LSTM - 長短期記憶網路
阿新 • • 發佈:2021-02-09
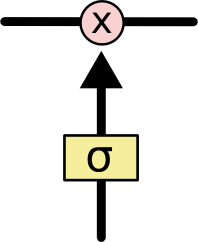
## 迴圈神經網路(RNN)
人們不是每一秒都從頭開始思考,就像你閱讀本文時,不會從頭去重新學習一個文字,人類的思維是有持續性的。傳統的卷積神經網路沒有記憶,不能解決這一個問題,迴圈神經網路(Recurrent Neural Networks)可以解決這一個問題,在迴圈神經網路中,通過迴圈可以解決沒有記憶的問題,如下圖: