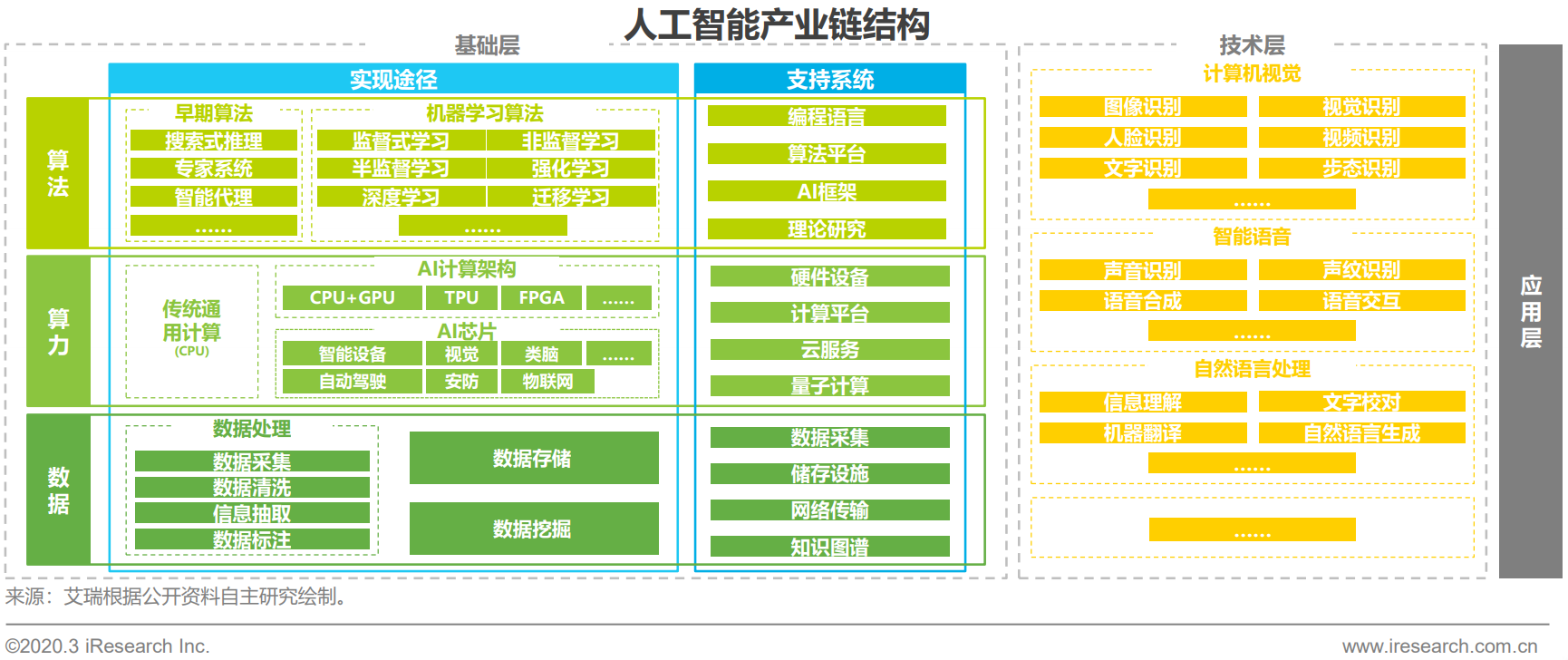
我們可以看到,機器學習的三大基石---算力、演算法與資料。機器學習的發展離不開演算法數學的進步,同樣離不開算力的發展。
在技術層面,機器學習在計算機視覺(CV, Computer Vision)和自然語言處理(NLP, Nature Language Processing)取得了關鍵的發展和應用。
演算法分類上,機器學習分為監督學習、非監督學習、半監督學習、強化學習等。
* **監督學習**:資料樣本有標籤。
* **非監督學習**:資料樣本無標籤。
* **半監督學習**:資料樣本有部分(少量)標籤。
* **強化學習**:趨向結果則獎勵,偏離結果則懲罰。
所謂Garbage in, Garbage out(垃圾進,垃圾出)。資料是機器學習的重中之重。我們需要花費大量的時間來處理資料,甚至佔到整個機器學習任務的90%以上。
比如資料處理過程中的資料採集,如果我們取樣的方式欠妥,就可能導致非代表性的資料集,這就導致了取樣偏差。
我們的資料可能會有很多無效的資料,我們需要剔除無效的資料,就叫做資料清洗。
我們通過挖掘大量資料來發現不太明顯的規律,就稱作資料探勘。
# 機器學習工業化流程
我們以一款工業化流水線工具TFX為例,看一下機器學習的技術流程。
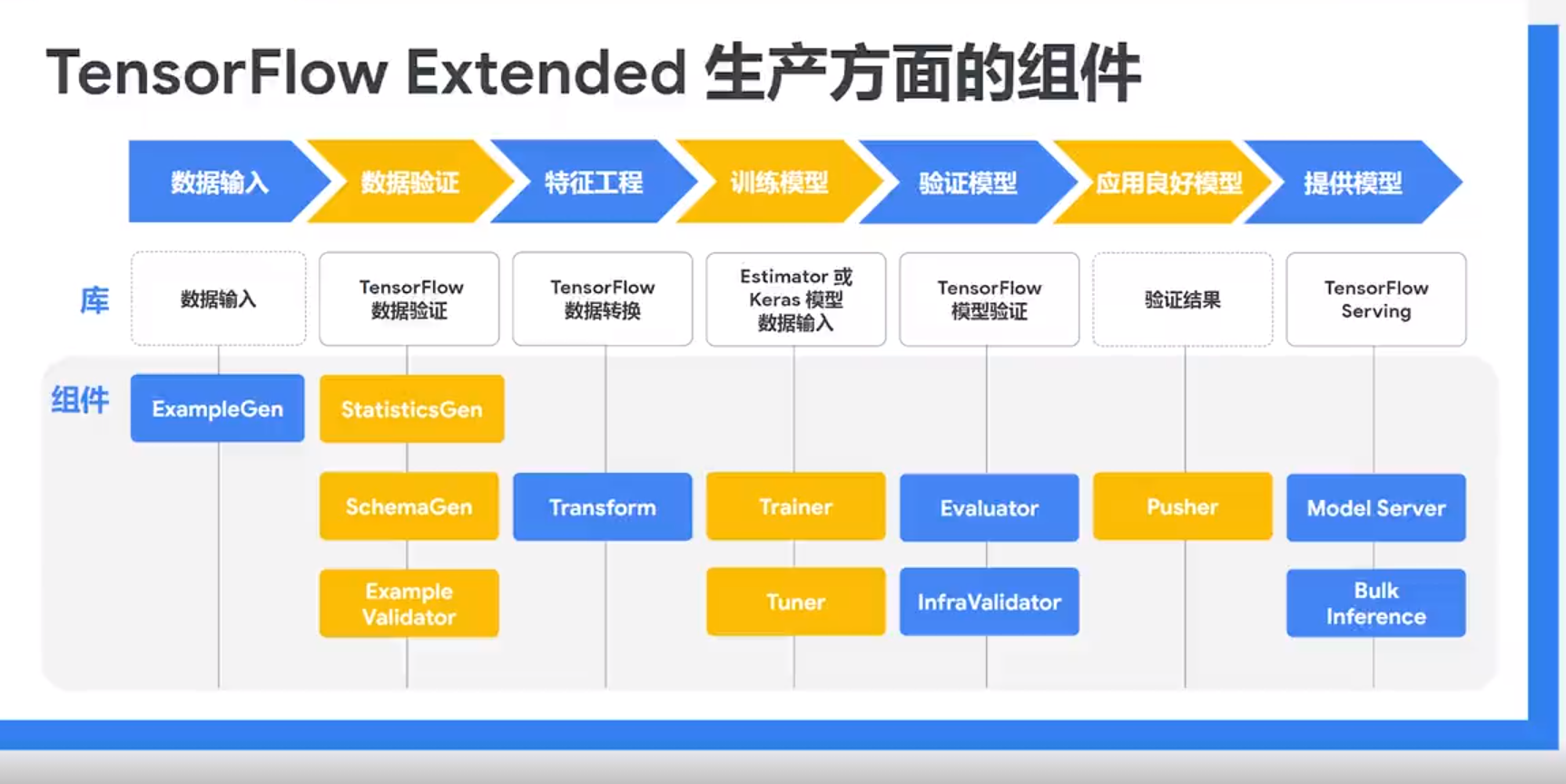
流程分為資料輸入、資料驗證、特徵工程、訓練模型、驗證模型、應用良好模型和提供模型六個部分:
1. 輸入資料,並根據需要拆分資料集。
2. 生成訓練資料和服務資料的特徵統計資訊。通過從訓練資料中推斷出型別、類別和範圍來建立架構。識別訓練資料和服務資料中的異常值。
3. 對資料集執行特徵工程。
4. 訓練模型,調整模型的超引數。
5. 對訓練結果進行深入分析,並幫助驗證匯出的模型。檢查模型是否確實可以從基礎架構提供服務,並防止推送不良模型。
6. 將模型部署到服務基礎架構。
我想通過以上解釋,大家應該可以對機器學習的實踐方法有了一定巨集觀的瞭解。
# 機器是如何學習的
我們從巨集觀角度看了機器學習的產業結構、工業化流程,你應該對你自己在機器學習的這些環節中有哪些發揮有了一定的把握。現在我們把視角拉回到微觀層面,看看機器是如何學習的。
我們以攝氏度轉換華氏度為例。
