
K8S線上叢集排查,實測排查Node節點NotReady異常狀態
阿新 • • 發佈:2021-02-19
#### 一,文章簡述
大家好,本篇是個人的第 2 篇文章。是關於在之前專案中,k8s 線上叢集中 Node 節點狀態變成 NotReady 狀態,導致整個 Node 節點中容器停止服務後的問題排查。
文章中所描述的是本人在專案中線上環境實際解決的,那除了如何解決該問題,更重要的是如何去排查這個問題的起因。
關於 Node 節點不可用的 NotReady 狀態,當時也是花了挺久的時間去排查的。
#### 二,Pod 狀態
在分析 NotReady 狀態之前,我們首先需要了解在 k8s 中 Pod 的狀態都有哪些。並且每個狀態都表示什麼含義,不同狀態是很直觀的顯示出當前 Pod 所處的建立資訊。
為了避免大家對 Node 和 Pod 的概念混淆,先簡單描述下兩者之間的關係(引用一張 K8S 官方圖)。
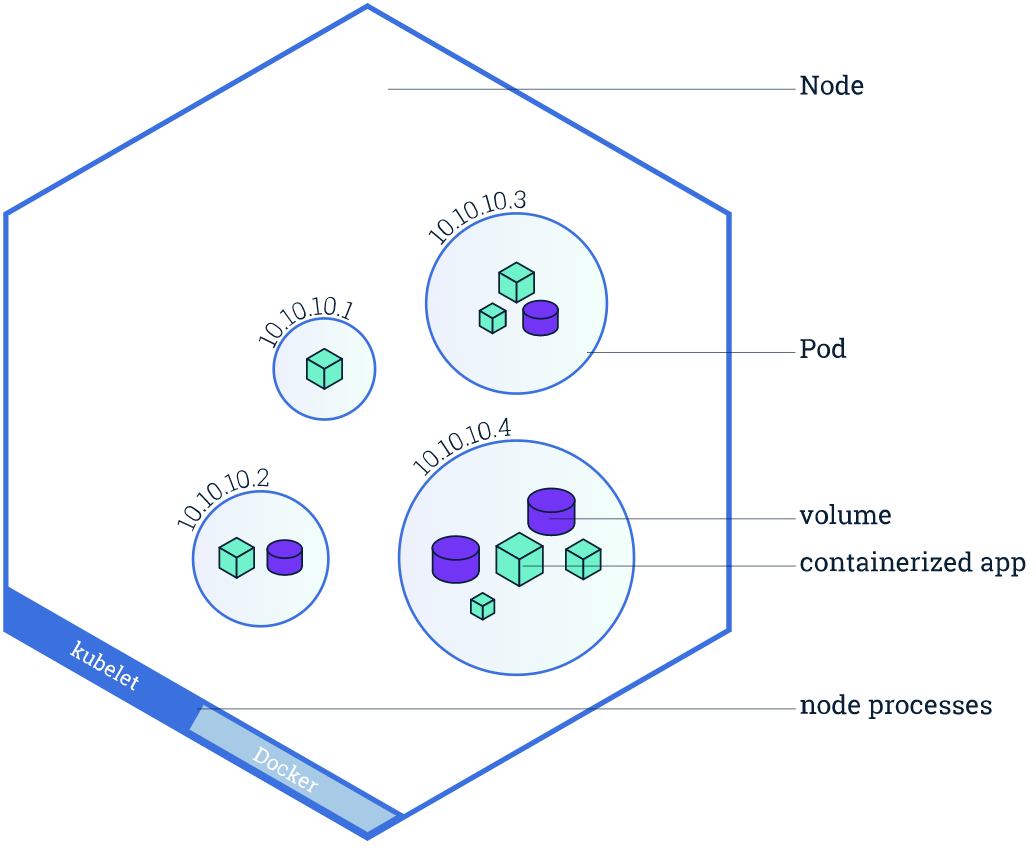 從圖中很直觀的顯示出最外面就是 Node 節點,而一個 Node 節點中是可以執行多個 Pod 容器,再深入一層就是每個 Pod 容器可以執行多個例項 App 容器。
因此關於本篇文章所闡述的 Node 節點不可用,就會直接導致 Node 節點中所有的容器不可用。
毫無疑問,Node 節點是否健康,直接影響該節點下所有的例項容器的健康狀態,直至影響整個 K8S 叢集。
那麼如何解決並排查 Node 節點的健康狀態?不急,我們先來聊聊關於關於 Pod 的生命週期狀態。
從圖中很直觀的顯示出最外面就是 Node 節點,而一個 Node 節點中是可以執行多個 Pod 容器,再深入一層就是每個 Pod 容器可以執行多個例項 App 容器。
因此關於本篇文章所闡述的 Node 節點不可用,就會直接導致 Node 節點中所有的容器不可用。
毫無疑問,Node 節點是否健康,直接影響該節點下所有的例項容器的健康狀態,直至影響整個 K8S 叢集。
那麼如何解決並排查 Node 節點的健康狀態?不急,我們先來聊聊關於關於 Pod 的生命週期狀態。
