
影象分類學習:X光胸片診斷識別----遷移學習
阿新 • • 發佈:2021-01-26
# 引言
剛進入人工智慧實驗室,不知道是在學習機器學習還是深度學習,想來他倆可能是一個東西,查閱之後才知道這是兩個領域,或許也有些交叉,畢竟我也剛接觸,不甚瞭解。
在我還是個純度小白之時,寫下這篇文章,希望後來同現在的我一樣,剛剛涉足此領域的同學能夠在這,跨越時空,在小白與小白的交流中得到些許幫助。
# 開始
在只會一些==python==語法,其他啥都沒有,第一週老師講了一些機器學習和深度學習的瞭解性內容,就給了一個實驗,讓我們一週內弄懂並跑出來,其實老師的程式碼已經完成了,我們可以直接放進Pycharm裡跑出來,但是程式碼細節並沒有講,俗話說師傅領進門,修行在個人。那就從最基本的開始,把這個程式碼弄懂,把實驗理解。
下面我會先把整個程式碼貼出來,之後一步一步去分析每個模組,每個函式的作用。
# 說明
本實驗來自[此處](https://www.jianshu.com/p/40545dcdee76)部落格,我們的實驗也是基於這個部落格的內容學習的。
### 一、資料集
資料來源於kaggle,可在[此連結](https://www.datafountain.cn/datasets/79)自行下載
### 二、執行程式碼
### 三、解析
#### 從頭開始,先來看這段程式碼(註釋進行解釋):
```
# 進行一系列資料增強,然後生成訓練(train)、驗證(val)、和測試(test)資料集
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}
```
這是一個字典資料型別,其中鍵分別為:==train、val、test==對應資料集裡的三個資料夾==train、val、test==
鍵train對應的值是一個操作==transfroms.Compose( [列表] )==
引數為一個列表,列表中的元素為四個操作:
==transforms.RandomResizedCrop()
transforms.RandomHorizontalFlip()
transforms.ToTensor
transforms.ToTensortransforms.Normalize()==
==transforms==在torchvision中,一個影象處理包,可以通過它呼叫一些影象處理函式,對影象進行處理
==transfroms.Compose( [列表] )==:此函式存在於==torchvision.transforms==中,一般用==Compose==函式把多個步驟整合到一起
==transforms.RandomResizedCrop(數字)==:將給定影象隨機裁剪為不同的大小和寬高比,然後縮放所裁剪得到的影象為制定的大小;(即先隨機採集,然後對裁剪得到的影象縮放為同一大小)
例如:
==transforms.RandomHorizontalFlip()==:以給定的概率隨機水平旋轉給定的PIL的影象,預設為0.5;
例如:

==transforms.ToTensor==:將給定影象轉為Tensor(一個數據型別,類似有深度的矩陣)
例如:
==transforms.ToTensortransforms.Normalize()==:歸一化處理
例如:
函式詳細內容請檢視[此處文章](https://blog.csdn.net/see_you_yu/article/details/106722787)
==可以看出,這一塊的程式碼就是定義一種操作集合,將一張圖片進行剪裁、旋轉、轉為一種資料、資料歸一化==
#### 繼續往下看,相應的解釋都在註釋中
```
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in
['train', 'val', 'test']}
dataloaders_dict = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in
['train', 'val', 'test']}
```
首先是資料匯入部分,這裡採用官方寫好的torchvision.datasets.ImageFolder介面實現資料匯入。這個介面需要你提供影象所在的資料夾
x是字典的鍵,從後面的for迭代的範圍中獲取,有'train', 'val', 'test'三個值
datasets.ImageFolder(os.path.join(==data_dir==, x), data_transforms[x])高亮部分是資料集的資料夾路徑,找到檔案後,確定x,在執行第二個引數data_transforms[x],把x進行一些列處理
前面torchvision.datasets.ImageFolder只是返回列表,列表是不能作為模型輸入的(我也不知道為什麼),因此在PyTorch中需要用另一個類來封裝列表,那就是:torch.utils.data.DataLoader
torch.utils.data.DataLoader類可以將列表型別的輸入資料封裝成Tensor資料格式,以備模型使用。
#### 好,我們繼續往下看
```
# 定義一個檢視圖片和標籤的函式
def imshow(inp, title=None):
# transpose(0,1,2),0是x軸,1是y軸,2是z軸,由(0,1,2)變為(1,2,0)就是x和z軸先交換,x和y軸再交換
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406]) # 建立一個數組[0.485, 0.456, 0.406]
std = np.array([0.229, 0.224, 0.225]) # 同樣也是建立一個數組
inp = std * inp + mean # 調整影象尺寸大小等
