
資料倉庫和正規化
0x00 概述
長期從事資料倉庫的你,是否還記得資料庫設計中的三大正規化?在設計資料倉庫的表時,是否考慮過規範化和反規範化之間的區別?是否想過資料倉庫和資料庫在設計中對正規化考慮的側重點是什麼?
本文,將包含如下幾個方面:
- 一起回顧資料庫設計中經典的三大正規化
- 聊一聊資料倉庫和正規化之間的關係
- 聊一聊資料倉庫和資料庫在正規化設計中的側重點
全文將會圍繞一個訂單表(假設一個訂單中只有一種商品出現)設計的例子,既有資料庫中表的設計,亦有資料倉庫中表的設計,一個例子貫穿全文,有始有終,簡單易懂。
0x01 三正規化
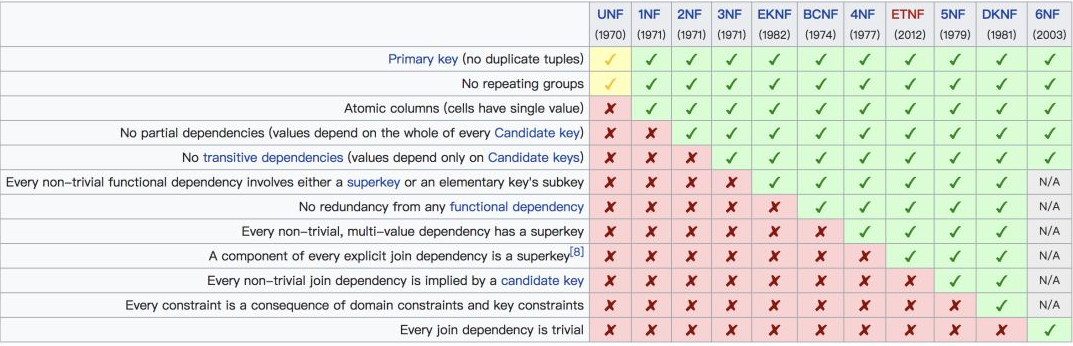
首先回顧一下正規化是什麼:
設計關係資料庫時,遵從不同的規範要求,設計出合理的關係型資料庫,這些不同的規範要求被稱為不同的正規化,各種正規化呈遞次規範,越高的正規化資料庫冗餘越小。
目前關係資料庫有六種正規化:第一正規化(1NF)、第二正規化(2NF)、第三正規化(3NF)、巴斯-科德正規化(BCNF)、第四正規化(4NF)和第五正規化(5NF,又稱完美正規化)。
資料庫正規化有這麼多,但是在工作中常用到的一般是前三個正規化,因此,本文將只舉例分享第一、二、三正規化。為了方便理解,先上一個關於各個正規化核心點的圖鎮樓,後面的說明會參考該圖來進行。
第零正規化
我們暫且將第一種設計稱為第零正規化,它滿足一個基本條件:無重複資料。
如下,是我們按照無正規化設計的第一張訂單表。雖說該設計將成為一個被挑毛病的壞孩子,但從設計上來看,仍是可被理解的。
第一正規化
第一正規化的核心在於 Atomic colums(cells have single value),即屬性不可分。
該設計和第零正規化的區別在於我們將“購買資訊”這一個欄位拆成了“購買單價”和“購買數量”兩個欄位,新表滿足了第一正規化。

第二正規化
第二正規化在第一正規化的基礎之上更進一層。第二正規化需要確保資料庫表中的每一列都和主鍵相關,而不能只與主鍵的某一部分相關(主要針對聯合主鍵而言)。即在第一正規化的基礎上滿足屬性完全依賴於主鍵。
以第一正規化中的設計為例,商品數量、總金額和購買日期是完全依賴於(使用者ID,商品ID)的,但是商品名和商品價格只依賴於商品ID,使用者資訊只依賴於使用者ID,這屬於部分依賴。
因此,將使用者資訊和商品資訊單獨拎出來後,我們的訂單表設計就變成了如下三張表:訂單表,商品表和使用者表。直觀一點來理解第二正規化的話,就是說一個數據表中只能儲存一種資料,不可以把多種資料儲存在同一張資料庫表中。
第三正規化
第三正規化需要確保資料表中的每一列資料都和主鍵直接相關,而不能間接相關。即在第二正規化的基礎上滿足屬性只直接依賴主鍵。
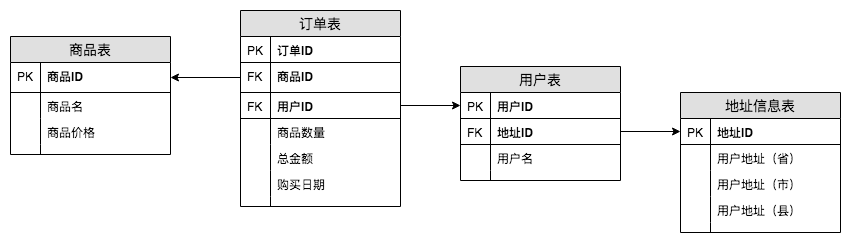
以第二正規化中的設計為例,現在訂單表中的資訊已經完全依賴於訂單ID了,該設計是滿足第二正規化的。但是在使用者表中,使用者ID和地址資訊是存在傳遞依賴的,即:使用者ID決定地址ID,地址ID決定(省,市,縣),這是傳遞依賴。
因此,我在地址資訊表單獨拎出來之後就可以設計出如下滿足第三正規化的表了。
0x02 資料倉庫和三正規化
以上,簡單回顧了一下三正規化的內容,下面將分析一下資料倉庫中的資料建模和三正規化之間的關係。
正規化建模
正規化建模是資料倉庫之父 Bill lnmon 提出的建模方法是從全企業的高度設計一個第三正規化的模型,用實體關係(Entity Relationship, ER)模型描述企業業務,在正規化理論上符合第三正規化。
