
國人之光:大資料分析神器Apache Kylin
阿新 • • 發佈:2021-01-20
一、簡介
Apache Kylin™是一個開源的、分散式的分析型資料倉庫,提供Hadoop/Spark 之上的 SQL 查詢介面及多維分析(OLAP)能力以支援超大規模資料,最初由 eBay 開發並貢獻至開源社群。之所以說它是國人之光,是因為它是首個由國人主導的Apache頂級開源專案,能在亞秒內查詢巨大的表。二、基本概念
先了解一下幾個概念,如下有一張表| ID | 客戶號 | 交易日期 | 交易型別 | 金額 |
| 1 | 001 | 20201230 | 工資代發 | 1000000 |
| 2 | 002 | 20210101 | 轉賬 | 66666 |
| 3 | 003 | 20210115 | 信用卡還款 | 1888 |
查詢某個客戶在哪個時間進行某種交易的金額,這種是多維分析,其中客戶號、交易日期和交易型別是維度(Dimensions),金額是度量(Measures)。
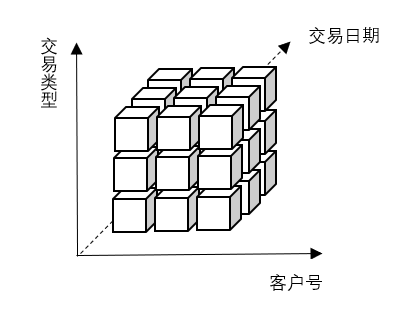 對於一個多維模型,在查詢上有多種組合,比如一維的:客戶號/交易日期/交易型別二維的:客戶號+交易日期/客戶號+交易型別/交易日期和交易型別三維的:客戶號+交易日期+交易型別對於每一種組合,稱之為Cuboid,這這些組合的統一,則是Cube。Cube定義了使用的模型、模型的維度和度量等資訊。
對於一個多維模型,在查詢上有多種組合,比如一維的:客戶號/交易日期/交易型別二維的:客戶號+交易日期/客戶號+交易型別/交易日期和交易型別三維的:客戶號+交易日期+交易型別對於每一種組合,稱之為Cuboid,這這些組合的統一,則是Cube。Cube定義了使用的模型、模型的維度和度量等資訊。
三、作用及原理
有些讀者就要說了:概念講了一堆,就是不說它到底為什麼出現,解決什麼問題,難怪閱讀量這麼少 別急,這不就準備講了嘛。Kylin是為減少在Hadoop/Spark上百億規模資料查詢延遲而設計的。 對於效率要求較高的大規模資料集的查詢,尤其多維查詢的時候,資料倉庫中一般存在事實表和維度表,需要關聯很多維度表,這就給查詢帶來一定的壓力,查詢效率低下。為了解決這個問題,Kylin應運而生。 但是Kylin為什麼快呢? 主要是因為它的預計算,它將多維分析可能用到的度量進行預計算,將計算好的結果儲存成Cube並存儲到HBase中,供查詢時直接訪問。說到底就是用空間換時間。 