
高效能快取 Caffeine 原理及實戰
一、簡介
Caffeine 是基於Java 8 開發的、提供了近乎最佳命中率的高效能本地快取元件,Spring5 開始不再支援 Guava Cache,改為使用 Caffeine。
下面是 Caffeine 官方測試報告。
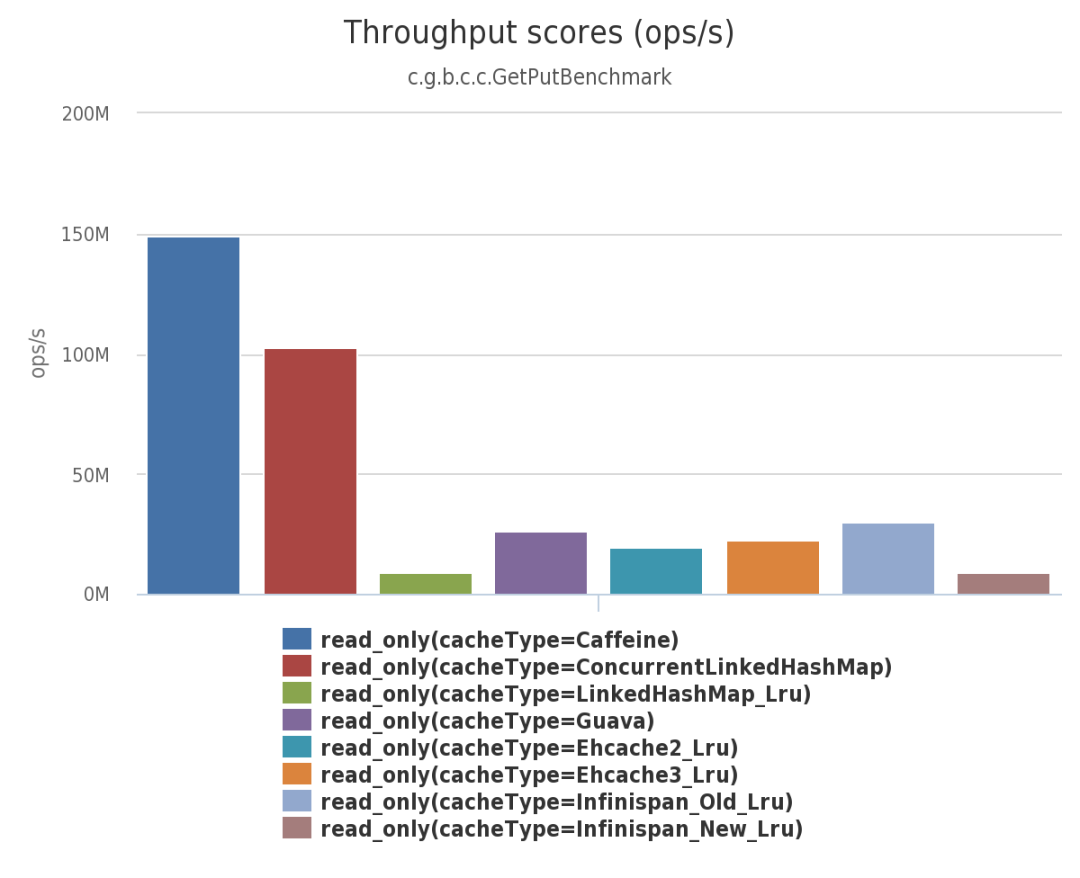
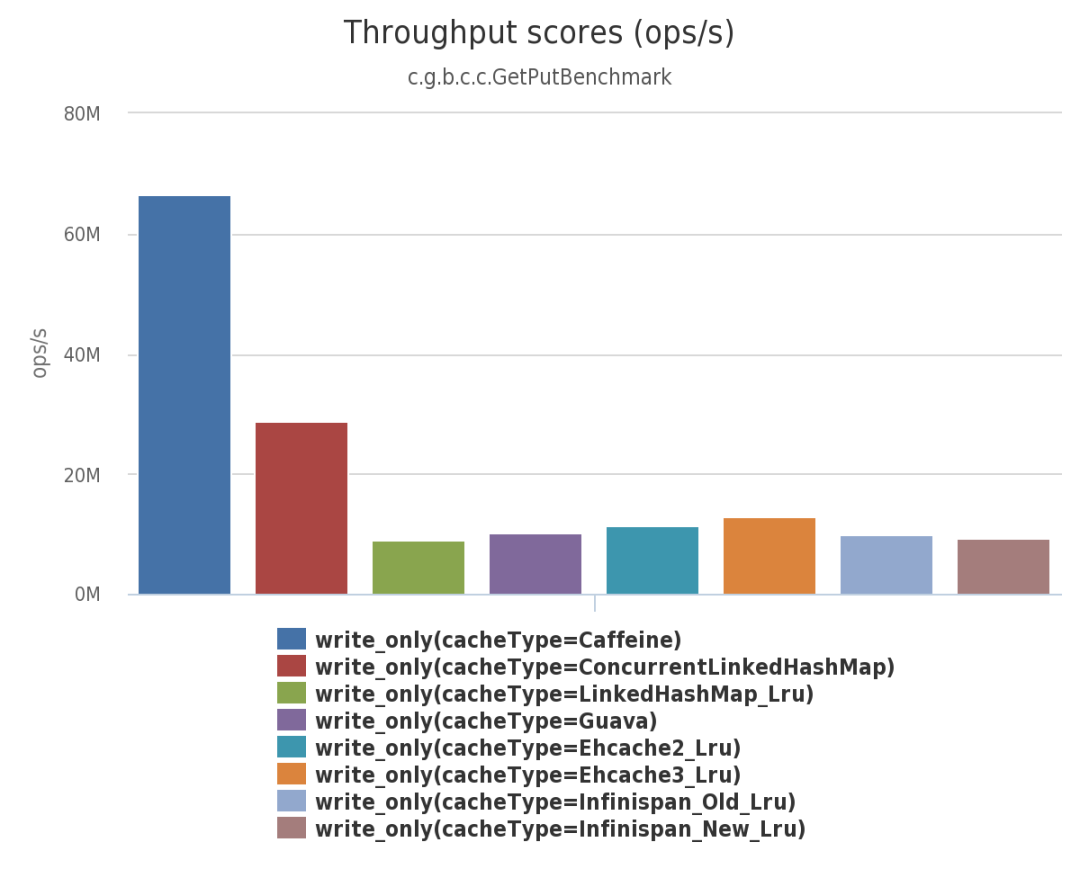
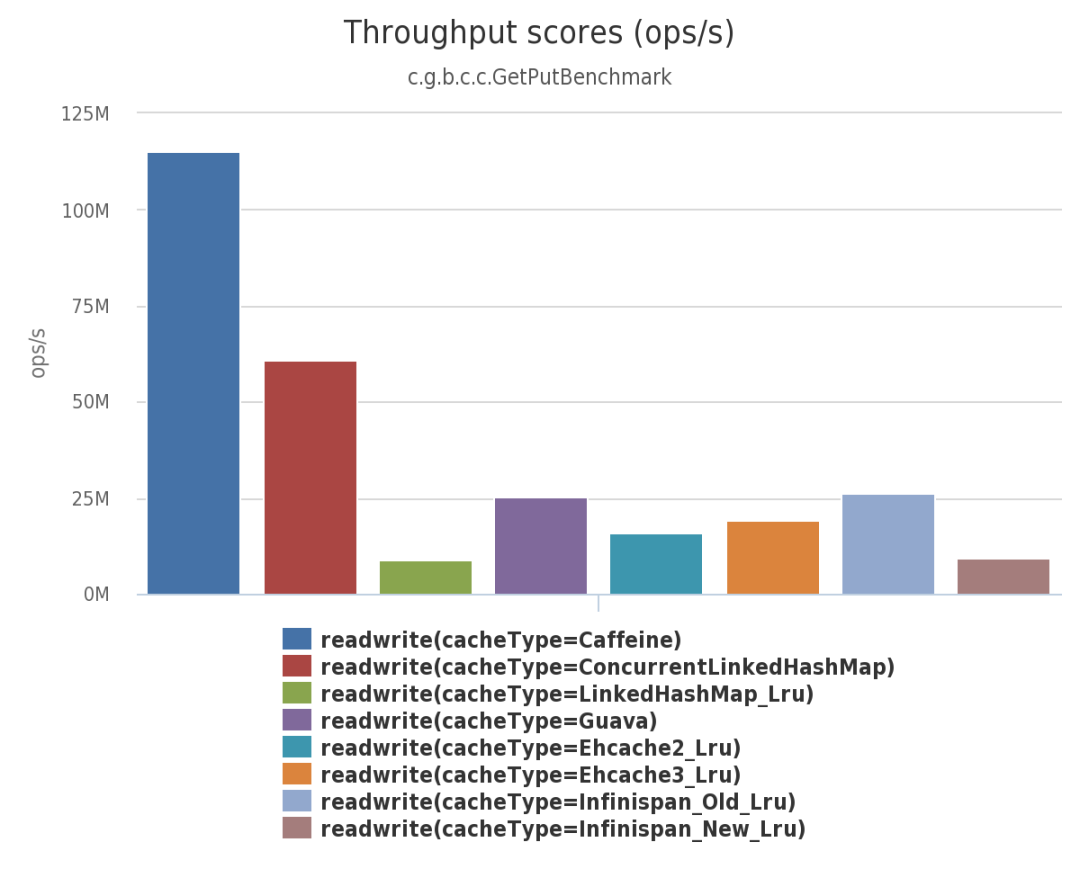
由上面三幅圖可見:不管在併發讀、併發寫還是併發讀寫的場景下,Caffeine 的效能都大幅領先於其他本地開源快取元件。
本文先介紹 Caffeine 實現原理,再講解如何在專案中使用 Caffeine 。
二、Caffeine 原理
2.1 淘汰演算法
2.1.1 常見演算法
對於 Java 程序內快取我們可以通過 HashMap 來實現。不過,Java 程序記憶體是有限的,不可能無限地往裡面放快取物件。這就需要有合適的演算法輔助我們淘汰掉使用價值相對不高的物件,為新進的物件留有空間。常見的快取淘汰演算法有 FIFO、LRU、LFU。
FIFO(First In First Out):先進先出。
它是優先淘汰掉最先快取的資料、是最簡單的淘汰演算法。缺點是如果先快取的資料使用頻率比較高的話,那麼該資料就不停地進進出出,因此它的快取命中率比較低。
LRU(Least Recently Used):最近最久未使用。
它是優先淘汰掉最久未訪問到的資料。缺點是不能很好地應對偶然的突發流量。比如一個數據在一分鐘內的前59秒訪問很多次,而在最後1秒沒有訪問,但是有一批冷門資料在最後一秒進入快取,那麼熱點資料就會被沖刷掉。
LFU(Least Frequently Used):
最近最少頻率使用。它是優先淘汰掉最不經常使用的資料,需要維護一個表示使用頻率的欄位。
主要有兩個缺點:
一、如果訪問頻率比較高的話,頻率欄位會佔據一定的空間;
二、無法合理更新新上的熱點資料,比如某個歌手的老歌播放歷史較多,新出的歌如果和老歌一起排序的話,就永無出頭之日。
2.1.2 W-TinyLFU 演算法
Caffeine 使用了 W-TinyLFU 演算法,解決了 LRU 和LFU上述的缺點。W-TinyLFU 演算法由論文《TinyLFU: A Highly Efficient Cache Admission Policy》提出。
它主要乾了兩件事:
一、採用 Count–Min Sketch 演算法降低頻率資訊帶來的記憶體消耗;
二、維護一個PK機制保障新上的熱點資料能夠快取。
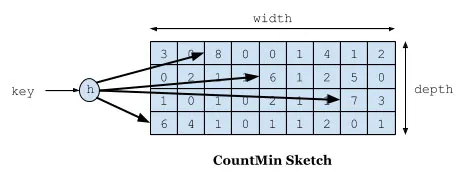
如下圖所示,Count–Min Sketch 演算法類似布隆過濾器 (Bloom filter)思想,對於頻率統計我們其實不需要一個精確值。儲存資料時,對key進行多次 hash 函式運算後,二維陣列不同位置儲存頻率(Caffeine 實際實現的時候是用一維 long 型陣列,每個 long 型數字切分成16份,每份4bit,預設15次為最高訪問頻率,每個key實際 hash 了四次,落在不同 long 型數字的16份中某個位置)。讀取某個key的訪問次數時,會比較所有位置上的頻率值,取最小值返回。對於所有key的訪問頻率之和有個最大值,當達到最大值時,會進行reset即對各個快取key的頻率除以2。
如下圖快取訪問頻率儲存主要分為兩大部分,即 LRU 和 Segmented LRU 。新訪問的資料會進入第一個 LRU,在 Caffeine 裡叫 WindowDeque。當 WindowDeque 滿時,會進入 Segmented LRU 中的 ProbationDeque,在後續被訪問到時,它會被提升到 ProtectedDeque。當 ProtectedDeque 滿時,會有資料降級到 ProbationDeque 。資料需要淘汰的時候,對 ProbationDeque 中的資料進行淘汰。具體淘汰機制:取ProbationDeque 中的隊首和隊尾進行 PK,隊首資料是最先進入佇列的,稱為受害者,隊尾的資料稱為攻擊者,比較兩者 頻率大小,大勝小汰。
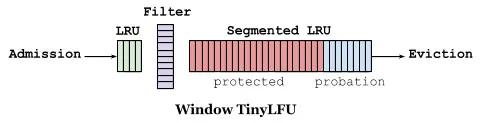
總的來說,通過 reset 衰減,避免歷史熱點資料由於頻率值比較高一直淘汰不掉,並且通過對訪問佇列分成三段,這樣避免了新加入的熱點資料早早地被淘汰掉。
2.2 高效能讀寫
Caffeine 認為讀操作是頻繁的,寫操作是偶爾的,讀寫都是非同步執行緒更新頻率資訊。
2.2.1 讀緩衝
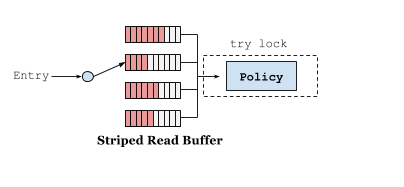
傳統的快取實現將會為每個操作加鎖,以便能夠安全的對每個訪問佇列的元素進行排序。一種優化方案是將每個操作按序加入到緩衝區中進行批處理操作。讀完把資料放到環形佇列 RingBuffer 中,為了減少讀併發,採用多個 RingBuffer,每個執行緒都有對應的 RingBuffer。環形佇列是一個定長陣列,提供高效能的能力並最大程度上減少了 GC所帶來的效能開銷。資料丟到佇列之後就返回讀取結果,類似於資料庫的WAL機制,和ConcurrentHashMap 讀取資料相比,僅僅多了把資料放到佇列這一步。非同步執行緒併發讀取 RingBuffer 陣列,更新訪問資訊,這邊的執行緒池使用的是下文實戰小節講的 Caffeine 配置引數中的 executor。
2.2.2 寫緩衝
與讀緩衝類似,寫緩衝是為了儲存寫事件。讀緩衝中的事件主要是為了優化驅逐策略的命中率,因此讀緩衝中的事件完整程度允許一定程度的有損。但是寫緩衝並不允許資料的丟失,因此其必須實現為一個安全的佇列。Caffeine 寫是把資料放入MpscGrowableArrayQueue 阻塞佇列中,它參考了JCTools裡的MpscGrowableArrayQueue ,是針對 MPSC- 多生產者單消費者(Multi-Producer & Single-Consumer)場景的高效能實現。多個生產者同時併發地寫入佇列是執行緒安全的,但是同一時刻只允許一個消費者消費佇列。
