
C指標的這些使用技巧,掌握後立刻提升一個Level
阿新 • • 發佈:2021-01-29
[TOC] ## 一、前言 半個月前寫的那篇關於指標最底層原理的文章,得到了很多朋友的認可(連結: [C語言指標-從底層原理到花式技巧,用圖文和程式碼幫你講解透徹](https://mp.weixin.qq.com/s/TwDiDmApmsIVSIFh2h1osQ)),特別是對剛學習C語言的小夥伴來說,很容易就從根本上理解指標到底是什麼、怎麼用,這也讓我堅信一句話;用心寫出的文章,一定會被讀者感受到!在寫這篇文章的時候,我列了一個提綱,寫到後面的時候,發現已經超過一萬字了,但是提綱上還有最後一個主題沒有寫。如果繼續寫下去,文章體積就太大了,於是就留下了一個尾巴。 今天,我就把這個尾巴給補上去:主要是介紹指標在應用程式的程式設計中,經常使用的技巧。如果之前的那篇文章勉強算是“道”層面的話,那這篇文章就屬於“術”的層面。主要通過 8 個示例程式來展示在 C 語言應用程式中,關於指標使用的常見套路,希望能給你帶來收穫。 記得我在校園裡學習C語言的時候,南師大的黃鳳良老師花了大半節課的時間給我們解釋指標,現在最清楚地記得老師說過的一句話就是:指標就是地址,地址就是指標! ## 二、八個示例 #### 1. 開胃菜:修改主調函式中的資料 ``` // 交換 2 個 int 型資料 void demo1_swap_data(int *a, int *b) { int tmp = *a; *a = *b; *b = tmp; } void demo1() { int i = 1; int j = 2; printf("before: i = %d, j = %d \n", i, j); demo1_swap_data(&i, &j); printf("after: i = %d, j = %d \n", i, j); } ``` 這個程式碼不用解釋了,大家一看就明白。如果再過多解釋的話,好像在侮辱智商。 #### 2. 在被呼叫函式中,分配系統資源 程式碼的目的是:在被呼叫函式中,從堆區分配 `size` 個位元組的空間,返回給主調函式中的 `pData` 指標。 ``` void demo2_malloc_heap_error(char *buf, int size) { buf = (char *)malloc(size); printf("buf = 0x%x \n", buf); } void demo2_malloc_heap_ok(char **buf, int size) { *buf = (char *)malloc(size); printf("*buf = 0x%x \n", *buf); } void demo2() { int size = 1024; char *pData = NULL; // 錯誤用法 demo2_malloc_heap_error(pData, size); printf("&pData = 0x%x, pData = 0x%x \n", &pData, pData); // 正確用法 demo2_malloc_heap_ok(&pData, size); printf("&pData = 0x%x, pData = 0x%x \n", &pData, pData); free(pData); } ``` ###### 2.1 錯誤用法 剛進入被呼叫函式 `demo2_malloc_heap_error` 的時候,形參 `buff` 是一個 char\* 型指標,它的值等於 `pData` 變數的值,也就是說 `buff` 與 `pData` 的值相同(都為 NULL),記憶體模型如圖:  在被呼叫函式中執行 `malloc` 語句之後,從堆區申請得到的地址空間賦值給 `buf`,就是說它就指向了這個新的地址空間,而 `pData` 裡仍然是`NULL`,記憶體模型如下:  從圖中可以看到,`pData` 的記憶體中一直是 `NULL`,沒有指向任何堆空間。另外,由於形參 `buf` 是放在函式的棧區的,從被調函式中返回的時候,堆區這塊申請的空間就被洩漏了。 ###### 2.2 正確用法 剛進入被呼叫函式 `demo2_malloc_heap_error` 的時候,形參 `buf` 是一個 char\* 型的二級指標,就是說 `buf` 裡的值是另一個指標變數的地址,在這個示例中 `buf` 裡的值就是 `pData` 這個指標變數的地址,記憶體模型如下: 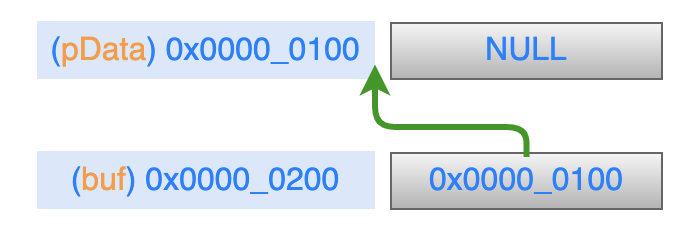 在被呼叫函式中執行 `malloc` 語句之後,從堆區申請得到的地址空間賦值給 \*buf,因為 `buf = &pData`,所以 \*buf 就相當於是 `pData`,那麼從堆區申請得到的地址空間就賦值 `pData` 變數,記憶體模型如下:  從被調函式中返回之後,`pData` 就正確的得到了一塊堆空間,別忘了使用之後要主動釋放。 #### 3. 傳遞函式指標 從上篇文章中我們知道,函式名本身就代表一個地址,在這個地址中儲存著函式體中定義的一連串指令碼,只要給這個地址後面加上一個呼叫符(小括號),就進入這個函式中執行。在實際程式中,函式名常常作為函式引數來進行傳遞。 熟悉C\+\+的小夥伴都知道,在標準庫中對容器型別的資料進行各種演算法操作時,可以傳入使用者自己的提供的演算法函式(如果不傳入函式,標準庫就使用預設的)。 下面是一個示例程式碼,對一個 int 行的陣列進行排序,排序函式 `demo3_handle_data` 的最後一個引數是一個函式指標,因此需要傳入一個具體的排序演算法函式。示例中有 2 個候選函式可以使用: > 1. 降序排列: demo3_algorithm_decend; > 2. 升序排列: demo3_algorithm_ascend; ``` typedef int BOOL; #define FALSE 0 #define TRUE 1 BOOL demo3_algorithm_decend(int a, int b) { return a > b; } BOOL demo3_algorithm_ascend(int a, int b) { return a < b; } typedef BOOL (*Func)(int, int); void demo3_handle_data(int *data, int size, Func pf) { for (int i = 0; i < size - 1; ++i) { for (int j = 0; j < size - 1 - i; ++j) { // 呼叫傳入的排序函式 if (pf(data[j], data[j+1])) { int tmp = data[j]; data[j] = data[j + 1]; data[j + 1] = tmp; } } } } void demo3() { int a[5] = {5, 1, 9, 2, 6}; int size = sizeof(a)/sizeof(int); // 呼叫排序函式,需要傳遞排序演算法函式 //demo3_handle_data(a, size, demo3_algorithm_decend); // 降序排列 demo3_handle_data(a, size, demo3_algorithm_ascend); // 升序排列 for (int i = 0; i < size; ++i) printf("%d ", a[i]); printf("\n"); } ``` 這個就不用畫圖了,函式指標 `pf` 就指向了傳入的那個函式地址,在排序的時候直接呼叫就可以了。 #### 4. 指向結構體的指標 在嵌入式開發中,指向結構體的指標使用特別廣泛,這裡以智慧家居中的一條控制指令來舉例。在一個智慧家居系統中,存在各種各樣的裝置(插座、電燈、電動窗簾等),每個裝置的控制指令都是不一樣的,因此可以在每個裝置的控制指令結構體中的最前面,放置所有指令都需要的、通用的成員變數,這些變數可以稱為指令頭(指令頭中包含一個代表命令型別的列舉變數)。 當處理一條控制指令時,先用一個通用命令(指令頭)的指標來接收指令,然後根據命令型別列舉變數來區分,把控制指令強制轉換成具體的那個裝置的資料結構,這樣就可以獲取到控制指令中特定的控制資料了。 本質上,與 Java/C++ 中的介面、基類的概念類似。 ``` // 指令型別列舉 typedef enum _CMD_TYPE_ { CMD_TYPE_CONTROL_SWITCH = 1, CMD_TYPE_CONTROL_LAMP, } CMD_TYPE; // 通用的指令資料結構(指令頭) typedef struct _CmdBase_ { CMD_TYPE cmdType; // 指令型別 int deviceId; // 裝置 Id } CmdBase; typedef struct _CmdControlSwitch_ { // 前 2 個引數是指令頭 CMD_TYPE cmdType; int deviceId; // 下面都有這個指令私有的資料 int slot; // 排插上的哪個插口 int state; // 0:斷開, 1:接通 } CmdControlSwitch; typedef struct _CmdControlLamp_ { // 前 2 個引數是指令頭 CMD_TYPE cmdType; int deviceId; // 下面都有這個指令私有的資料 int color; // 顏色 int brightness; // 亮度 } CmdControlLamp; // 引數是指令頭指標 void demo4_control_device(CmdBase *pcmd) { // 根據指令頭中的命令型別,把指令強制轉換成具體裝置的指令 if (CMD_TYPE_CONTROL_SWITCH == pcmd->cmdType) { // 型別強制轉換 CmdControlSwitch *cmd = pcmd; printf("control switch. slot = %d, state = %d \n", cmd->slot, cmd->state); } else if (CMD_TYPE_CONTROL_LAMP == pcmd->cmdType) { // 型別強制轉換 CmdControlLamp * cmd = pcmd; printf("control lamp. color = 0x%x, brightness = %d \n", cmd->color, cmd->brightness); } } void demo4() { // 指令1:控制一個開關 CmdControlSwitch cmd1 = {CMD_TYPE_CONTROL_SWITCH, 1, 3, 0}; demo4_control_device(&cmd1); // 指令2:控制一個燈泡 CmdControlLamp cmd2 = {CMD_TYPE_CONTROL_LAMP, 2, 0x112233, 90}; demo4_control_device(&cmd2); } ``` #### 5. 函式指標陣列 這個示例在上篇文章中演示過,為了完整性,這裡再貼一下。 ``` int add(int a, int b) { return a + b; } int sub(int a, int b) { return a - b; } int mul(int a, int b) { return a * b; } int divide(int a, int b) { return a / b; } void demo5() { int a = 4, b = 2; int (*p[4])(int, int); p[0] = add; p[1] = sub; p[2] = mul; p[3] = divide; printf("%d + %d = %d \n", a, b, p[0](a, b)); printf("%d - %d = %d \n", a, b, p[1](a, b)); printf("%d * %d = %d \n", a, b, p[2](a, b)); printf("%d / %d = %d \n", a, b, p[3](a, b)); } ``` #### 6. 在結構體中使用柔性陣列 先不解釋概念,我們先來看一個程式碼示例: ``` // 一個結構體,成員變數 data 是指標 typedef struct _ArraryMemberStruct_NotGood_ { int num; char *data; } ArraryMemberStruct_NotGood; void demo6_not_good() { // 列印結構體的記憶體大小 int size = sizeof(ArraryMemberStruct_NotGood); printf("size = %d \n", size); // 分配一個結構體指標 ArraryMemberStruct_NotGood *ams = (ArraryMemberStruct_NotGood *)malloc(size); ams->num = 1; // 為結構體中的 data 指標分配空間 ams->data = (char *)malloc(1024); strcpy(ams->data, "hello"); printf("ams->data = %s \n", ams->data); // 列印結構體指標、成員變數的地址 printf("ams = 0x%x \n", ams); printf("ams->num = 0x%x \n", &ams->num); printf("ams->data = 0x%x \n", ams->data); // 釋放空間 free(ams->data); free(ams); } ``` 在我的電腦上,列印結果如下: 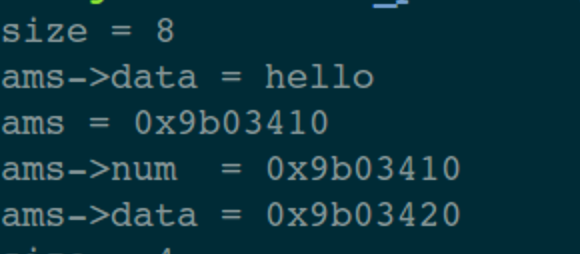 可以看到:該結構體一共有 8 個位元組(int 型佔 4 個位元組,指標型佔 4 個位元組)。 