
剖析虛幻渲染體系(02)- 多執行緒渲染
阿新 • • 發佈:2021-01-26
[TOC]
# **2.1 多執行緒程式設計基礎**
為了更平穩地過渡,在真正進入UE的多執行緒渲染知識之前,先學習或重溫一下多執行緒程式設計的基礎知識。
## **2.1.1 多執行緒概述**
**多執行緒(Multithread)**程式設計的思想早在單核時代就已經出現了,當時的作業系統(如Windows95)就已經支援多工的功能,其原理就是在單核中切換不同的上下文(Context),以便每個程序中的執行緒都有時間獲得執行指令的機會。
但到了2005年,當單核主頻接近4GHz時,CPU硬體廠商英特爾和AMD發現,速度也會遇到自己的極限:那就是單純的主頻提升,已經無法明顯提升系統整體效能。
隨著單核計算頻率摩爾定律的緩慢終結,Intel率先於2005年釋出了奔騰D和奔騰四至尊版840系列,首次支援了兩個物理級別的執行緒計算單元。此後十多年,多核CPU得到蓬勃發展,由AMD製造的Ryzen 3990X處理器已經擁有64個核心128個邏輯執行緒。

*銳龍(Ryzen)3990X的宣傳海報中赫然凸顯的核心與執行緒數量。*
硬體的多核發展,給軟體極大的發揮空間。應用程式可以充分發揮多核多執行緒的計算資源,各個應用領域由此也產生多執行緒程式設計模型和技術。作為遊戲的發動機Unreal Engine等商業引擎,同樣可以利用多執行緒技術,以便更加充分地提升效率和效果。
使用多執行緒併發帶來的作用總結起來主要有兩點:
* **分離關注點。**通過將相關的程式碼與無關的程式碼分離,可以使程式更容易理解和測試,從而減少出錯的可能性。比如,遊戲引擎中通常將檔案載入、網路傳輸放入獨立的執行緒中,既可以不阻礙主執行緒,也可以分離邏輯程式碼,使得更加清晰可擴充套件。
* **提升效能。**人多力量大,這樣的道理同樣用到CPU上(核多力量大)。相同量級的任務,如果能夠分散到多個CPU中同時執行,必然會帶來效率的提升。
但是,隨著CPU核心數量的提升,計算機獲得的效益並非直線提升,而是遵循**Amdahl's law(阿姆達爾定律)**,Amdahl's law的公式定義如下:
$$
S_{latency}(s) = \frac{1}{(1-p) + \frac{p}{s}}
$$
公式的各個分量含義如下:
* $S_{latency}$:整個任務在多執行緒處理中理論上獲得的加速比。
* $s$:用於執行任務並行部分的硬體資源的執行緒數量。
* $p$:可並行處理的任務佔比。
舉個具體的栗子,假設有8核16執行緒的CPU用於處理某個任務,這個任務有70%的部分是可以並行處理的,那麼它的理論加速比為:
$$
S_{latency}(16) = \frac{1}{(1-0.7) + \frac{0.7}{16}} = 2.9
$$
由此可見,多執行緒程式設計帶來的效益並非跟核心數呈直線正比,實際上它的曲線如下所示:
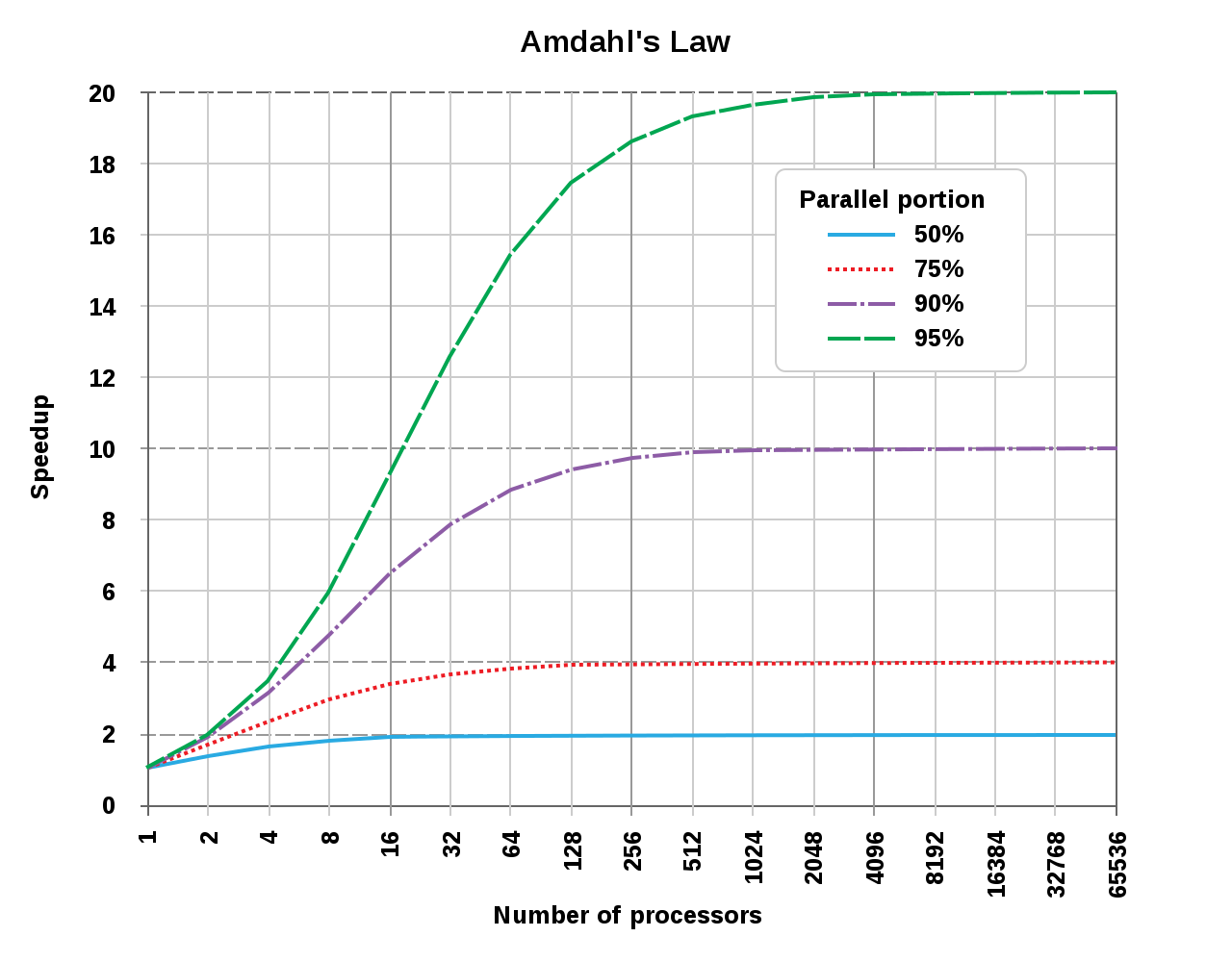