大致流程:將資料來源(比如Hive)中的資料按照指定的維度和指標,由計算引擎MapReduce離線計算出所有可能的查詢結果(即Cube)儲存到HBase中。HBase中每行記錄的Rowkey由各維度的值拼接而成,度量會儲存在column family中。為了減少儲存代價,會對維度和度量進行編碼。查詢階段,利用HBase列儲存的特性就可以保證Kylin有良好的快速響應和高併發。四、Kylin的架構
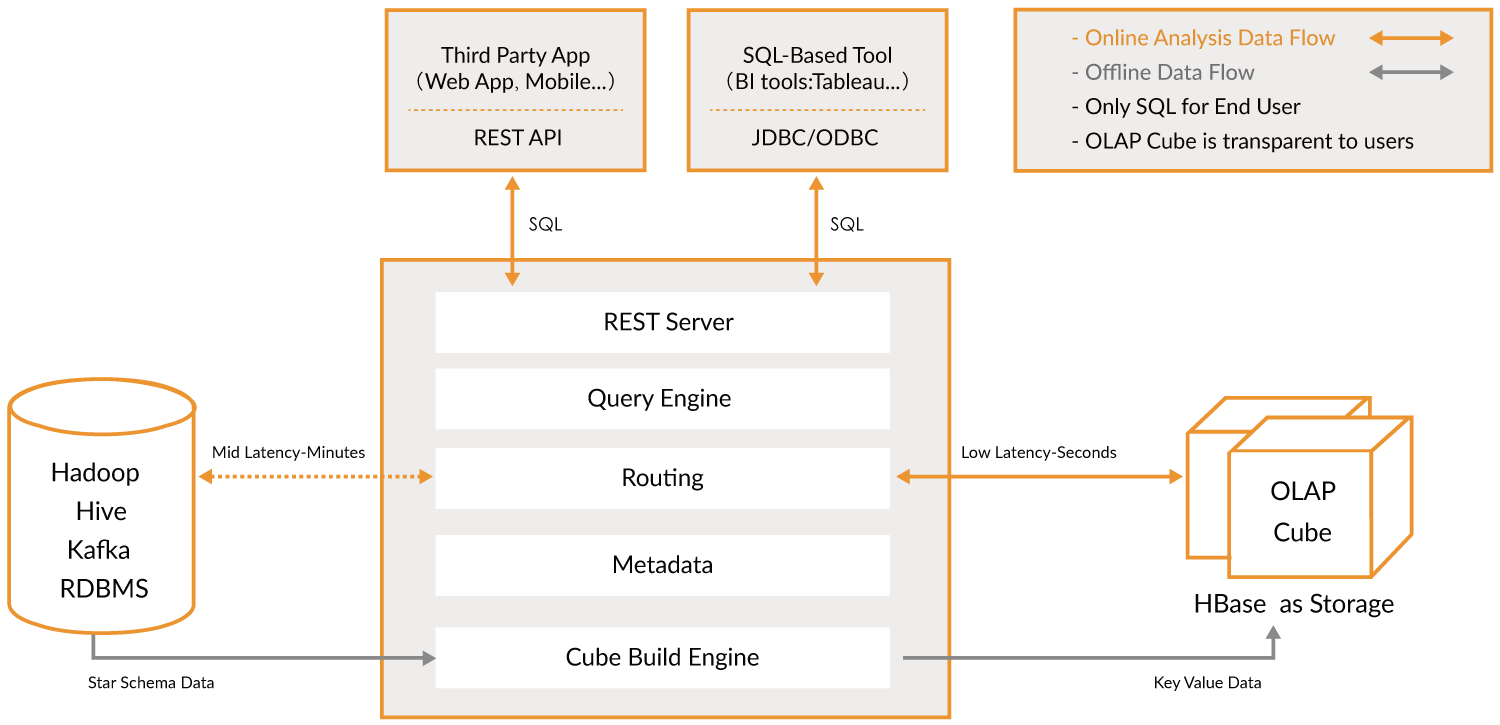 Kylin的架構主要有這幾個部分:
源資料:Hive、Kafka、RDBMS等;
對外查詢介面:REST API、JDBC/ODBC;
儲存引擎:HBase;
構建Cube的計算引擎。
其中構建Cube的計算引擎模組如下:
REST Server:是一套面向應用程式開發的入口點,旨在實現針對Kylin平臺的應用開發工作。
Query Engine:當cube準備就緒後,查詢引擎就能夠獲取並解析使用者查詢。
Routing:查詢路由,負責將解析的SQL生成的執行計劃轉換成cube快取的查詢,若查詢沒辦法從cube快取中獲取,則下壓至資料來源進行查詢。
Metadata:Kylin是由元資料驅動的。元資料管理工具是一大關鍵性元件,用於對儲存在Kylin當中的所有元資料進行管理,其中包括最為重要的cube元資料。
Cube Build Engine:這套引擎的作用在於處理所有離線任務。
Kylin的架構主要有這幾個部分:
源資料:Hive、Kafka、RDBMS等;
對外查詢介面:REST API、JDBC/ODBC;
儲存引擎:HBase;
構建Cube的計算引擎。
其中構建Cube的計算引擎模組如下:
REST Server:是一套面向應用程式開發的入口點,旨在實現針對Kylin平臺的應用開發工作。
Query Engine:當cube準備就緒後,查詢引擎就能夠獲取並解析使用者查詢。
Routing:查詢路由,負責將解析的SQL生成的執行計劃轉換成cube快取的查詢,若查詢沒辦法從cube快取中獲取,則下壓至資料來源進行查詢。
Metadata:Kylin是由元資料驅動的。元資料管理工具是一大關鍵性元件,用於對儲存在Kylin當中的所有元資料進行管理,其中包括最為重要的cube元資料。
Cube Build Engine:這套引擎的作用在於處理所有離線任務。
五、總結
本文大概介紹了Kylin以及一些相關的概念和原理、架構。更多內容可以去Kylin 官網進行了