
Redis 核心篇:唯快不破的祕密
阿新 • • 發佈:2021-01-26
> 天下武功,無堅不摧,唯快不破!
**學習一個技術,通常只接觸了零散的技術點,沒有在腦海裡建立一個完整的知識框架和架構體系,沒有系統觀。這樣會很吃力,而且會出現一看好像自己會,過後就忘記,一臉懵逼。**
跟著「碼哥位元組」一起吃透 Redis,深層次的掌握 Redis 核心原理以及實戰技巧。一起搭建一套完整的知識框架,學會全域性觀去整理整個知識體系。
系統觀其實是至關重要的,從某種程度上說,在解決問題時,擁有了系統觀,就意味著你能有依據、有章法地定位和解決問題。
## Redis 全景圖
全景圖可以圍繞兩個緯度展開,分別是:
**應用緯度:快取使用、叢集運用、資料結構的巧妙使用**
**系統緯度:可以歸類為三高**
1. 高效能:執行緒模型、網路 IO 模型、資料結構、持久化機制;
2. 高可用:主從複製、哨兵叢集、Cluster 分片叢集;
3. 高拓展:負載均衡
**Redis 系列篇章**圍繞如下思維導圖展開,這次從 **《Redis 唯快不破的祕密》一起探索 Redis 的核心知識點。**
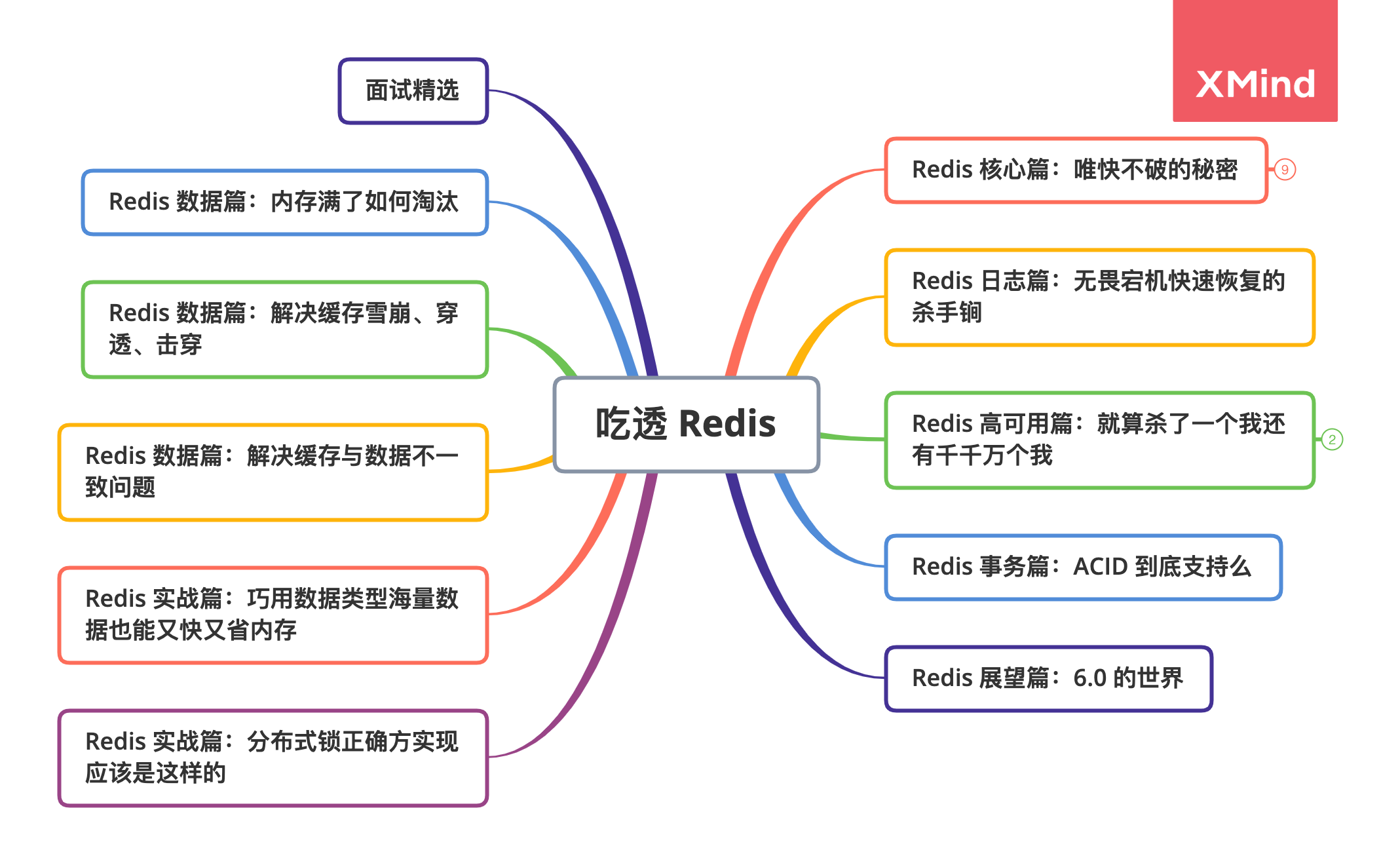