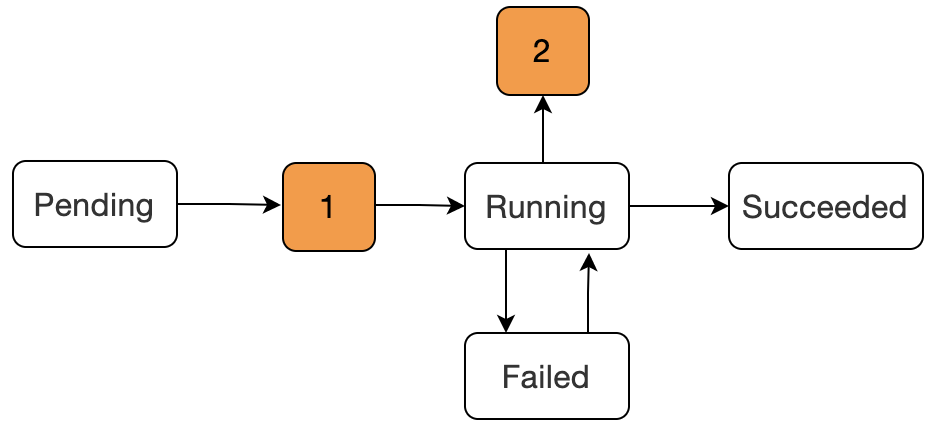 - `Pending`:該階段表示已經被 Kubernetes 所接受,但是容器還沒有被建立,正在被 kube 進行資源排程。
- `1`:圖中數字 1 是表示在被 kube 資源排程成功後,開始進行容器的建立,但是在這個階段是會出現容器建立失敗的現象
- `Waiting或ContainerCreating`:這兩個原因就在於容器建立過程中**映象拉取失敗**,或者**網路錯誤**容器的狀態就會發生轉變。
- `Running`:該階段表示容器已經正常執行。
- `Failed`:Pod 中的容器是以非 0 狀態(非正常)狀態退出的。
- `2`:階段 2 可能出現的狀態為`CrashLoopBackOff`,表示容器正常啟動但是存在異常退出。
- `Succeeded`:Pod 容器成功終止,並且不會再在重啟。
上面的狀態只是 Pod 生命週期中比較常見的狀態,還有一些狀態沒有列舉出來。
這。。。狀態有點多。休息 3 秒鐘
- `Pending`:該階段表示已經被 Kubernetes 所接受,但是容器還沒有被建立,正在被 kube 進行資源排程。
- `1`:圖中數字 1 是表示在被 kube 資源排程成功後,開始進行容器的建立,但是在這個階段是會出現容器建立失敗的現象
- `Waiting或ContainerCreating`:這兩個原因就在於容器建立過程中**映象拉取失敗**,或者**網路錯誤**容器的狀態就會發生轉變。
- `Running`:該階段表示容器已經正常執行。
- `Failed`:Pod 中的容器是以非 0 狀態(非正常)狀態退出的。
- `2`:階段 2 可能出現的狀態為`CrashLoopBackOff`,表示容器正常啟動但是存在異常退出。
- `Succeeded`:Pod 容器成功終止,並且不會再在重啟。
上面的狀態只是 Pod 生命週期中比較常見的狀態,還有一些狀態沒有列舉出來。
這。。。狀態有點多。休息 3 秒鐘