因此我們可以認為資料倉庫中的正規化建模,在表的設計上和正規化中的第三正規化基本上一致的,具體到表的設計是可以如下內容。
維度建模
維度模型是資料倉庫領域另一位大師 Ralph Kimball 所倡導,維度建模以分析決策的需求出發構建模型,構建的資料模型為分析需求服務,因此它重點解決使用者如何更快速完成分析需求,同時還有較好的大規模複雜查詢的響應效能。
維度建模的理論就不再細說,我們只介紹兩個主要概念:事實表和維度表。
事實表:我們可以簡單地將事實理解為現實中發生的一次操作型事件。比如訂單表,我們就可以理解為一張事實表,我們每完成一個訂單,就會在訂單事實表中增加一條記錄。
維度表:我們可以簡單地理解維度表包含了事實表中指定屬性的相關詳細資訊。比如商品維度表表和使用者維度表。
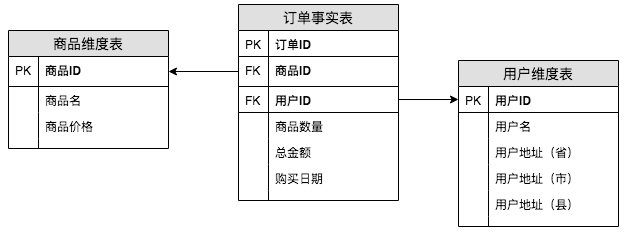
那麼用維度建模的方式進行設計的話,我們會設計如下三張表:訂單事實表、商品維度表和使用者維度表。這種設計,在正規化理論上符合第二正規化。
一般大家也會稱維度建模是星星模型,可以將事實表當作是中間最大的一顆星星,維度表圍繞在事實表周圍。星星模型和雪花模型的主要區別在於維度表是否都和事實表直接相連。如下圖,將我們的星星模型轉換成了雪花模型,比如年維度表並不是直接連在訂單事實表上,而是連在日期維度表上。
因此,簡單點來講,我們可以認為星星模型是將同一主題的維度資訊冗餘在了一張維表中。
有冗餘的事實表
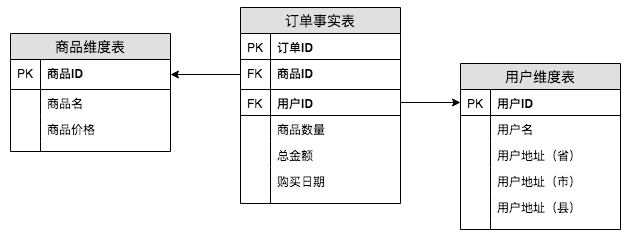
在維度建模中我們聊到了事實表的設計,它其實是符合第二正規化的設計,但是在實際工作中我們經常會在事實表中存放更多的資訊,以便更好地滿足業務需求。
如下圖,我們會將使用者資訊和商品資訊都冗餘到訂單事實表中,在這種情況下,該事實表的設計在正規化理論上符合第一正規化。

0x03 資料倉庫和資料庫的側重點
在大部分的資料倉庫設計中,一般是不怎麼考慮是否滿足第幾正規化的,特別是網際網路場景下的資料建設就更少考慮資料倉庫和正規化之間的關係,但是這並不妨礙我們去理解它們設計背後的出發點。至少我們可以搞明白為什麼資料倉庫設計不用過多關注正規化。
我們這裡聊到的資料庫的設計,可以理解是聯機事務處理OLTP(On-Line Transaction Processing),主要是基本的、日常的事務處理,例如銀行交易。直白點講,就是各種增刪改查,需要對資料進行操作。而資料倉庫,我們可以理解為是聯機分析處理OLAP(On-Line Analytical Processing),主要是面向日常資料分析,它的資料主要是插入和查詢,基本不涉及刪除和修改操作。
本文的主人公-正規化,主要優化的是增刪改的問題,比如資料冗餘、更新異常、刪除異常等。這些也正是資料庫設計比較關注的點。而資料倉庫對這方面的關注度則比較少,資料倉庫更關注的是使用是否方便,查詢效率是否高,因此在設計資料倉庫的時候不必太多關注正規化的設計,一般第一或者第二正規化就夠用。
另外,資料倉庫不同層級的設計也會用到不同的建模方式,比如說接近業務資料的層次,會更傾向使用正規化建模,接近資料分析的層次則會更傾向於維度建模,這個話題會在資料分層的文章中有更詳細的講解。
0xFF 總結
本文主要是聊一聊資料倉庫和正規化之間的關係,算是對資料倉庫相關理論的一種梳理。雖說對日常工作的影響不大,但是仍可以作為補充知識的學