## 唯快不破的祕密
65 哥前段時間去面試 996 大廠,被問到「Redis 為什麼快?」
> 65 哥:額,因為它是基於記憶體實現和單執行緒模型
面試官:還有呢?
> 65 哥:沒了呀。
很多人僅僅只是知道基於記憶體實現,其他核心的原因模凌兩可。今日跟著「碼哥位元組」一起探索真正快的原因,做一個唯快不破的真男人!
Redis 為了高效能,從各方各面都進行了優化,下次小夥伴們面試的時候,面試官問 Redis 效能為什麼如此高,可不能傻傻的只說單執行緒和記憶體儲存了。
根據官方資料,Redis 的 QPS 可以達到約 100000(每秒請求數),有興趣的可以參考官方的基準程式測試《How fast is Redis?》,地址:https://redis.io/topics/benchmarks
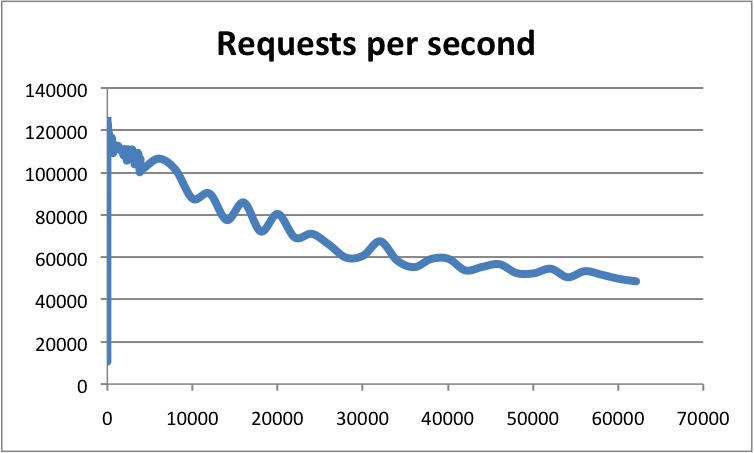
橫軸是連線數,縱軸是 QPS。此時,這張圖反映了一個數量級,希望大家在面試的時候可以正確的描述出來,不要問你的時候,你回答的數量級相差甚遠!
## 完全基於記憶體實現
> 65 哥:這個我知道,Redis 是基於記憶體的資料庫,跟磁碟資料庫相比,完全吊打磁碟的速度,就像段譽的凌波微步。對於磁碟資料庫來說,首先要將資料通過 IO 操作讀取到記憶體裡。
沒錯,不論讀寫操作都是在記憶體上完成的,我們分別對比下記憶體操作與磁碟操作的差異。
**磁碟呼叫棧圖**
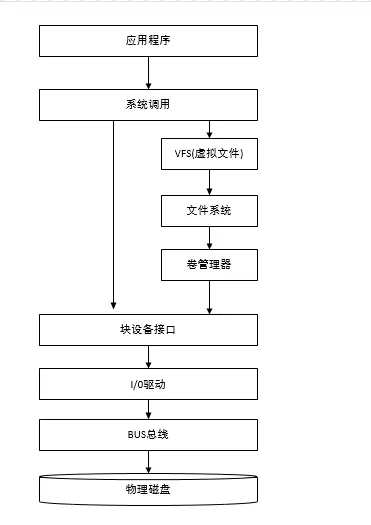
**記憶體操作**
記憶體直接由 CPU 控制,也就是 CPU 內部整合的記憶體控制器,所以說記憶體是直接與 CPU 對接,享受與 CPU 通訊的最優頻寬。
**Redis 將資料儲存在記憶體中,讀寫操作不會因為磁碟的 IO 速度限制,所以速度飛一般的感覺!**
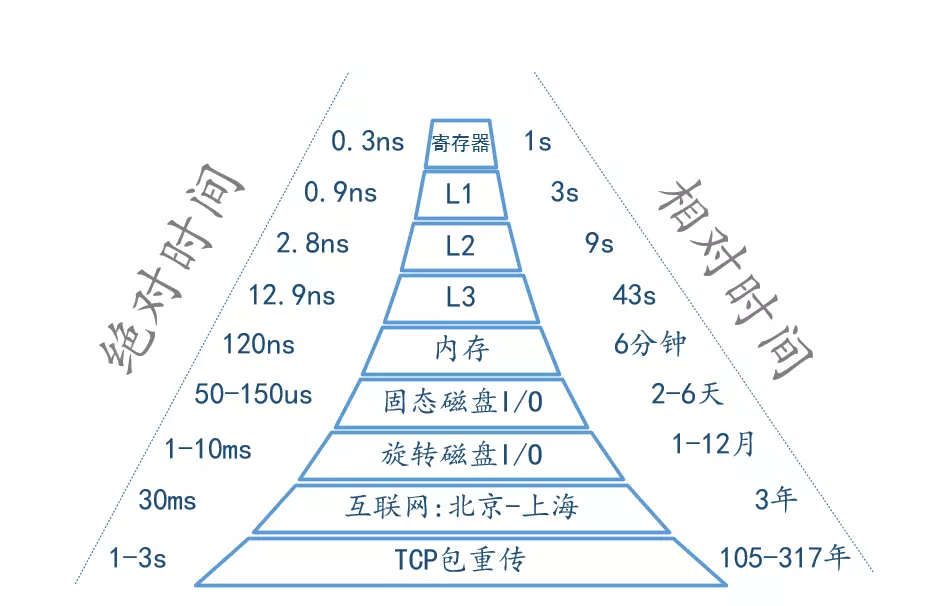
最後以一張圖量化系統的各種延時時間(部分資料引用 Brendan Gregg)
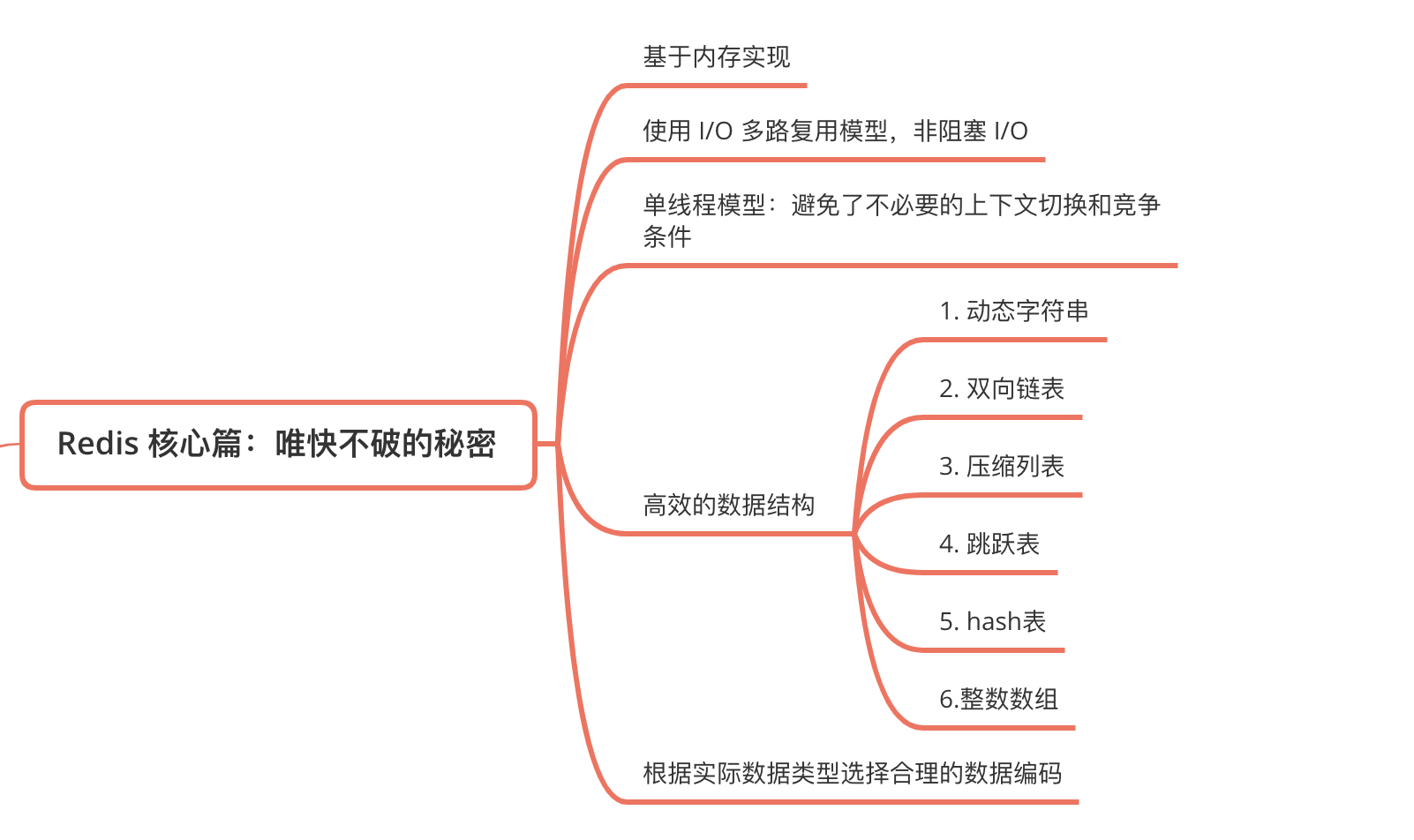
## 高效的資料結構
> 65 哥:學習 MySQL 的時候我知道為了提高檢索速度使用了 B+ Tree 資料結構,所以 Redis 速度快應該也跟資料結構有關。
回答正確,這裡所說的資料結構並不是 Redis 提供給我們使用的 5 種資料型別:String、List、Hash、Set、SortedSet。
在 Redis 中,常用的 5 種資料型別和應用場景如下:
- **String:** 快取、計數器、分散式鎖等。
- **List:** 連結串列、佇列、微博關注人時間軸列表等。
- **Hash:** 使用者資訊、Hash 表等。
- **Set:** 去重、贊、踩、共同好友等。
- **Zset:** 訪問量排行榜、點選量排行榜等。
上面的應該叫做 Redis 支援的資料型別,也就是資料的儲存形式。「碼哥位元組」要說的是針對這 5 種資料型別,底層都運用了哪些高效的資料結構來支援。
> 65 哥:為啥搞這麼多資料結構呢?
當然是為了追求速度,不同資料型別使用不同的資料結構速度才得以提升。每種資料型別都有一種或者多種資料結構來支撐,底層資料結構有 6 種。

### Redis hash 字典
Redis 整體就是一個 雜湊表來儲存所有的鍵值對,無論資料型別是 5 種的任意一種。雜湊表,本質就是一個數組,每個元素被叫做雜湊桶,不管什麼資料型別,每個桶裡面的 entry 儲存著實際具體值的指標。

整個資料庫就是一個**全域性雜湊表**,而雜湊表的時間複雜度是 O(1),只需要計算每個鍵的雜湊值,便知道對應的雜湊桶位置,定位桶裡面的 entry 找到對應資料,這個也是 Redis 快的原因之一。
**那 Hash 衝突怎麼辦?**
當寫入 Redis 的資料越來越多的時候,雜湊衝突不可避免,會出現不同的 key 計算出一樣的雜湊值。
Redis 通過**鏈式雜湊**解決衝突:**也就是同一個 桶裡面的元素使用連結串列儲存**。但是當連結串列過長就會導致查詢效能變差可能,所以 Redis 為了追求快,使用了兩個全域性雜湊表。用於 rehash 操作,增加現有的雜湊桶數量,減少雜湊衝突。
開始預設使用 hash 表 1 儲存鍵值對資料,雜湊表 2 此刻沒有分配空間。當資料越來多觸發 rehash 操作,則執行以下操作:
1. 給 hash 表 2 分配更大的空間;
2. 將 hash 表 1 的資料重新對映拷貝到 hash 表 2 中;
3. 釋放 hash 表 1 的空間。
**值得注意的是,將 hash 表 1 的資料重新對映到 hash 表 2 的過程中並不是一次性的,這樣會造成 Redis 阻塞,無法提供服務。**
而是採用了**漸進式 rehash**,每次處理客戶端請求的時候,先從 hash 表 1 中第一個索引開始,將這個位置的 所有資料拷貝到 hash 表 2 中,就這樣將 rehash 分散到多次請求過程中,避免耗時阻塞。
### SDS 簡單動態字元
> 65 哥:Redis 是用 C 語言實現的,為啥還重新搞一個 SDS 動態字串呢?
字串結構使用最廣泛,通常我們用於快取登陸後的使用者資訊,key = userId,value = 使用者資訊 JSON 序列化成字串。
C 語言中字串的獲取 「MageByte」的長度,要從頭開始遍歷,直到 「\0」為止,Redis 作為唯快不破的男人是不能忍受的。
C 語言字串結構與 SDS 字串結構對比圖如下所示:

#### SDS 與 C 字串區別
**O(1) 時間複雜度獲取字串長度**
C 語言字串布吉路長度資訊,需要遍歷整個字串時間複雜度為 O(n),C 字串遍歷時遇到 '\0' 時結束。
SDS 中 len 儲存這字串的長度,O(1) 時間複雜度。
**空間預分配**
SDS 被修改後,程式不僅會為 SDS 分配所需要的必須空間,還會分配額外的未使用空間。
分配規則如下:如果對 SDS 修改後,len 的長度小於 1M,那麼程式將分配和 len 相同長度的未使用空間。舉個例子,如果 len=10,重新分配後,buf 的實際長度會變為 10(已使用空間)+10(額外空間)+1(空字元)=21。如果對 SDS 修改後 len 長度大於 1M,那麼程式將分配 1M 的未使用空間。
**惰性空間釋放**
當對 SDS 進行縮短操作時,程式並不會回收多餘的記憶體空間,而是使用 free 欄位將這些位元組數量記錄下來不釋放,後面如果需要 append 操作,則直接使用 free 中未使用的空間,減少了記憶體的分配。
**二進位制安全**
在 Redis 中不僅可以儲存 String 型別的資料,也可能儲存一些二進位制資料。
二進位制資料並不是規則的字串格式,其中會包含一些特殊的字元如 '\0',在 C 中遇到 '\0' 則表示字串的結束,但在 SDS 中,標誌字串結束的是 len 屬性。
### zipList 壓縮列表
壓縮列表是 List 、hash、 sorted Set 三種資料型別底層實現之一。
當一個列表只有少量資料的時候,並且每個列表項要麼就是小整數值,要麼就是長度比較短的字串,那麼 Redis 就會使用壓縮列表來做列表鍵的底層實現。
ziplist 是由一系列特殊編碼的連續記憶體塊組成的順序型的資料結構,ziplist 中可以包含多個 entry 節點,每個節點可以存放整數或者字串。
ziplist 在表頭有三個欄位 zlbytes、zltail 和 zllen,分別表示列表佔用位元組數、列表尾的偏移量和列表中的 entry 個數;壓縮列表在表尾還有一個 zlend,表示列表結束。
```c
struct