 好吧,那就看看為什麼還沒準備好。
##### 4.1 問題分析
再回到我們前面說到問題,就是 Node 節點變成 NotReady 狀態後,Pod 容器是否還成正常執行。

圖中用紅框標示的就是在節點`edgenode`上,此時 Pod 狀態已經顯示為**Terminating**,表示 Pod 已經終止服務。
接下來我們就分析下 Node 節點為什麼不可用。
(1)首先從伺服器物理環境排查,使用命令`df -m`檢視磁碟的使用情況

或者直接使用命令`free`檢視

磁碟並沒有溢位,也就是說物理空間足夠。
(2)接著我們再檢視下 CPU 的使用率,命令為:`top -c (大寫P可倒序)`

CPU 的使用率也是在範圍內,不管是在物理磁碟空間還是 CPU 效能,都沒有什麼異常。那 Node 節點怎麼就不可用了呢?而且伺服器也是正常執行中。
這似乎就有點為難了,這可咋整?

(3)不慌,還有一項可以作為排查的依據,那就是使用 kube 命令 describe 命令檢視 Node 節點的詳細日誌。完整命令為:
`kubectl describe node <節點名稱>`,那麼圖中 Node 節點如圖:

哎呀,好像在這個日誌裡面看到了一些資訊描述,首先我們先看第一句:`Kubelet stoped posting node status`,大致的意思是 Kubelet 停止傳送 node 狀態了,再接著`Kubelet never posted node status`意思為再也收不到 node 狀態了。
> 檢視下 Kubelet 是否在正常執行,是使用命令:`systemctl status kubelet`,如果狀態為 Failed,那麼是需要重啟下的。但如果是正常執行,請繼續向下看。
分析一下好像有點眉目了,Kubelet 為什麼要傳送 node 節點的狀態呢?這就丟擲了關於 Pod 的另一個知識點,請耐心向下看。
#### 五,Pod 健康檢測 PLEG
根據我們最後面分析的情形,似乎是 node 狀態再也沒有收到上報,導致 node 節點不可用,這就引申出關於 Pod 的生命健康週期。
`PLEG`全稱為:`Pod Lifecycle Event Generator`:Pod 生命週期事件生成器。
簡單理解就是根據 Pod 事件級別來調整容器執行時的狀態,並將其寫入 Pod 快取中,來保持 Pod 的最新狀態。
在上述圖中,看出是 Kubelet 在檢測 Pod 的健康狀態。Kubelet 是每個節點上的一個守護程序,Kubelet 會定期去檢測 Pod 的健康資訊,先看一張官方圖。
好吧,那就看看為什麼還沒準備好。
##### 4.1 問題分析
再回到我們前面說到問題,就是 Node 節點變成 NotReady 狀態後,Pod 容器是否還成正常執行。

圖中用紅框標示的就是在節點`edgenode`上,此時 Pod 狀態已經顯示為**Terminating**,表示 Pod 已經終止服務。
接下來我們就分析下 Node 節點為什麼不可用。
(1)首先從伺服器物理環境排查,使用命令`df -m`檢視磁碟的使用情況

或者直接使用命令`free`檢視

磁碟並沒有溢位,也就是說物理空間足夠。
(2)接著我們再檢視下 CPU 的使用率,命令為:`top -c (大寫P可倒序)`

CPU 的使用率也是在範圍內,不管是在物理磁碟空間還是 CPU 效能,都沒有什麼異常。那 Node 節點怎麼就不可用了呢?而且伺服器也是正常執行中。
這似乎就有點為難了,這可咋整?

(3)不慌,還有一項可以作為排查的依據,那就是使用 kube 命令 describe 命令檢視 Node 節點的詳細日誌。完整命令為:
`kubectl describe node <節點名稱>`,那麼圖中 Node 節點如圖:

哎呀,好像在這個日誌裡面看到了一些資訊描述,首先我們先看第一句:`Kubelet stoped posting node status`,大致的意思是 Kubelet 停止傳送 node 狀態了,再接著`Kubelet never posted node status`意思為再也收不到 node 狀態了。
> 檢視下 Kubelet 是否在正常執行,是使用命令:`systemctl status kubelet`,如果狀態為 Failed,那麼是需要重啟下的。但如果是正常執行,請繼續向下看。
分析一下好像有點眉目了,Kubelet 為什麼要傳送 node 節點的狀態呢?這就丟擲了關於 Pod 的另一個知識點,請耐心向下看。
#### 五,Pod 健康檢測 PLEG
根據我們最後面分析的情形,似乎是 node 狀態再也沒有收到上報,導致 node 節點不可用,這就引申出關於 Pod 的生命健康週期。
`PLEG`全稱為:`Pod Lifecycle Event Generator`:Pod 生命週期事件生成器。
簡單理解就是根據 Pod 事件級別來調整容器執行時的狀態,並將其寫入 Pod 快取中,來保持 Pod 的最新狀態。
在上述圖中,看出是 Kubelet 在檢測 Pod 的健康狀態。Kubelet 是每個節點上的一個守護程序,Kubelet 會定期去檢測 Pod 的健康資訊,先看一張官方圖。
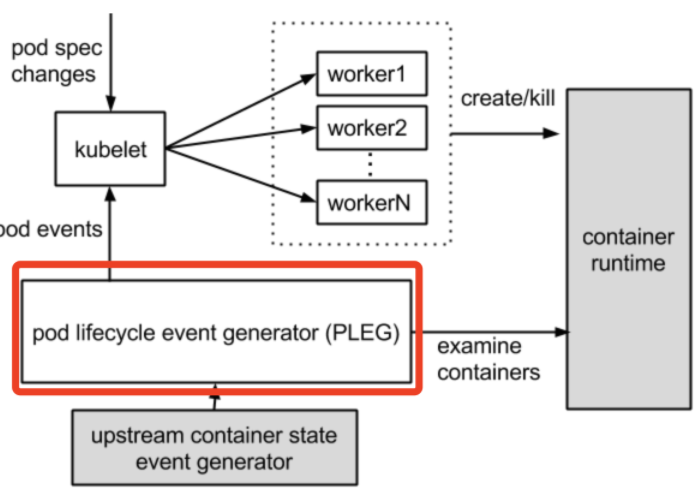 `PLEG`去檢測執行容器的狀態,而 kubelet 是通過**輪詢**機制去檢測的。
分析到這裡,似乎有點方向了,導致 Node 節點變成 NotReady 狀態是和 Pod 的健康狀態檢測有關係,正是因為超過預設時間了,K8S 叢集將 Node 節點停止服務了。
那為什麼會沒有收到健康狀態上報呢?我們先檢視下在 K8S 中預設檢測的時間是多少。
在叢集伺服器是上,進入目錄:`/etc/kubernetes/manifests/kube-controller-manager.yaml`,檢視引數:
```yaml
–node-monitor-grace-period=40s(node驅逐時間)
–node-monitor-period=5s(輪詢間隔時間)
```
上面兩項引數表示每隔 5 秒 kubelet 去檢測 Pod 的健康狀態,如果在 40 秒後依然沒有檢測到 Pod 的健康狀態便將其置為 NotReady 狀態,5 分鐘後就將節點下所有的 Pod 進行驅逐。
官方文件中對 Pod 驅逐策略進行了簡單的描述,`https://kubernetes.io/zh/docs/concepts/scheduling-eviction/eviction-policy/`
`PLEG`去檢測執行容器的狀態,而 kubelet 是通過**輪詢**機制去檢測的。
分析到這裡,似乎有點方向了,導致 Node 節點變成 NotReady 狀態是和 Pod 的健康狀態檢測有關係,正是因為超過預設時間了,K8S 叢集將 Node 節點停止服務了。
那為什麼會沒有收到健康狀態上報呢?我們先檢視下在 K8S 中預設檢測的時間是多少。
在叢集伺服器是上,進入目錄:`/etc/kubernetes/manifests/kube-controller-manager.yaml`,檢視引數:
```yaml
–node-monitor-grace-period=40s(node驅逐時間)
–node-monitor-period=5s(輪詢間隔時間)
```
上面兩項引數表示每隔 5 秒 kubelet 去檢測 Pod 的健康狀態,如果在 40 秒後依然沒有檢測到 Pod 的健康狀態便將其置為 NotReady 狀態,5 分鐘後就將節點下所有的 Pod 進行驅逐。
官方文件中對 Pod 驅逐策略進行了簡單的描述,`https://kubernetes.io/zh/docs/concepts/scheduling-eviction/eviction-policy/`
 kubelet 輪詢檢測 Pod 的狀態其實是一種很消耗效能的操作,尤其隨著 Pod 容器的數量增加,對效能是一種嚴重的消耗。
在 GitHub 上的一位小哥對此也表示有自己的看法,原文連結為:
`https://github.com/fabric8io/kansible/blob/master/vendor/k8s.io/kubernetes/docs/proposals/pod-lifecycle-event-generator.md`