傳統程式設計中,我們要求得攝氏度和華氏度的關係,我們必須找出公式:
$$ Fahrenheit = Celsius * 1.8 + 32 $$
而在對機器學習來說,我們有大量的資料,卻需要找出關係。機器學習的過程就是不斷求導,以此來找出數學模型,來解釋規律的過程。
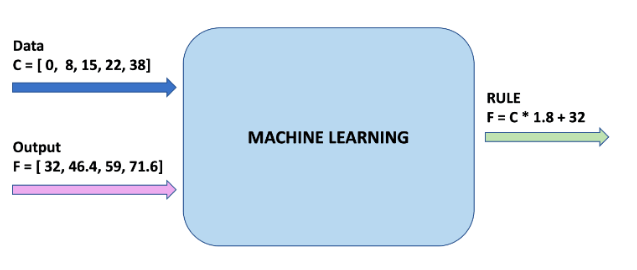
如圖所示,我們有攝氏度資料0, 8, 15, 22, 38以及華氏度資料32, 46.4, 59, 71.6, 100.4,機器學習的過程就是找出公式的過程。
其中,攝氏度就是我們的**特徵**,華氏度就是我們的**標籤**,攝氏度與華氏度的關係就是**例項**。
* **特徵**:我們模型的輸入。 在這種情況下,只有一個值-攝氏度。
* **標籤**:我們的模型預測的輸出。 在這種情況下,只有一個值-華氏度。
* **例項**:訓練期間使用的一對輸入/輸出。 在我們的例子中,是攝氏度/華氏度一對資料,例如,(0, 32), (8, 46.4)。
藍色的部分表示我們設定好數學函式,然後通過不斷的調整權重與偏差不斷地**擬合**資料,最終得到可以表示規律的**模型**的過程。
* **擬合**:通過訓練資料,使模型來概括表示資料的過程。
* **模型**:圖結構,包含了訓練過程中的權重與偏差的資料。其中的圖為由各函式組成的計算結構。
# 簡單上手機器學習程式碼
在上手程式碼之前我預設你已經配置好了環境,掌握了Jupyter, Numpy, Pandas, Matplotlib的用法。如果你沒有掌握以上技能,請參考我寫的配套教程[前置機器學習系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=MzUxMjU4NjI4MQ==&scene=1&album_id=1627166768236412929&count=3#wechat_redirect)
```
import numpy as np
import matplotlib.pyplot as plt
celsius = [[-40], [-10], [ 0], [ 8], [15], [22], [ 38]]
fahrenheit = [[-40], [ 14], [32], [46.4], [59], [71.6], [100.4]]