三、Caffeine 實戰
3.1 配置引數
Caffeine 借鑑了Guava Cache 的設計思想,如果之前使用過 Guava Cache,那麼Caffeine 很容易上手,只需要改變相應的類名就行。構造一個快取 Cache 示例程式碼如下:
Cache cache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(6, TimeUnit.MINUTES).softValues().build();
Caffeine 類相當於建造者模式的 Builder 類,通過 Caffeine 類配置 Cache,配置一個Cache 有如下引數:
- expireAfterWrite:寫入間隔多久淘汰;
- expireAfterAccess:最後訪問後間隔多久淘汰;
- refreshAfterWrite:寫入後間隔多久重新整理,該重新整理是基於訪問被動觸發的,支援非同步重新整理和同步重新整理,如果和 expireAfterWrite 組合使用,能夠保證即使該快取訪問不到、也能在固定時間間隔後被淘汰,否則如果單獨使用容易造成OOM;
- expireAfter:自定義淘汰策略,該策略下 Caffeine 通過時間輪演算法來實現不同key 的不同過期時間;
- maximumSize:快取 key 的最大個數;
- weakKeys:key設定為弱引用,在 GC 時可以直接淘汰;
- weakValues:value設定為弱引用,在 GC 時可以直接淘汰;
- softValues:value設定為軟引用,在記憶體溢位前可以直接淘汰;
- executor:選擇自定義的執行緒池,預設的執行緒池實現是 ForkJoinPool.commonPool();
- maximumWeight:設定快取最大權重;
- weigher:設定具體key權重;
- recordStats:快取的統計資料,比如命中率等;
- removalListener:快取淘汰監聽器;
- writer:快取寫入、更新、淘汰的監聽器。
3.2 專案實戰
Caffeine 支援解析字串引數,參照 Ehcache 的思想,可以把所有快取項引數資訊放入配置檔案裡面,比如有一個 caffeine.properties 配置檔案,裡面配置引數如下:
users=maximumSize=10000,expireAfterWrite=180s,softValues goods=maximumSize=10000,expireAfterWrite=180s,softValues
針對不同的快取,解析配置檔案,並加入 Cache 容器裡面,程式碼如下:
@Component
@Slf4j
public class CaffeineManager {
private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap<>(16);
@PostConstruct
