
無所不能的Embedding6 - 跨入Transformer時代~模型詳解&程式碼實現
阿新 • • 發佈:2021-02-08
上一章我們聊了聊quick-thought通過幹掉decoder加快訓練, CNN—LSTM用CNN作為Encoder平行計算來提速等方法,這一章看看拋開CNN和RNN,transformer是如何只基於attention對不定長的序列資訊進行提取的。雖然Attention is All you need論文字身是針對NMT翻譯任務的,但transformer作為後續USE/Bert的重要元件,放在embedding裡也沒啥問題。以下基於WMT英翻中的任務實現了transfromer,完整的模型程式碼詳見[**DSXiangLi-Embedding-transformer**](https://github.com/DSXiangLi/Embedding/tree/master/transformer)
## 模型元件
讓我們先過一遍Transformer的基礎元件,以文字場景為例,encoder和decoder的輸入是文字序列,每個batch都pad到相同長度然後對每個詞做embedding得到batch * padding_len * emb_size的輸入向量
**假設batch=1,Word Embedding維度為512,Encoder的輸入是'Fox hunt rabbit at night', 經過Embedding之後得到1 * 5 * 512的向量,以下的模型元件都服務於如何從這條文本里提取出更多的資訊**
### Attention
序列資訊提取的一個要點在於如何讓每個詞都考慮到它所在的上下文語境
- RNN:上下文資訊靠向後/前傳遞,從前往後傳rabbit就能考慮到fox,從後往前傳rabbit就能考慮到night
- CNN:靠不同kernel_size定義的區域性視窗來獲取context資訊, kernel_size>=3,rabbit就能考慮到所有其他token的資訊
- Attention:通過計算詞和上下文之間的相關性(廣義),來決定如何把周圍資訊(value)融合(weighted-average)進當前資訊(query),下圖來源Reference5
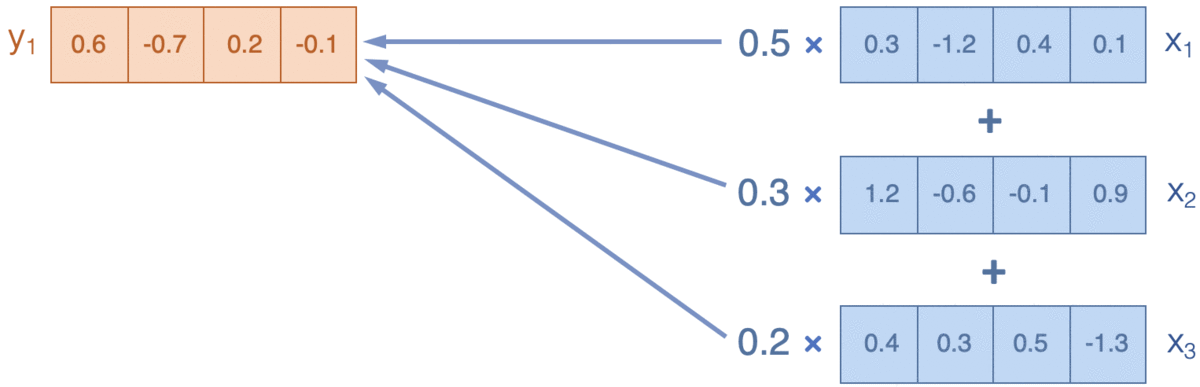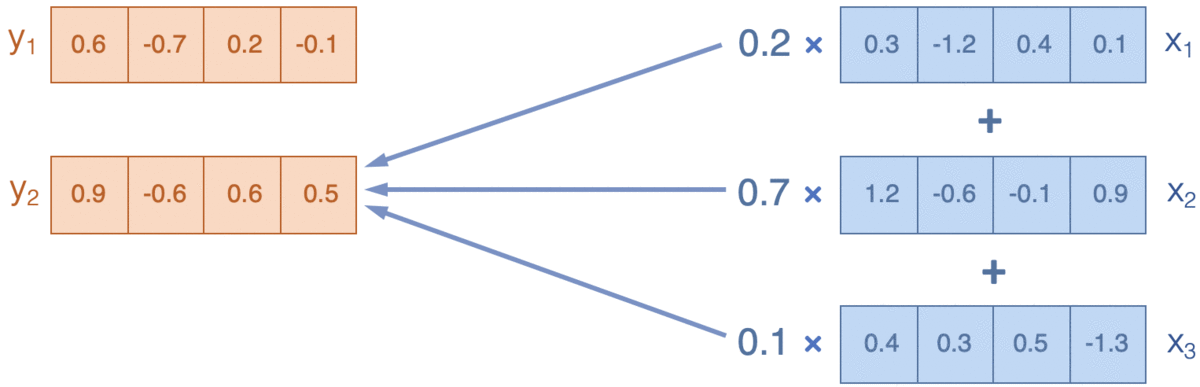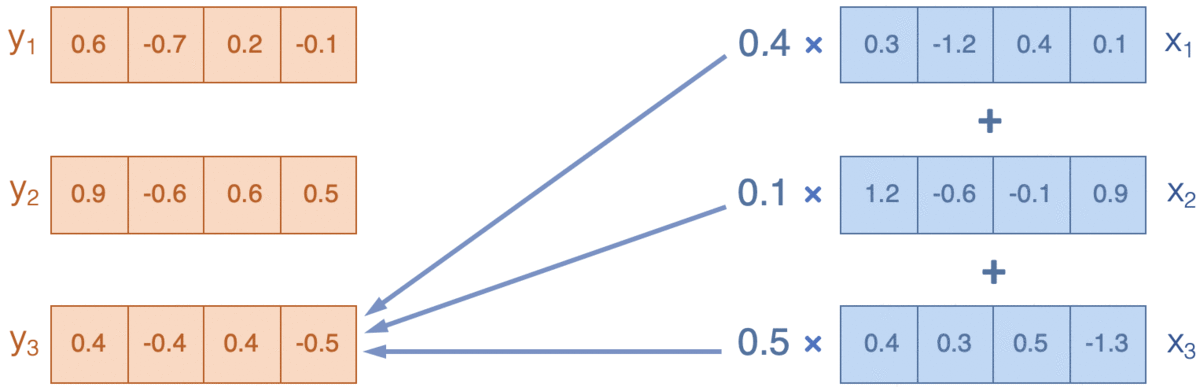
Transformer在attention的基礎上有兩點改良, 分別是Scaled-dot product attention和multi-head attention。 #### Scaled-dot product attention

Attention的輸入是三要素query,key和value,通過計算query和Key的相關性,這裡是廣義的相關,可以通過[加法][1]/[乘法][2]得到權重向量,用權重對value做加權平均作為輸出。‘fox hunt rabbit at night’會計算每個詞對所有詞的相關性,得到[5, 5]的相似度矩陣/權重向量,來對輸入[5, 512]進行加權,得到每個詞在考慮上下文語義後新的向量表達[5, 512] Transformer在常規的乘法attention的基礎上加入$d_k$維度的正則化。這裡$d_k$是query和key的特徵維度,在我們的文字場景下是embedding_size[512] 。正則化的原因是避免高維embedding的內積出現超級大的值,導致softmax的gradient非常小。 直觀解釋,假設query和key的每個元素都獨立服從$\mu=0 \, \sigma^2=1$的分佈, 那內積$\sum_{d_k}q_ik_i$就服從$\mu=0 \, \sigma^2=d_k$的分佈,因此需要用$\sqrt{d_k}$做正則化,保證內積依舊服從$\mu=0 \, \sigma=1$的分佈。 $$ Attentino(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}) \cdot V $$ ```python def scaled_dot_product_attention(key, value, query, mask): with tf.variable_scope('scaled_dot_product_attention', reuse=tf.AUTO_REUSE): # scalaed weight matrix : batch_size * query_len * key_len dk = tf.cast(key.shape.as_list()[-1], tf.float32)# emb_size weight = tf.matmul(query, key, transpose_b=True)/(dk**0.5) # apply mask: large negative will become 0 in softmax[mask=0 ignore] weight += (1-mask) * (-2**32+1) # normalize on axis key_len so that score add up to 1 weight = tf.nn.softmax(weight, axis=-1) tf.summary.image("attention", tf.expand_dims(weight[:1], -1)) # add channel dim add_layer_summary('attention', weight) # weighted value: batch_size * query_len * emb_size weighted_value = tf.matmul(weight, value ) return weighted_value ``` ### Mask 上面程式碼中的mask是做什麼的呢?mask決定了Attention對哪些特徵計算權重,transformer的mask有兩種【以下mask=1是保留的部分,0是drop的部分】 其一是padding mask, 讓attention的權重只針對真實文字計算其餘為0。padding mask的dimension是[batch, 1, key_len], 1是預留給query,會在attention中被broadcast成[batch, query_len, key_len] ```python def seq_mask_gen(input_, params): mask = tf.sequence_mask(lengths=tf.to_int32(input_['seq_len']), maxlen=tf.shape(input_['tokens'])[1], dtype=params['dtype']) mask = tf.expand_dims(mask, axis=1) return mask ``` 如果輸入文字長度分別為3,4,5,都padding到5,padding mask維度是[3,1,5] 如下

其二是future mask只用於decoder,mask每個token後面的序列,保證在預測T+1的token時只會用到T及T以前的資訊,如果不加future mask,預測T+1時就會用到T+1的文字本身,出現feature leakage。 ```python def future_mask_gen(input_, params): seq_mask = seq_mask_gen(input_, params) # batch_size * 1 * key_len mask = tf.matmul(seq_mask, seq_mask, transpose_a=True) # batch_size * key_len * key_len mask = tf.matrix_band_part(mask, num_lower=-1, num_upper=0) return mask ``` 還是上面的例子,future mask的維度是[3,5,5] 如下

#### multi-head attention

這些年對multi-head為啥有效的討論有很多,下面Reference3~8都從不同方面給出了不同的Insight。最開始看multi-head的設計,第一反應是你莫不是在逗我?!你把