plt.scatter(celsius,fahrenheit, c='red', label='real')
plt.xlabel('celsius')
plt.ylabel('fahrenheit')
plt.legend()
plt.grid(True)
plt.title('real data')
plt.show()
```
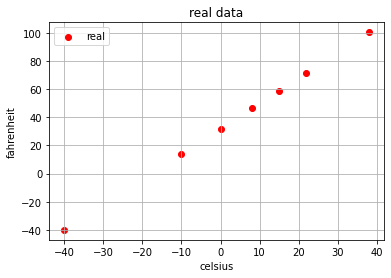
如上程式碼所示,我們準備攝氏度與華氏度的資料,然後通過matplotlib庫繪製圖像。
```
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(celsius,fahrenheit)
```
我們通過上方僅僅3行程式碼就訓練了資料。`LinearRegression`是scikit-learn包下的線性迴歸方法,是普通的最小二乘線性迴歸。而`fit`就是擬合的意思,以此來訓練模型。
```
celsius_test = [[-50],[-30],[10],[20],[50],[70]]
fahrenheit_test = lr.predict(celsius_test)
plt.scatter(celsius,fahrenheit, c='red', label='real')
plt.scatter(celsius_test,fahrenheit_test, c='orange', label='predicted')
plt.xlabel('celsius')
plt.ylabel('fahrenheit')
plt.legend()
plt.grid(True)
plt.title('estimated vs real data')
plt.show()
```
接下來我們呼叫`lr.predict(celsius_test)`方法來進行預測,以此來檢驗我們的模型準確度。我們通過下方影象中黃色的點可以看出,我們的模型非常準確。
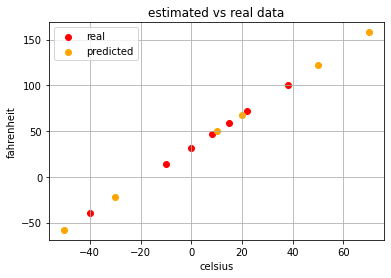
**你就說這玩意簡單不簡單!** 咳咳,別囂張,我們好好玩。
# 順帶一提的深度學習程式碼
既然都上手了,我們也試一試深度學習程式碼:
```
import tensorflow as tf