到這裡我們分析的也差不多了,得到的結論為:
- Pod 數量的增加導致 Kubelet 輪詢對伺服器的壓力增大,CPU 資源緊張
- Kubelet 輪詢去檢測 Pod 的狀態,就勢必受網路的影響
- Node 節點物理硬體資源限制,無法承載較多的容器
而由於本人當時硬體的限制,及網路環境較差的前提下,所以只改了上面了兩項引數配置,延長 Kubelet 去輪詢檢測 Pod 的健康狀態。實際效果也確實得到了改善。
```yaml
// 需要重啟docker
sudo systemctl restart docker
// 需要重啟kubelet
sudo systemctl restart kubelet
```
但是如果條件允許的情況下,個人建議最好是從硬體方面優化。
- 提高 Node 節點的物理資源
- 優化 K8S 網路環境
#### 六,K8S 常用命令
最後分享一些常用的 K8S 命令
##### 1,查詢全部 pod(名稱空間)
kubectl get
kubelet 輪詢檢測 Pod 的狀態其實是一種很消耗效能的操作,尤其隨著 Pod 容器的數量增加,對效能是一種嚴重的消耗。
在 GitHub 上的一位小哥對此也表示有自己的看法,原文連結為:
`https://github.com/fabric8io/kansible/blob/master/vendor/k8s.io/kubernetes/docs/proposals/pod-lifecycle-event-generator.md`
到這裡我們分析的也差不多了,得到的結論為:
- Pod 數量的增加導致 Kubelet 輪詢對伺服器的壓力增大,CPU 資源緊張
- Kubelet 輪詢去檢測 Pod 的狀態,就勢必受網路的影響
- Node 節點物理硬體資源限制,無法承載較多的容器
而由於本人當時硬體的限制,及網路環境較差的前提下,所以只改了上面了兩項引數配置,延長 Kubelet 去輪詢檢測 Pod 的健康狀態。實際效果也確實得到了改善。
```yaml
// 需要重啟docker
sudo systemctl restart docker
// 需要重啟kubelet
sudo systemctl restart kubelet
```
但是如果條件允許的情況下,個人建議最好是從硬體方面優化。
- 提高 Node 節點的物理資源
- 優化 K8S 網路環境
#### 六,K8S 常用命令
最後分享一些常用的 K8S 命令
##### 1,查詢全部 pod(名稱空間)
kubectl get
從圖中很直觀的顯示出最外面就是 Node 節點,而一個 Node 節點中是可以執行多個 Pod 容器,再深入一層就是每個 Pod 容器可以執行多個例項 App 容器。
因此關於本篇文章所闡述的 Node 節點不可用,就會直接導致 Node 節點中所有的容器不可用。
毫無疑問,Node 節點是否健康,直接影響該節點下所有的例項容器的健康狀態,直至影響整個 K8S 叢集。
那麼如何解決並排查 Node 節點的健康狀態?不急,我們先來聊聊關於關於 Pod 的生命週期狀態。
- `Pending`:該階段表示已經被 Kubernetes 所接受,但是容器還沒有被建立,正在被 kube 進行資源排程。
- `1`:圖中數字 1 是表示在被 kube 資源排程成功後,開始進行容器的建立,但是在這個階段是會出現容器建立失敗的現象
- `Waiting或ContainerCreating`:這兩個原因就在於容器建立過程中**映象拉取失敗**,或者**網路錯誤**容器的狀態就會發生轉變。
- `Running`:該階段表示容器已經正常執行。
- `Failed`:Pod 中的容器是以非 0 狀態(非正常)狀態退出的。
- `2`:階段 2 可能出現的狀態為`CrashLoopBackOff`,表示容器正常啟動但是存在異常退出。
- `Succeeded`:Pod 容器成功終止,並且不會再在重啟。
上面的狀態只是 Pod 生命週期中比較常見的狀態,還有一些狀態沒有列舉出來。
這。。。狀態有點多。休息 3 秒鐘
好吧,那就看看為什麼還沒準備好。
##### 4.1 問題分析
再回到我們前面說到問題,就是 Node 節點變成 NotReady 狀態後,Pod 容器是否還成正常執行。