inp = np.clip(inp, 0, 1) # 小於0的都為0,大於1的都為1,之間的不變
plt.imshow(inp) # 設定影象為灰色
if title is not None: # 如果影象有標題則顯示標題
plt.title(title) # 設定影象標題
plt.pause(0.001) # 視窗繪製後停留0.001秒
imgs, labels = next(iter(dataloaders_dict['train'])) # 自動往下迭代引數物件
out = torchvision.utils.make_grid(imgs[:8]) # 將8個圖拼成一張圖片
classes = image_datasets['test'].classes # 每個影象的檔名
# out是一個8個圖片拼成的長圖,經過imshow()處理後附加標題(圖片檔名的前8個字母)輸出
# imshow(out, title=[classes[x] for x in labels[:8]])
```
==輸出後,在IDE中是這樣的(右上角):==
#### 好,想在繼續往下走
下面呢給出了四個訓練模型,實戰中我們只需要挑其中一個進行訓練就好,其他的模型要註釋掉,下面程式碼上四個模型我都會分析
```
# inception------------------------------------------------------inception模型,有趣的是它可以翻譯為盜夢空間
model = models.inception_v3(pretrained=True)
# inception_v3是一個預訓練模型, pretrained=True執行後會把模型下載到我們的電腦上
model.aux_logits = False # 是否給模型建立輔助,具體增麼個輔助太複雜,請觀眾老爺們自行谷歌
num_fc_in = model.fc.in_features # 提取fc層固定的引數
# 改變全連線層,2分類問題,out_features = 2
model.fc = nn.Linear(num_fc_in, num_classes) # 修改fc層引數為num_classes = 4(最前面前面定義了)
# alexnet--------------------------------------------------------alexnet模型
model = models.alexnet(pretrained=True) # alexnet是一個預訓練模型, pretrained=True執行後會把模型下載到我們的電腦上
num_fc_in = model.classifier[6].in_features # 提取fc層固定的引數
model.fc = torch.nn.Linear(num_fc_in, num_classes) # 修改fc層引數為num_classes = 4(最前面前面定義了)
model.classifier[6] = model.fc
#將圖層初始化為model.fc
#相當於model.classifier[6] = torch.nn.Linear(num_fc_in, num_classes)
# 建立VGG16遷移學習模型------------------------------------------------vgg16模型
model = torchvision.models.vgg16(pretrained=True)# vgg16是一個預訓練模型, pretrained=True執行後會把模型下載到我們的電腦上
# 先將模型引數改為不可更新
for param in model.parameters():
param.requires_grad = False
# 再更改最後一層的輸出,至此網路只能更改該層引數
model.classifier[6] = nn.Linear(4096, num_classes)
model.classifier = torch.nn.Sequential( # 修改全連線層 自動梯度會恢復為預設值
torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, num_classes))
# resnet18---------------------------------------------------------------resnet模型(和前幾個模型差不多,自己腦部吧)
model = models.resnet18(pretrained=True)
# 全連線層的輸入通道in_channels個數
num_fc_in = model.fc.in_features
# 改變全連線層,2分類問題,out_features = 2
model.fc = nn.Linear(num_fc_in, num_classes)
```
#### 繼續,解釋都在註釋裡了
```
# 定義訓練函式
def train_model(model, dataloaders, criterion, optimizer, mundde_epochs=25):
since = time.time() # 返回當前時間的時間戳(1970紀元後經過的浮點秒數)
# state_dict變數存放訓練過程中需要學習的權重和偏執係數,state_dict作為python的字典物件將每一層的引數對映成tensor張量,
# 需要注意的是torch.nn.Module模組中的state_dict只包含卷積層和全連線層的引數
best_model_wts = copy.deepcopy(model.state_dict()) # copy是一個複製函式
best_acc = 0.0
# 下面這個迭代就是一個進度條的輸出,從0到9顯示進度
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 下面這個迭代,範圍就兩個'train', 'val',對應不執行不同的訓練模式
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in dataloaders[phase]:
# 下面這行程式碼的意思是將所有最開始讀取資料時的tensor變數copy一份到device所指定的GPU或CPU上去,
# 之後的運算都在GPU或CPU上進行
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 模型梯度設為0
# 接下來所有的tensor運算產生的新的節點都是不可求導的
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs) # output等於把inputs放到指定裝置上去運算
loss = criterion(outputs, labels) # loss為outputs和labels的交叉熵損失
# 舉例:output = torch.max(input, dim)
# 輸入
# input是softmax函式輸出的一個tensor
# dim是max函式索引的維度0 / 1,0是每列的最大值,1是每行的最大值
# 輸出
# 函式會返回兩個tensor,第一個tensor是每行的最大值,softmax的輸出中最大的是1,所以第一個tensor是全1的tensor;
# 第二個tensor是每行最大值的索引。
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward() # 反向傳播計算得到每個引數的梯度值
optimizer.step() # 通過梯度下降執行一步引數更新
running_loss += loss.item() * inputs.size(0)
running_corrects += (preds == labels).sum().item()
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects / len(dataloaders[phase].dataset)
print('{} loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
```
#### 繼續往下看
```
# 定義優化器和損失函式
model = model.to(device) # 前面解釋過了
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# optimizer = optim.Adam(model.classifier.parameters(), lr=0.0001)
# sched = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
criterion = nn.CrossEntropyLoss() # 交叉熵損失函式
```
引用[此文章](https://www.cnblogs.com/peixu/p/13194328.html)
==class torch.optim.SGD==(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)[source]
實現隨機梯度下降演算法(momentum可選)。
引數:
params (iterable) – 待優化引數的iterable或者是定義了引數組的dict
lr (float) – 學習率
momentum (float, 可選) – 動量因子(預設:0)
weight_decay (float, 可選) – 權重衰減(L2懲罰)(預設:0)
dampening (float, 可選) – 動量的抑制因子(預設:0)
nesterov (bool, 可選) – 使用Nesterov動量(預設:False)
例子:
```
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
```
==class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)==
adam演算法來源:[Adam: A Method for Stochastic Optimization](https://arxiv.org/pdf/1412.6980.pdf)
Adam(Adaptive Moment Estimation)本質上是帶有動量項的RMSprop,它利用梯度的一階矩估計和二階矩估計動態調整每個引數的學習率。它的優點主要在於經過偏置校正後,每一次迭代學習率都有個確定範圍,使得引數比較平穩。
其公式如下:
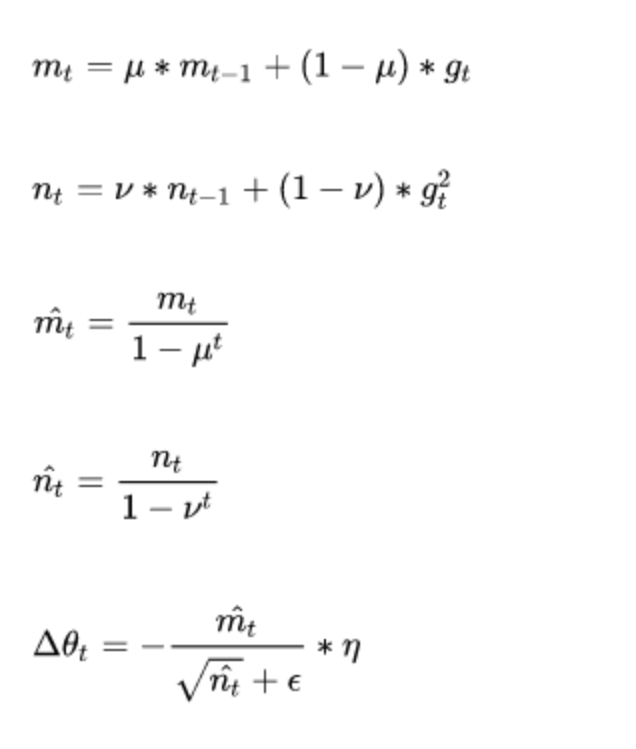
引數:
```
params(iterable):可用於迭代優化的引數或者定義引數組的dicts。
lr (float, optional) :學習率(預設: 1e-3)
betas (Tuple[float, float], optional):用於計算梯度的平均和平方的係數(預設: (0.9, 0.999))
eps (float, optional):為了提高數值穩定性而新增到分母的一個項(預設: 1e-8)
weight_decay (float, optional):權重衰減(如L2懲罰)(預設: 0)
step(closure=None)函式:執行單一的優化步驟
closure (callable, optional):用於重新評估模型並返回損失的一個閉