*阿姆達爾定律揭示的核心數和加速比圖例。由此可見,可並行的任務佔比越低,加速比獲得的效果越差:當可並行任務佔比為50%時,16核已經基本達到加速比天花板,無論後面增加多少核心數量,都無濟於事;如果可並行任務佔比為95%時,到2048個核心才會達到加速比天花板。*
雖然阿姆達爾定律給我們帶來了殘酷的現實,但是,如果我們能夠提升任務並行佔比到接近100%,則加速比天花板可以得到極大提升:
$$
S_{latency}(s) = \frac{1}{(1-p) + \frac{p}{s}} = \frac{1}{(1-1) + \frac{1}{s}} = s
$$
如上公式所示,當$p=1$(即可並行的任務佔比100%)時,理論上的加速比和核心數量成線性正比!!
舉個具體的例子,在編譯Unreal Engine工程原始碼或Shader時,由於它們基本是100%的並行佔比,理論上可以獲得接近線性關係的加速比,在多核系統中將極大地縮短編譯時間。
利用多執行緒併發提高效能的方式有兩種:
* **任務並行(task parallelism)。**將一個單個任務分成幾部分,且各自並行執行,從而降低總執行時間。這種方式雖然看起來很簡單直觀,但實際操作中可能會很複雜,因為在各個部分之間可能存在著依賴。
* **資料並行(data parallelism)。**任務並行的是演算法(執行指令)部分,即每個執行緒執行的指令不一樣;而資料並行是指令相同,但執行的資料不一樣。SIMD也是資料並行的一種方式。
上面闡述了多執行緒併發的益處,接下來說說它的副作用。總結起來,副作用如下:
* **導致資料競爭。**多執行緒訪問常常會交叉執行同一段程式碼,或者操作同一個資源,又或者多核CPU的高度快取同步問題,由此變化帶來各種資料不同步或資料讀寫錯誤,由此產生了各種各樣的異常結果,這便是資料競爭。
* **邏輯複雜化,難以除錯。**由於多執行緒的併發方式不唯一,不可預知,所以為了避免資料競爭,常常加入複雜多樣的同步操作,程式碼也會變得離散、片段化、繁瑣、難以理解,增加程式碼的輔助,對後續的維護、擴充套件都帶來不可估量的阻礙。也會引發小概率事件難以重現的BUG,給除錯和查錯增加了數量級的難度。
* **不一定能夠提升效益。**多執行緒技術用得到確實會帶來效率的提升,但並非絕對,常和物理核心、同步機制、執行時狀態、併發佔比等等因素相關,在某些極端情況,或者用得不夠妥當,可能反而會降低程式效率。
## **2.1.2 多執行緒概念**
本小節將闡述多執行緒程式設計技術中常涉及的基本概念。
* **程序(Process)**
**程序(Process)**是作業系統執行應用程式的基本單元和實體,它本身只是個容器,通常包含核心物件、地址空間、統計資訊和若干執行緒。它本身並不真正執行程式碼指令,而是交由程序內的執行緒執行。
對Windows而言,作業系統在建立程序時,同時也會給它建立一個執行緒,該執行緒被稱為**主執行緒**(Primary thread, Main thread)。
> 對Unix而言,程序和主執行緒其實是同一個東西,作業系統並不知道有執行緒的存在,執行緒更接近於lightweight processes(輕量級程序)的概念。