public void afterPropertiesSet() {
String filePath = CaffeineManager.class.getClassLoader().getResource("").getPath() + File.separator + "config"
+ File.separator + "caffeine.properties";
Resource resource = new FileSystemResource(filePath);
if (!resource.exists()) {
return;
}
Properties props = new Properties();
try (InputStream in = resource.getInputStream()) {
props.load(in);
Enumeration propNames = props.propertyNames();
while (propNames.hasMoreElements()) {
String caffeineKey = (String) propNames.nextElement();
String caffeineSpec = props.getProperty(caffeineKey);
CaffeineSpec spec = CaffeineSpec.parse(caffeineSpec);
Caffeine caffeine = Caffeine.from(spec);
Cache manualCache = caffeine.build();
cacheMap.put(caffeineKey, manualCache);
}
}
catch (IOException e) {
log.error("Initialize Caffeine failed.", e);
}
}
}
當然也可以把 caffeine.properties 裡面的配置項放入配置中心,如果需要動態生效,可以通過如下方式:
至於是否利用 Spring 的 EL 表示式通過註解的方式使用,仁者見仁智者見智,筆者主要考慮三點:
一、EL 表示式上手需要學習成本;
二、引入註解需要注意動態代理失效場景;
獲取快取時通過如下方式:
caffeineManager.getCache(cacheName).get(redisKey, value -> getTFromRedis(redisKey, targetClass, supplier));
Caffeine 這種帶有回源函式的 get 方法最終都是呼叫 ConcurrentHashMap 的 compute 方法,它能確保高併發場景下,如果對一個熱點 key 進行回源時,單個程序內只有一個執行緒回源,其他都在阻塞。業務需要確保回源的方法耗時比較短,防止執行緒阻塞時間比較久,系統可用性下降。