結構體中的 `data` 成員是一個指標變數,需要單獨為它申請一塊空間才可以使用。而且在結構體使用之後,需要先釋放 `data`,然後釋放結構體指標 `ams`,順序不能錯。 這樣使用起來,是不是有點麻煩? 於是,C99 標準就定義了一個語法:flexible array member(柔性陣列),直接上程式碼(下面的程式碼如果編譯時遇到警告,請檢查下編譯器對這個語法的支援): ``` // 一個結構體,成員變數是未指明大小的陣列 typedef struct _ArraryMemberStruct_Good_ { int num; char data[]; } ArraryMemberStruct_Good; void demo6_good() { // 列印結構體的大小 int size = sizeof(ArraryMemberStruct_Good); printf("size = %d \n", size); // 為結構體指標分配空間 ArraryMemberStruct_Good *ams = (ArraryMemberStruct_Good *)malloc(size + 1024); strcpy(ams->data, "hello"); printf("ams->data = %s \n", ams->data); // 列印結構體指標、成員變數的地址 printf("ams = 0x%x \n", ams); printf("ams->num = 0x%x \n", &ams->num); printf("ams->data = 0x%x \n", ams->data); // 釋放空間 free(ams); } ``` 列印結果如下: 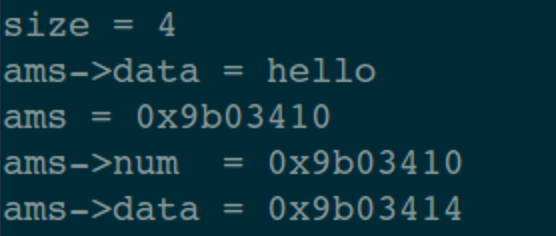 與第一個例子中有下面幾個不同點: > 1. 結構體的大小變成了 4; > 2. 為結構體指標分配空間時,除了結構體本身的大小外,還申請了 data 需要的空間大小; > 3. 不需要為 data 單獨分配空間了; > 4. 釋放空間時,直接釋放結構體指標即可; 是不是用起來簡單多了?!這就是柔性陣列的好處。 從語法上來說,柔性陣列就是指結構體中最後一個元素個數未知的陣列,也可以理解為長度為 0,那麼就可以讓這個結構體稱為可變長的。 前面說過,陣列名就代表一個地址,是一個不變的地址常量。在結構體中,陣列名僅僅是一個符號而已,只代表一個偏移量,不會佔用具體的空間。 另外,柔性陣列可以是任意型別。這裡示例大家多多體會,在很多通訊類的處理場景中,常常見到這種用法。 #### 7. 通過指標來獲取結構體中成員變數的偏移量 這個標題讀起來似乎有點拗口,拆分一下:在一個結構體變數中,可以利用指標操作的技巧,獲取某個成員變數的地址、距離結構體變數的開始地址、之間的偏移量。 在 Linux 核心程式碼中你可以看到很多地方都利用了這個技巧,程式碼如下: ``` #define offsetof(TYPE, MEMBER) ((size_t) &(((TYPE*)0)->MEMBER)) typedef struct _OffsetStruct_ { int a; int b; int c; } OffsetStruct; void demo7() { OffsetStruct os; // 列印結構體變數、成員變數的地址 printf("&os = 0x%x \n", &os); printf("&os->a = 0x%x \n", &os.a); printf("&os->b = 0x%x \n", &os.b); printf("&os->c = 0x%x \n", &os.c); printf("===== \n"); // 列印成員變數地址,與結構體變數開始地址,之間的偏移量 printf("offset: a = %d \n", (char *)&os.a - (char *)&os); printf("offset: b = %d \n", (char *)&os.b - (char *)&os); printf("offset: c = %d \n", (char *)&os.c - (char *)&os); printf("===== \n"); // 通過指標的強制型別轉換來獲取偏移量 printf("offset: a = %d \n", (size_t) &((OffsetStruct*)0)->a); printf("offset: b = %d \n", (size_t) &((OffsetStruct*)0)->b); printf("offset: c = %d \n", (size_t) &((OffsetStruct*)0)->c); printf("===== \n"); // 利用巨集定義來得到成員變數的偏移量 printf("offset: a = %d \n", offsetof(OffsetStruct, a)); printf("offset: b = %d \n", offsetof(OffsetStruct, b)); printf("offset: c = %d \n", offsetof(OffsetStruct, c)); } ``` 先來看列印結果: 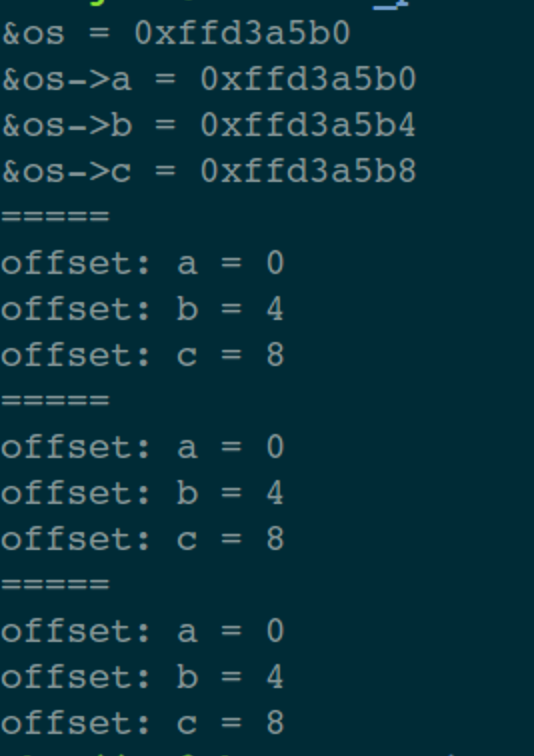 前面 4 行的列印資訊不需要解釋了,直接看下面這個記憶體模型即可理解。 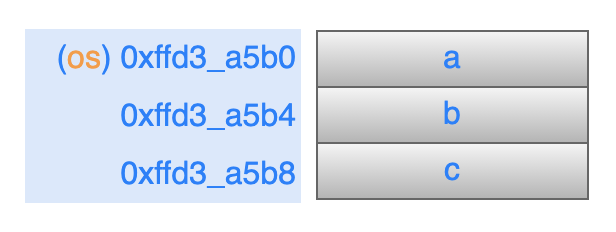 下面這個語句也不需要多解釋,就是把兩個地址的值進行相減,得到距離結構體變數開始地址的偏移量,注意:需要把地址強轉成 char\* 型之後,才可以相減。 ``` printf("offset: a = %d \n", (char *)&os.a - (char *)&os); ``` 下面這條語句需要好好理解: ``` printf("offset: a = %d \n", (size_t) &((OffsetStruct*)0)->a); ``` 數字 0 看成是一個地址,也就是一個指標。上篇文章解釋過,指標就代表記憶體中的一塊空間,至於你把這塊空間裡的資料看作是什麼,這個隨便你,你只要告訴編譯器,編譯器就按照你的意思去操作這些資料。 現在我們把 0 這個地址裡的資料看成是一個 OffsetStruct 結構體變數(通過強制轉換來告訴編譯器),這樣就得到了一個 OffsetStruct 結構體指標(下圖中綠色橫線),然後得到該指標變數中的成員變數 a(藍色橫線),再然後通過取地址符 & 得到 a 的地址(橙色橫線),最後把這個地址強轉成 size_t 型別(紅色橫線)。 因為這個結構體指標變數是從 0 地址開始的,因此,成員變數 a 的地址就是 a 距離結構體變數開始地址的偏移量。 上面的描述過程,如果感覺拗口,請結合下面這張圖再讀幾遍: 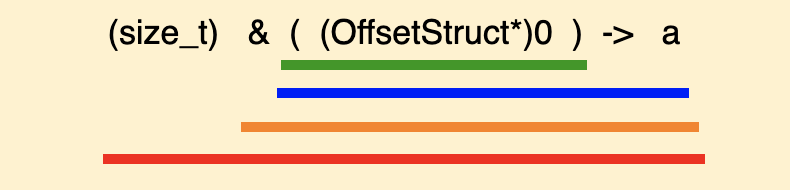 上面這張圖如果能看懂的話,那麼最後一種通過巨集定義獲取偏移量的列印語句也就明白了,無非就是把程式碼抽象成巨集定義了,方便呼叫: ``` #define offsetof(TYPE, MEMBER) ((size_t) &(((TYPE*)0)->MEMBER)) printf("offset: a = %d \n", offsetof(OffsetStruct, a)); ``` 可能有小夥伴提出:獲取這個偏移量有什麼用啊?那就請接著看下面的示例 8。 #### 8. 通過結構體中成員變數的指標,來獲取該結構體的指標 標題同樣比較拗口,直接結合程式碼來看: ``` typedef struct _OffsetStruct_ { int a; int b; int c; } OffsetStruct; ``` 假設有一個 OffsetStruct 結構體變數 os,我們只知道 os 中成員變數 c 的地址(指標),那麼我們想得到變數 os 的地址(指標),應該怎麼做?這就是標題所描述的目的。 下面程式碼中的巨集定義 `container_of` 同樣是來自於 Linux 核心中的(大家平常沒事時多挖掘,可以發現很多好東西)。 ``` #define container_of(ptr, type, member) ({ \ const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );}) void demo8() { // 下面 3 行僅僅是演示 typeof 關鍵字的用法 int n = 1; typeof(n) m = 2; // 定義相同型別的變數m printf("n = %d, m = %d \n", n, m); // 定義結構體變數,並初始化 OffsetStruct os = {1, 2, 3}; // 列印結構體變數的地址、成員變數的值(方便後面驗證) printf("&os = 0x%x \n", &os); printf("os.a = %d, os.b = %d, os.c = %d \n", os.a, os.b, os.c); printf("===== \n"); // 假設只知道某個成員變數的地址 int *pc = &os.c; OffsetStruct *p = NULL; // 根據成員變數的地址,得到結構體變數的地址 p = container_of(pc, OffsetStruct, c); // 列印指標的地址、成員變數的值 printf("p = 0x%x \n", p); printf("p->a = %d, p->b = %d, p->c = %d \n", p->a, p->b, p->c); } ``` 先看列印結果: 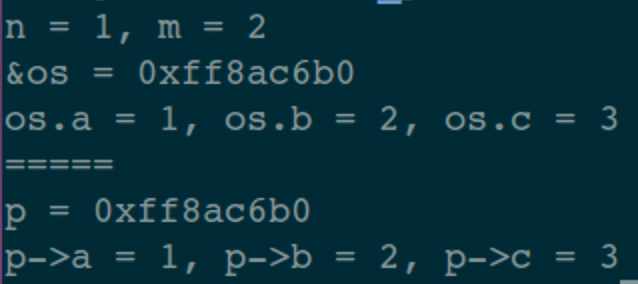 首先要清楚巨集定義中引數的型別: > 1. ptr: 成員變數的指標; > 2. type: 結構體型別; > 3. member:成員變數的名稱; 這裡的重點就是理解巨集定義 `container_of`,結合下面這張圖,把巨集定義拆開來進行描述:  巨集定義中的第 1 條語句分析: > 1. 綠色橫線:把數字 0 看成是一個指標,強轉成結構體 type 型別; > 2. 藍色橫線:獲取該結構體指標中的成員變數 member; > 3. 橙色橫線:利用 typeof 關鍵字,獲取該 member 的型別,然後定義這個型別的一個指標變數 __mptr; > 4. 紅色橫線:把巨集引數 ptr 賦值給 __mptr 變數; 巨集定義中的第 2 條語句分析: > 5. 綠色橫線:利用 demo7 中的 offset 巨集定義,得到成員變數 member 距離結構體變數開始地址的偏移量,而這個成員變數指標剛才已經知道了,就是 __mptr; > 6. 藍色橫線:把 __mptr 這個地址,減去它自己距離結構體變數開始地址的偏移量,就得到了該結構體變數的開始地址; > 7. 橙色橫線:最後把這個指標(此時是 char\* 型),強轉成結構體 type 型別的指標; ## 三、總結 上面這 8 個關於指標的用法掌握之後,再去處理子字元、陣列、連結串列等資料,基本上就是熟練度和工作量的問題了。 希望大家都能用好指標這個神器,提高程式程式執行效率。 面對程式碼,永無bug;面對生活,春暖花開!祝您好運! 原創不易,如果這篇文章有幫助,請轉發、分享給您的朋友,道哥在此表示感謝! ---
> 作者:道哥(公眾號: IOT物聯網小鎮) > 知乎:道哥 > B站:道哥分享 > 掘金:道哥分享 > CSDN:道哥分享
我會把十多年嵌入式開發中的專案實戰經驗進行輸出總結!
如果覺得文章不錯,請轉發、分享給您的朋友,您的支援是我持續寫作的最大動力!
轉載:歡迎轉載,但未經作者同意,必須保留此段宣告,必須在文章中給出原文連線。 ---
推薦閱讀 [1] [C語言指標-從底層原理到花式技巧,用圖文和程式碼幫你講解透徹](https://mp.weixin.qq.com/s/TwDiDmApmsIVSIFh2h1osQ) [2] [一步步分析-如何用C實現面向物件程式設計](https://mp.weixin.qq.com/s/xOdwQQHIjEobe4jR_2gDRQ) [3] [原來gdb的底層除錯原理這麼簡單](https://mp.weixin.qq.com/s/oY2pF5ilk8UCq09022Tt6w) [4] [生產者和消費者模式中的雙緩衝技術](https://mp.weixin.qq.com/s/ZAdiynT-OAE1HscPrj4Sew) [5] [關於加密、證書的那些事](https://mp.weixin.qq.com/s/boOSJ-dCaLYcCa_yY_2sIw) [6] [深入LUA指令碼語言,讓你徹底明白除錯原理](https://mp.weixin.qq.com/s/qJiEaVfivAbK89gv1itUhA) [7] [一個printf(結構體變數)引發的血案](https://mp.weixin.qq.com/s/Ap26EOp40TfFV4Ot