程序有優先順序概念,Windows下由低到高為:低(Low)、低於正常(Below normal)、正常(Normal)、高於正常(Above normal)、高(High)、實時(Real time)。(見下圖)
預設情況下,程序的優先順序為Normal。優先順序高的程序將會優先獲得執行機會和時間。
* **執行緒(Thread)**
**執行緒(Thread)**是可以執行程式碼的實體,通常不能獨立存在,需要依附在某個程序內部。一個程序可以擁有多個執行緒,這些執行緒可以共享程序的資料,以便並行或併發地執行多個任務。
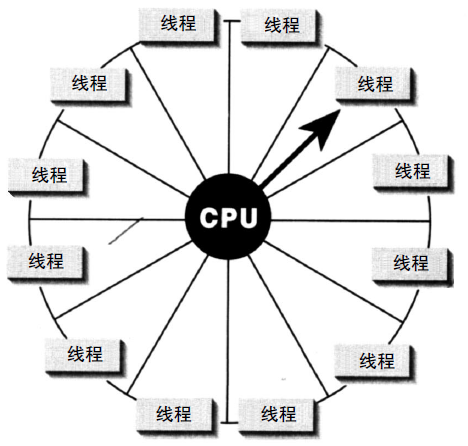
在單核CPU中,作業系統(如Windows)可能會採用輪循(Round robin)的方式進行排程,使得多個執行緒看起來是同時執行的。(下圖)
在多核CPU中,執行緒可能會安排在不同的CPU核心同時執行,從而達到並行處理的目的。
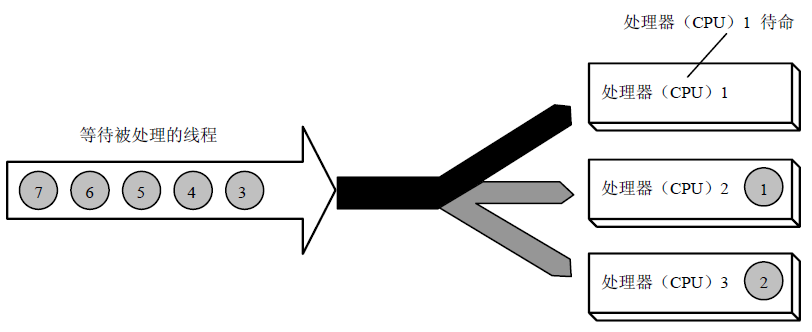
*採用SMP的Windows在多核CPU的執行示意圖。等待處理的執行緒被安排到不同的CPU核心。*
每個執行緒可擁有自己的執行指令上下文(如Windows的IP(指令暫存器地址)和SP(棧起始暫存器地址))、執行棧和TLS(Thread Local Storage,執行緒區域性快取)。
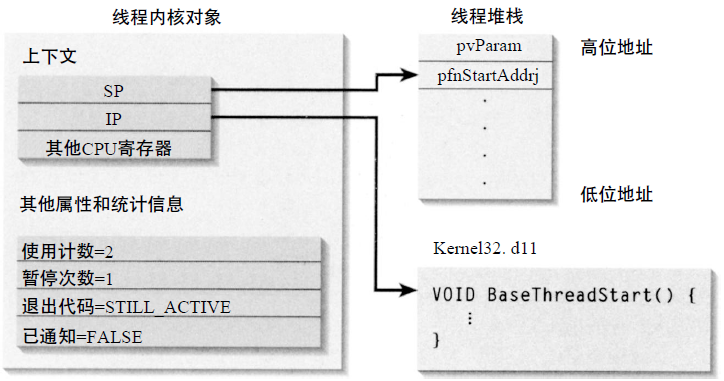
*Windows執行緒建立和初始化示意圖。*
> **執行緒區域性儲存(Thread Local Storage)**是一種儲存持續期,物件的生命週期與執行緒一樣,線上程開始時分配,執行緒結束時回收。每個執行緒有該物件自己的例項,訪問和修改這樣的物件不會造成競爭條件(Race Condition)。
執行緒也存在優先順序概念,優先順序越高的將優先獲得執行指令的機會。
執行緒的狀態一般有執行狀態、暫停狀態等。Windows可用以下介面切換執行緒狀態:
```c++
// 暫停執行緒
DWORD SuspendThread(HANDLE hThread);
// 繼續執行執行緒
DWORD ResumeThread(HANDLE hThread);
```
同個執行緒可被多次暫停,如果要恢復執行狀態,則需要呼叫同等次數的繼續執行介面。
* **協程(Coroutine)**
**協程(Coroutine)**是一種輕量級(lightweight)的使用者態執行緒,通常跑在同一個執行緒,利用同一個執行緒的不同時間片段執行指令,沒有執行緒、程序切換和排程的開銷。從使用者角度,可以利用協程機制實現在同個執行緒模擬非同步的任務和編碼方式。在同個執行緒內,它不會造成資料競爭,但也會因執行緒阻塞而阻塞。
* **纖程(Fiber)**
**纖程(Fiber)**如同協程,也是一種輕量級的使用者態執行緒,可以使得應用程式獨立決定自己的執行緒要如何運作。作業系統核心不知道纖程的存在,也不會為它進行排程。
* **競爭條件(Race Condition)**