筆者實際開發中用了 Caffeine 和 Redis 兩級快取。Caffeine 的 cache 快取 key 和 Redis 裡面一致,都是命名為 redisKey。targetClass 是返回物件型別,從 Redis 中獲取字串反序列化成實際物件時使用。supplier 是函式式介面,是快取回源到資料庫的業務邏輯。
getTFromRedis 方法實現如下:
private <T> T getTFromRedis(String redisKey, Class targetClass, Supplier supplier) {
String data;
T value;
String redisValue = UUID.randomUUID().toString();
if (tryGetDistributedLockWithRetry(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue, 30)) {
try {
data = getFromRedis(redisKey);
if (StringUtils.isEmpty(data)) {
value = (T) supplier.get();
setToRedis(redisKey, JackSonParser.bean2Json(value));
}
else {
value = json2Bean(targetClass, data);
}
}
finally {
releaseDistributedLock(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue);
}
}
else {
value = json2Bean(targetClass, getFromRedis(redisKey));
}
return value;
}
由於回源都是從 MySQL 查詢,雖然 Caffeine 本身解決了程序內同一個 key 只有一個執行緒回源,需要注意多個業務節點的分散式情況下,如果 Redis 沒有快取值,併發回源時會穿透到 MySQL ,所以回源時加了分散式鎖,保證只有一個節點回源。
注意一點:從本地快取獲取物件時,如果業務要對快取物件做更新,需要深拷貝一份物件,不然併發場景下多個執行緒取值會相互影響。
筆者專案之前都是使用 Ehcache 作為本地快取,切換成 Caffeine 後,涉及本地快取的介面,同樣 TPS 值時,CPU 使用率能降低 10% 左右,介面效能都有一定程度提升,最多的提升了 25%。上線後觀察呼叫鏈,平均響應時間降低24%左右。
四、總結
Caffeine 是目前比較優秀的本地快取解決方案,通過使用 W-TinyLFU 演算法,實現了快取高命中率、記憶體低消耗。如果之前使用過 Guava Cache,看下介面名基本就能上手。如果之前使用的是 Ehcache,筆者分享的使用方式可以作為參考。
五、參考文獻
-
TinyLFU: A Highly Efficient Cache Admission Policy
-
Design Of A Modern Cache
-
Caffeine Github
作者:Zhang Zhenglin