圖中用紅框標示的就是在節點`edgenode`上,此時 Pod 狀態已經顯示為**Terminating**,表示 Pod 已經終止服務。
接下來我們就分析下 Node 節點為什麼不可用。
(1)首先從伺服器物理環境排查,使用命令`df -m`檢視磁碟的使用情況

或者直接使用命令`free`檢視

磁碟並沒有溢位,也就是說物理空間足夠。
(2)接著我們再檢視下 CPU 的使用率,命令為:`top -c (大寫P可倒序)`

CPU 的使用率也是在範圍內,不管是在物理磁碟空間還是 CPU 效能,都沒有什麼異常。那 Node 節點怎麼就不可用了呢?而且伺服器也是正常執行中。
這似乎就有點為難了,這可咋整?

(3)不慌,還有一項可以作為排查的依據,那就是使用 kube 命令 describe 命令檢視 Node 節點的詳細日誌。完整命令為:
`kubectl describe node <節點名稱>`,那麼圖中 Node 節點如圖:

哎呀,好像在這個日誌裡面看到了一些資訊描述,首先我們先看第一句:`Kubelet stoped posting node status`,大致的意思是 Kubelet 停止傳送 node 狀態了,再接著`Kubelet never posted node status`意思為再也收不到 node 狀態了。
> 檢視下 Kubelet 是否在正常執行,是使用命令:`systemctl status kubelet`,如果狀態為 Failed,那麼是需要重啟下的。但如果是正常執行,請繼續向下看。
分析一下好像有點眉目了,Kubelet 為什麼要傳送 node 節點的狀態呢?這就丟擲了關於 Pod 的另一個知識點,請耐心向下看。
#### 五,Pod 健康檢測 PLEG
根據我們最後面分析的情形,似乎是 node 狀態再也沒有收到上報,導致 node 節點不可用,這就引申出關於 Pod 的生命健康週期。
`PLEG`全稱為:`Pod Lifecycle Event Generator`:Pod 生命週期事件生成器。
簡單理解就是根據 Pod 事件級別來調整容器執行時的狀態,並將其寫入 Pod 快取中,來保持 Pod 的最新狀態。
在上述圖中,看出是 Kubelet 在檢測 Pod 的健康狀態。Kubelet 是每個節點上的一個守護程序,Kubelet 會定期去檢測 Pod 的健康資訊,先看一張官方圖。
`PLEG`去檢測執行容器的狀態,而 kubelet 是通過**輪詢**機制去檢測的。
分析到這裡,似乎有點方向了,導致 Node 節點變成 NotReady 狀態是和 Pod 的健康狀態檢測有關係,正是因為超過預設時間了,K8S 叢集將 Node 節點停止服務了。
那為什麼會沒有收到健康狀態上報呢?我們先檢視下在 K8S 中預設檢測的時間是多少。
在叢集伺服器是上,進入目錄:`/etc/kubernetes/manifests/kube-controller-manager.yaml`,檢視引數:
```yaml
–node-monitor-grace-period=40s(node驅逐時間)
–node-monitor-period=5s(輪詢間隔時間)
```
上面兩項引數表示每隔 5 秒 kubelet 去檢測 Pod 的健康狀態,如果在 40 秒後依然沒有檢測到 Pod 的健康狀態便將其置為 NotReady 狀態,5 分鐘後就將節點下所有的 Pod 進行驅逐。
官方文件中對 Pod 驅逐策略進行了簡單的描述,`https://kubernetes.io/zh/docs/concepts/scheduling-eviction/eviction-policy/`
kubelet 輪詢檢測 Pod 的狀態其實是一種很消耗效能的操作,尤其隨著 Pod 容器的數量增加,對效能是一種嚴重的消耗。
在 GitHub 上的一位小哥對此也表示有自己的看法,原文連結為:
`https://github.com/fabric8io/kansible/blob/master/vendor/k8s.io/kubernetes/docs/proposals/pod-lifecycle-event-generator.md`
到這裡我們分析的也差不多了,得到的結論為:
- Pod 數量的增加導致 Kubelet 輪詢對伺服器的壓力增大,CPU 資源緊張
- Kubelet 輪詢去檢測 Pod 的狀態,就勢必受網路的影響
- Node 節點物理硬體資源限制,無法承載較多的容器
而由於本人當時硬體的限制,及網路環境較差的前提下,所以只改了上面了兩項引數配置,延長 Kubelet 去輪詢檢測 Pod 的健康狀態。實際效果也確實得到了改善。
```yaml
// 需要重啟docker
sudo systemctl restart docker
// 需要重啟kubelet
sudo systemctl restart kubelet
```
但是如果條件允許的情況下,個人建議最好是從硬體方面優化。
- 提高 Node 節點的物理資源
- 優化 K8S 網路環境
#### 六,K8S 常用命令
最後分享一些常用的 K8S 命令
##### 1,查詢全部 pod(名稱空間)
kubectl get