
Golang應用效能問題排查分析
阿新 • • 發佈:2021-01-21
## 背景
公司有一個使用golang開發的採集模組,負責呼叫多個外部系統採集資料;最近做了一次架構上的調整,將採集模組分成api、job兩個子模組,並部署到容器中,拆分前部署在虛機上。
## 現象
部分採集任務在容器中的執行時間比虛機中執行時間要長,8倍左右,本地測試無異常
## 排查思路
### 呼叫外部介面耗時過長?
只有部分任務執行時間長,懷疑容器呼叫那部分系統介面比較慢,於是在容器中curl外部介面介面,發現並不慢,排除這個可能。
### 程式問題?
將現有部署在虛機中的正常執行的應用,部署到容器中發現部分任務也會慢; 將部署在容器中的應用部署到虛機後恢復了正常;懷疑是容器本身或容器網路的問題,一時想不到是什麼原因,於是開始了漫長的定位
### pprof
> pprof是golang提供的效能分析工具之一,採集模組已經引入pprof,首先使用它進行排查;
(1). 在容器中安裝pprof/flamegraph1
(2). 在容器中執行如下命令,開啟pprof的http服務

(3).輸入上述http地址
* 檢視cpu profiler
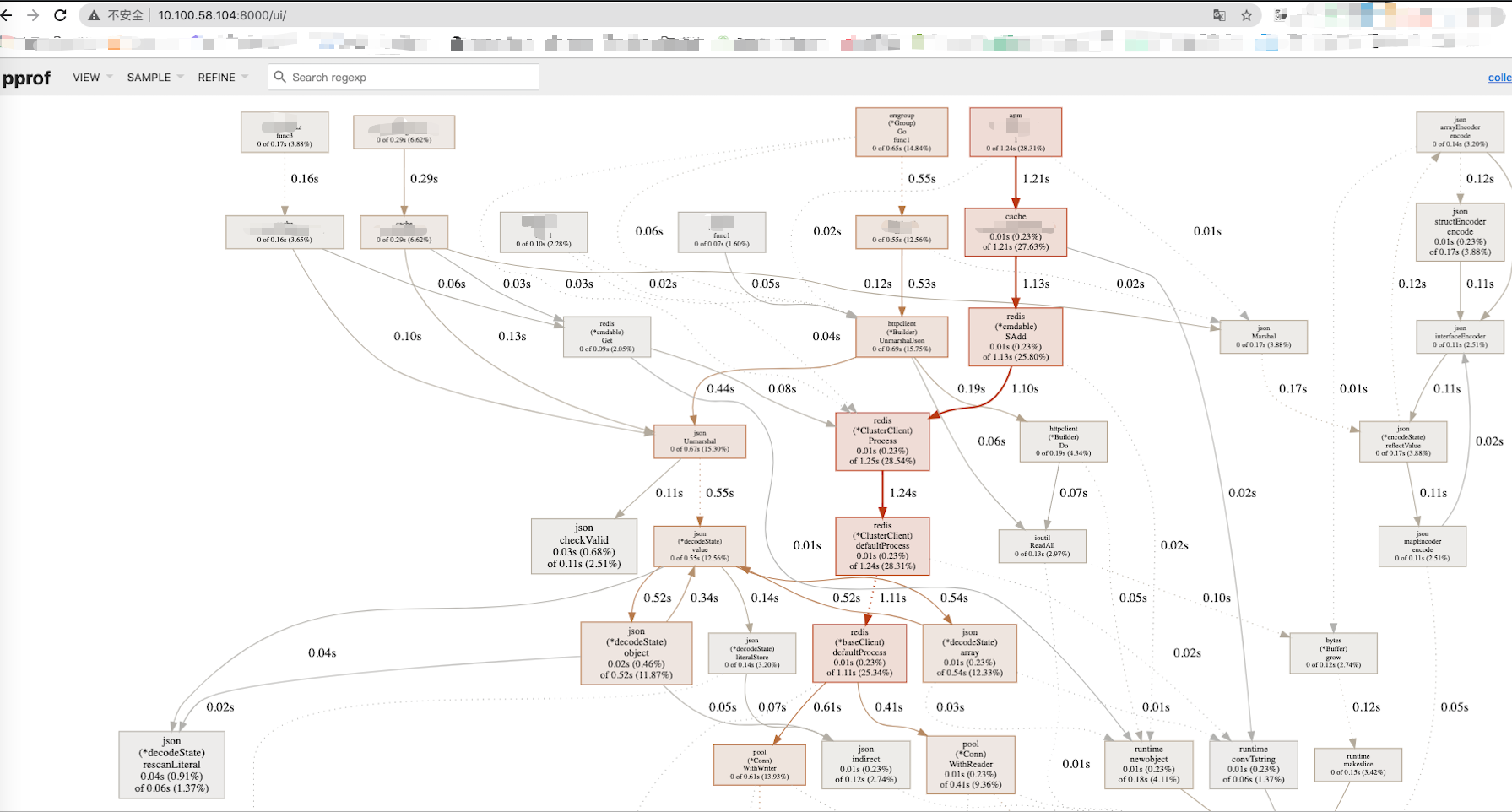
>