同個程序允許有多個執行緒,這些執行緒可以共享程序的地址空間、資料結構和上下文。程序內的同一資料塊,可能存在多個執行緒在某個很小的時間片段內同時讀寫,這就會造成資料異常,從而導致了不可預料的結果。這種不可預期性便造就了**競爭條件(Race Condition)**。
避免產生競爭條件的技術有很多,諸如原子操作、臨界區、讀寫鎖、核心物件、訊號量、互斥體、柵欄、屏障、事件等等。
* **並行(Parallelism)**
至少兩個執行緒同時執行任務的機制。一般有多核多物理執行緒的CPU同時執行的行為,才可以叫並行,單核的多執行緒不能稱之為並行。
* **併發(Concurrency)**
至少兩個執行緒利用時間片(Timeslice)執行任務的機制,是並行的更普遍形式。即便單核CPU同時執行的多執行緒,也可稱為併發。
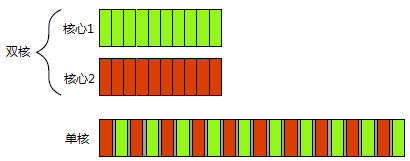
*併發的兩種形式——上:雙物理核心的同時執行(並行);下:單核的多工切換(併發)。*
事實上,併發和並行在多核處理器中是可以同時存在的,比如下圖所示,存在雙核,每個核心又同時切換著多個任務:
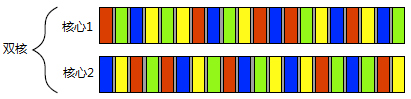
> 部分參考文獻嚴格區分了並行和併發,但部分文獻並不明確指出其中的區別。虛幻引擎的多執行緒渲染架構和API中,常出現並行和併發的概念,所以虛幻是明顯區分兩者之間的含義。
* **執行緒池(Thread Pool)**
執行緒池提供了一種新的任務併發的方式,呼叫者只需要傳入一組可並行的任務和分組的策略,便可以使用執行緒池的若干執行緒併發地執行任務,使得呼叫者無需接直接觸執行緒的呼叫和管理細節,降低了呼叫者的成本,也提升了執行緒的排程效率和吞吐量。
不過,建立一個執行緒池時,幾個關鍵性的設計問題會影響併發效率,比如:可使用的執行緒數量,高效的任務分配方式,以及是否需要等待一個任務完成。
執行緒池可以自定義實現,也可以直接使用C++、作業系統或第三方庫提供的API。
## **2.1.3 C++的多執行緒**
在C++11之前,C++的多執行緒支援基本為零,僅提供少量雞肋的`volatile`等關鍵字。直到C++11標準,多執行緒才真正納入C++標準,並提供了相關關鍵字、STL標準庫,以便使用者實現跨平臺的多執行緒呼叫。
當然,對使用者來說,多執行緒的實現可採用C++11的執行緒庫,也可以根據具體的系統平臺提供的多執行緒API自定義執行緒庫,還可以使用諸如ACE、boost::thread等第三方庫。使用C++自帶的多執行緒庫,有幾個優點,一是使用簡單方便,依賴少;二是跨平臺,無需關注系統底層。
### **2.1.3.1 C++多執行緒關鍵字**
* **thread_local**
thread_local是C++是實現執行緒區域性儲存的關鍵,添加了此關鍵字的變數意味著每個執行緒都有自己的一份資料,不會共享同一份資料,避免資料競爭。
C11的關鍵字`_Thread_local`用於定義執行緒區域性變數。在