import numpy as np
# prepare data
celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
fahrenheit_a = np.array([-40, 14, 32, 46.4, 59, 71.6, 100.4], dtype=float)
# fit model
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Finished training the model")
# print loss
import matplotlib.pyplot as plt
plt.xlabel('Epoch Number')
plt.ylabel("Loss Magnitude")
plt.plot(history.history['loss'])
```
我們使用TensorFlow內建的Keras方法建立了1層的神經網路,選擇了MSE損失函式以及Adam優化器,訓練了500代。
如下圖可以看到,隨著代(epoch)數量的增加,損失函式的結果逐漸降低。
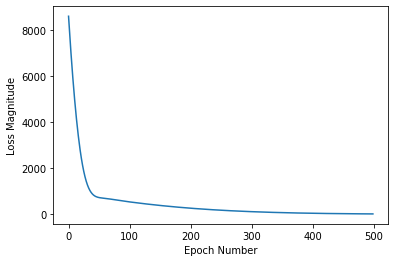
那麼什麼是損失函式呢?我們在接下來的文章中一探究竟。感謝您的關注公眾號【caiyongji】與支援!
# 前置學習系列
* [前置機器學習(五):30分鐘掌握常用Matplotlib用法](https://mp.weixin.qq.com/s/5brLPnUP6sYvc-_JO7IzkA)
* [前置機器學習(四):一文掌握Pandas用法](https://mp.weixin.qq.com/s/LlLkkBfI-4s3qdVaiv7EdQ)
* [前置機器學習(三):30分鐘掌握常用NumPy用法](https://mp.weixin.qq.com/s/U8dV8ENzzSx_VwBDdJdr_w)
* [前置機器學習(二):30分鐘掌握常用Jupyter Notebook用法](https://mp.weixin.qq.com/s/PCGThwI-YD7_hHxO35V8xw)
* [前置機器學習(一):數學符號及希臘字母](https://mp.weixin.qq.com/s/BLxyqK3CGV9yd92yGEs4XQ)